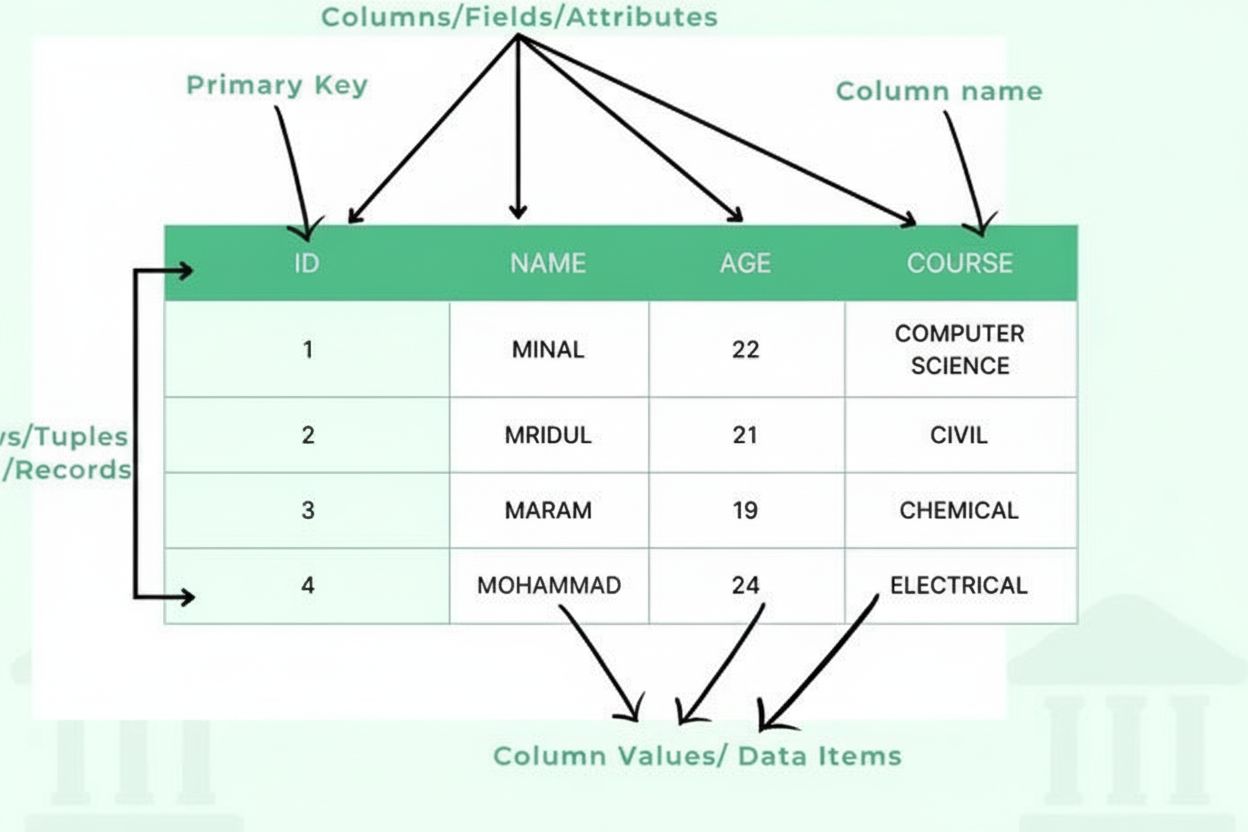
Definition af tabel: Organiserede data i rækker og kolonner
En tabel er en grundlæggende datastruktur, der organiserer information i et todimensionelt gitter bestående af vandrette rækker og lodrette kolonner. I sin mest grundlæggende form repræsenterer en tabel en samling af relaterede data arrangeret på en struktureret måde, hvor hvert kryds mellem en række og kolonne indeholder et enkelt dataelement eller celle. Tabeller fungerer som hjørnestenen i relationelle databaser, regneark, datalagre og stort set ethvert system, der kræver organiseret informationslagring og -hentning. Styrken ved tabeller ligger i deres evne til at muliggøre hurtig visuel scanning, logisk sammenligning af data på tværs af flere dimensioner og programmatisk adgang til specifik information via standardiserede forespørgselssprog. Uanset om de bruges i forretningsanalyse, videnskabelig forskning eller AI-overvågningsplatforme, leverer tabeller et universelt forstået format til præsentation af strukturerede data, der nemt kan tolkes både af mennesker og maskiner.
