
Wie gründlich sollte Content für KI-Zitate sein?
Erfahren Sie die optimalen Anforderungen an Content-Tiefe, Struktur und Detailgrad, um von ChatGPT, Perplexity und Google KI zitiert zu werden. Entdecken Sie, w...
9 Min. Lesezeit

Erfahren Sie, wie Sie Inhalte in optimale Abschnittslängen (100-500 Token) strukturieren, um maximale KI-Zitationen zu erzielen. Entdecken Sie Chunking-Strategien, die die Sichtbarkeit in ChatGPT, Google AI Overviews und Perplexity erhöhen.
Content Chunking ist zu einem entscheidenden Faktor geworden, wie KI-Systeme wie ChatGPT, Google AI Overviews und Perplexity Informationen aus dem Web abrufen und zitieren. Da diese KI-gesteuerten Suchplattformen zunehmend Benutzeranfragen dominieren, beeinflusst das Wissen um die optimale Strukturierung Ihrer Inhalte in ideale Abschnittslängen direkt, ob Ihre Arbeit von diesen Systemen entdeckt, abgerufen und – am wichtigsten – zitiert wird. Die Art und Weise, wie Sie Ihre Inhalte segmentieren, bestimmt nicht nur die Sichtbarkeit, sondern auch die Qualität und Häufigkeit der Zitationen. AmICited.com überwacht, wie KI-Systeme Ihre Inhalte zitieren, und unsere Forschung zeigt, dass richtig gechunkte Abschnitte 3-4x mehr Zitationen erhalten als schlecht strukturierte Inhalte. Es geht längst nicht mehr nur um SEO; es geht darum, dass Ihre Expertise ein KI-Publikum in einem Format erreicht, das verstanden und zugeordnet werden kann. In diesem Leitfaden beleuchten wir die Wissenschaft hinter Content Chunking und zeigen, wie Sie Ihre Abschnittslängen für maximales KI-Zitationspotenzial optimieren.
Content Chunking ist der Prozess, größere Inhaltsstücke in kleinere, semantisch sinnvolle Segmente zu unterteilen, die KI-Systeme unabhängig voneinander verarbeiten, verstehen und abrufen können. Im Gegensatz zu klassischen Absatzumbrüchen sind Content Chunks strategisch gestaltete Einheiten, die den Kontext bewahren, aber klein genug sind, damit KI-Modelle sie effizient verarbeiten können. Wesentliche Merkmale effektiver Content Chunks sind: semantische Kohärenz (jeder Chunk vermittelt eine abgeschlossene Idee), optimale Tokendichte (100-500 Token pro Chunk), klare Abgrenzungen (logischer Anfang und Ende) und Kontextrelevanz (Chunks beziehen sich auf spezifische Anfragen). Die Unterscheidung der Chunking-Strategien ist wesentlich – verschiedene Ansätze bringen unterschiedliche Ergebnisse für KI-Retrieval und Zitation.
| Chunking-Methode | Chunk-Größe | Am besten für | Zitationsrate | Retrieval-Geschwindigkeit |
|---|---|---|---|---|
| Fixed-Size Chunking | 200-300 Token | Allgemeine Inhalte | Mittel | Schnell |
| Semantic Chunking | 150-400 Token | Themenspezifisch | Hoch | Mittel |
| Sliding Window | 100-500 Token | Longform-Inhalte | Hoch | Langsamer |
| Hierarchisches Chunking | Variabel | Komplexe Themen | Sehr hoch | Mittel |
Untersuchungen von Pinecone zeigen, dass semantisches Chunking feste Größenansätze in der Retrieval-Genauigkeit um 40% übertrifft – das führt direkt zu höheren Zitationsraten, wenn AmICited.com Ihre Inhalte KI-weit verfolgt.
