
AI-Crawler-Referenzkarte: Alle Bots auf einen Blick
Vollständiger Referenzleitfaden zu AI-Crawlern und Bots. Identifizieren Sie GPTBot, ClaudeBot, Google-Extended und 20+ weitere AI-Crawler mit User-Agents, Crawl...
15 Min. Lesezeit

Entdecken Sie die entscheidenden Unterschiede zwischen KI-Trainingscrawlern und Suchcrawlern. Erfahren Sie, wie sie die Sichtbarkeit Ihrer Inhalte, Optimierungsstrategien und KI-Zitationen beeinflussen.
Suchmaschinen-Crawler wie Googlebot und Bingbot bilden das Rückgrat traditioneller Suchmaschinen. Diese automatisierten Bots navigieren systematisch durchs Web, entdecken und indexieren Inhalte, um festzulegen, was in den Suchergebnisseiten (SERPs) erscheint. Googlebot, betrieben von Google, ist der bekannteste und aktivste Suchcrawler, gefolgt von Bingbot von Microsoft und YandexBot von Yandex. Diese Crawler verfügen über ausgefeilte Fähigkeiten, die es ihnen erlauben, JavaScript auszuführen, dynamische Inhalte zu rendern und komplexe Website-Strukturen zu verstehen. Sie besuchen Websites häufig, abhängig von Faktoren wie Seitenautorität, Aktualität der Inhalte und Update-Historie – Seiten mit hoher Autorität werden häufiger gecrawlt. Das Hauptziel von Suchcrawlern ist das Indexieren von Inhalten für Ranking-Zwecke; das heißt, sie bewerten Seiten anhand von Relevanz, Qualität und Nutzererfahrungssignalen.
| Crawler-Typ | Hauptzweck | JavaScript-Unterstützung | Crawl-Frequenz | Ziel |
|---|---|---|---|---|
| Googlebot | Indexierung für Suchrankings | Ja (mit Einschränkungen) | Häufig, abhängig von Autorität | Ranking & Sichtbarkeit |
| Bingbot | Indexierung für Suchrankings | Ja (mit Einschränkungen) | Regelmäßig, abhängig von Inhaltsaktualisierungen | Ranking & Sichtbarkeit |
| YandexBot | Indexierung für Suchrankings | Ja (mit Einschränkungen) | Regelmäßig, abhängig von Seitensignalen | Ranking & Sichtbarkeit |
KI-Trainingscrawler stellen eine grundlegend andere Kategorie von Web-Bots dar, die darauf ausgelegt sind, Daten zum Training großer Sprachmodelle (LLMs) zu sammeln, nicht für die Suchindexierung. GPTBot, betrieben von OpenAI, ist der bekannteste KI-Trainingscrawler, daneben gibt es ClaudeBot von Anthropic, PetalBot von Huawei und CCBot von Common Crawl. Im Gegensatz zu Suchcrawlern, die Inhalte für Rankings erfassen, konzentrieren sich KI-Trainingscrawler auf das Sammeln hochwertiger, kontextuell reichhaltiger Informationen, um die Wissensbasis und Antwortfähigkeiten von KI-Modellen zu verbessern. Diese Crawler agieren in der Regel seltener als Suchcrawler, besuchen eine Website oft nur alle paar Wochen oder Monate, und priorisieren die Inhaltsqualität vor der Masse. Das ist entscheidend: Während Ihre Inhalte von Googlebot gründlich für Suchsichtbarkeit indexiert werden, werden sie von GPTBot möglicherweise nur teilweise oder selten für das Training von KI-Modellen gecrawlt.