Historisk kontekst og udvikling af tabulær dataorganisering
Konceptet med at organisere information i rækker og kolonner går flere århundreder forud for moderne databehandling. Gamle civilisationer anvendte tabulære formater til at registrere lagerbeholdninger, finansielle transaktioner og astronomiske observationer. Den formelle definition af tabelstrukturer i databehandling opstod dog med udviklingen af relationel databaseteori af Edgar F. Codd i 1970, hvilket revolutionerede måden, hvorpå data kunne lagres og forespørges. Den relationelle model fastslog, at data bør organiseres i tabeller med klart definerede relationer og ændrede fundamentalt principperne for databasens design. Gennem 1980’erne og 1990’erne demokratiserede regnearksapplikationer som Lotus 1-2-3 og Microsoft Excel brugen af tabeller, hvilket gjorde tabulær dataorganisering tilgængelig for ikke-tekniske brugere. I dag bruger cirka 97% af organisationer regnearksapplikationer til datastyring og analyse, hvilket demonstrerer den vedvarende betydning af tabelbaseret dataorganisering. Udviklingen fortsætter med moderne tiltag inden for kolonnedatabaser, NoSQL-systemer og datalakes, som udfordrer traditionelle rækkeorienterede tilgange, men stadig bevarer grundlæggende tabel-lignende strukturer til organisering af information.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Kernekomponenter og struktur i tabeller
En tabel består af flere væsentlige strukturelle komponenter, der arbejder sammen for at skabe en organiseret data-ramme. Kolonner (også kaldet felter eller attributter) løber lodret og repræsenterer informationskategorier som “Kundenavn”, “E-mailadresse” eller “Købsdato”. Hver kolonne har en defineret datatype, der specificerer, hvilken slags information den kan indeholde—heltal, tekststrenge, datoer, decimaler eller mere komplekse strukturer. Rækker (også kaldet poster eller tupler) løber vandret og repræsenterer individuelle dataindtastninger eller enheder, hvor hver række indeholder én komplet post. Krydsningen mellem en række og kolonne skaber en celle eller dataelement, som indeholder et enkelt stykke information. Kolonneoverskrifter identificerer hver kolonne og vises øverst i tabellen for at give kontekst til dataene nedenfor. Primærnøgler er særlige kolonner, der entydigt identificerer hver række, så der ikke opstår dubletter. Fremmednøgler etablerer relationer mellem tabeller ved at referere til primærnøgler i andre tabeller. Denne hierarkiske organisering gør databaser i stand til at opretholde dataintegritet, forhindre redundans og understøtte komplekse forespørgsler, der henter information baseret på flere kriterier.
Sammenligning af tabelorganiseringsmetoder
| Aspekt | Rækkeorienterede tabeller | Kolonneorienterede tabeller | Hybride tilgange |
|---|
| Lagringsmetode | Data lagres og tilgås efter komplette poster | Data lagres og tilgås efter individuelle kolonner | Kombinerer fordelene ved begge tilgange |
| Forespørgselsydelse | Optimeret til transaktionsforespørgsler, der henter hele poster | Optimeret til analytiske forespørgsler på specifikke kolonner | Balanceret ydeevne til blandede arbejdsmængder |
| Brugsscenarier | OLTP (Online Transaction Processing), forretningsdrift | OLAP (Online Analytical Processing), datalagre | Realtidsanalyse, operationel intelligens |
| Databaseeksempler | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Komprimeringseffektivitet | Lavere komprimeringsrate pga. datadiversitet | Højere komprimeringsrate for ensartede kolonneværdier | Optimeret komprimering til specifikke mønstre |
| Skriveydelse | Hurtig skrivning af hele poster | Langsommere skrivning kræver kolonneopdateringer | Balanceret skriveydelse |
| Skalerbarhed | Skalerer godt til transaktionsmængder | Skalerer godt til datamængde og forespørgselskompleksitet | Skalerer på begge dimensioner |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Teknisk implementering og databasearkitektur
I relationelle databasestyringssystemer (RDBMS) implementeres tabeller som strukturerede samlinger af rækker, hvor hver række følger et foruddefineret skema. Skemaet definerer tabelstrukturen og specificerer kolonnenavne, datatyper, begrænsninger og relationer. Når data indsættes i en tabel, validerer databasestyringssystemet, at hver værdi matcher den tilhørende kolonnes datatype og opfylder eventuelle definerede begrænsninger. For eksempel vil en kolonne defineret som INTEGER afvise tekstværdier, og en kolonne markeret som NOT NULL vil afvise tomme indgange. Indekser oprettes på ofte forespurgte kolonner for at fremskynde datahentning og fungerer som organiserede referencer, der gør det muligt for databasen at finde specifikke rækker uden at skulle gennemgå hele tabellen. Normalisering er et designprincip, der organiserer tabeller for at minimere dataredundans og forbedre dataintegritet ved at opdele information i relaterede tabeller, der forbindes via nøgler. Moderne databaser understøtter transaktioner, som sikrer, at flere operationer på tabeller enten alle lykkes eller alle fejler, og dermed opretholder konsistens selv ved systemnedbrud. Forespørgselsoptimereren i database-motorer analyserer SQL-forespørgsler og bestemmer den mest effektive måde at tilgå tabeldata på, under hensyntagen til tilgængelige indekser og tabelstatistikker.
