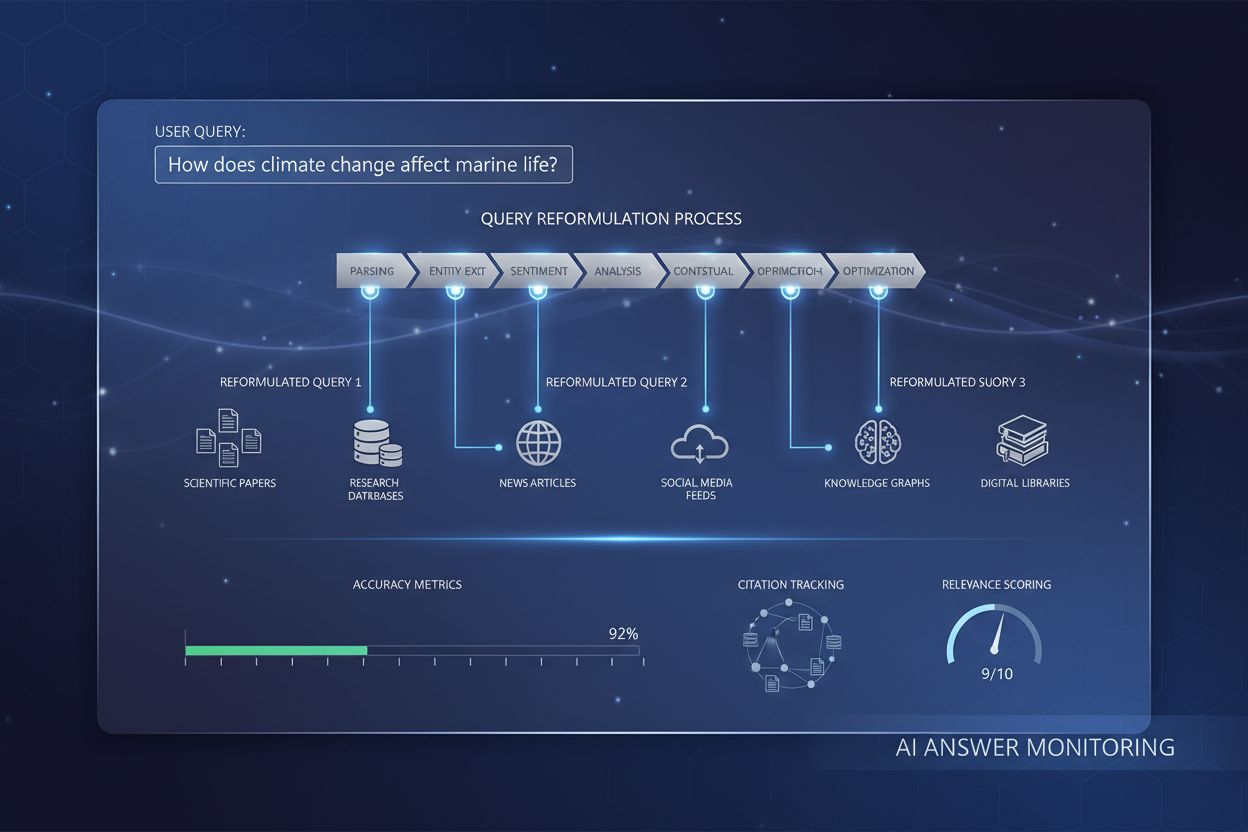
Forespørgselsreformulering
Lær hvordan forespørgselsreformulering hjælper AI-systemer med at fortolke og forbedre brugerforespørgsler for bedre informationssøgning. Forstå teknikkerne, fo...
