
AI-indholdsdetektion
Lær hvad AI-indholdsdetektion er, hvordan detektionsværktøjer fungerer med maskinlæring og NLP, og hvorfor de er vigtige for brandovervågning, uddannelse og ver...
12 min læsning
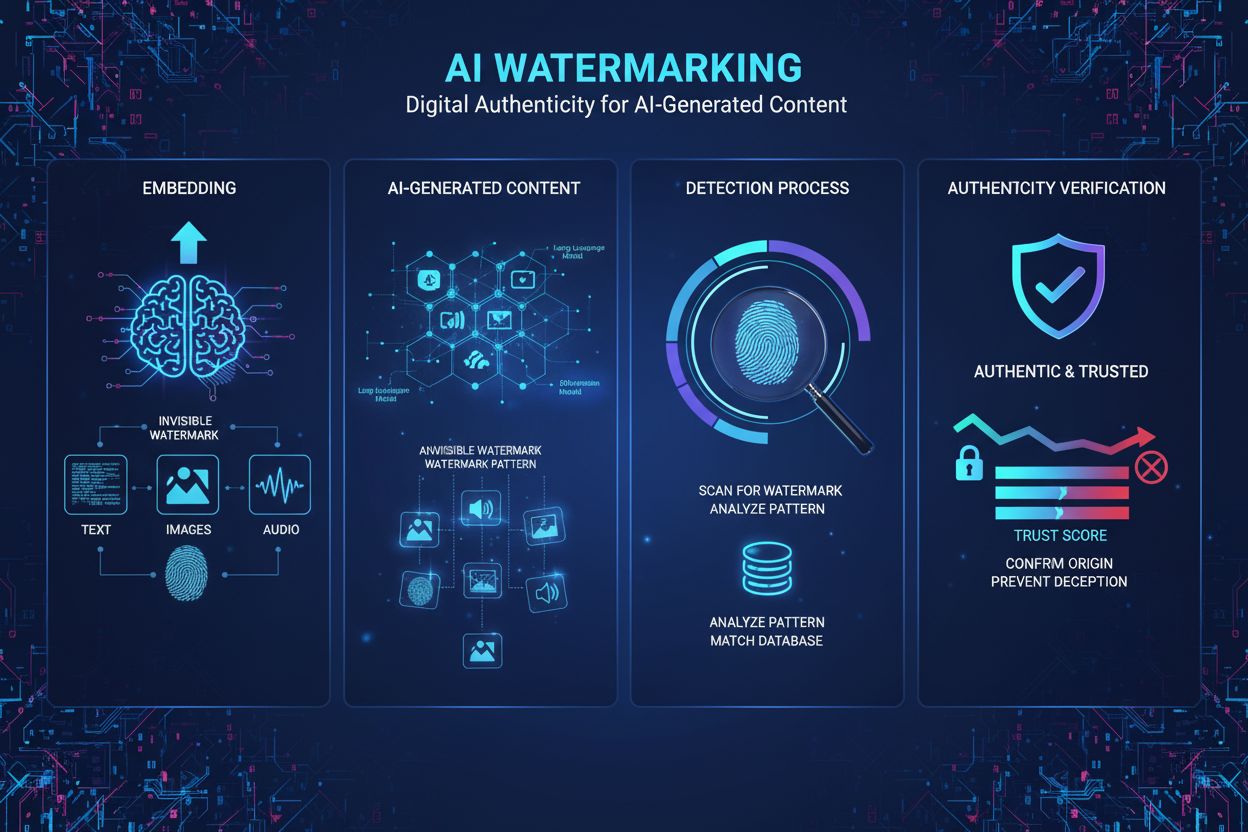
Vandmærkning af AI-indhold er processen, hvor usynlige eller synlige digitale markører indlejres i AI-genereret tekst, billeder, lyd eller video for at identificere og autentificere indholdet som maskin-genereret. Disse vandmærker fungerer som digitale fingeraftryk, der muliggør detektion, verificering og sporing af AI-genereret materiale på tværs af platforme og applikationer.
Vandmærkning af AI-indhold er processen, hvor usynlige eller synlige digitale markører indlejres i AI-genereret tekst, billeder, lyd eller video for at identificere og autentificere indholdet som maskin-genereret. Disse vandmærker fungerer som digitale fingeraftryk, der muliggør detektion, verificering og sporing af AI-genereret materiale på tværs af platforme og applikationer.
