Sonar-algoritmen i Perplexity: Realtids-søgemodel forklaret
Lær hvordan Perplexitys Sonar-algoritme driver AI-søgning i realtid med omkostningseffektive modeller. Udforsk varianterne Sonar, Sonar Pro og Sonar Reasoning....
8 min læsning
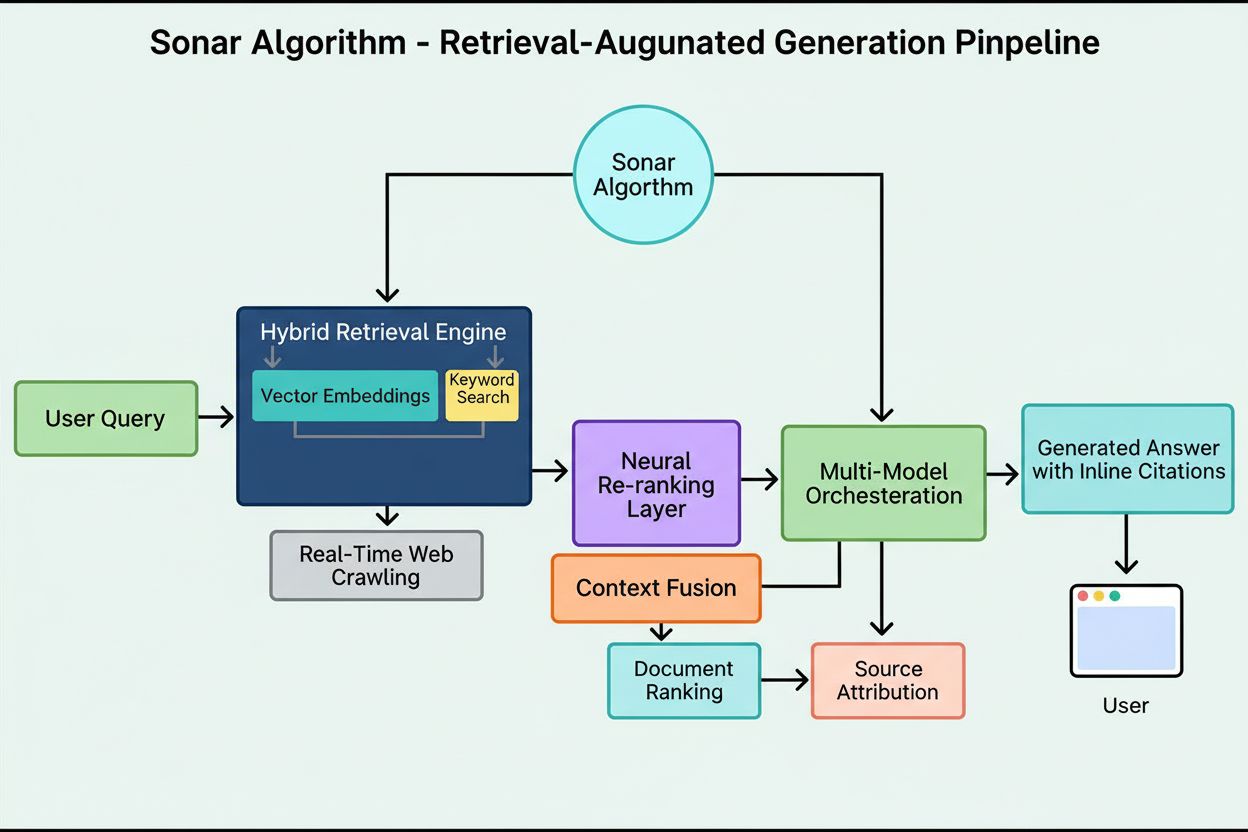
Sonar-algoritmen er Perplexitys proprietære retrieval-augmented generation (RAG) rangeringssystem, der kombinerer hybrid semantisk og nøgleordsøgning med neuralt gen-rangering for at hente, rangere og citere websider i realtid i AI-genererede svar. Den prioriterer indholdsaktualitet, semantisk relevans og citerbarhed for at levere velunderbyggede, kildebaserede svar og samtidig minimere hallucinationer.