10 min læsning
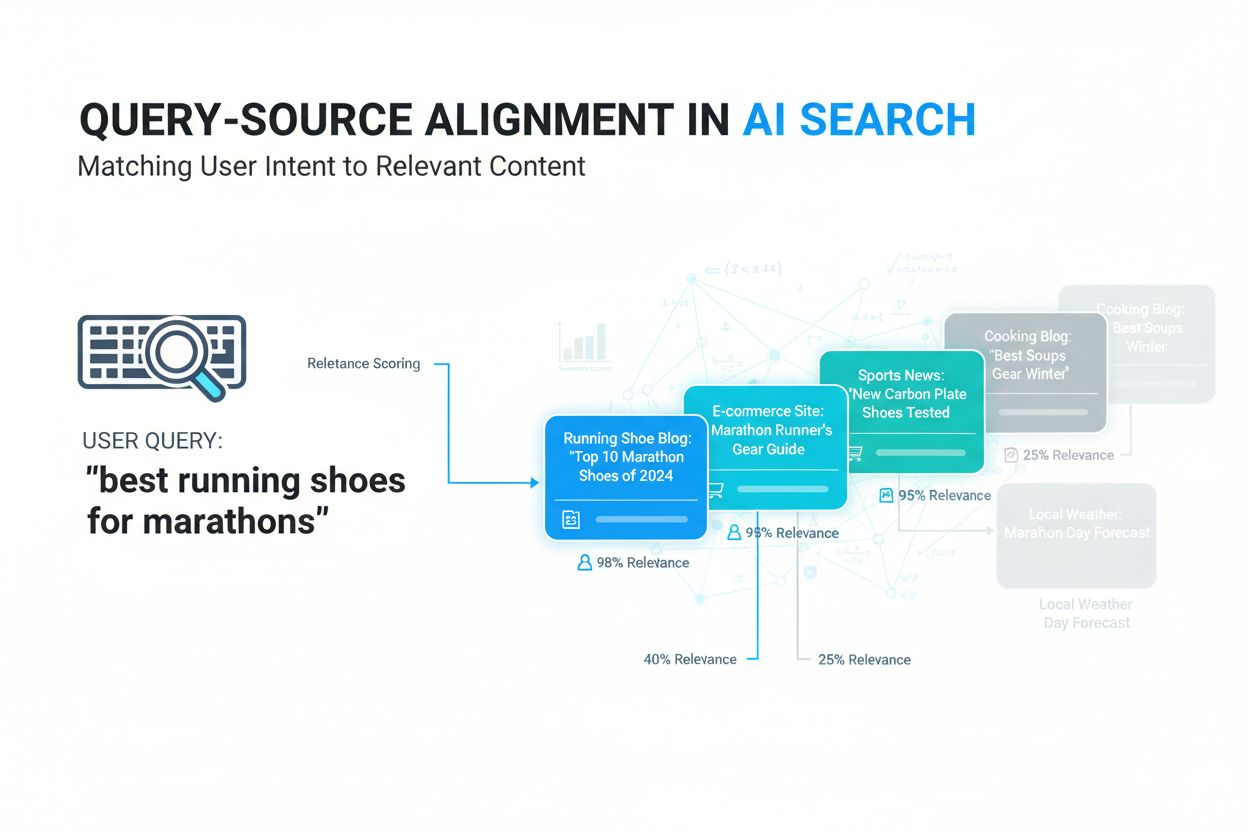
Forespørgsels-kilde justering er processen med at matche brugersøgeforespørgsler med de mest relevante informationskilder baseret på semantisk betydning og kontekstuel relevans. Det bruger AI og maskinlæring til at forstå intentionen bag forespørgsler og forbinde dem til kilder, der reelt dækker brugerens informationsbehov, frem for blot at stole på simpel nøgleords-matchning. Denne teknologi er grundlæggende for moderne AI-søgesystemer som Google AI Overviews, ChatGPT og Perplexity. Effektiv justering sikrer, at AI-systemer returnerer nøjagtige, relevante resultater, der forbedrer brugertilfredshed og synlighed af indhold.
Forespørgsels-kilde justering er processen med at matche brugersøgeforespørgsler med de mest relevante informationskilder baseret på semantisk betydning og kontekstuel relevans. Det bruger AI og maskinlæring til at forstå intentionen bag forespørgsler og forbinde dem til kilder, der reelt dækker brugerens informationsbehov, frem for blot at stole på simpel nøgleords-matchning. Denne teknologi er grundlæggende for moderne AI-søgesystemer som Google AI Overviews, ChatGPT og Perplexity. Effektiv justering sikrer, at AI-systemer returnerer nøjagtige, relevante resultater, der forbedrer brugertilfredshed og synlighed af indhold.