Vandmærkning af AI-indhold henviser til processen med at indlejre digitale markører, mønstre eller signaturer i AI-genereret materiale for at identificere, autentificere og spore dets oprindelse. Disse vandmærker fungerer som digitale fingeraftryk, der adskiller maskin-genereret indhold fra menneskeskabt indhold på tværs af tekst, billeder, lyd og videoformater. Det primære formål med AI-indholdsvandmærkning er at sikre gennemsigtighed om indholdets oprindelse, bekæmpe misinformation, beskytte immaterielle rettigheder og sikre ansvarlighed i det hastigt voksende landskab for generativ kunstig intelligens. I modsætning til traditionelle vandmærker, der er synlige på fysiske dokumenter eller billeder, benytter moderne AI-vandmærkningsteknikker ofte usynlige mønstre, som kun kan opdages af specialiserede algoritmer, hvorved indholdskvaliteten bevares samtidig med robuste autentificeringsmuligheder.
Konceptet med vandmærkning opstod i den fysiske verden, hvor usynlige mærker på pengesedler og dokumenter fungerede som foranstaltninger mod forfalskning. I takt med digitalisering af medier tilpassede forskere vandmærkningsteknikker til billeder, lyd og video gennem 1990’erne og 2000’erne. Fremkomsten af avancerede generative AI-modeller som ChatGPT, DALL-E og Midjourney i 2022-2023 skabte dog et akut behov for standardiserede metoder til autentificering af AI-indhold. Den hurtige udvikling af AI, der kan producere mere og mere realistisk syntetisk indhold, fik regeringer, teknologivirksomheder og civilsamfundsorganisationer til at prioritere vandmærkning som et vigtigt værn. Ifølge forskning fra Brookings Institution anerkender over 78% af virksomheder vigtigheden af AI-drevne indholdsovervågningsværktøjer til håndtering af risici ved syntetiske medier. EU’s AI-forordning, formelt vedtaget i marts 2024, blev den første større lovramme, der kræver vandmærkning af AI-indhold og forpligter udbydere af AI-systemer til at markere deres output som AI-genereret. Denne regulatoriske fremdrift har accelereret forskning og udvikling inden for vandmærkningsteknologier, hvor virksomheder som Google DeepMind, OpenAI og Meta investerer betydeligt i robuste vandmærkningsløsninger.
AI-vandmærkning fungerer gennem to primære tekniske tilgange: synlig vandmærkning og usynlig vandmærkning. Synlige vandmærker omfatter tydelige mærkater, logoer eller tekstindikatorer, der tilføjes til indhold – som fx de fem farvede firkanter DALL-E placerer på genererede billeder eller ChatGPT’s indledende sætning “as a language model trained by OpenAI.” Synlige vandmærker er lette at implementere, men kan fjernes uden større besvær ved simpel redigering. Usynlig vandmærkning indlejrer derimod subtile mønstre, der ikke kan opfattes af mennesker, men kan opdages af specialiserede algoritmer. For AI-genererede billeder bruges teknikker som tree-ring-vandmærkning, udviklet på University of Maryland, hvor mønstre indlejres i den tilfældige støj før diffusionsprocessen, hvilket gør dem modstandsdygtige over for beskæring, rotation og filtrering. For AI-genereret tekst er statistisk vandmærkning den mest lovende metode, hvor sprogmodellen subtilt favoriserer bestemte tokens (“grønne tokens”), mens andre (“røde tokens”) undgås baseret på forudgående kontekst. Dette skaber en statistisk usædvanlig ordsammensætning, som detektionsalgoritmer nemt kan identificere. Lydvandmærkning indlejrer umærkelige mønstre i frekvensområder uden for den menneskelige hørelse (under 20 Hz eller over 20.000 Hz), hvilket minder om billedvandmærkning, men er tilpasset akustiske egenskaber. SynthID-teknologien fra Google DeepMind er et eksempel på moderne vandmærkning, hvor genererings- og detektionsmodeller trænes sammen, så robusthed over for transformationer sikres, samtidig med at indholdskvaliteten bevares.