| Crawler-Typ | Hauptzweck | JavaScript-Unterstützung | Crawl-Frequenz | Ziel |
|---|---|---|---|---|
| GPTBot | Datensammlung für LLM-Training | Nein | Selten, selektiv | Trainingsdaten-Qualität |
| ClaudeBot | Datensammlung für LLM-Training | Nein | Selten, selektiv | Trainingsdaten-Qualität |
| PetalBot | Datensammlung für LLM-Training | Nein | Selten, selektiv | Trainingsdaten-Qualität |
| CCBot | Datensammlung für Common Crawl | Nein | Selten, selektiv | Trainingsdaten-Qualität |
Die technischen Unterschiede zwischen Such- und KI-Trainingscrawlern haben erhebliche Auswirkungen auf die Sichtbarkeit von Inhalten. Der wichtigste Unterschied ist die JavaScript-Ausführung: Suchcrawler wie Googlebot können JavaScript ausführen (wenn auch mit Einschränkungen) und so dynamisch gerenderte Inhalte erfassen. KI-Trainingscrawler hingegen führen überhaupt kein JavaScript aus – sie parsen nur das rohe HTML, das beim ersten Laden der Seite verfügbar ist. Das bedeutet: Inhalte, die dynamisch über clientseitige Skripte geladen werden, sind für KI-Crawler völlig unsichtbar. Darüber hinaus respektieren Suchcrawler das Crawl-Budget und priorisieren Seiten nach Seitenarchitektur und interner Verlinkung, während KI-Crawler selektiver und qualitätsorientierter crawlen. Suchcrawler halten sich meist strikt an robots.txt-Vorgaben, während einige KI-Crawler in der Vergangenheit weniger transparent bezüglich ihrer Compliance waren. Die Crawl-Frequenz unterscheidet sich deutlich: Suchcrawler besuchen aktive Seiten mehrmals pro Woche oder sogar täglich, während KI-Trainingscrawler oft nur alle paar Wochen oder Monate vorbeikommen. Suchcrawler sind außerdem darauf ausgelegt, Rankingsignale und Nutzererfahrungsmetriken zu verstehen, während KI-Crawler sich darauf konzentrieren, saubere, gut strukturierte Textinhalte für das Modelltraining zu extrahieren.
| Merkmal | Suchcrawler | KI-Trainingscrawler |
|---|---|---|
| JavaScript-Ausführung | Ja (mit Einschränkungen) | Nein |
| Crawl-Frequenz | Hoch (mehrmals pro Woche) | Niedrig (einmal alle paar Wochen) |
| Inhalts-Parsing | Komplette Seitenrendering | Nur rohes HTML |
| robots.txt-Einhaltung | Strikt | Variabel |
| Crawl-Budget-Fokus | Priorisierung nach Autorität | Qualitätsbasierte Auswahl |
| Dynamische Inhalte | Können gerendert & indexiert werden | Werden vollständig übersehen |
| Hauptziel | Ranking & Suchsichtbarkeit | Datensammlung fürs Training |
| Timeout-Toleranz | Länger (erlaubt komplexes Rendering) | Streng (1–5 Sekunden) |
Die Unfähigkeit von KI-Crawlern, JavaScript auszuführen, schafft eine kritische Sichtbarkeitslücke für viele moderne Websites. Wenn eine Website JavaScript verwendet, um Inhalte dynamisch zu laden – etwa Produktbeschreibungen, Kundenbewertungen, Preisinformationen oder Bilder – werden diese Inhalte für KI-Crawler unsichtbar. Besonders problematisch ist dies für Single-Page-Applications (SPAs) auf Basis von React, Vue oder Angular, bei denen die meisten Inhalte erst clientseitig nach dem initialen HTML-Laden erscheinen. Zum Beispiel zeigt ein E-Commerce-Shop die Produktverfügbarkeit und Preise über JavaScript an – GPTBot sieht dann nur eine leere Seite oder das Grundgerüst des HTMLs. Ebenso werden Websites, die Lazy-Loading für Bilder oder Infinite Scroll für Inhalte nutzen, von KI-Crawlern in diesen Bereichen komplett übersehen. Die geschäftlichen Auswirkungen sind erheblich: Sind Ihre Produktdetails, Kundenstimmen oder wichtige Inhalte hinter JavaScript verborgen, haben KI-Systeme wie ChatGPT und Perplexity keinen Zugriff darauf – und Ihre Informationen tauchen in KI-generierten Antworten nicht auf. So kann es passieren, dass Sie in Google gut ranken, aber in KI-Antworten völlig fehlen und für Nutzer, die auf KI zur Informationsbeschaffung setzen, unsichtbar bleiben.