Forespørgsels-kilde justering henviser til processen med at matche brugersøgeforespørgsler med de mest relevante informationskilder baseret på semantisk betydning og kontekstuel relevans frem for simpel nøgleordsoverlap. I sin kerne adresserer dette koncept en grundlæggende udfordring inden for informationssøgning: at sikre, at når brugere søger information, modtager de ikke bare teknisk relaterede resultater til deres søgetermer, men at resultaterne reelt dækker deres underliggende informationsbehov.
Traditionelt har søgesystemer været afhængige af nøgleords-matchning – at finde dokumenter, der indeholder de præcise ord eller fraser, som en bruger har indtastet. Selvom denne tilgang er ligetil, gav den ofte irrelevante resultater, fordi den ignorerede kontekst, intention og den dybere betydning bag forespørgsler. Forespørgsels-kilde justering løser dette problem ved at anvende semantiske matchningsteknikker, der forstår det konceptuelle forhold mellem det, brugeren spørger om, og hvad informationskilder indeholder. Det betyder, at en søgning på “køretøjsvedligeholdelse” effektivt kan finde artikler om “bilpleje” eller “bilservice”, selv uden præcis nøgleords-match.
I konteksten af moderne AI-søgesystemer er forespørgsels-kilde justering blevet stadig vigtigere, efterhånden som kunstig intelligens muliggør mere sofistikeret forståelse af sprogets nuancer og brugerintentioner. I stedet for at behandle forespørgsler som blot samlinger af ord, analyserer AI-drevne justeringssystemer det semantiske indhold af både brugerens spørgsmål og tilgængelige kilder og skaber meningsfulde forbindelser baseret på relevans fremfor overfladisk lighed.
Denne forskel har væsentlig betydning, fordi det direkte påvirker søgekvalitet og brugertilfredshed. Effektiv forespørgsels-kilde justering sikrer, at informationssøgningssystemer returnerer resultater, der reelt besvarer brugerens spørgsmål, reducerer irrelevant støj i søgeresultaterne og hjælper brugere med at opdage information, de måske ikke ville have fundet via traditionelle nøgleordsbaserede metoder. Efterhånden som AI-søgeteknologi fortsætter med at udvikle sig, forbliver forespørgsels-kilde justering et grundlæggende princip for at opbygge systemer, der virkelig forstår og imødekommer brugeres informationsbehov.
Den tekniske proces for forespørgsels-kilde justering involverer flere avancerede trin, der omdanner brugerforespørgsler til meningsfulde forbindelser med relevante kilder:
Forespørgselsbehandling og tokenisering – Når en bruger indsender en søgeforespørgsel, opdeler systemet den først i individuelle tokens (ord og fraser) og analyserer den grammatiske struktur. Algoritmer til naturlig sprogbehandling identificerer de centrale koncepter, entiteter og intentionen bag forespørgslen, fjerner stopord og identificerer de mest meningsfulde komponenter, der skal lede justeringsprocessen.
Forespørgsels-embedding-generering – Den behandlede forespørgsel konverteres til en semantisk vektor—en matematisk repræsentation, der fanger betydningen og konteksten af forespørgslen i et multidimensionalt rum. Denne embedding skabes ved hjælp af neurale sprogmodeller trænet på store mængder tekstdata, hvilket gør systemet i stand til at repræsentere forespørgslens semantiske kerne frem for blot dens ordlyd.
Vektorisering af kildedokumenter – Samtidig konverteres alle tilgængelige kildedokumenter i systemet til semantiske vektorer ved hjælp af den samme embeddingmodel. Dette sikrer, at både forespørgsler og kilder er repræsenteret i det samme semantiske rum, så direkte sammenligning er mulig. Hver dokuments vektor fanger dets overordnede betydning, emner og relevanssignaler.
Vektorligningsberegninger – Systemet beregner ligheden mellem forespørgselsvektoren og hver kildedokuments vektor ved hjælp af matematiske afstandsmål, oftest cosinus-lighed. Denne beregning afgør, hvor tæt den semantiske betydning af hver kilde stemmer overens med forespørgslens semantiske betydning, og giver en lighedsscore mellem 0 og 1.
Relevansscoring og rangering – Ud over semantisk lighed anvender systemet yderligere rangeringsfaktorer, herunder domæneautoritet, indholdsaktualitet, brugerengagement og emnerelevans. Disse faktorer kombineres med semantiske lighedsscorer for at danne en samlet relevansscore for hver kilde, hvilket afgør dens placering i de rangerede resultater.
