
AI-Crawler-Zugriffsprüfung: Sehen die richtigen Bots Ihre Inhalte?
Erfahren Sie, wie Sie den Zugang von KI-Crawlern zu Ihrer Website prüfen. Entdecken Sie, welche Bots Ihre Inhalte sehen können, und beheben Sie Blocker, die die...
8 Min. Lesezeit

Erfahren Sie, wie Sie KI-Crawler wie GPTBot und ClaudeBot mit robots.txt, serverseitiger Blockierung und erweiterten Schutzmethoden blockieren oder zulassen. Vollständiger technischer Leitfaden mit Beispielen.
Die digitale Landschaft hat sich grundlegend von der traditionellen Suchmaschinenoptimierung hin zur Verwaltung einer völlig neuen Kategorie automatisierter Besucher verschoben: KI-Crawler. Anders als herkömmliche Such-Bots, die über Suchergebnisse Traffic auf Ihre Seite lenken, konsumieren KI-Trainings-Crawler Ihre Inhalte, um große Sprachmodelle zu erstellen – ohne zwangsläufig Referral-Traffic zurückzusenden. Dieser Unterschied hat tiefgreifende Auswirkungen für Publisher, Content-Ersteller und Unternehmen, die auf Web-Traffic als Einnahmequelle angewiesen sind. Die Einsätze sind hoch – die Kontrolle darüber, welche KI-Systeme auf Ihre Inhalte zugreifen, wirkt sich direkt auf Ihren Wettbewerbsvorteil, Datenschutz und Ihr Geschäftsergebnis aus.
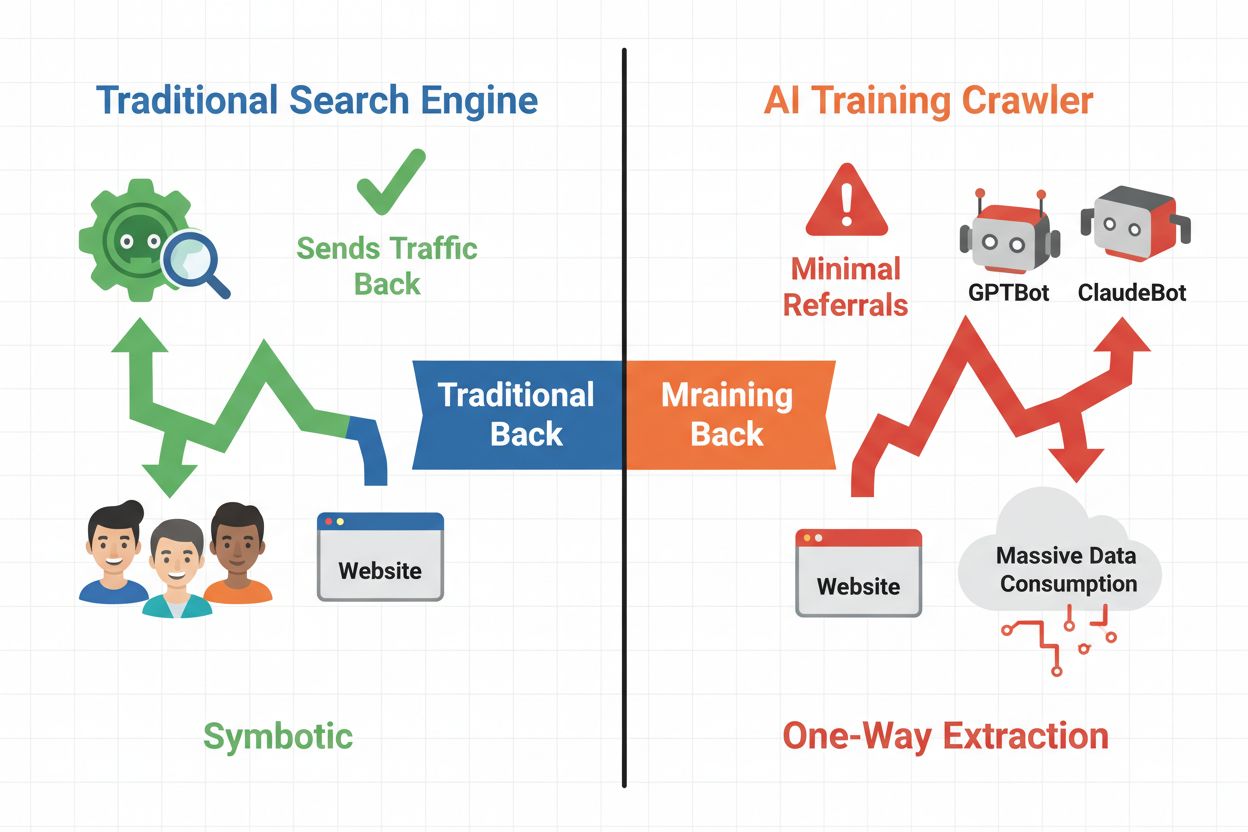
KI-Crawler lassen sich in drei unterschiedliche Kategorien einteilen, die sich hinsichtlich Zweck und Traffic-Auswirkungen unterscheiden. Trainings-Crawler werden von KI-Unternehmen eingesetzt, um ihre Sprachmodelle zu erstellen und zu verbessern, operieren meist im großen Maßstab und liefern nur minimalen Rücklauf-Traffic. Such- und Zitations-Crawler indexieren Inhalte für KI-gestützte Suchmaschinen und Zitationssysteme und führen gelegentlich Traffic zu den Publishern zurück. Nutzergetriebene Crawler rufen Inhalte auf Abruf ab, wenn Nutzer mit KI-Anwendungen interagieren – dies ist ein kleiner, aber wachsender Bereich. Das Verständnis dieser Kategorien hilft Ihnen, fundierte Entscheidungen zu treffen, welche Crawler Sie je nach Geschäftsmodell zulassen oder blockieren sollten.
| Crawler-Typ | Zweck | Traffic-Auswirkung | Beispiele |