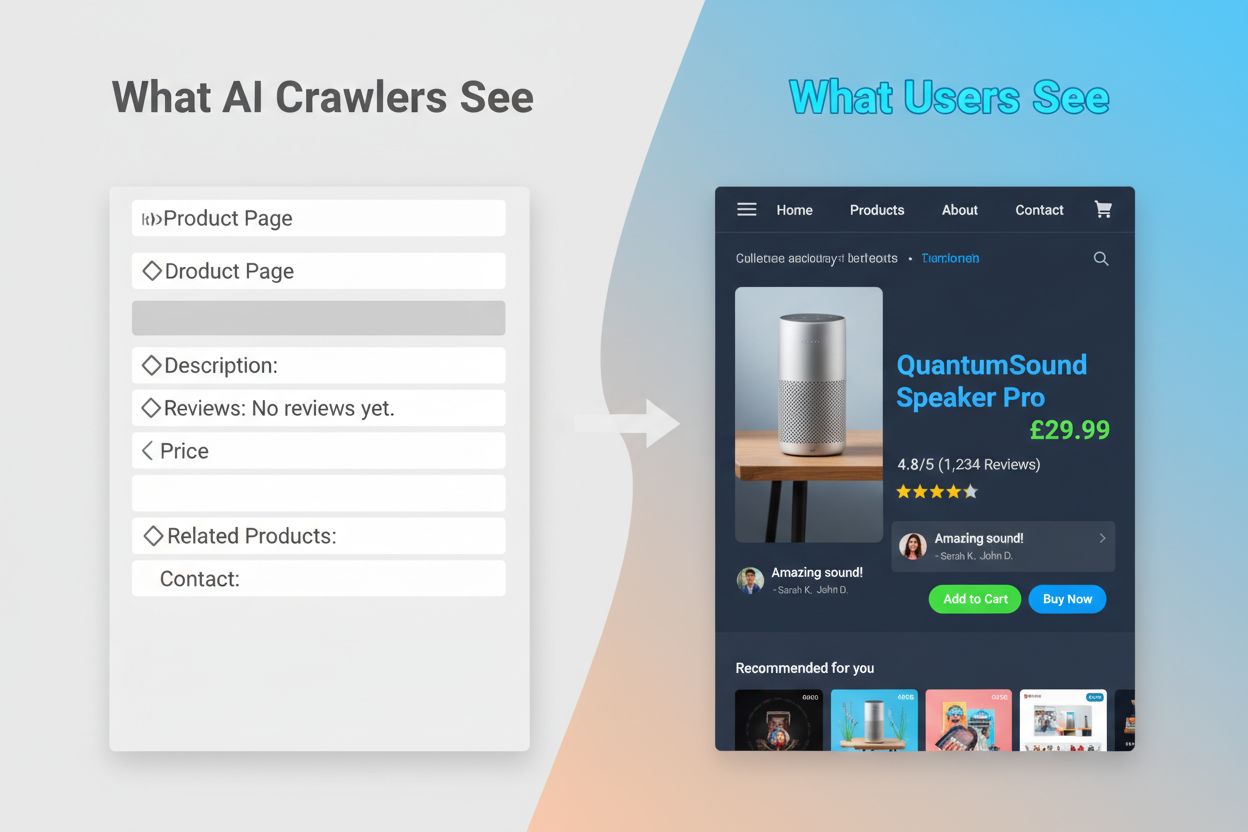
Die praktischen Folgen dieser technischen Unterschiede sind tiefgreifend und werden von Website-Betreibern oft unterschätzt. Ihre Website kann in Google exzellente Rankings erzielen, während sie für ChatGPT, Perplexity und andere KI-Systeme nahezu unsichtbar bleibt. Es entsteht ein Paradoxon: Traditioneller SEO-Erfolg garantiert keine Sichtbarkeit in KI-Systemen. Fragt ein Nutzer ChatGPT nach Ihrer Branche oder Ihrem Produkt, kann es sein, dass die KI stattdessen Ihre Konkurrenten zitiert – einfach weil deren Inhalte für KI-Crawler zugänglicher waren. Das Verhältnis zwischen Trainingsdaten und Suchzitaten schafft zusätzliche Komplexität: Inhalte, die für das Training eines KI-Modells verwendet wurden, können in dessen Suchergebnissen bevorzugt werden, sodass das Blockieren von KI-Trainingscrawlern Ihre Sichtbarkeit in KI-Antworten verringern könnte. Für Publisher und Content-Ersteller bedeutet das: Die strategische Entscheidung, KI-Crawler zuzulassen oder zu blockieren, hat reale Folgen für künftigen Traffic. Eine Website, die GPTBot blockiert, um Inhalte zu schützen, verringert damit gleichzeitig die Chance, in ChatGPT-Suchergebnissen aufzutauchen. Umgekehrt liefert das Zulassen von KI-Crawlern zwar Trainingsdaten, garantiert aber keine Zitationen oder Traffic – ein echtes strategisches Dilemma ohne perfekte Lösung.
Zu verstehen, welche Crawler Ihre Website besuchen und wie häufig, ist essenziell, um Ihre Content-Strategie zu optimieren. Die Logfile-Analyse ist das wichtigste Mittel zur Identifikation von Crawler-Aktivitäten: Sie ermöglicht es, Server-Logs zu segmentieren und