Validering af indholdsmatch – Systemet validerer, at de udvalgte kilder faktisk indeholder relevant information ved at analysere specifikke sektioner af indholdet. Dette sikrer, at kilder ikke rangeres højt blot fordi de nævner relevante nøgleord, men fordi de reelt dækker brugerens informationsbehov med substantielt, korrekt indhold.
Endelig kildeudvælgelse og rangering – De højest rangerede kilder udvælges til præsentation for brugeren eller til citation i AI-genererede svar. Den endelige rangering afspejler den samlede vurdering af semantisk justering, autoritet, relevans og indholdskvalitet, så brugeren får de mest passende kilder til deres specifikke forespørgsel.
| Metode/Tilgang | Sådan fungerer det | Fordele | Ulemper | Bedst til |
|---|---|---|---|---|
| Nøgleords-matchning (traditionel) | Søger efter præcise ord eller fraser i dokumenter; rangerer efter hyppighed og placering | Nem at implementere; hurtig behandling; gennemsigtig matchlogik | Ignorerer kontekst og intention; giver irrelevante resultater; fejler ved synonymer | Enkle, faktuelle forespørgsler; legacy-systemer |
| Semantisk lighed (vektorbaseret) | Konverterer forespørgsler og dokumenter til semantiske vektorer; beregner lighed via matematiske afstandsmål | Forstår betydning ud over nøgleord; håndterer synonymer og kontekst; meget præcis | Beregningsmæssigt tung; kræver store træningsdatamængder; mindre gennemsigtig | Komplekse forespørgsler; intention-drevet søgning; moderne AI-systemer |
| Entitetsgenkendelse | Identificerer og klassificerer nøgleentiteter (personer, steder, organisationer, produkter) i forespørgsler og indhold | Forbedrer forståelse af specifikke emner; afklarer begreber; muliggør knowledge graph-integration | Kræver omfattende entitetsdatabaser; svært ved nye/niche entiteter | Forespørgsler om specifikke entiteter; videnbaseret søgning |
| Kontekstuel forståelse | Analyserer omkringliggende kontekst, brugerhistorik og forespørgselsmønstre for at udlede betydning | Opfanger nuanceret intention; personaliserer resultater; forbedrer præcision ved tvetydige forespørgsler | Privatlivsproblemer ved brugerdata; kræver historiske data; kompleks implementering | Samtalesøgning; personlige anbefalinger |
| Hybrid tilgang | Kombinerer flere metoder (semantisk lighed, entitetsgenkendelse, kontekstforståelse) til omfattende match | Udnytter styrker ved flere metoder; mere robust og præcis; håndterer alsidige forespørgsler | Kompleks at implementere og vedligeholde; højere beregningsomkostninger; sværere at fejlfinde | Enterprise-søgning; AI-søgeplatforme |
| Knowledge graph-baseret | Bruger sammenkædede entiteter og relationer til at forstå forespørgsler og matche relevante kilder | Fanger virkelige relationer; muliggør avanceret ræsonnement; understøtter komplekse forespørgsler | Kræver omfattende knowledge graph-opbygning; vedligeholdelseskrævende; domænespecifik | Komplekse forskningsforespørgsler; semantiske webapplikationer |
Forespørgsels-kilde justering er fundamentalt for, hvordan moderne AI-søgesystemer fungerer og vælger kilder til deres svar:
Google AI Overviews – Bruger forespørgsels-kilde justering til at udvælge de mest relevante kilder, der skal citeres, når AI-baserede søgeopsummeringer genereres. Systemet analyserer semantisk justering mellem brugerens forespørgsel og tilgængelige websider og prioriterer kilder med stærk semantisk relevans og høj autoritet. Forskning viser, at cirka 70% af kilderne i AI Overviews kommer fra de øverste 10 organiske søgeresultater, hvilket indikerer at traditionel rangering og semantisk justering arbejder sammen.
ChatGPT med browsing – Når ChatGPTs browsing-funktion er aktiveret, bruger den forespørgsels-kilde justering til at identificere og hente de mest relevante websider for at besvare brugerens spørgsmål. Systemet prioriterer autoritative kilder med stærk semantisk justering til forespørgslen, så de genererede svar er forankret i pålidelig, relevant information fra nettet.