|---|---|---|---|
| Training | Aufbau/Verbesserung von LLMs | Minimal bis keiner | GPTBot, ClaudeBot, Bytespider |
| Suche/Zitation | Indexierung für KI-Suche & Zitationen | Mäßiger Referral-Traffic | Googlebot-Extended, Perplexity |
| Nutzergetrieben | Abruf auf Anfrage für Nutzer | Niedrig, aber konstant | ChatGPT-Plugins, Claude-Browsing |
Das KI-Crawler-Ökosystem umfasst Crawler der größten Technologieunternehmen der Welt, jeweils mit eigenen User-Agents und Zwecken. OpenAIs GPTBot (User-Agent: GPTBot/1.0) crawlt zum Trainieren von ChatGPT und anderen Modellen, während ClaudeBot von Anthropic (User-Agent: Claude-Web/1.0) einen ähnlichen Zweck für Claude erfüllt. Googlebot-Extended von Google (User-Agent: Mozilla/5.0 ... Googlebot-Extended) indexiert Inhalte für AI Overviews und Bard, während Meta-ExternalFetcher für die KI-Initiativen von Meta crawlt. Weitere wichtige Akteure sind:
Jeder Crawler operiert in unterschiedlichem Umfang und hält sich unterschiedlich konsequent an Blockierungsanweisungen.
Die robots.txt-Datei ist Ihre erste Verteidigungslinie zur Steuerung des Zugriffs von KI-Crawlern, wobei Sie beachten sollten, dass sie lediglich empfehlenden Charakter hat und rechtlich nicht bindend ist. Sie befindet sich im Root-Verzeichnis Ihrer Domain (z.B. ihreseite.de/robots.txt) und verwendet eine einfache Syntax, um Crawler anzuweisen, welche Bereiche gemieden werden sollen. Um alle KI-Crawler umfassend zu blockieren, fügen Sie folgende Regeln hinzu:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Wenn Sie selektiv blockieren möchten – also Such-Crawler zulassen, aber Trainings-Crawler blockieren –, verwenden Sie dieses Vorgehen:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Ein häufiger Fehler ist die Verwendung zu allgemeiner Regeln wie Disallow: *, was Parser verwirren kann, oder das Vergessen, einzelne Crawler explizit zu nennen, wenn Sie nur bestimmte blockieren wollen. Große Unternehmen wie OpenAI, Anthropic und Google respektieren robots.txt in der Regel, während einige Crawler wie Perplexity nachweislich diese Regeln komplett ignorieren.