Sonar-algoritmen er Perplexitys proprietære retrieval-augmented generation (RAG) rangeringssystem, der kombinerer hybrid semantisk og nøgleordsøgning med neuralt gen-rangering for at hente, rangere og citere websider i realtid i AI-genererede svar. Den prioriterer indholdsaktualitet, semantisk relevans og citerbarhed for at levere velunderbyggede, kildebaserede svar og samtidig minimere hallucinationer.
Sonar-algoritmen er Perplexitys proprietære retrieval-augmented generation (RAG) rangeringssystem, der driver deres svarmotor ved at kombinere hybrid semantisk og nøgleordsøgning, neuralt gen-rangering og realtids-generering af citater. I modsætning til traditionelle søgemaskiner, der rangerer sider til visning i en resultatliste, rangerer Sonar indholdssnippets til syntese i et enkelt, samlet svar med indlejrede kildehenvisninger. Algoritmen prioriterer indholdsaktualitet, semantisk relevans og citerbarhed for at levere velunderbyggede, kildebaserede svar og minimere hallucinationer. Sonar repræsenterer et grundlæggende skifte i, hvordan AI-systemer henter og rangerer information—fra linkbaserede autoritetssignaler til svarfokuserede nytte-metrikker, der understreger, om indholdet direkte opfylder brugerens hensigt og nemt kan citeres i syntetiserede svar. Denne sondring er afgørende for at forstå, hvordan synlighed i AI-svarmotorer adskiller sig fra traditionel SEO, da Sonar vurderer indholdet ikke for dets evne til at rangere i en liste, men for dets evne til at blive udtrukket, syntetiseret og tilskrevet i et AI-genereret svar.
Fremkomsten af Sonar-algoritmen afspejler et bredere brancheskrift mod retrieval-augmented generation som den dominerende arkitektur for AI-svarmotorer. Da Perplexity blev lanceret i slutningen af 2022, identificerede virksomheden et kritisk hul i AI-landskabet: Mens ChatGPT tilbød stærke konversationsmuligheder, manglede den adgang til realtidsinformation og kildeangivelse, hvilket førte til hallucinationer og forældede svar. Perplexitys stifterteam, som oprindeligt arbejdede på et databaseforespørgsels-oversættelsesværktøj, skiftede fuldt fokus til at bygge en svarmotor, der kunne kombinere live web-søgning med LLM-syntese. Denne strategiske beslutning formede Sonars arkitektur fra begyndelsen—algoritmen blev konstrueret ikke til at rangere sider for menneskelig browsing, men til at hente og rangere indholdsfragmenter til maskinsyntese og citation. I løbet af de seneste to år har Sonar udviklet sig til et af de mest sofistikerede rangeringssystemer i AI-økosystemet, hvor Perplexitys Sonar-modeller indtager pladserne 1 til 4 i Search Arena Evaluation, hvilket klart overgår konkurrerende modeller fra Google og OpenAI. Algoritmen behandler nu over 400 millioner søgeforespørgsler om måneden, indekserer over 200 milliarder unikke URL’er og opretholder realtidsaktualitet gennem titusindvis af indeksopdateringer pr. sekund. Denne skala og sofistikation understreger Sonars betydning som et definerende rangeringsparadigme i AI-søgealderen.