zu parsen, um zu sehen, welche Bots Ihre Seite wann und mit welchem Fokus besucht haben. Über die User-Agent-Strings in den Server-Logs können Sie Googlebot, GPTBot, OAI-SearchBot und andere Crawler unterscheiden und Verhaltensmuster erkennen. Wichtige Kennzahlen sind Crawl-Frequenz (wie oft besucht jeder Crawler Ihre Seite), Crawl-Tiefe (wie viele Ebenen Ihrer Seitenstruktur werden gecrawlt) und Crawl-Budget (wie viele Seiten werden in einem bestimmten Zeitraum gecrawlt). Tools wie die Google Search Console und Bing Webmaster Tools geben Einblicke in Suchcrawler-Aktivitäten, während spezialisierte Lösungen wie AmICited.com eine umfassende Überwachung von KI-Crawlern über verschiedene Plattformen hinweg bieten – inklusive ChatGPT, Perplexity und Google AI Overviews. AmICited.com verfolgt gezielt, wie KI-Systeme Ihre Marke und Inhalte referenzieren und wie oft. Diese Einblicke helfen dabei, technische Probleme frühzeitig zu erkennen, das Crawl-Budget optimal einzusetzen und informierte Entscheidungen zu Crawler-Zugängen und Content-Optimierung zu treffen.
Die Optimierung für traditionelle Suchcrawler erfordert den Fokus auf bewährte technische SEO-Grundlagen, damit Ihre Inhalte auffindbar und indexierbar sind. Die folgenden Strategien bleiben entscheidend für eine starke Suchsichtbarkeit:
Suchmaschinen wie Google legen zunehmend Wert auf Crawleffizienz. Google-Vertreter weisen darauf hin, dass Googlebot künftig weniger crawlen wird. Ihre Website sollte also möglichst schlank und verständlich aufgebaut sein, mit klaren Hierarchien und effizienter interner Verlinkung, die Crawler direkt zu Ihren wichtigsten Seiten führen.