Perplexity AI – Implementerer forespørgsels-kilde justering til at vælge kilder til sine samtalesvar. Platformen viser citerede kilder sammen med svarene, hvilket gør justeringsprocessen gennemsigtig for brugerne. Stærk semantisk justering mellem forespørgsler og kilder sikrer, at Perplexitys svar er velunderbyggede og verificerbare.
Bing AI Chat – Udnytter forespørgsels-kilde justering til at integrere søgeresultater i samtalesvar. Systemet matcher brugerforespørgsler til relevante Bing-søgeresultater via semantisk forståelse og syntetiserer information fra flere justerede kilder i sammenhængende svar.
Kernekilde-konceptet – AI-systemer identificerer “kernekilder”—URL’er, der konsekvent optræder på tværs af flere svar for beslægtede forespørgsler. Disse kilder har exceptionelt stærk semantisk justering med emnerne og anses for meget autoritative. At blive kernekilde for din niche er et vigtigt mål for indholdssynlighed i AI-søgning.
Semantisk relevansscoring – AI-platforme tildeler relevansscore baseret på, hvor godt kildeindhold semantisk matcher forespørgselsintention. Kilder med højere semantisk justeringsscore bliver oftere udvalgt, citeret og fremhævet i AI-genererede svar.
Multi-forespørgsels-justering – Når AI-systemer genererer svar, opdeler de ofte brugerforespørgsler i flere underforespørgsler (fan-out forespørgsler). Forespørgsels-kilde justering anvendes på hver underforespørgsel, og kilder, der matcher flere beslægtede forespørgsler godt, prioriteres, hvilket skaber mere omfattende og veldokumenterede svar.
AmICited-overvågning – AmICited sporer forespørgsels-kilde justering ved at overvåge, hvilke af dine sider der vælges som kilder til specifikke forespørgsler på tværs af AI-platforme. Platformen viser dine semantiske justeringsscore, sporer kernekilde-status og identificerer muligheder for at forbedre justering med værdifulde forespørgsler i din niche.
Autoritet og semantisk balance – Selvom domæneautoritet stadig er vigtig, viser forskning, at semantisk justering bliver stadig mere afgørende. Kilder med stærk semantisk justering men moderat autoritet kan overgå kilder med høj autoritet men svag semantisk justering, hvilket viser, at betydning er lige så vigtig som ry.
Sporing af justering i realtid – Moderne AI-overvågningsplatforme sporer, hvordan forespørgsels-kilde justering ændrer sig over tid, efterhånden som indhold opdateres og nye kilder dukker op. Dette gør det muligt for marketingfolk at forstå, hvilke indholdsopdateringer, der forbedrer justering, og hvilke forespørgsler, der repræsenterer de bedste muligheder for synlighed.
At forstå og optimere forespørgsels-kilde justering er blevet essentielt for indholdsskabere, marketingfolk og brands i AI-søgnings tidsalder:
Brand-citatsporing – Forespørgsels-kilde justering afgør direkte, om dit brand og indhold citeres i AI-genererede svar. Platforme som AmICited overvåger denne justering og viser, hvilke forespørgsler dit indhold rangerer for i AI-svar, og hvor ofte dit brand nævnes på tværs af AI-søgeplatforme.
Semantisk relevans og opdagelse – Stærk semantisk justering med brugerforespørgsler øger sandsynligheden for, at dit indhold bliver opdaget og citeret af AI-systemer. Dette er især vigtigt for long-tail forespørgsler og nicheemner, hvor traditionel SEO-konkurrence kan være lavere, men semantisk relevans kritisk.
Konkurrencefordel i AI-søgning – Efterhånden som AI-søgning bliver mere udbredt, opnår brands med stærk forespørgsels-kilde justering for værdifulde forespørgsler betydelige konkurrencefordele. Tidlig optimering for semantisk justering sikrer, at dit indhold fanger synlighed før konkurrenterne tilpasser deres strategier.
Kildesporing og attribution – At forstå forespørgsels-kilde justering hjælper dig med at spore, hvilke af dine sider der udvælges som kilder til specifikke forespørgsler. Denne attributionsdata afslører, hvilket indhold der performer bedst i AI-svar, og hvilke emner der er muligheder for forbedring.