Sonars rangeringssystem fungerer gennem en omhyggeligt orkestreret femtrins retrieval-augmented generation pipeline, der omdanner brugerforespørgsler til velunderbyggede, citerede svar. Første trin, forespørgselsintent-fortolkning, bruger en LLM til at gå ud over simpel nøgleords-match og opnå semantisk forståelse af, hvad brugeren faktisk spørger om, inklusive kontekst, nuancer og underliggende hensigt. Andet trin, live webhentning, sender den fortolkede forespørgsel til Perplexitys massive distribuerede indeks drevet af Vespa AI, som i realtid gennemsøger nettet efter relevante sider og dokumenter. Dette retrieval-system kombinerer tæt retrieval (vektorsøgning med semantiske embeddings) og sparsom retrieval (leksikal/nøgleordsbaseret søgning), og fusionerer resultater for at frembringe cirka 50 forskellige kandidatdokumenter. Tredje trin, snippet-udtrækning og kontekstualisering, sender ikke hele sidens tekst til den generative model; i stedet udtrækker algoritmer de mest relevante snippets, afsnit eller chunks, der omhandler forespørgslen, og samler dem i et fokuseret kontekstvindue. Fjerde trin, syntetiseret svargenerering med citater, sender denne kuraterede kontekst til en valgt LLM (fra Perplexitys proprietære Sonar-familie eller tredjepartsmodeller som GPT-4 eller Claude), som genererer et naturligt sprogligt svar udelukkende baseret på det hentede materiale. Afgørende er det, at indlejrede citater linker hver påstand tilbage til kildedokumenter, hvilket sikrer gennemsigtighed og muliggør verifikation. Femte trin, konversationel forfining, opretholder samtalekontekst over flere omgange, så opfølgende spørgsmål kan forfine svar via iterativ webhentning. Pipeline’ens definerende princip—“du må ikke sige noget, du ikke har hentet”—sikrer, at Sonar-drevne svar er forankret i verificerbare kilder og grundlæggende reducerer hallucinationer sammenlignet med modeller, der udelukkende bygger på træningsdata.
| Aspekt | Traditionel søgning (Google) | Sonar-algoritme (Perplexity) | ChatGPT-rangering | Gemini-rangering | Claude-rangering |
|---|---|---|---|---|---|
| Primær enhed | Rangeret liste af links | Enkelt syntetiseret svar med citater | Konsensusbaserede entitetsomtaler | E-E-A-T-justeret indhold | Neutrale, faktabaserede kilder |
| Retrieval-fokus | Nøgleord, links, ML-signaler | Hybrid semantisk + nøgleordssøgning | Træningsdata + web-browsing | Knowledge graph-integration | Konstitutionelle sikkerhedsfiltre |
| Aktualitetsprioritet | Query-deserves-freshness (QDF) | Realtids-webhentning, 37% boost inden for 48 timer | Lavere prioritet, afhængig af træningsdata | Moderat, integreret med Google Search | Lavere prioritet, fokus på stabilitet |
| Rangeringssignaler | Backlinks, domæneautoritet, CTR | Indholdsaktualitet, semantisk relevans, citerbarhed, autoritetsboost | Entitetsgenkendelse, konsensusomtaler | E-E-A-T, konversationel tilpasning, strukturerede data | Gennemsigtighed, verificerbare citater, neutralitet |
| Citationsmekanisme | URL-snippets i resultater | Indlejrede citater med kilde-links | Implicit, ofte ingen citater | AI Overviews med attribution | Eksplicit kildeangivelse |
| Indholdsdiversitet | Flere resultater på tværs af sider | Udvalgte få kilder til syntese | Syntetiseret fra flere kilder | Flere kilder i overblik | Balancerede, neutrale kilder |
| Personalisering | Subtil, mest implicit | Eksplicitke fokus-modes (Web, Akademisk, Finans, Skrivning, Social) | Implicit baseret på samtale | Implicit baseret på forespørgselstype | Minimal, fokus på konsistens |
| PDF-håndtering | Standardindeksering | 22% citeringsfordel over HTML | Standardindeksering | Standardindeksering | Standardindeksering |
| Schema markup-indflydelse | FAQ-schema i featured snippets | FAQ-schema øger citater 41%, reducerer tid-til-citation med 6 timer | Minimal direkte effekt | Moderat effekt på knowledge graph | Minimal direkte effekt |
