Strukturerede data
Strukturerede data er standardiseret markup, der hjælper søgemaskiner med at forstå websideindhold. Lær, hvordan JSON-LD, schema.org og microdata forbedrer SEO,...
10 min læsning

Schema-markup, der er specielt designet til at hjælpe AI-systemer med at forstå og citere indhold nøjagtigt. Strukturerede data bruger standardiserede formater som JSON-LD til at give eksplicit kontekst om sideindhold, hvilket gør det muligt for store sprogmodeller at analysere information mere pålideligt og citere kilder med større sikkerhed.
Schema-markup, der er specielt designet til at hjælpe AI-systemer med at forstå og citere indhold nøjagtigt. Strukturerede data bruger standardiserede formater som JSON-LD til at give eksplicit kontekst om sideindhold, hvilket gør det muligt for store sprogmodeller at analysere information mere pålideligt og citere kilder med større sikkerhed.
Strukturerede data til AI henviser til organiseret, maskinlæsbar information, formateret efter standardiserede skemaer, der gør det muligt for kunstig intelligens at forstå, fortolke og bruge indhold med præcision. I modsætning til ustruktureret tekst, som kræver kompleks naturlig sprogbehandling for at afkode betydning, giver strukturerede data eksplicit kontekst om, hvad informationen repræsenterer. Denne klarhed er essentiel, fordi AI-systemer—særligt store sprogmodeller og søgemaskiner—behandler milliarder af datapunkter dagligt. Når indhold struktureres med standarder som schema.org, JSON-LD eller microdata, kan AI straks genkende entiteter, relationer og attributter uden tvetydighed. Denne strukturerede tilgang giver 300% højere nøjagtighed i AI-forståelse sammenlignet med ustrukturerede alternativer. For organisationer, der ønsker synlighed i AI Overviews og andre AI-genererede resultater, er strukturerede data blevet uundværlig infrastruktur. Det forvandler råt indhold til intelligens, som AI-systemer trygt kan citere, referere og indarbejde i deres svar, og ændrer fundamentalt, hvordan digitalt indhold opnår synlighed i en AI-drevet verden.

AI-systemer behandler strukturerede data gennem en sofistikeret pipeline, der omdanner markeret indhold til brugbar intelligens. Når et AI-system møder korrekt formaterede strukturerede data, kan det straks udtrække nøgleinformation uden det beregningsmæssige overhead, som naturlig sprogforståelse kræver. Den tekniske mekanisme følger disse væsentlige trin:
Denne proces gør det muligt for AI at levere 30%+ højere synlighed i AI Overviews for korrekt struktureret indhold. Den strukturerede tilgang reducerer risikoen for hallucinationer ved at forankre AI-svar til eksplicitte, verificerbare data frem for sandsynlighedsdrevet tekstgenerering. Organisationer, der implementerer omfattende strategier for strukturerede data, ser målbare forbedringer i, hvordan AI-systemer opdager, forstår og promoverer deres indhold på tværs af flere platforme og applikationer.
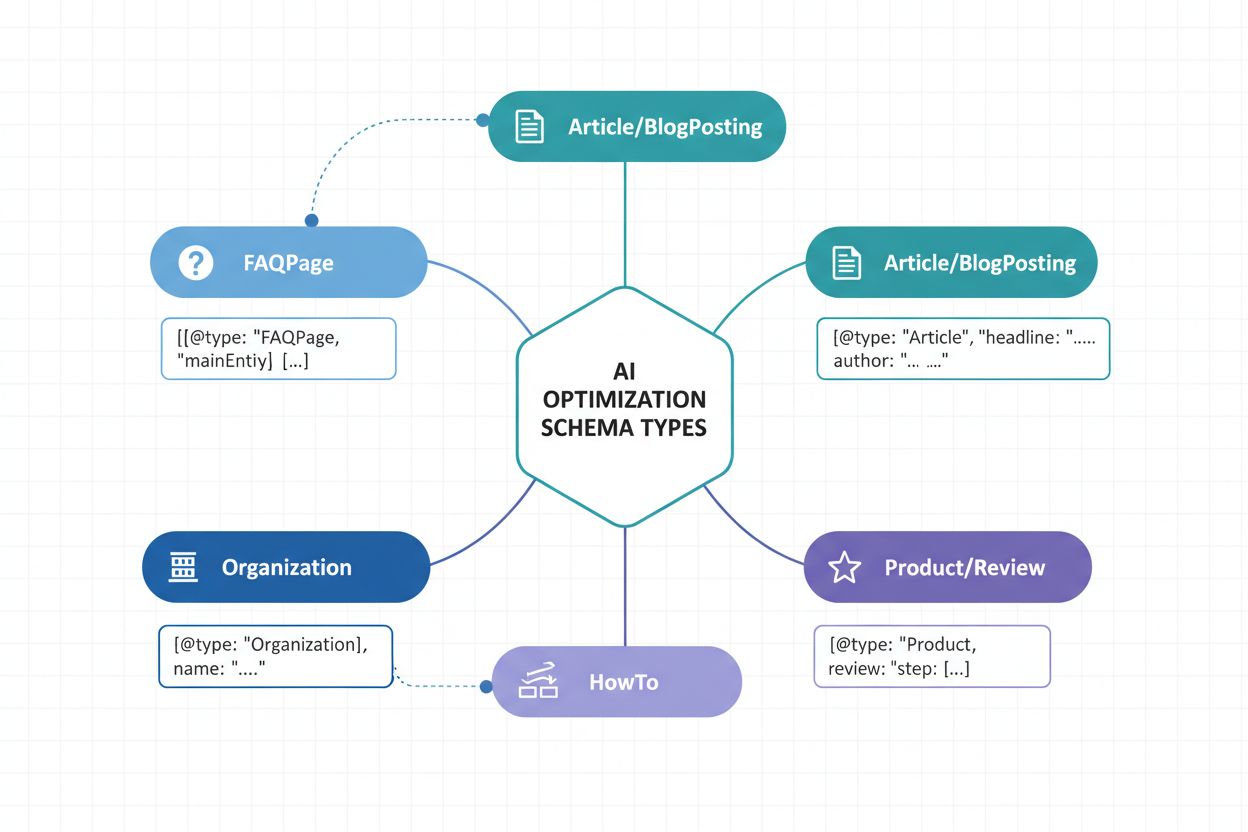