| Vandmærkningsmetode | Indholdstype | Robusthed | Kvalitetspåvirkning | Kræver modeladgang | Detektionsevne |
|---|---|---|---|---|---|
| Synlig vandmærkning | Billeder, Video | Meget lav | Ingen | Nej | Høj (Menneskelig) |
| Statistisk vandmærkning | Tekst, Billeder | Høj | Minimal | Ja | Høj (Algoritmisk) |
| Maskinlæringsbaseret | Billeder, Lyd | Høj | Minimal | Ja | Høj (Algoritmisk) |
| Tree-ring-vandmærkning | Billeder | Meget høj | Ingen | Ja | Høj (Algoritmisk) |
| Indholdsoprindelse (C2PA) | Alle medier | Mellem | Ingen | Nej | Mellem (Metadata) |
| Post-hoc detektion | Alle medier | Lav | Ikke relevant | Nej | Lav (Upålidelig) |
Statistisk vandmærkning er den mest levedygtige teknik til autentificering af AI-genereret tekst, da tekst mangler det dimensionsrum, som billeder eller lyd har til at indlejre mønstre. Under genereringsprocessen får en sprogsmodel instruktioner om at favorisere bestemte tokens baseret på en kryptografisk nøgle, der kun er kendt af modeludvikleren. Modellens tilfældighed “lades” ifølge dette skema, så den foretrækker specifikke ord eller fraser og undgår andre. Detektionsprotokoller analyserer den genererede tekst for at beregne sandsynligheden for, at de observerede token-mønstre opstår tilfældigt; statistisk usandsynlige mønstre indikerer et vandmærke. Forskning fra University of Maryland og OpenAI har vist, at denne metode kan opnå høj detektionsnøjagtighed uden at gå på kompromis med tekstkvaliteten. Dog har statistisk vandmærkning af tekst iboende begrænsninger: faktuelle svar med begrænset genereringsfleksibilitet (f.eks. matematiske løsninger eller historiske fakta) er sværere at vandmærke effektivt, og grundig omskrivning eller oversættelse til andre sprog kan markant reducere detektionssikkerheden. SynthID Text, nu tilgængelig i Hugging Face Transformers v4.46.0+, tilbyder produktionsklar vandmærkning med konfigurerbare parametre, herunder kryptografiske nøgler og n-gram-længde for at balancere robusthed og detektionsevne.
AI-genererede billeder drager fordel af mere avancerede vandmærkningsmetoder på grund af det høje dimensionsrum til indlejring af mønstre. Tree-ring-vandmærkning indlejrer skjulte mønstre i det tilfældige billede før diffusionsprocessen, hvilket skaber vandmærker, der overlever almindelige transformationer som beskæring, sløring og rotation uden at forringe billedkvaliteten. Maskinlæringsbaseret vandmærkning fra Meta og Google bruger neurale netværk til at indlejre og opdage umærkelige vandmærker, hvilket opnår over 96% nøjagtighed på uændrede billeder og samtidig forbliver modstandsdygtig over for pixelbaserede angreb. Lydvandmærkning bygger på lignende principper og indlejrer mønstre i frekvensområder uden for menneskets hørelse. AudioSeal, udviklet af Meta, træner generator- og detektormodeller sammen for at skabe vandmærker, der er robuste over for naturlige lydtransformationer, samtidig med at lydkvaliteten forbliver uændret. Teknologien anvender perceptuelt tab for at sikre, at vandmærket lyd lyder identisk med originalen, og lokalisationstab for at detektere vandmærker uanset forstyrrelser. Disse metoder viser, at usynlig vandmærkning kan opnå både robusthed og kvalitet, når de implementeres korrekt, men de kræver adgang til den underliggende AI-model for at indlejre vandmærket.
Det lovgivningsmæssige miljø for vandmærkning af AI-indhold har udviklet sig hurtigt, og flere jurisdiktioner har indført eller foreslået obligatoriske krav om vandmærkning. EU AI-forordningen, formelt vedtaget i marts 2024, er den mest omfattende lovramme og kræver, at udbydere af AI-systemer markerer deres output som AI-genereret indhold. Denne regulering gælder alle generative AI-systemer anvendt inden for EU og etablerer en juridisk forpligtelse til at overholde vandmærkning. Californiens AI Transparency Act (SB 942), gældende fra 1. januar 2026, kræver, at relevante AI-udbydere stiller gratis, offentligt tilgængelige AI-indholdsdetektionsværktøjer til rådighed, hvilket reelt kræver vandmærkning eller tilsvarende autentificeringsmekanismer. U.S. National Defense Authorization Act (NDAA) for regnskabsåret 2024 indeholder bestemmelser om en konkurrence til evaluering af vandmærkningsteknologi og pålægger forsvarsministeriet at undersøge og afprøve implementering af “industriens åbne tekniske standarder” til indlejring af informationsoprindelse i metadata. Det Hvide Hus’ bekendtgørelse om AI pålægger handelsministeriet at identificere og udvikle standarder for mærkning af AI-genereret indhold. Disse lovinitiativer afspejler en stigende enighed om, at AI-vandmærkning er afgørende for gennemsigtighed, ansvarlighed og forbrugerbeskyttelse. Dog udestår fortsatte implementeringsudfordringer, især i forhold til open source-modeller, international koordinering og teknisk gennemførlighed af universelle vandmærkningsstandarder.