| Latency-optimering | Millisekunder til rangering | Under sekund til retrieval + generering | Sekunder til syntese | Sekunder til syntese | Sekunder til syntese |
Det tekniske fundament for Sonar-algoritmen hviler på en hybrid retrieval-motor, der kombinerer flere søgestrategier for at maksimere både recall og præcision. Tæt retrieval (vektorsøgning) bruger semantiske embeddings til at forstå den konceptuelle betydning bag forespørgsler og finde kontekstuelt lignende dokumenter, selv uden præcise nøgleords-match. Denne tilgang udnytter transformerbaserede embeddings, der placerer forespørgsler og dokumenter i højdimensionelle vektorrum, hvor semantisk beslægtet indhold grupperes. Sparsom retrieval (leksikal søgning) supplerer tæt retrieval ved at levere præcision for sjældne termer, produktnavne, interne virksomhedsid’er og specifikke entiteter, hvor semantisk tvetydighed er uønsket. Systemet bruger rangeringsfunktioner som BM25 til at matche disse kritiske termer præcist. Disse to retrieval-metoder sammensmeltes og deduplikeres til cirka 50 forskellige kandidatdokumenter, hvilket forhindrer overfitting på domæner og sikrer bred dækning på tværs af flere autoritative kilder. Efter den indledende retrieval anvender Sonars neurale gen-rangeringslag avancerede maskinlæringsmodeller (såsom DeBERTa-v3 cross-encoders) til at evaluere kandidater ved hjælp af et rigt feature-set, herunder leksikale relevans-score, vektorsimilaritet, dokumentautoritet, aktualitetssignaler, brugerengagement og metadata. Denne flerfase-arkitektur gør det muligt for Sonar løbende at forfine resultater under stramme latency-krav, så det endelige rangerede sæt repræsenterer de mest relevante og højeste kvalitetskilder til syntese. Hele retrieval-infrastrukturen er bygget på Vespa AI, en distribueret søgeplatform, der kan håndtere indeksering i webskala (200+ milliarder URL’er), realtidsopdateringer (titusindvis pr. sekund) og detaljeret indholdsforståelse gennem dokument-chunking. Dette arkitekturvalg gør det muligt for Perplexitys relativt lille ingeniørteam at fokusere på differentierende komponenter—RAG-orkestrering, Sonar-modelfintuning og inferensoptimering—fremfor at genopfinde distribueret søgning fra bunden.
Indholdsaktualitet er et af Sonars stærkeste rangeringssignaler, og empirisk forskning viser, at nyligt opdaterede sider får markant højere citeringsrater. I kontrollerede A/B-tests udført over 24 uger på tværs af 120 URL’er blev artikler, der var opdateret inden for de seneste 48 timer, citeret 37% oftere end identisk indhold med ældre tidsstempler. Denne fordel fortsatte på cirka 14% efter to uger, hvilket indikerer, at aktualitet giver et vedvarende, men gradvist aftagende boost. Mekanismen bag denne prioritering er forankret i Sonars designfilosofi: Algoritmen betragter forældet indhold som en større hallucinationsrisiko og antager, at forældet information kan være overhalet af nyere udviklinger. Perplexitys infrastruktur behandler titusindvis af indeksopdateringsanmodninger pr. sekund, hvilket muliggør realtidsaktualitets-signaler. En ML-model forudsiger, om en URL kræver genindeksering og planlægger opdateringer baseret på sidens vigtighed og historiske opdateringsfrekvens, så værdifuldt indhold opdateres mere aggressivt. Selv mindre kosmetiske ændringer nulstiller aktualitetsklokken, hvis CMS’et republikerer det ændrede tidsstempel. For udgivere skaber det et strategisk imperativ: Enten antag en nyhedsredaktionskadence med ugentlige eller daglige opdateringer, eller se evergreen-indhold gradvist forsvinde i synlighed. Konsekvensen er dyb—i Sonar-æraen er content velocity ikke et forfængeligheds-mål, men et overlevelseskrav. Brands, der automatiserer ugentlige mikroopdateringer, tilføjer live changelogs eller opretholder kontinuerlige optimerings-workflows, vil sikre sig en uforholdsmæssig andel af citater sammenlignet med konkurrenter, der satser på statiske sider.