Implementering af de rette schema-typer er grundlæggende for en AI-synlighedsstrategi. Forskellige indholdstyper kræver specifik struktureret datamarkup for at kommunikere deres natur og værdi til AI-systemer. Her er de vigtigste schema-typer for at maksimere AI-genkendelse:
Article Schema – Markerer nyhedsartikler, blogindlæg og længere indhold med overskrift, forfatter, publiceringsdato og brødtekst. Kritisk for AI-systemers identifikation af autoritative kilder og etablering af publicerings-troværdighed.
Organization Schema – Definerer virksomhedsidentitet, inkl. navn, logo, kontaktinformation og sociale profiler. Gør det muligt for AI at genkende og korrekt tilskrive organisatorisk indhold i flere sammenhænge.
Product Schema – Strukturerer produktinformation inkl. navn, beskrivelse, pris, tilgængelighed og anmeldelser. Vigtigt for e-handels-synlighed i AI-shoppingassistenter og produktanbefalingssystemer.
LocalBusiness Schema – Marker virksomhedsplacering, åbningstider, kontaktoplysninger og tjenester. Afgørende for lokale AI-forespørgsler og stedbaserede AI Overviews, som i stigende grad dominerer søgeresultater.
BreadcrumbList Schema – Definerer navigationens hierarki og hjælper AI med at forstå indholdsstruktur og relationer mellem sider i din informationsarkitektur.
FAQPage Schema – Strukturerer ofte stillede spørgsmål med svar, så AI-systemer direkte kan udtrække og citere specifikt Q&A-indhold i svar.
NewsArticle og BlogPosting Schemas – Specialiserede artikeltyper, der signalerer indholdskategori til AI-systemer og forbedrer kategoriseringsnøjagtighed og relevansmatch.
Event Schema – Markerer begivenhedsdetaljer, herunder dato, sted, beskrivelse og registreringsinformation, essentielt for AI-begivenhedsopdagelse og kalenderintegration.
I øjeblikket bruger 45 millioner domæner schema.org-markup, hvilket repræsenterer 12,4% af alle domæner globalt. Organisationer, der implementerer flere schema-typer samtidigt, oplever forstærkede synlighedsfordele, da AI-systemer får rigere kontekstuel forståelse af deres indholdsøkosystem.
Succesfuld implementering af strukturerede data kræver strategisk planlægning og teknisk præcision. Organisationer bør følge disse etablerede best practices for at maksimere AI-synlighed og sikre datanøjagtighed:
Her er et praktisk JSON-LD-eksempel for en artikel:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Structured Data for AI: Strategic Implementation Guide",
"author": {
"@type": "Person",
"name": "Content Author"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Full article text here...",
"publisher": {
"@type": "Organization",
"name": "Your Organization",
"logo": "https://example.com/logo.png"
}
}
Korrekt implementering giver 35% forbedring i klikrate fra rich results i traditionel søgning, med yderligere fordele, efterhånden som AI Overviews bliver primære opdagelseskanaler. Organisationer, der overvåger deres performance for strukturerede data via løsninger som AmICited.com, opnår konkurrencefordel ved at identificere, hvilke indholdstyper og schema-implementeringer, der driver størst AI-synlighed.