Trods betydelige tekniske fremskridt står AI-vandmærkning over for væsentlige begrænsninger, der begrænser dens praktiske effektivitet. Fjernelse af vandmærker er fortsat mulig gennem forskellige omgåelsesteknikker: parafrasering af tekst, beskæring eller filtrering af billeder, oversættelse af indhold til andre sprog eller anvendelse af adversarielle forstyrrelser. Forskning fra Duke University har demonstreret proof-of-concept-angreb mod maskinlæringsbaserede vandmærkedetektorer, hvilket indikerer, at selv avancerede metoder er sårbare over for målrettede aktører. Manglen på universelle løsninger er en anden væsentlig begrænsning – detektorer er modelspecifikke, hvilket betyder, at brugere skal kontakte hver AI-udbyders detektionsservice separat for at verificere indholdets oprindelse. Uden et centralt register og standardiserede detektionsprotokoller bliver verifikation af AI-genereret indhold en ineffektiv og uformel proces. Falske positive rater i vandmærkedetektion, især for tekst, er fortsat problematiske; algoritmer kan fejlagtigt markere menneskeskabt indhold som AI-genereret eller undlade at detektere vandmærkede indhold efter små ændringer. Kompatibilitet med open source-modeller udgør en styringsmæssig udfordring, da vandmærker kan fjernes ved at slette kode fra downloadede modeller. Kvalitetsforringelse kan forekomme, når vandmærkningsalgoritmer kunstigt begrænser modeloutput for at indlejre detekterbare mønstre, hvilket kan reducere indholdskvaliteten eller begrænse genereringsfleksibiliteten for faktuelle eller begrænsede outputopgaver. Privatlivsimplicationer ved vandmærkning – især hvis vandmærker indeholder brugeridentifikation – kræver omhyggelig politisk overvejelse. Derudover falder detektionssikkerheden markant med indholdslængden; kortere tekster og stærkt modificeret indhold giver lavere detektionssikkerhed, hvilket begrænser vandmærkningens nytte i visse anvendelser.
Fremtiden for AI-vandmærkning afhænger af fortsat teknisk innovation, regulatorisk harmonisering og etablering af betroet infrastruktur til detektion og verifikation af vandmærker. Forskere undersøger offentligt detekterbare vandmærker, der bevarer robustheden, selv om detektionsmetoder offentliggøres, hvilket potentielt muliggør decentraliseret verifikation uden tillid til tredjepartsdetektionsservices. Standardiseringsinitiativer via organisationer som ICANN eller branchekonsortier kan etablere universelle vandmærkningsprotokoller, reducere fragmentering og muliggøre effektiv detektion på tværs af platforme. Integration med indholdsoprindelsesstandarder som C2PA kan skabe lagdelte autentificeringsmetoder, der kombinerer vandmærker med metadata-baseret oprindelsessporing. Udvikling af vandmærker, der er robuste over for oversættelse og parafrasering, er et aktivt forskningsområde med potentielle anvendelser i flersproget indholdsauthenticering. Blockchain-baserede verifikationssystemer kan levere uforanderlige registreringer af detektion og oprindelse, hvilket styrker tilliden til autentificeringsresultater. I takt med at generative AI-evner udvikler sig, skal vandmærkningsteknikker tilpasses for at forblive effektive mod stadig mere avancerede omgåelsesforsøg. Den regulatoriske fremdrift, der er skabt af EU AI-forordningen og californisk lovgivning, vil sandsynligvis drive global vedtagelse af vandmærkningsstandarder og skabe incitamenter for robuste tekniske løsninger. Realistisk set vil vandmærkning dog primært kunne håndtere AI-genereret indhold fra populære kommercielle modeller, mens nytten vil være begrænset i højrisikosituationer, hvor øjeblikkelig detektion kræves. Integration af AI-indholdsovervågningsplatforme som AmICited med vandmærkningsinfrastruktur gør det muligt for organisationer at spore brandattribution på tværs af AI-systemer og sikre korrekt anerkendelse, når deres domæner optræder i AI-genererede svar. Fremtidige udviklinger vil sandsynligvis understrege samarbejde mellem mennesker og AI i indholdsautentificering, hvor automatiseret vandmærkedetektion kombineres med menneskelig verifikation til kritiske anvendelser i journalistik, retssager og akademisk integritet.