Die Optimierung für KI-Trainingscrawler erfordert einen anderen Ansatz, der auf Inhaltsqualität, Klarheit und Zugänglichkeit statt auf Rankingsignale abzielt. Da KI-Crawler gut strukturierte, kontextreiche Inhalte priorisieren, sollte Ihre Strategie auf Vollständigkeit und Lesbarkeit setzen. Vermeiden Sie JavaScript-abhängige Inhalte für kritische Informationen – stellen Sie sicher, dass Produktdetails, Preise, Bewertungen und wichtige Daten im rohen HTML stehen, sodass KI-Crawler darauf zugreifen können. Erstellen Sie umfassende, tiefgehende Inhalte, die Themen gründlich behandeln und Kontext liefern, von dem KI-Modelle lernen können. Nutzen Sie klare Formatierung mit Überschriften, Aufzählungen und Nummerierungen, um Texte leicht parsen zu lassen. Schreiben Sie semantisch klar und verwenden Sie eine verständliche Sprache ohne übermäßigen Jargon, der KI-Modelle verwirren könnte. Implementieren Sie eine saubere Überschriftenhierarchie (H1, H2, H3), damit KI-Crawler die Struktur und Zusammenhänge Ihrer Inhalte erkennen. Fügen Sie relevante Metadaten und Schema-Markup hinzu, das Kontext zu Ihren Inhalten bietet. Sorgen Sie für schnelle Ladezeiten, da KI-Crawler strenge Timeouts (typisch 1–5 Sekunden) haben und langsame Seiten überspringen können.
Der große Unterschied zur Suchoptimierung: KI-Crawler interessieren sich nicht für Rankingsignale, Backlinks oder Keyword-Dichte. Sie schätzen Inhalte, die klar, gut organisiert und informationsreich sind. Eine Seite, die in Google nicht gut rankt, kann für KI-Modelle äußerst wertvoll sein, wenn sie umfassende, gut strukturierte Informationen zu einem Thema bietet.
Die Landschaft des Web-Crawlings entwickelt sich rasant. KI-Crawler werden für die Sichtbarkeit von Inhalten und Markenbekanntheit immer wichtiger. Mit der steigenden Nutzung KI-gesteuerter Suchtools wie ChatGPT, Perplexity und Google AI Overviews wird es genauso entscheidend wie traditionelle Suchrankings, dort gefunden und zitiert zu werden. Die Unterscheidung zwischen Trainingscrawlern und Suchcrawlern wird vermutlich noch feiner werden, mit potenziell klarerer Trennung zwischen Datensammlung und Suchabruf – ähnlich wie OpenAI es mit GPTBot und OAI-SearchBot macht. Website-Betreiber müssen Strategien entwickeln, die traditionelle SEO-Optimierung und KI-Sichtbarkeit ausbalancieren und erkennen, dass beides sich ergänzt und nicht ausschließt. Die Entstehung spezialisierter Monitoring-Tools und Lösungen erleichtert es, Crawler-Aktivitäten sowohl auf traditionellen als auch auf KI-Plattformen zu verfolgen und datenbasierte Entscheidungen zu Crawler-Zugängen und Content-Optimierung zu treffen. Wer jetzt sowohl für Such- als auch für KI-Crawler optimiert, verschafft sich einen Wettbewerbsvorteil und sorgt dafür, dass seine Inhalte über mehrere Kanäle gefunden werden – während sich die Suchlandschaft weiterentwickelt. Die Zukunft der Sichtbarkeit von Inhalten hängt davon ab, das gesamte Spektrum der Crawler zu verstehen und für sie zu optimieren.
Suchcrawler wie Googlebot indexieren Inhalte für Suchrankings und können JavaScript ausführen, um dynamische Inhalte zu sehen. KI-Trainingscrawler wie GPTBot sammeln Daten zum Trainieren von LLMs und können in der Regel kein JavaScript ausführen, wodurch ihnen dynamisch geladene Inhalte entgehen. Dieser grundlegende Unterschied bedeutet, dass Ihre Website bei Google gut ranken kann, aber für ChatGPT nahezu unsichtbar ist.