Både strukturerede data og llms.txt tjener AI-opdagelighed, men fungerer gennem fundamentalt forskellige mekanismer. Strukturerede data bruger standardiserede schemaer (schema.org, JSON-LD), der indlejres i HTML til at markere specifikke indholdselementer med eksplicit semantisk betydning. Denne tilgang integreres direkte i websider, så information straks er tilgængelig for både søgemaskiner og AI-systemer under crawling. Strukturerede data muliggør detaljeret markup af individuelle artikler, produkter, events og organisationer, så AI kan forstå præcise relationer og attributter.
llms.txt er derimod en tekstfil, der placeres i roden af et website og indeholder instruktioner og retningslinjer for store sprogmodeller. Den fungerer som en manifestfil, der kommunikerer præferencer om, hvordan AI-systemer bør interagere med og citere dit indhold. Mens llms.txt giver overordnede retningslinjer om brugsrettigheder og citeringspræferencer, mangler den den semantiske præcision, som strukturerede data giver. Strukturerede data besvarer “hvad er dette indhold?” med eksplicit maskinlæsbare svar, hvorimod llms.txt svarer “hvordan bør du bruge dette indhold?” som vejledning.
Den mest effektive strategi kombinerer begge tilgange: Strukturerede data sikrer, at AI-systemer nøjagtigt forstår og kan citere dit indhold, mens llms.txt etablerer klare brugsregler og krav om attribution. Organisationer, der implementerer begge, oplever 36% større sandsynlighed for at optræde i AI-genererede sammendrag sammenlignet med dem, der ikke bruger nogen af delene. Strukturerede data giver grundlaget for AI-forståelse, mens llms.txt giver rammerne for korrekt attribution og brugscompliance.
Måling af effektiviteten af strukturerede data kræver overvågning af specifikke målinger, der viser, hvordan AI-systemer opdager, forstår og citerer dit indhold. Organisationer bør følge disse centrale KPI’er:
AmICited.com tilbyder specialiseret overvågning af AI-citatperformance, så organisationer kan følge, hvordan deres investeringer i strukturerede data omsættes til reel AI-synlighed og attribution. Platformen viser, hvilket indhold der modtager AI-citater, hvilke forespørgsler der udløser dit indhold, og hvordan din citathyppighed sammenlignes med konkurrenter. Denne datadrevne tilgang forvandler implementering af strukturerede data fra teoretisk best practice til målbar forretningsværdi.
Organisationer, der implementerer omfattende strategier for strukturerede data, rapporterer, at 93% af forespørgsler besvares af AI uden klik, hvilket gør citationssynlighed stadig mere kritisk for at drive trafik. Måling af citatperformance sikrer, at dine investeringer i strukturerede data giver kvantificerbare afkast gennem forbedret AI-opdagelighed og brand-attribution.
Succesfuld implementering af strukturerede data følger en trinvis tilgang, der gradvist opbygger kapacitet og leverer målbar værdi på hvert trin. Organisationer bør strukturere deres implementeringstidslinje således:
Fase 1: Fundament (Måned 1-2)
Fase 2: Udvidelse (Måned 3-4)
Fase 3: Optimering (Måned 5-6)
Fase 4: Strategisk integration (Måned 7+)
Denne tidslinje gør det muligt for organisationer at opnå meningsfulde forbedringer af AI-synlighed inden for 2-3 måneder, mens de bevæger sig mod en omfattende, virksomhedsorienteret infrastruktur for strukturerede data. Tidlige adoptører, der implementerer dette roadmap, får konkurrencefordel, efterhånden som AI Overviews bliver primære opdagelseskanaler.
Strukturerede data er gået fra at være et valgfrit SEO-tiltag til at være essentiel strategisk infrastruktur i et AI-drevet digitalt landskab. Efterhånden som AI-systemer i stigende grad medierer, hvordan brugere opdager information, står organisationer uden omfattende markup for strukturerede data over for systematiske synlighedsulemper. Skiftet afspejler grundlæggende ændringer i informationsstrømme: Traditionel søgning krævede, at brugere klikkede videre til websites, men AI Overviews besvarer spørgsmål direkte, hvilket gør citationssynlighed til den nye konkurrencemæssige slagmark.