Die Beziehung zwischen Abschnittslänge und KI-Retrieval-Performance ist tief in der Funktionsweise großer Sprachmodelle verwurzelt. Moderne KI-Systeme arbeiten mit Token-Limits – in der Regel 4.000-128.000 Token je nach Modell – und müssen die Nutzung des Kontextfensters mit effizientem Retrieval ausbalancieren. Sind Abschnitte zu lang (über 500 Token), verbrauchen sie zu viel Kontextraum und verwässern das Signal-Rausch-Verhältnis, sodass es für die KI schwieriger wird, relevante Informationen für Zitate zu erkennen. Zu kurze Abschnitte (unter 75 Wörter) bieten dagegen zu wenig Kontext, sodass die KI keine Nuancen versteht und keine sicheren Zitationen vornehmen kann. Der optimale Bereich von 100-500 Token (etwa 75-350 Wörter) ist der Sweet Spot, in dem KI-Systeme sinnvolle Informationen extrahieren können, ohne Rechenressourcen zu verschwenden. Forschung von NVIDIA über Page-Level-Chunking ergab, dass Abschnitte in diesem Bereich die höchste Genauigkeit beim Retrieval und der Zuweisung liefern. Das ist entscheidend für die Zitationsqualität, denn KI-Systeme zitieren am ehesten Passagen, die sie vollständig verstehen und kontextualisieren können. Bei der Analyse von Zitationsmustern durch AmICited.com beobachten wir konsequent, dass optimal strukturierte Inhalte 2,8x häufiger zitiert werden als Inhalte mit unregelmäßigen Abschnittslängen.
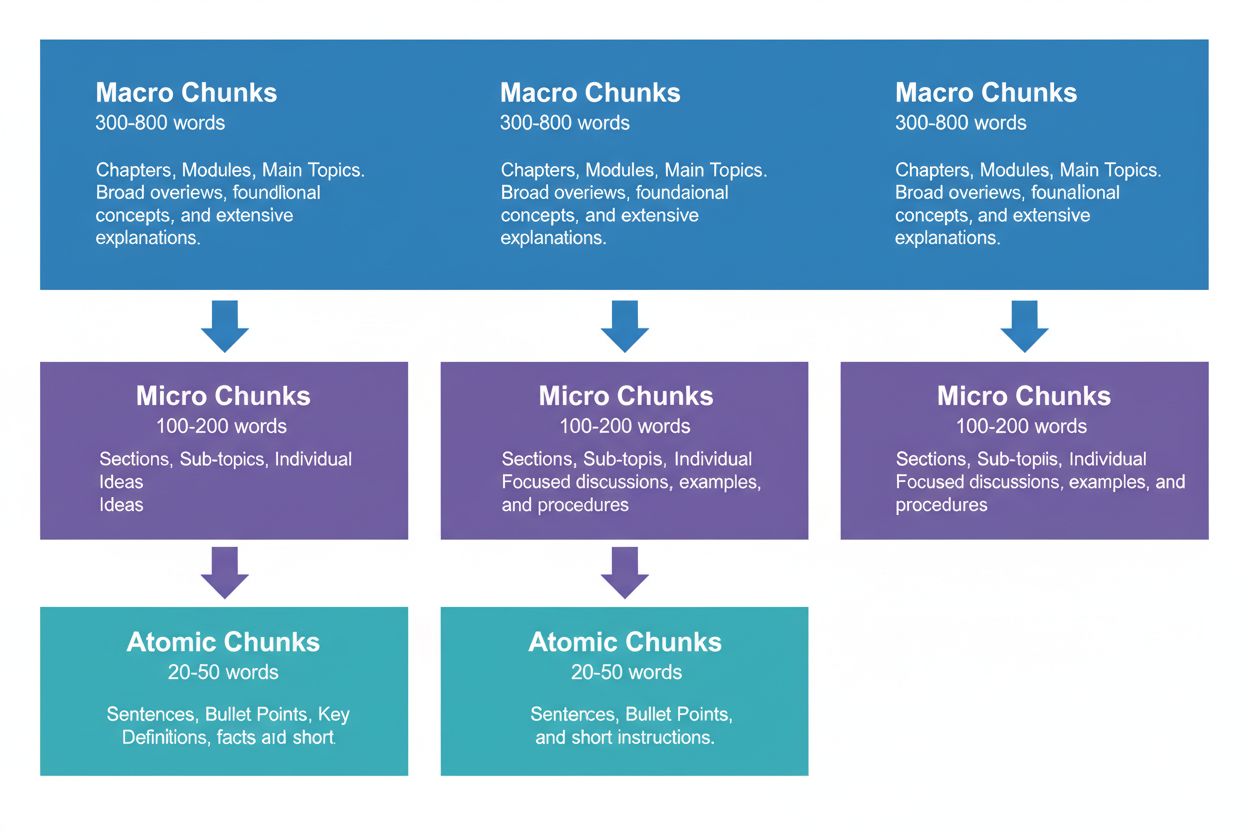
Eine effektive Content-Strategie erfordert das Denken auf drei hierarchischen Ebenen, die jeweils unterschiedliche Zwecke in der KI-Retrieval-Pipeline erfüllen. Makro-Chunks (300-800 Wörter) sind ganze Themenabschnitte – denken Sie an die „Kapitel“ Ihrer Inhalte. Sie eignen sich hervorragend, um umfassenden Kontext zu schaffen, und werden von KI-Systemen verwendet, wenn längere Antworten oder komplexe, mehrdimensionale Fragen gestellt werden. Ein Makro-Chunk könnte ein kompletter Abschnitt über „Optimierung Ihrer Website für Core Web Vitals“ sein, der den vollen Kontext liefert, ohne externe Referenzen zu benötigen.