Synlige vandmærker er lette for mennesker at opdage, såsom logoer eller tekstetiketter tilføjet til billeder eller lydklip, men de er nemme at fjerne eller forfalske. Usynlige vandmærker indlejrer subtile mønstre, der er umærkelige for mennesker, men kan opdages af specialiserede algoritmer, hvilket gør dem betydeligt mere robuste over for manipulation og fjernelsesforsøg. Usynlige vandmærker foretrækkes generelt til autentificering af AI-indhold, da de bevarer indholdskvaliteten og samtidig giver stærkere sikkerhed mod omgåelse.
Statistisk vandmærkning for tekst fungerer ved diskret at påvirke sprogmodellens valg af tokens under genereringen. Modeludvikleren "lader terningen" ved hjælp af et kryptografisk skema, så modellen favoriserer bestemte "grønne tokens" og undgår "røde tokens" baseret på forudgående kontekst. Detektionsalgoritmer analyserer derefter teksten for at identificere, om favoriserede tokens optræder med statistisk usædvanlig hyppighed, hvilket indikerer tilstedeværelsen af et vandmærke. Denne tilgang bevarer tekstkvaliteten og indlejrer samtidig et detekterbart fingeraftryk.
Nøgleudfordringer inkluderer den lette fjernelse af vandmærker gennem mindre redigeringer eller transformationer, manglen på universel detektion på tværs af forskellige AI-modeller samt vanskeligheden ved at vandmærke tekst sammenlignet med billeder eller lyd. Derudover kræver vandmærkning samarbejde fra AI-modeludviklere, er inkompatibel med open source-modeller og kan forringe indholdskvalitet, hvis det ikke implementeres omhyggeligt. Falske positiver og falske negativer i detektionen udgør også betydelige tekniske udfordringer.
EU AI-forordningen, formelt vedtaget i marts 2024, kræver, at udbydere af AI-systemer markerer deres output som AI-genereret indhold. Californiens AI Transparency Act (SB 942), gældende fra 1. januar 2026, forpligter relevante AI-udbydere til at stille gratis, offentligt tilgængelige indholdsdetektionsværktøjer til rådighed. Den amerikanske National Defense Authorization Act (NDAA) for regnskabsåret 2024 indeholder bestemmelser om evaluering af vandmærkningsteknologi og udvikling af industristandarder for indholdsoprindelse.
Vandmærkning indlejrer identificerende mønstre direkte i AI-genereret indhold, hvilket skaber et permanent digitalt fingeraftryk, der bevares, selv hvis indholdet kopieres eller ændres. Indholdsoprindelse, såsom C2PA-standarden, gemmer metadata om indholdets oprindelse og ændringshistorik separat i filmetadata. Vandmærkning er mere robust over for omgåelse, men kræver samarbejde fra modeludviklere, mens oprindelse er lettere at implementere, men kan fjernes ved at kopiere indhold uden metadata.
SynthID er Google DeepMinds teknologi, der vandmærker og identificerer AI-genereret indhold ved at indlejre digitale vandmærker direkte i billeder, lyd, tekst og video. For tekst bruger SynthID en logits-processor, der udvider modellens genereringspipeline for at indkode vandmærkningsinformation uden væsentlig påvirkning af kvaliteten. Teknologien anvender maskinlæringsmodeller til både at indlejre og detektere vandmærker, hvilket gør den modstandsdygtig over for almindelige angreb samtidig med, at indholdets troværdighed bevares.
Ja, motiverede aktører kan fjerne eller omgå vandmærker gennem forskellige teknikker, herunder parafrasering af tekst, beskæring eller filtrering af billeder eller oversættelse af indhold til andre sprog. Dog kræver fjernelse af sofistikerede vandmærker teknisk ekspertise og kendskab til vandmærkningsskemaet. Statistiske vandmærker er mere robuste end traditionelle metoder, men forskning har vist proof-of-concept-angreb på selv avancerede vandmærkningsmetoder, hvilket indikerer, at ingen vandmærkningsteknik er fuldstændig ufejlbarlig.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvad AI-indholdsdetektion er, hvordan detektionsværktøjer fungerer med maskinlæring og NLP, og hvorfor de er vigtige for brandovervågning, uddannelse og ver...

Lær om AI-indholdslicensaftaler, der regulerer, hvordan kunstig intelligens bruger ophavsretligt beskyttet indhold. Udforsk licenstyper, nøgleelementer, platfor...
Lær hvad AI-indholdsgenerering er, hvordan det fungerer, dets fordele og udfordringer, og bedste praksis for at bruge AI-værktøjer til at skabe marketingindhold...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.