Sonar prioriterer semantisk relevans over nøgleordstæthed og belønner grundlæggende indhold, der direkte besvarer brugerforespørgsler i naturligt, samtalende sprog. Algoritmens retrieval-system anvender tætte vektorembeddings for at matche forespørgsler til indhold på det konceptuelle niveau, hvilket betyder, at sider, der bruger synonymer, beslægtet terminologi eller kontekst-rigt sprog, kan overgå nøgleordsproppede sider uden semantisk dybde. Dette skift fra nøgleordscentreret til betydningscentreret rangering har store konsekvenser for indholdsstrategien. Indhold, der vinder i Sonar, har flere strukturelle karakteristika: det indleder med et kort, faktuelt resumé før det går i dybden, bruger beskrivende H2/H3-overskrifter og korte afsnit for at lette passageudtræk, inkluderer klare citater og links til primære kilder og har synlige tidsstempler og versionsnoter for at signalere aktualitet. Hvert afsnit fungerer som en atomar semantisk enhed, optimeret til copy-paste-klarhed og LLM-forståelse. Tabeller, punktopstillinger og mærkede diagrammer er særligt værdifulde, fordi de præsenterer information i strukturerede, let citerbare formater. Algoritmen belønner også original analyse og unikke data frem for ren aggregering, da Sonars syntesemotor søger kilder med nye vinkler, primærdokumenter eller proprietære indsigter, der adskiller dem fra generiske overblik. Denne vægt på semantisk rigdom og svar-først struktur er et grundlæggende brud med traditionel SEO, hvor nøgleordsplacering og linkautoritet dominerede. I Sonar-æraen skal indhold designes til maskin-hentning og syntese, ikke menneskelig browsing.
Offentligt hostede PDF’er udgør en væsentlig og ofte overset fordel i Sonars rangeringssystem, hvor empiriske tests viser, at PDF-versioner af indhold overgår HTML-ækvivalenter med cirka 22% i citeringsfrekvens. Fordelen skyldes, at Sonars crawler favoriserer PDF’er sammenlignet med HTML-sider. PDF’er mangler cookie-bannere, JavaScript-renderingskrav, betalingsmursautentifikation og andre HTML-komplikationer, der kan skjule eller forsinke indholdstilgang. Sonars crawler kan læse PDF’er rent og forudsigeligt og udtrække tekst uden den fortolknings-usikkerhed, der plager komplekse HTML-strukturer. Udgivere kan strategisk udnytte denne fordel ved at placere PDF’er i offentligt tilgængelige mapper, bruge semantiske filnavne, der afspejler indholdets emne, og signalere PDF’en som kanonisk ved hjælp af <link rel="alternate" type="application/pdf"> tags i HTML-head. Dette skaber det, forskere kalder en “LLM-honeytrap”—et højsynligt aktiv, som konkurrenternes tracking scripts ikke let kan opdage eller overvåge. For B2B-virksomheder, SaaS-udbydere og forskningsbaserede organisationer er denne strategi særligt stærk: publicering af whitepapers, forskningsrapporter, casestudier og teknisk dokumentation som PDF’er kan markant øge Sonar-citeringsrater. Nøglen er at behandle PDF’en ikke som et downloadbart biprodukt, men som en kanonisk kopi, der fortjener lige så stor eller større optimeringsindsats end HTML-versionen. Tilgangen har vist sig særligt effektiv for virksomheders indhold, hvor PDF’er ofte indeholder mere struktureret, autoritativ information end websider.