Wenn robots.txt allein nicht ausreicht, bieten mehrere stärkere Schutzmethoden zusätzlichen Zugriffsschutz vor KI-Crawlern. IP-basierte Blockierung erfordert, IP-Bereiche von KI-Crawlern zu identifizieren und auf Firewall- oder Serverebene zu blockieren – das ist sehr effektiv, muss aber regelmäßig gepflegt werden, da sich IP-Bereiche ändern. Serverseitige Blockierung per .htaccess (Apache) oder Nginx-Konfiguration bietet granulare Kontrolle und ist schwerer zu umgehen als robots.txt. Für Apache-Server können Sie folgende Regel implementieren:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Meta-Tag-Blockierung mit <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> verhindert das Indexieren, stoppt jedoch keine Trainings-Crawler. Prüfung der Request-Header kontrolliert, ob Crawler tatsächlich von den angegebenen Quellen stammen, etwa durch Reverse-DNS- und SSL-Zertifikats-Prüfung. Nutzen Sie serverseitige Blockierung, wenn Sie absolute Sicherheit wünschen, und kombinieren Sie mehrere Methoden für maximalen Schutz.
Ob Sie KI-Crawler blockieren, hängt von verschiedenen, teils gegensätzlichen Interessen ab. Blockieren von Trainings-Crawlern (GPTBot, ClaudeBot, Bytespider) verhindert, dass Ihre Inhalte für KI-Modelle verwendet werden, was Ihr geistiges Eigentum und Ihren Wettbewerbsvorteil schützt. Such-Crawler zulassen (Googlebot-Extended, Perplexity) kann dagegen Referral-Traffic bringen und die Sichtbarkeit in KI-basierten Suchergebnissen erhöhen – einem wachsenden Discovery-Kanal. Der Kompromiss ist komplexer, da einige KI-Unternehmen ein schlechtes Crawl-zu-Referral-Verhältnis haben: Die Crawler von Anthropic generieren etwa 38.000 Crawl-Anfragen pro einzelnem Referral, bei OpenAI liegt das Verhältnis bei etwa 400:1. Serverlast und Bandbreite sind ein weiterer Faktor – KI-Crawler verbrauchen bedeutende Ressourcen, und eine Blockierung kann Infrastrukturkosten senken. Ihre Entscheidung sollte zu Ihrem Geschäftsmodell passen: Für News-Seiten und Publisher kann Referral-Traffic nützlich sein, während SaaS-Anbieter und Urheber proprietärer Inhalte meist eine Blockierung bevorzugen.
Die Umsetzung von Crawler-Blockierungen ist nur die halbe Miete – Sie müssen überprüfen, ob Crawler Ihre Vorgaben tatsächlich befolgen. Server-Log-Analyse ist Ihr zentrales Verifizierungstool; durchsuchen Sie Ihre Zugriffs-Logs nach User-Agents und IP-Adressen von Crawlern, die nach der Blockierung auf Ihre Seite zugreifen. Mit grep durchsuchen Sie Ihre Logs beispielsweise so:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Dieser Befehl zählt, wie oft diese Crawler auf Ihre Seite zugegriffen haben. Testtools wie curl simulieren Crawler-Anfragen zur Überprüfung Ihrer Blockierungsregeln:
curl -A "GPTBot/1.0" https://ihreseite.de/robots.txt
Überwachen Sie Ihre Logs wöchentlich im ersten Monat nach Implementierung der Blockierungen, danach vierteljährlich. Wenn Sie feststellen, dass Crawler Ihre robots.txt ignorieren, erhöhen Sie die Schutzstufe auf Serverebene oder kontaktieren Sie das Abuse-Team des jeweiligen Crawler-Betreibers.
Das KI-Crawler-Umfeld entwickelt sich rasant, da ständig neue Unternehmen KI-Produkte starten und bestehende Crawler ihre User-Agent-Strings und IP-Bereiche ändern. Vierteljährliche Überprüfungen Ihrer Blockliste stellen sicher, dass Sie keine neuen Crawler verpassen oder versehentlich legitimen Traffic blockieren. Das Crawler-Ökosystem ist fragmentiert und dezentralisiert, was es unmöglich macht, eine dauerhafte Blockliste zu erstellen. Beobachten Sie diese Ressourcen für Updates:
Setzen Sie sich Erinnerungen, um robots.txt und serverseitige Regeln alle 90 Tage zu überprüfen, und abonnieren Sie Security-Mailinglisten, die neue Crawler-Muster melden.