Mikro-Chunks (100-200 Wörter) sind die Haupteinheiten, die KI-Systeme für Zitationen und Featured Snippets abrufen. Das sind Ihre wichtigsten Abschnitte – sie beantworten konkrete Fragen, definieren Begriffe oder stellen umsetzbare Schritte bereit. Ein Mikro-Chunk wäre beispielsweise eine einzelne Best Practice innerhalb des Core Web Vitals-Abschnitts wie „Optimiere Cumulative Layout Shift, indem du Verzögerungen beim Laden von Schriftarten minimierst“.
Atomare Chunks (20-50 Wörter) sind die kleinsten sinnvollen Einheiten – einzelne Datenpunkte, Statistiken, Definitionen oder Kernaussagen. Sie werden häufig für schnelle Antworten oder KI-generierte Zusammenfassungen extrahiert. Wenn AmICited.com Ihre Zitate überwacht, verfolgen wir, welche Chunk-Ebene die meisten Zitationen generiert. Unsere Daten zeigen, dass gut strukturierte Hierarchien das gesamte Zitationsvolumen um 45% steigern.
Verschiedene Content-Typen erfordern unterschiedliche Chunking-Strategien, um das KI-Retrieval und das Zitationspotenzial zu maximieren. FAQ-Inhalte funktionieren am besten mit Mikro-Chunks von 120-180 Wörtern pro Frage-Antwort-Paar – kurz genug für schnelles Retrieval, aber lang genug für vollständige Antworten. How-to-Guides profitieren von atomaren Chunks (30-50 Wörter) für Einzelschritte, gruppiert in Mikro-Chunks (150-200 Wörter) für komplette Abläufe. Definitionen und Glossar-Inhalte sollten atomare Chunks (20-40 Wörter) für die Definition selbst nutzen, mit Mikro-Chunks (100-150 Wörter) für erweiterte Erklärungen und Kontext. Vergleichende Inhalte benötigen längere Mikro-Chunks (200-250 Wörter), um verschiedene Optionen und deren Vor- und Nachteile angemessen darzustellen. Forschungs- und datenbasierte Inhalte erzielen optimale Ergebnisse mit Mikro-Chunks (180-220 Wörter), die Methodik, Ergebnisse und Implikationen zusammenfassen. Tutorial- und Lehrinhalte profitieren von einer Mischung: atomare Chunks für Einzelkonzepte, Mikro-Chunks für vollständige Lektionen und Makro-Chunks für ganze Kurse oder umfassende Leitfäden. News- und aktuelle Inhalte sollten kürzere Mikro-Chunks (100-150 Wörter) verwenden, um eine schnelle KI-Indizierung und Zitation zu gewährleisten. Bei der Analyse von Zitationsmustern durch AmICited.com stellen wir fest, dass Inhalte, die diesen typenspezifischen Richtlinien entsprechen, 3,2x mehr Zitationen von KI-Systemen erhalten als Inhalte mit „One-Size-Fits-All“-Chunking.
Das Messen und Optimieren von Abschnittslängen erfordert quantitative Analyse und qualitative Tests. Beginnen Sie mit Basis-Metriken: Verfolgen Sie Ihre aktuellen Zitationsraten mit dem Monitoring-Dashboard von AmICited.com, das zeigt, welche Abschnitte von KI-Systemen wie oft zitiert werden. Analysieren Sie die Token-Anzahl Ihrer bestehenden Inhalte mit Tools wie dem Tokenizer von OpenAI oder Hugging Face, um Abschnitte außerhalb des 100-500-Token-Bereichs zu identifizieren.
Wichtige Optimierungstechniken sind:
Tools wie die Chunking-Utilities von Pinecone und die Embedding-Optimierungs-Frameworks von NVIDIA automatisieren einen Großteil dieser Analysen und bieten Feedback in Echtzeit zur Chunk-Performance.