Datapræsentation og visualisering i tabeller
Tabeller fungerer som den primære mekanisme til at præsentere strukturerede data for brugere i både digitale og trykte formater. I business intelligence- og analyseapplikationer viser tabeller aggregerede målinger, præstationsindikatorer og detaljerede transaktionsdata, der gør det muligt for beslutningstagere hurtigt at forstå komplekse datasæt. Forskning viser, at 83% af forretningsprofessionelle benytter datatabeller som deres primære værktøj til informationsanalyse, da tabeller muliggør præcis værdisammenligning og mønstergenkendelse. HTML-tabeller på websites anvender semantisk markup med <table>, <tr> (tablerække), <td> (tabeldata) og <th> (tabeloverskrift) elementer for at strukturere data til både visning og programmatisk fortolkning. Regnearksapplikationer som Microsoft Excel, Google Sheets og LibreOffice Calc udvider grundlæggende tabelfunktionalitet med formler, betinget formatering og pivottabeller, der gør det muligt for brugere at udføre beregninger og omorganisere data dynamisk. Best practices for datavisualisering anbefaler at bruge tabeller, når præcise værdier er vigtigere end visuelle mønstre, når flere attributter for enkelte poster skal sammenlignes, eller når brugere har behov for opslag eller beregninger. W3C Web Accessibility Initiative understreger, at korrekt strukturerede tabeller med klare overskrifter og passende markup er afgørende for at gøre data tilgængelige for brugere med handicap, især dem der anvender skærmlæsere.
Tabeller i AI-overvågning og indholdssporing
I konteksten af AI-overvågningsplatforme som AmICited spiller tabeller en kritisk rolle i at organisere og præsentere data om, hvordan indhold optræder på tværs af forskellige AI-systemer. Overvågningstabeller sporer målinger som citationsfrekvens, optrædelsesdatoer, AI-platformkilder (ChatGPT, Perplexity, Google AI Overviews, Claude) og kontekstuel information om, hvordan domæner og URL’er refereres. Disse tabeller gør det muligt for organisationer at forstå deres brand-synlighed i AI-genererede svar og identificere tendenser i, hvordan forskellige AI-systemer citerer eller refererer til deres indhold. Den strukturerede natur af overvågningstabeller gør det muligt at filtrere, sortere og aggregere citationsdata, hvilket gør det muligt at besvare spørgsmål som “Hvilke af vores URL’er optræder oftest i Perplexity-svar?” eller “Hvordan har vores citationsrate ændret sig den seneste måned?” Datatabeller i overvågningssystemer muliggør også sammenligning på tværs af flere dimensioner—sammenligne citationsmønstre mellem forskellige AI-platforme, analysere citationsvækst over tid eller identificere hvilke indholdstyper der får flest AI-referencer. Muligheden for at eksportere overvågningsdata fra tabeller til rapporter, dashboards og yderligere analyseværktøjer gør tabeller uundværlige for organisationer, der ønsker at forstå og optimere deres tilstedeværelse i AI-genereret indhold.