JSON-LD FAQ-schema markup forstærker markant Sonars citeringsrater, hvor sider med tre eller flere FAQ-blokke får 41% flere citater end kontrolsider uden schema. Denne markante stigning afspejler Sonars præference for struktureret, chunk-baseret indhold, der passer til retrieval- og synteselogikken. FAQ-schema præsenterer diskrete, selvstændige Q&A-enheder, som algoritmen let kan udtrække, rangere og citere som atomare semantiske blokke. I modsætning til traditionel SEO, hvor FAQ-schema var en “nice-to-have”, behandler Sonar struktureret Q&A-markup som en central rangeringsfaktor. Sonar citerer desuden ofte FAQ-spørgsmål som ankertekst, hvilket mindsker risikoen for kontekst-drift, der opstår, når LLM’en opsummerer tilfældige sætninger midt i et afsnit. Schemaet fremskynder også tid-til-første-citation med cirka seks timer, hvilket antyder, at Sonars parser prioriterer strukturerede Q&A-blokke tidligt i rangeringsforløbet. For udgivere er optimeringsstrategien ligetil: Indsæt tre til fem målrettede FAQ-blokke under folden med samtalebaserede trigger-sætninger, der spejler reelle brugerforespørgsler. Spørgsmål bør benytte long-tail søgefraser og semantisk symmetri med sandsynlige Sonar-forespørgsler. Hvert svar skal være kort, faktuelt og direkte, uden fyldstof eller markedsføringssprog. Tilgangen har vist sig særligt effektiv for SaaS-virksomheder, klinikker og professionelle servicefirmaer, hvor FAQ-indhold naturligt matcher brugerhensigt og Sonars syntesebehov.
Sonars rangeringssystem integrerer flere signaler i en samlet citeringsramme, hvor forskning har identificeret otte primære faktorer, der påvirker kildevalg og citeringsfrekvens. For det første dominerer semantisk relevans for spørgsmålet retrieval, da algoritmen prioriterer indhold, der klart besvarer forespørgslen i naturligt sprog. For det andet betyder autoritet og troværdighed meget, hvor Perplexitys udgiverpartnerskaber og algoritmiske boosts favoriserer etablerede nyhedsmedier, akademiske institutioner og anerkendte eksperter. For det tredje vægtes aktualitet højt, som beskrevet, med nylige opdateringer, der udløser 37% flere citater. For det fjerde værdsættes diversitet og dækning, idet Sonar foretrækker flere høj-kvalitetskilder frem for enkeltskilde-svar og reducerer hallucinationsrisiko gennem krydsvalidering. For det femte bestemmer mode og scope, hvilke indeks Sonar søger i—fokusmodes som Akademisk, Finans, Skrivning og Social indsnævrer kildetyper, mens kildeselektorer (Web, Org Files, Web + Org Files, Ingen) afgør, om retrieval sker fra det åbne web, interne dokumenter eller begge dele. For det sjette er citerbarhed og adgang kritisk; hvis PerplexityBot kan crawle og indeksere indhold, er det lettere at citere, hvilket gør robots.txt-compliance og sidehastighed væsentlige. For det syvende tillader brugerdefinerede kildefiltre via API virksomhedsudrulninger at begrænse eller foretrække bestemte domæner, hvilket ændrer rangering inden for whitelists. For det ottende påvirker samtalekontekst opfølgende spørgsmål, hvor sider, der matcher udviklende hensigt, overgår mere generiske referencer. Samlet skaber disse faktorer et multidimensionelt rangeringsrum, hvor succes kræver optimering på flere parametre samtidigt, ikke blot et enkelt træk som backlinks eller nøgleordstæthed.