Ja, Sie können robots.txt verwenden, um bestimmte KI-Crawler wie GPTBot zu blockieren und gleichzeitig Suchcrawler zuzulassen. Dies kann jedoch Ihre Sichtbarkeit in KI-generierten Antworten und Zusammenfassungen verringern. Der strategische Kompromiss hängt davon ab, ob Sie den Schutz Ihrer Inhalte höher gewichten als potenziellen KI-Traffic.
KI-Crawler wie GPTBot parsen nur das rohe HTML beim ersten Laden der Seite und führen kein JavaScript aus. Inhalte, die dynamisch über Skripte geladen werden – z. B. Produktdetails, Bewertungen oder Bilder – bleiben für sie völlig unsichtbar. Dies ist eine entscheidende Einschränkung für moderne Websites, die stark auf Client-Side-Rendering setzen.
KI-Trainingscrawler besuchen in der Regel seltener als Suchcrawler, mit längeren Intervallen zwischen den Besuchen. Sie priorisieren hochwertige Inhalte und crawlen eine Seite möglicherweise nur alle paar Wochen oder Monate. Dieses seltene Crawling-Muster spiegelt ihren Fokus auf Qualität statt Quantität wider.
Produktdetails, Kundenbewertungen, lazy-geladene Bilder, interaktive Elemente (Tabs, Karussells, Modale), Preisinformationen und alle Inhalte, die hinter JavaScript verborgen sind, sind besonders gefährdet. Für E-Commerce- und SPA-basierte Websites kann dies einen erheblichen Teil der wichtigsten Inhalte ausmachen.
Stellen Sie sicher, dass wichtige Inhalte im rohen HTML vorhanden sind, verbessern Sie die Seitengeschwindigkeit, verwenden Sie eine klare Struktur und Formatierung mit korrekter Überschriftenhierarchie, implementieren Sie Schema-Markup und vermeiden Sie JavaScript-abhängige kritische Inhalte. Ziel ist es, Ihre Inhalte sowohl für traditionelle als auch für KI-Crawler zugänglich zu machen.
Logfile-Analyse-Tools, die Google Search Console, Bing Webmaster Tools und spezialisierte Lösungen wie AmICited.com helfen, das Crawler-Verhalten zu verfolgen. AmICited.com überwacht speziell, wie KI-Systeme Ihre Marke in ChatGPT, Perplexity und Google AI Overviews referenzieren.
Potentiell ja. Während das Blockieren von Trainingscrawlern Ihre Inhalte schützt, könnte es Ihre Sichtbarkeit in KI-basierten Suchergebnissen und Zusammenfassungen verringern. Außerdem bleiben Inhalte, die bereits vor dem Blockieren gecrawlt wurden, in trainierten Modellen erhalten. Die Entscheidung erfordert eine Abwägung zwischen Inhaltschutz und potenziellem Verlust von KI-Traffic.
Verfolgen Sie, wie KI-Systeme Ihre Marke in ChatGPT, Perplexity und Google AI Overviews referenzieren. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Sichtbarkeit und optimieren Sie Ihre Content-Strategie.
Vollständiger Referenzleitfaden zu AI-Crawlern und Bots. Identifizieren Sie GPTBot, ClaudeBot, Google-Extended und 20+ weitere AI-Crawler mit User-Agents, Crawl...

Verstehen Sie, wie KI-Crawler wie GPTBot und ClaudeBot funktionieren, wo sie sich von traditionellen Such-Crawlern unterscheiden und wie Sie Ihre Website für Si...

Erfahren Sie, welche KI-Crawler Sie in Ihrer robots.txt zulassen oder blockieren sollten. Umfassender Leitfaden zu GPTBot, ClaudeBot, PerplexityBot und 25+ KI-C...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.