Optimering for AI-svar – I stedet for kun at optimere til traditionelle søgerangeringer skal moderne indholdsstrategi tage højde for forespørgsels-kilde justering. Indhold, der rangerer godt i traditionel søgning, men har svag semantisk justering, kan blive fravalgt af AI-systemer og gå glip af synlighed.
Risikominimering og brandkontrol – Overvågning af forespørgsels-kilde justering hjælper dig med at forstå, hvordan dit brand præsenteres i AI-svar. Hvis konkurrenters indhold har stærkere justering på vigtige forespørgsler, kan du identificere huller og skabe indhold, der bedre adresserer brugerintention.
Finjustering af indholdsstrategi – Forespørgsels-kilde justeringsmålinger afslører, hvilke emner, nøgleord og indholdsformater, der resonerer stærkest med AI-systemer. Disse data styrer indholdsstrategien og hjælper dig med at fokusere på emner, hvor semantisk justering er opnåelig og værdifuld.
Konkurrenceanalyse – Ved at analysere forespørgsels-kilde justering i din branche kan du identificere, hvilke konkurrenters indhold der oftest citeres i AI-svar. Denne konkurrenceanalyse afslører huller i din indholdsstrategi og muligheder for at opnå synlighed.
Langsigtet synlighedsplanlægning – Forespørgsels-kilde justering er mere stabil end traditionelle søgerangeringer, fordi den er baseret på semantisk betydning frem for algoritmiske faktorer, der ofte ændres. Stærk semantisk justering giver mere holdbar synlighed i AI-søgning over tid.
Målbar ROI på indholdsinvestering – Sporing af forespørgsels-kilde justering og resulterende synlighed i AI-svar giver klare målinger for indholds-ROI. Du kan direkte se, hvordan indholdsindsats omsættes til brandciteringer og trafik fra AI-søgeplatforme.
Optimering til forespørgsels-kilde justering kræver en strategisk tilgang, der rækker ud over traditionel SEO. Målet er at sikre, at dit indhold har stærk semantisk justering med de forespørgsler, din målgruppe bruger, så det er mere sandsynligt, at AI-systemer udvælger det som relevant kilde.
Forståelse af semantisk optimering – Semantisk optimering handler om at sikre, at dit indhold grundigt adresserer specifikke brugerintentioner og spørgsmål, ikke blot at rangere på nøgleord. Dette indebærer at forstå de semantiske relationer mellem koncepter, bruge konsekvent terminologi og strukturere indholdet, så det tydeligt kommunikerer betydning både til mennesker og AI-systemer.
Best practices for forespørgsels-kilde justering:
Udfør semantisk søgeordsanalyse – Gå ud over traditionel søgeordsanalyse og identificér semantiske klynger af relaterede termer og koncepter. Brug værktøjer som SEMrush eller Ahrefs til ikke kun at finde søgeord med høj volumen, men også semantiske variationer og relaterede forespørgsler, der dækker samme brugerintention. Gruper disse i semantiske klynger og lav omfattende indhold, der dækker alle variationer.
Implementér semantisk HTML5-markup – Brug semantiske HTML5-elementer som <article>, <section>, <header>, <nav> og <main> til klart at strukturere dit indhold. Disse elementer hjælper AI-systemer med at forstå organisationen og hierarkiet i dit indhold og forbedrer semantisk fortolkning. Brug overskrifts-tags (<h1>, <h2>, etc.) hierarkisk for at etablere tydelige emnerelationer.
Skab entitetsrigt indhold – Identificér nøgleentiteter (personer, organisationer, produkter, begreber), der er relevante for dit emne, og nævn dem eksplicit i dit indhold. Brug konsekvent terminologi og giv kontekst, der hjælper AI-systemer med at forstå, hvilke entiteter du omhandler. For eksempel, hvis du skriver om “Apple”, så tydeliggør via kontekst, om du mener teknologivirksomheden eller frugten.
Brug strukturerede data (JSON-LD) – Implementér schema.org-markup via JSON-LD-format for eksplicit at give semantisk information om dit indhold. Brug passende schema-typer som Article, NewsArticle, HowTo, FAQPage eller Product afhængig af indholdstype. Dette hjælper AI-systemer med at forstå præcist, hvad dit indhold handler om, og hvordan det relaterer til brugerforespørgsler.