Best practices for tabeldesign og organisering
Effektiv tabeldesign kræver omhyggelig overvejelse af struktur, navngivningskonventioner og dataorganiseringsprincipper. Kolonnenavne bør bruge klare, beskrivende betegnelser, der præcist afspejler de indeholdte data, og undgå forkortelser, der kan forvirre brugere eller udviklere. Datatyper er afgørende—valg af passende typer forhindrer ugyldig dataindtastning og muliggør korrekt sortering og sammenligning. Definition af primærnøgle sikrer, at hver række kan identificeres entydigt, hvilket er essentielt for dataintegritet og etablering af relationer til andre tabeller. Normalisering reducerer dataredundans ved at organisere information i relaterede tabeller frem for at gemme dubletter flere steder. Indekseringsstrategi skal balancere forespørgselsydelse mod den ekstra vedligeholdelse, indekser medfører ved dataændringer. Dokumentation af tabelstruktur, herunder kolonnedefinitioner, datatyper, begrænsninger og relationer, er vigtig for langsigtet vedligeholdelse. Adgangskontrol bør implementeres for at sikre, at følsomme data i tabeller er beskyttet mod uautoriseret adgang. Ydelsesoptimering indebærer overvågning af forespørgselsudførelse og justering af tabelstrukturer, indekser eller forespørgsler for at forbedre effektiviteten. Backup- og gendannelsesprocedurer skal etableres for at beskytte tabeldata mod tab eller korruption.
Væsentlige aspekter af tabelorganisering og -styring
- Strukturelle komponenter: Tabeller består af kolonner (felter), rækker (poster), overskrifter, dataelementer (celler), datatyper, primærnøgler og fremmednøgler, der arbejder sammen for at skabe organiserede datastrukturer
- Dataintegritet: Begrænsninger, valideringsregler og nøgle-relationer opretholder dataens nøjagtighed og forhindrer uoverensstemmelser eller dubletter
- Forespørgselseffektivitet: Korrekt indeksering, normalisering og forespørgselsoptimering muliggør hurtig hentning af specifik information fra store tabeller
- Tilgængelighed: Semantisk HTML-markup, klare overskrifter og korrekt struktur gør tabeller tilgængelige for brugere med handicap og assistiv teknologi
- Skalerbarhed: Veludformede tabeller kan effektivt håndtere voksende datamængder gennem passende indeksering, partitionering og databaseoptimeringsteknikker
- Relationsstyring: Fremmednøgler etablerer forbindelser mellem tabeller og muliggør komplekse forespørgsler, der kombinerer information fra flere kilder
- Datatypetvang: Definerede datatyper sikrer, at kun gyldig information gemmes i hver kolonne, hvilket forhindrer fejl og muliggør korrekt sortering
- Dokumentation og vedligeholdelse: Klar dokumentation af tabelstruktur og regelmæssig vedligeholdelse sikrer langvarig anvendelighed og ydeevne
Udvikling og fremtid for tabelbaseret dataorganisering
Fremtiden for tabelbaseret dataorganisering udvikler sig for at imødekomme stadig mere komplekse datakrav, samtidig med at de grundlæggende principper, der gør tabeller effektive, bevares. Kolonnedatabasers lagringsformater som Apache Parquet og ORC bliver standard i big data-miljøer, optimerer tabeller til analytiske arbejdsbelastninger og bevarer tabulær struktur. Semistrukturerede data i JSON- og XML-formater gemmes i stigende grad i tabelkolonner, hvilket gør det muligt for tabeller at rumme både strukturerede og fleksible data. Maskinlæringsintegration gør databaser i stand til automatisk at optimere tabelstrukturer og forespørgselsudførelse baseret på brugsdata. Realtime-analyseplatforme udvider tabeller til at understøtte streamede data og kontinuerlige opdateringer og bevæger sig ud over traditionelle batchorienterede tabeloperationer. Cloud-native databaser redesigner tabelimplementeringer for at udnytte distribueret databehandling, hvilket gør det muligt for tabeller at skalere på tværs af flere servere og geografiske regioner. Datagovernance-rammeværker lægger større vægt på tabelmetadata, linjeføringssporing og kvalitetsmålinger for at sikre datatillid. Fremkomsten af AI-drevne dataplatforme skaber nye muligheder for, at tabeller kan fungere som strukturerede kilder til træning af maskinlæringsmodeller, samtidig med at det rejser spørgsmål om, hvordan tabeller bør designes for at levere data af høj kvalitet til træning. Efterhånden som organisationer fortsætter med at generere eksponentielt mere data, forbliver tabeller den grundlæggende struktur til organisering, forespørgsel og analyse af information, med innovationer fokuseret på at forbedre ydeevne, skalerbarhed og integration med moderne datateknologier.