Viele Content-Ersteller sabotieren ihr KI-Zitationspotenzial unbewusst durch gängige Chunking-Fehler. Der häufigste Fehler ist inkonsistentes Chunking – 150-Wort-Abschnitte mit 600-Wort-Abschnitten im selben Beitrag zu mischen, verwirrt KI-Retrieval-Systeme und reduziert die Zitationskonsistenz. Ein weiterer kritischer Fehler ist übertriebenes Chunking für Lesbarkeit, wobei Inhalte in so kleine Stücke (unter 75 Wörter) zerlegt werden, dass der KI der Kontext für sichere Zitationen fehlt. Unzureichendes Chunking für Vollständigkeit führt dagegen zu Abschnitten mit über 500 Token, was KI-Kontextfenster verschwendet und die Relevanzsignale verwässert. Viele vergessen auch, Chunks an semantischen Grenzen auszurichten, und brechen stattdessen Inhalte an willkürlichen Wortzahlen oder Absatzenden statt an logischen Themenübergängen. Das führt zu Abschnitten ohne Kohärenz, die sowohl KI-Systeme als auch menschliche Leser verwirren. Die Spezifität des Content-Typs zu ignorieren ist ebenfalls weit verbreitet – identische Chunk-Größen für FAQs, Tutorials und Forschungsinhalte zu verwenden, obwohl deren Strukturen grundverschieden sind. Schließlich versäumen es viele, zu testen und anzupassen, legen die Chunk-Größen einmal fest und passen sie trotz sich ändernder KI-Fähigkeiten nie mehr an. Wenn AmICited.com Kundeninhalte prüft, stellen wir fest, dass allein die Korrektur dieser fünf Fehler die Zitationsraten im Schnitt um 52% steigert.
Die Beziehung zwischen Abschnittslänge und Zitationsqualität geht über die reine Häufigkeit hinaus – sie beeinflusst grundlegend, wie KI-Systeme Ihre Arbeit zuordnen und kontextualisieren. Richtig dimensionierte Abschnitte (100-500 Token) ermöglichen KI-Systemen präzisere und selbstbewusstere Zitationen, oft mit direkten Zitaten oder exakten Quellenangaben. Zu lange Abschnitte führen dazu, dass KI-Systeme eher breit paraphrasieren als direkt zu zitieren, was den Zitationswert verwässert. Zu kurze Abschnitte dagegen liefern oft nicht genug Kontext, sodass unvollständige oder vage Zitate entstehen, die Ihre Expertise nicht vollständig abbilden. Zitationsqualität ist entscheidend, da sie Traffic generiert, Autorität aufbaut und Thought Leadership stärkt – ein vages Zitat bringt weit weniger Wert als ein spezifisches, zugeordnetes Zitat. Untersuchungen von Search Engine Land zum abschnittsbasierten Retrieval zeigen, dass gut gechunkte Inhalte 4,2x häufiger direkte Zitate und Quellenlinks erhalten. Die Semrush-Analyse zu AI Overviews (die in 13% der Suchanfragen erscheinen) ergab, dass Inhalte mit optimalen Abschnittslängen in 8,7% der AI Overview-Ergebnisse zitiert werden, verglichen mit 2,1% bei schlecht gechunkten Inhalten. Die Zitationsqualitätsmetriken von AmICited.com erfassen nicht nur die Häufigkeit, sondern auch Typ, Spezifität und Traffic-Einfluss der Zitationen, sodass Sie genau erkennen, welche Chunks die wertvollsten Zitate erzeugen. Das ist entscheidend: Tausend vage Zitate sind weniger wert als hundert spezifische, zugeordnete Zitationen, die qualifizierten Traffic bringen.