Optimer for variations i søgeintention – Identificér de forskellige måder, brugere udtrykker det samme informationsbehov, og skab indhold, der adresserer alle variationer. For eksempel kan brugere søge på “hvordan fikser man en dryppende hane”, “reparationsguide til vandhane” eller “løsning på dryppende vandhane”. Lav omfattende indhold, der dækker alle disse intentionsvariationer med konsekvent semantisk betydning.
Udvikl omfattende emnedækning – I stedet for at lave flere overfladiske artikler om beslægtede emner, lav omfattende guides, der grundigt dækker specifikke emner. AI-systemer foretrækker dybdegående indhold, der giver komplette svar på brugerens spørgsmål. Brug emneklynger for at sikre, at dit indhold dækker alle aspekter af et emne med stærke semantiske relationer mellem sektionerne.
Oprethold konsekvent terminologi – Brug konsekvent sprog og terminologi gennem hele dit indhold og på tværs af dit website. Hvis du introducerer et koncept med en bestemt betegnelse, så brug samme betegnelse konsekvent frem for at veksle mellem synonymer. Denne konsistens hjælper AI-systemer med at genkende, at du diskuterer de samme koncepter hele vejen igennem.
Skab klare indholdshierarkier – Strukturér dit indhold med klare hierarkier, der viser, hvordan koncepter relaterer til hinanden. Brug overskrifts-tags, punktopstillinger og nummererede lister til at skabe relationer mellem ideer. Denne struktur hjælper AI-systemer med at forstå den semantiske organisation af dit indhold og hvordan forskellige koncepter hænger sammen.
Optimer metabeskrivelser og titler – Skriv metabeskrivelser og sidetitler, der klart kommunikerer det semantiske indhold på din side. Disse elementer bruges ofte af AI-systemer til at forstå sideindhold, så sørg for, at de nøjagtigt afspejler sidens hovedemne og nøglekoncepter. Inkludér relevante entiteter og begreber i titler og beskrivelser.
Overvåg semantiske justeringsscore – Brug AI-overvågningsplatforme som AmICited til at følge dine semantiske justeringsscore for vigtige forespørgsler. Overvåg, hvordan din justering ændres, når du opdaterer indholdet, og identificér hvilke opdateringer, der forbedrer justeringen. Følg, hvilke forespørgsler der har stærkest justering, og fokuser på at udbygge indholdet i disse områder.
Virkelige eksempler på tværs af brancher:
E-handel – En onlineforhandler, der sælger løbesko, kan optimere for forespørgsels-kilde justering ved at lave omfattende guides om “maratontræningssko”, “bedste løbesko til forskellige fodtyper” og “sammenligning af sko-teknologi”. Ved at adressere semantiske variationer af brugerintention og bruge konsekvent terminologi om skofunktioner øger forhandleren sandsynligheden for at blive udvalgt som kilde i AI-svar om løbesko.
Sundhedssektoren – En lægepraksis kan forbedre forespørgsels-kilde justering ved at lave detaljeret indhold om specifikke sygdomme, behandlinger og behandlere. Ved at bruge korrekt medicinsk terminologi, entitetsgenkendelse for tilstande og behandlinger samt struktureret datamarkup hjælper det AI-systemer med at forstå det semantiske indhold og matche det til relevante sundhedsforespørgsler.
Teknologi – Et softwarefirma kan optimere justering ved at skabe omfattende dokumentation og guides, der adresserer semantiske variationer af brugerproblemer. Ved at bruge konsekvent terminologi for funktioner, klare konceptuelle hierarkier og strukturerede data kan AI-systemer genkende indholdet som relevant kilde til teknologirelaterede forespørgsler.
Traditionel nøgleords-matchning leder blot efter præcise ord eller fraser i dokumenter, mens forespørgsels-kilde justering bruger semantisk forståelse til at matche betydning og intention bag forespørgsler. Det betyder, at en søgning på 'køretøjsvedligeholdelse' kan finde artikler om 'bilpleje' uden præcis nøgleords-match. Forespørgsels-kilde justering giver mere relevante resultater, fordi den forstår kontekst og brugerintention frem for blot overfladisk ordlighed.