Sonar-algoritmen udvikler sig hurtigt i takt med fremskridt inden for LLM-inferens og retrieval-teknologi. Perplexitys engineering-blog har for nylig fremhævet spekulativ decoding, en teknik, der halverer token-latency ved at forudsige flere fremtidige tokens samtidigt. Hurtigere genereringsloops gør det muligt for systemet at hente friskere retrieval-sæt for hver forespørgsel og indsnævre vinduet, hvor forældede sider kan konkurrere. En rygtet Sonar-Reasoning-Pro-model overgår allerede Gemini 2.0 Flash og GPT-4o Search i arena-evalueringer, hvilket antyder, at Sonars rangeringssofistikering kun vil stige. Når latencyn nærmer sig menneskets tankehastighed, bliver citeringskapløbet et højfrekvent spil, hvor content velocity er den afgørende faktor. Forvent nye infrastrukturløsninger som “LLM freshness API’er”, der auto-opdaterer tidsstempler, ligesom adtech engang gjorde med budpriser, hvilket skaber nye konkurrencevilkår omkring realtidsopdateringer af indhold. Juridiske og etiske udfordringer vil også opstå, efterhånden som PDF-pirater udnytter Sonars PDF-præference til at stjæle autoritet fra lukkede e-bøger og proprietær forskning, hvilket
**Sonar-algoritmen** er Perplexitys proprietære rangeringssystem, der driver deres svarmotor og adskiller sig grundlæggende fra traditionelle søgemaskiner som Google. Hvor Google rangerer sider for visning i en liste af blå links, rangerer Sonar indholdssnippets til syntese i et enkelt, samlet svar med indlejrede kildehenvisninger. Sonar anvender retrieval-augmented generation (RAG) og kombinerer hybrid søgning (vektorembedding samt nøgleords-match), neuralt gen-rangering og realtids webhentning for at forankre svar i verificerbare kilder. Denne tilgang prioriterer semantisk relevans og indholdsaktualitet frem for ældre SEO-signaler som backlinks, hvilket gør det til et særskilt rangeringsparadigme optimeret til AI-genereret syntese frem for linkbaseret autoritet.
Sonar implementerer en **hybrid retrieval-motor**, der kombinerer to komplementære søgestrategier: tæt retrieval (vektorsøgning med semantiske embeddings) og sparsom retrieval (leksikal/nøgleordsbaseret søgning ved hjælp af BM25). Tæt retrieval fanger konceptuel betydning og kontekst, hvilket gør det muligt at finde semantisk lignende indhold selv uden præcise nøgleords-match. Sparsom retrieval giver præcision for sjældne termer, produktnavne og specifikke identifikatorer, hvor semantisk tvetydighed er uønsket. Disse to metoder sammensmeltes og deduplikeres for at producere cirka 50 forskellige kandidatdokumenter og undgår overfitting på domæner samt sikrer bred dækning. Denne hybride tilgang overgår enkeltmetode-systemer både hvad angår recall og relevanspræcision.
De primære rangeringsfaktorer for Sonar omfatter: (1) **Indholdsaktualitet** – nyligt opdaterede eller publicerede sider modtager 37% flere citater inden for 48 timer efter opdatering; (2) **Semantisk relevans** – indholdet skal svare direkte på forespørgslen i naturligt sprog og prioritere klarhed frem for nøgleords-tæthed; (3) **Autoritet og troværdighed** – kilder fra etablerede udgivere, akademiske institutioner og nyhedsorganisationer får algoritmiske boosts; (4) **Citerbarhed** – indhold skal let kunne citeres og være struktureret med tydelige overskrifter, tabeller og afsnit; (5) **Diversitet** – Sonar foretrækker flere høj-kvalitets kilder frem for enkeltskilde-svar; og (6) **Teknisk tilgængelighed** – sider skal kunne crawles af PerplexityBot og indlæses hurtigt for on-demand browsing.
**Aktualitet er en af Sonars vigtigste rangeringssignaler**, især for tidskritiske emner. Perplexitys infrastruktur behandler titusindvis af indeksopdateringsanmodninger pr. sekund, så indekset altid afspejler den mest aktuelle information. En ML-model forudsiger, om en URL skal genindekseres og planlægger opdateringer baseret på sidens vigtighed og opdateringsfrekvens. I empiriske tests fik indhold, der var opdateret inden for de sidste 48 timer, 37% flere citater end identisk indhold med ældre tidsstempler, og denne fordel holdt sig på 14% efter to uger. Selv mindre ændringer nulstiller aktualitetsklokken, hvilket gør løbende optimering af indhold afgørende for at opretholde synlighed i Sonar-drevne svar.