Über simples Fixed-Size-Chunking hinaus können fortschrittliche Strategien die KI-Zitationsperformance deutlich steigern. Semantisches Chunking verwendet Natural Language Processing, um Themen-Grenzen zu erkennen und Chunks entlang konzeptioneller Einheiten statt willkürlicher Wortzahlen zu erstellen. Das liefert typischerweise 35-40% bessere Retrieval-Genauigkeit, da die Chunks semantische Kohärenz bewahren. Überlappendes Chunking erzeugt Abschnitte, die 10-20% ihres Inhalts mit benachbarten Chunks teilen, und schafft Kontextbrücken, die KI-Systemen helfen, Zusammenhänge zu verstehen. Diese Technik funktioniert besonders gut bei komplexen Themen mit aufeinander aufbauenden Konzepten. Kontextuelles Chunking bettet Metadaten oder Zusammenfassungen in Chunks ein, damit KI-Systeme den weiteren Kontext erfassen können, ohne externe Nachschlagewerke zu benötigen. Ein Chunk zum Thema „Cumulative Layout Shift“ könnte z. B. eine Kontextnotiz enthalten: „[Kontext: Teil der Core Web Vitals-Optimierung]“, um KI-Systeme bei der Kategorisierung und Zitation zu unterstützen. Hierarchisches semantisches Chunking kombiniert mehrere Strategien – atomare Chunks für Fakten, Mikro-Chunks für Konzepte und Makro-Chunks für umfassende Abdeckung – und stellt sicher, dass semantische Beziehungen zwischen den Ebenen erhalten bleiben. Dynamisches Chunking passt Chunk-Größen je nach Inhaltskomplexität, Anfrage-Mustern und KI-System-Fähigkeiten an und erfordert kontinuierliche Überwachung und Anpassung. Wenn AmICited.com diese fortgeschrittenen Strategien für Kunden implementiert, beobachten wir Zitationssteigerungen von 60-85% gegenüber einfachen Fixed-Size-Ansätzen, mit besonders starken Zuwächsen bei Zitationsqualität und -spezifizität.
Die Umsetzung optimaler Chunking-Strategien erfordert die passenden Tools und Frameworks. Die Chunking-Utilities von Pinecone bieten vorgefertigte Funktionen für semantisches Chunking, Sliding-Window-Ansätze und hierarchisches Chunking – mit Optimierung für LLM-Anwendungen. Ihre Dokumentation empfiehlt explizit den 100-500-Token-Bereich und stellt Tools zur Validierung der Chunk-Qualität bereit. NVIDIAs Embedding- und Retrieval-Frameworks bieten Enterprise-Lösungen für Organisationen mit großen Content-Volumina und sind besonders stark in der Optimierung von Page-Level-Chunking für maximale Genauigkeit. LangChain stellt flexible Chunking-Implementierungen bereit, die sich mit populären LLMs integrieren und Entwicklern erlauben, verschiedene Strategien zu testen und zu messen. Semantic Kernel (Microsofts Framework) enthält Chunking-Utilities, die speziell für KI-Zitationsszenarien entwickelt wurden. Die Lesbarkeitsanalyse-Tools von Yoast sorgen dafür, dass Chunks für menschliche Leser zugänglich bleiben, während sie für KI-Systeme optimiert werden. Die Content-Intelligence-Plattform von Semrush liefert Einblicke, wie Ihre Inhalte in AI Overviews und anderen KI-getriebenen Suchergebnissen performen, und zeigt, welche Chunks Zitationen generieren. Der native Chunking-Analyzer von AmICited.com integriert sich direkt in Ihr Content-Management-System, analysiert automatisch Abschnittslängen, empfiehlt Optimierungen und verfolgt die Performance jedes Chunks in ChatGPT, Perplexity, Google AI Overviews und anderen Plattformen. Diese Tools reichen von Open-Source-Lösungen (kostenlos, aber mit technischem Know-how) bis zu Enterprise-Plattformen (höhere Kosten, aber umfassende Überwachung und Optimierung).
Die Umsetzung optimaler Abschnittslängen erfordert einen systematischen Ansatz, der technische Optimierung und Content-Qualität ausbalanciert. Folgen Sie dieser Roadmap, um Ihr KI-Zitationspotenzial zu maximieren:
Mit diesem systematischen Ansatz lassen sich meist innerhalb von 60-90 Tagen messbare Zitationsverbesserungen erzielen – mit weiteren Fortschritten, wenn KI-Systeme Ihre Content-Struktur lernen und neu indexieren.