Organisationer, der implementerer strukturerede data strategisk, positionerer sig til langsigtet succes på tværs af flere AI-platforme og nye opdagelseskanaler. Infrastrukturinvesteringen betaler sig ud over øjeblikkelig AI-synlighed—strukturerede data forbedrer intern indholdsstyring, muliggør bedre personalisering, understøtter optimering af stemmesøgning og skaber dataaktiver, der er værdifulde for fremtidige AI-applikationer. Tidlige adoptører, der etablerer omfattende fundament for strukturerede data, opnår forstærkede fordele, efterhånden som AI-systemer i stigende grad prioriterer veldokumenteret indhold.
Konkurrencefordelen ved tidlig adoption kan ikke overvurderes. Efterhånden som flere organisationer erkender betydningen af strukturerede data, bliver implementering en forudsætning for synlighed. Organisationer, der etablerer robust infrastruktur for strukturerede data nu, vil dominere AI-genererede resultater, efterhånden som disse kanaler modnes. Omvendt vil organisationer, der udskyder implementering, opleve stigende vanskeligheder med at opnå synlighed, når AI-systemer lærer at foretrække omfattende markeret indhold. Strukturerede data er ikke blot en teknisk implementering, men et grundlæggende strategisk valg for at forblive synlig og citerbar i et AI-medieret informationsøkosystem.
Strukturerede data påvirker ikke direkte Googles placeringer, men de forbedrer markant udseendet i søgeresultater gennem rich snippets, hvilket øger klikraten med op til 35%. For AI-systemer har strukturerede data en mere direkte effekt på, om dit indhold bliver citeret i AI-genererede svar.
Ja, AI-systemer behandler strukturerede data både under træning og ved realtidsforespørgsler. Selvom OpenAI ikke har udtalt sig offentligt om det, tyder beviser på, at GPTBot og andre AI-crawlere analyserer JSON-LD-markup. Microsoft har officielt bekræftet, at Bings AI-systemer bruger schema markup til bedre at forstå indhold.
JSON-LD er det anbefalede format, fordi det adskiller schema fra HTML-indholdet, hvilket gør det lettere at implementere og vedligeholde i stor skala. Google anbefaler eksplicit JSON-LD, og det er mindre tilbøjeligt til implementeringsfejl end Microdata eller RDFa.
Rich snippets kan vises inden for 1-4 uger efter implementering. Forbedringer i klikrate kan ofte måles inden for 2 uger. For forbedringer i AI-citater, forvent 4-8 uger for, at grundarbejdet får effekt, med yderligere autoritetsopbygning, der akkumuleres over 3-6 måneder.
Prioritér schema markup først—det er gennemprøvet og bredt understøttet. llms.txt er stadig en ny standard med begrænset anvendelse blandt AI-crawlere. Hvis du er en udviklerfokuseret virksomhed med omfattende dokumentation, kan den minimale indsats for at oprette llms.txt være værdifuld for fremtidssikring.
Start med Organization-schema på din forside (med sameAs-egenskaber), derefter Article-schema på nøgleindholdssider. FAQPage-schema bør være næste—det er mest direkte nyttigt for AI-ekstraktion. Derefter tilføj HowTo-schema til vejledninger og SoftwareApplication-schema til produktsider.
Kun forkert implementeret markup skader ydeevnen. Googles retningslinjer er klare: brug relevante schema-typer, der matcher synligt indhold, hold priser og datoer nøjagtige, og markér ikke indhold op, som brugerne ikke kan se. Validér altid med Googles Rich Results Test før udgivelse.
Strukturerede data giver eksplicit kontekst, der hjælper AI-systemer med at forstå, hvad information repræsenterer—entiteter, relationer, attributter. Denne klarhed gør det muligt for AI at udtrække og citere dit indhold med sikkerhed. LLM'er, der er forankret i knowledge graphs, opnår 300% højere nøjagtighed sammenlignet med dem, der kun bruger ustrukturerede data.
Følg, hvordan AI-systemer citerer dit indhold på tværs af ChatGPT, Perplexity, Google AI Overviews og andre platforme. Få realtidsindsigt i din AI-tilstedeværelse.
Strukturerede data er standardiseret markup, der hjælper søgemaskiner med at forstå websideindhold. Lær, hvordan JSON-LD, schema.org og microdata forbedrer SEO,...
Lær hvordan AI-crawlere behandler strukturerede data. Opdag hvorfor JSON-LD-implementeringsmetoden er afgørende for synlighed i ChatGPT, Perplexity, Claude og G...
Fællesskabsdiskussion om hvorvidt AI-crawlere læser strukturerede data. Virkelige erfaringer fra SEO-professionelle der tester schema markup-påvirkning på ChatG...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.