AI-søgeplatforme bruger forespørgsels-kilde justering til at vælge de mest relevante kilder at citere i deres genererede svar. Systemet analyserer både den semantiske betydning af brugerens forespørgsel og indholdet i tilgængelige kilder og rangerer derefter kilder baseret på relevans, autoritet og semantisk justering. Dette sikrer, at AI-genererede svar er forankret i høj-kvalitets, relevante kilder, der reelt dækker brugerens informationsbehov.
Forespørgsels-kilde justering har direkte indflydelse på, om dit indhold bliver udvalgt som kilde i AI-genererede svar. Hvis dit indhold har stærk semantisk justering med almindelige forespørgsler inden for din niche, er det mere sandsynligt, at det bliver citeret af AI-systemer. Denne synlighed i AI-svar driver trafik og opbygger brandautoritet. At forstå og optimere for forespørgsels-kilde justering er essentielt for at bevare synlighed i AI-søgnings tidsalder.
For at optimere for forespørgsels-kilde justering skal du fokusere på at skabe indhold, der grundigt besvarer specifikke brugerintentioner og spørgsmål. Brug semantisk HTML-markup, implementér strukturerede data (JSON-LD), sikr tydelig entitetsgenkendelse, og brug konsekvent terminologi. Skriv omfattende, løsningsorienteret indhold, der grundigt besvarer spørgsmål. Overvåg dine semantiske justeringsscore og følg, hvordan dit indhold klarer sig i AI-svar med værktøjer som AmICited.
Semantisk lighed er den centrale mekanisme i forespørgsels-kilde justering. Den måler, hvor tæt betydningen af en forespørgsel matcher betydningen af indhold i kilder. Dette beregnes ved hjælp af vektorindlejring—matematiske repræsentationer af tekst, der indfanger semantisk mening. Kilder med højere semantisk lighedsscore med forespørgslen rangeres højere og er mere tilbøjelige til at blive udvalgt af AI-systemer som relevante kilder til at besvare brugerens spørgsmål.
AmICited er en AI-overvågningsplatform, der følger hvordan dit brand og indhold citeres på tværs af AI-søgeplatforme. Den overvåger forespørgsels-kilde justering ved at vise, hvilke af dine sider der udvælges som kilder til specifikke forespørgsler, hvor ofte dit brand nævnes i AI-svar, og hvordan din semantiske justering sammenlignes med konkurrenter. Disse data hjælper dig med at forstå og optimere din indholdsstrategi for bedre synlighed i AI-søgning.
Kernekilder er URL'er, der konsekvent optræder på tværs af flere AI-genererede svar for samme eller beslægtede forespørgsler. Disse kilder har stærk semantisk justering med forespørgselsemner og anses for at være meget relevante af AI-systemer. Kernekilder rangerer typisk højere i traditionelle søgeresultater og har bedre semantisk justering med forespørgselsintention. At blive en kernekilde for dine nicheforespørgsler er et centralt mål for indholdssynlighed i AI-søgning.
Entitetsgenkendelse hjælper AI-systemer med at identificere og forstå nøglebegreber, personer, organisationer og emner i både forespørgsler og kildeindhold. Ved at genkende entiteter kan AI-systemer bedre forstå, hvad en forespørgsel egentlig handler om, og matche den til kilder, der behandler de samme entiteter i relevante kontekster. For eksempel hjælper det at genkende, at 'Apple' henviser til teknologivirksomheden og ikke frugten, med at matche forespørgsler om Apple-produkter med relevante teknologikilder.
Følg hvordan dit indhold citeres på tværs af AI-søgeplatforme og optimer for bedre forespørgsels-kilde justering med AmICiteds AI-overvågningsplatform.
Lær hvordan forespørgselsreformulering hjælper AI-systemer med at fortolke og forbedre brugerforespørgsler for bedre informationssøgning. Forstå teknikkerne, fo...

Lær hvad informationssøgningsintention betyder for AI-systemer, hvordan AI genkender disse forespørgsler, og hvorfor forståelse af denne intention er vigtig for...

Lær hvordan semantisk forespørgselsmatching gør det muligt for AI-systemer at forstå brugerhensigt og levere relevante resultater ud over nøgleordsmatching. Udf...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.