Während das Blockieren von KI-Crawlern diese am Zugriff auf Ihre Inhalte hindert, adressiert AmICited die komplementäre Herausforderung: zu überwachen, ob KI-Systeme Ihre Marke und Inhalte in deren Ausgaben zitieren und referenzieren. AmICited verfolgt Erwähnungen Ihrer Organisation in KI-generierten Antworten und verschafft Ihnen Transparenz darüber, wie Ihre Inhalte die Ausgaben von KI-Modellen beeinflussen und wo Ihre Marke in KI-Suchergebnissen erscheint. So entsteht eine umfassende KI-Strategie: Sie steuern den Zugriff von Crawlern über robots.txt und serverseitige Blockierungen, während AmICited die Auswirkungen Ihrer Inhalte auf KI-Systeme messbar macht. Gemeinsam bieten Ihnen diese Werkzeuge vollständige Sichtbarkeit und Kontrolle über Ihre Präsenz im KI-Ökosystem – von der Verhinderung unerwünschter Trainingsnutzung bis zur Messung tatsächlicher Zitate und Referenzen Ihrer Inhalte auf KI-Plattformen.
Nein. Das Blockieren von KI-Trainings-Crawlern wie GPTBot, ClaudeBot und Bytespider hat keinen Einfluss auf Ihr Google- oder Bing-Suchranking. Herkömmliche Suchmaschinen verwenden andere Crawler (Googlebot, Bingbot), die unabhängig arbeiten. Blockieren Sie diese nur, wenn Sie vollständig aus den Suchergebnissen verschwinden möchten.
Große Crawler von OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) und Perplexity (PerplexityBot) geben offiziell an, robots.txt-Direktiven zu respektieren. Kleinere oder weniger transparente Bots können jedoch Ihre Konfiguration ignorieren, weshalb es gestaffelte Schutzstrategien gibt.
Das hängt von Ihrer Strategie ab. Wenn Sie nur Trainings-Crawler (GPTBot, ClaudeBot, Bytespider) blockieren, schützen Sie Ihre Inhalte vor Modelltraining, während Sie suchfokussierten Crawlern erlauben, Sie in KI-Suchergebnissen erscheinen zu lassen. Eine vollständige Blockierung entfernt Sie komplett aus KI-Ökosystemen.
Überprüfen Sie Ihre Konfiguration mindestens vierteljährlich. KI-Unternehmen stellen regelmäßig neue Crawler vor. Anthropic hat beispielsweise ihre 'anthropic-ai'- und 'Claude-Web'-Bots zu 'ClaudeBot' zusammengeführt, wodurch der neue Bot vorübergehend uneingeschränkten Zugriff auf Seiten hatte, die ihre Regeln nicht aktualisiert hatten.
Blockieren verhindert, dass Crawler überhaupt auf Ihre Inhalte zugreifen, und schützt diese vor Trainingsdatensammlung oder Indexierung. Wenn Sie Crawler zulassen, gewähren Sie Zugriff, was dazu führen kann, dass Ihre Inhalte für das Modelltraining verwendet oder mit minimalem Referral-Traffic in KI-Suchergebnissen angezeigt werden.
Ja, robots.txt ist eine Empfehlung, aber rechtlich nicht durchsetzbar. Gutartige Crawler großer Unternehmen respektieren robots.txt in der Regel, einige Crawler ignorieren sie jedoch. Für stärkeren Schutz sollten Sie serverseitige Blockierungen über .htaccess oder Firewall-Regeln implementieren.
Überprüfen Sie Ihre Server-Logs auf User-Agent-Strings blockierter Crawler. Wenn Sie Anfragen von Crawlern sehen, die Sie blockiert haben, respektieren diese robots.txt möglicherweise nicht. Nutzen Sie Testtools wie den robots.txt-Tester der Google Search Console oder curl-Befehle, um Ihre Konfiguration zu überprüfen.
Das Blockieren von Trainings-Crawlern hat in der Regel minimale Auswirkungen auf den direkten Traffic, da sie ohnehin kaum Referral-Traffic liefern. Das Blockieren von Such-Crawlern kann jedoch die Sichtbarkeit auf KI-basierten Discovery-Plattformen verringern. Überwachen Sie Ihre Analysen 30 Tage nach der Implementierung, um die tatsächlichen Auswirkungen zu messen.
Während Sie mit robots.txt den Zugriff von Crawlern steuern, hilft Ihnen AmICited dabei, zu verfolgen, wie KI-Systeme Ihre Inhalte in deren Ausgaben zitieren und referenzieren. Erhalten Sie vollständige Transparenz über Ihre KI-Präsenz.
Erfahren Sie, wie Sie den Zugang von KI-Crawlern zu Ihrer Website prüfen. Entdecken Sie, welche Bots Ihre Inhalte sehen können, und beheben Sie Blocker, die die...

Vollständiger Referenzleitfaden zu AI-Crawlern und Bots. Identifizieren Sie GPTBot, ClaudeBot, Google-Extended und 20+ weitere AI-Crawler mit User-Agents, Crawl...

Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.