**PDF'er udgør en væsentlig fordel i Sonars rangeringssystem** og overgår ofte HTML-versioner af samme indhold med 22% i citeringsfrekvens. Sonars crawler favoriserer PDF'er, fordi de mangler cookie-bannere, betalingsmure, JavaScript-renderingsproblemer og andre HTML-komplikationer, som kan skjule indholdet. Udgivere kan optimere PDF-synlighed ved at placere dem i offentligt tilgængelige mapper, bruge semantiske filnavne og signalere PDF'en som kanonisk ved hjælp af `` tags i HTML-head. Dette skaber det forskere kalder en "LLM-honeytrap", som konkurrenters tracking scripts ikke let kan opdage, hvilket gør PDF'er til et strategisk aktiv for at sikre Sonar-citater.
**JSON-LD FAQ-schema øger Sonars citeringsrater markant**, hvor sider med tre eller flere FAQ-blokke modtager 41% flere citater end kontrolsider uden schema. FAQ-markup passer perfekt til Sonars chunk-baserede retrieval-logik, fordi det præsenterer diskrete, selvstændige Q&A-enheder, som algoritmen let kan udtrække og citere. Derudover citerer Sonar ofte FAQ-spørgsmål som ankertekst, hvilket mindsker risikoen for kontekst-drift, der kan opstå, når LLM'en opsummerer tilfældige sætninger midt i et afsnit. Schemaet fremskynder også tiden til første citation med cirka seks timer, hvilket antyder, at Sonars parser prioriterer strukturerede Q&A-blokke tidligt i rangeringskæden.
Sonar implementerer en **tretrins retrieval-augmented generation (RAG) pipeline**, der er designet til at forankre svar i verificeret ekstern viden. Første trin henter relevante dokumenter med hybrid søgning; andet trin udtrækker og kontekstualiserer de mest relevante snippets; tredje trin syntetiserer et svar ved kun at bruge den leverede kontekst og håndhæver et strengt princip: "du må ikke sige noget, du ikke har hentet." Denne arkitektur kobler retrieval og generation tæt sammen, så hvert udsagn kan spores til en kilde. Indlejrede citater linker genereret tekst tilbage til kildedokumenter og muliggør brugervalidering. Denne forankrede tilgang reducerer hallucinationer betydeligt sammenlignet med modeller, der udelukkende bygger på træningsdata, hvilket gør Sonars svar mere faktuelt pålidelige og troværdige.
Mens **ChatGPT prioriterer entitetsgenkendelse og konsensus** fra sine træningsdata, **fokuserer Gemini på E-E-A-T-signaler og konversationel tilpasning**, og **Claude vægter konstitutionel sikkerhed og neutralitet**, **prioriterer Sonar unikt realtidsaktualitet og semantisk dybde**. Sonars tre-lags maskinlærings-reranker anvender strengere kvalitetsfiltre end traditionel søgning og kasserer hele resultatsæt, hvis indholdet ikke opfylder kvalitetskriterierne. I modsætning til ChatGPT's afhængighed af historiske træningsdata udfører Sonar live webhentning for hver forespørgsel, så svarene afspejler aktuel information. Sonar adskiller sig også fra Geminis knowledge graph-integration ved at betone semantisk relevans på afsnitsniveau og fra Claudes neutralitetsfokus ved at acceptere autoritetsboost fra etablerede udgivere.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvordan Perplexitys Sonar-algoritme driver AI-søgning i realtid med omkostningseffektive modeller. Udforsk varianterne Sonar, Sonar Pro og Sonar Reasoning....
Lær hvad RAG (Retrieval-Augmented Generation) er i AI-søgning. Opdag hvordan RAG forbedrer nøjagtighed, reducerer hallucinationer og driver ChatGPT, Perplexity ...
RankBrain er Googles AI-drevne maskinlæringssystem, der fortolker søgehensigt og rangerer resultater. Lær hvordan denne centrale rangeringsfaktor påvirker SEO o...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.