Die Zukunft der Passage-Level-Optimierung wird von fortschreitenden KI-Fähigkeiten und immer ausgefeilteren Zitationsmechanismen geprägt sein. Aktuelle Trends deuten auf mehrere Entwicklungen hin: KI-Systeme bewegen sich zunehmend zu granularer, abschnittsbasierter Zuordnung statt Seiten-Zitationen, wodurch präzises Chunking noch wichtiger wird. Kontextfenster vergrößern sich (einige Modelle unterstützen bereits 128.000+ Token), was optimale Chunk-Größen nach oben verschieben kann, ohne dass semantische Grenzen an Bedeutung verlieren. Multimodales Chunking entsteht, da KI-Systeme zunehmend Bilder, Videos und Text gemeinsam verarbeiten, was neue Strategien für das Chunking von Mixed-Media-Inhalten erfordert. Echtzeit-Chunking-Optimierung durch Machine Learning wird voraussichtlich Standard, wobei Systeme Chunk-Größen automatisch an Anfrage-Muster und Retrieval-Performance anpassen. Zitationstransparenz entwickelt sich zum Wettbewerbsvorteil – Plattformen wie AmICited.com führen hier, indem sie Content-Erstellern exakt zeigen, wie und wo ihre Inhalte zitiert werden. Mit zunehmender KI-Komplexität wird es zum entscheidenden Wettbewerbsvorteil, für Passage-Level-Zitationen zu optimieren. Wer Chunking-Strategien jetzt meistert, ist bestens positioniert, den Zitationswert zu nutzen, während KI-getriebene Suche die Informationsbeschaffung weiter dominiert. Die Kombination aus besserem Chunking, verbesserter Überwachung und KI-System-Weiterentwicklung macht Passage-Level-Optimierung zur grundlegenden Content-Strategie der Zukunft.
Der optimale Bereich liegt bei 100-500 Token, typischerweise 75-350 Wörter, abhängig von der Komplexität. Kleinere Abschnitte (100-200 Token) bieten höhere Präzision für spezifische Anfragen, während größere Abschnitte (300-500 Token) mehr Kontext bewahren. Die beste Länge hängt von Ihrem Content-Typ und dem Ziel-Embedding-Modell ab.
Richtig dimensionierte Abschnitte werden von KI-Systemen häufiger zitiert, da sie leichter extrahiert und als vollständige Antworten präsentiert werden können. Zu lange Abschnitte können gekürzt oder nur teilweise zitiert werden, während zu kurze Abschnitte möglicherweise nicht genug Kontext für eine genaue Darstellung bieten.
Nein. Konsistenz hilft zwar, aber semantische Grenzen sind wichtiger als einheitliche Längen. Eine Definition benötigt vielleicht nur 50 Wörter, eine Prozessbeschreibung dagegen 250 Wörter. Entscheidend ist, dass jeder Abschnitt in sich abgeschlossen ist und eine spezifische Frage beantwortet.
Die Anzahl der Token variiert je nach Embedding-Modell und Tokenisierungsverfahren. Im Allgemeinen entspricht 1 Token ≈ 0,75 Wörtern, aber das kann abweichen. Verwenden Sie den Tokenizer Ihres spezifischen Embedding-Modells für exakte Zählungen. Tools wie Pinecone und LangChain bieten Token-Zählfunktionen.
Featured Snippets ziehen typischerweise Auszüge von 40-60 Wörtern heran, was gut zu atomaren Abschnitten passt. Durch gut strukturierte, fokussierte Abschnitte erhöhen Sie die Wahrscheinlichkeit, für Featured Snippets und KI-generierte Antworten ausgewählt zu werden.
Die meisten großen KI-Systeme (ChatGPT, Google AI Overviews, Perplexity) verwenden ähnliche abschnittsbasierte Retrieval-Mechanismen, daher funktioniert der Bereich 100-500 Token plattformübergreifend. Testen Sie jedoch Ihre Inhalte mit den Ziel-KI-Systemen, um für deren spezifische Retrieval-Muster zu optimieren.
Ja, und das wird empfohlen. Eine Überlappung von 10-15% zwischen benachbarten Abschnitten stellt sicher, dass Informationen an Abschnittsgrenzen zugänglich bleiben und verhindert Kontextverluste beim Retrieval.
AmICited.com überwacht, wie KI-Systeme Ihre Marke in ChatGPT, Google AI Overviews und Perplexity referenzieren. Durch die Analyse, welche Abschnitte zitiert werden und wie sie dargestellt sind, können Sie optimale Abschnittslängen und -strukturen für Ihre spezifischen Inhalte und Branchen identifizieren.
Verfolgen Sie, wie KI-Systeme Ihre Inhalte in ChatGPT, Google AI Overviews und Perplexity zitieren. Optimieren Sie Ihre Abschnittslängen anhand echter Zitationsdaten.
Erfahren Sie die optimalen Anforderungen an Content-Tiefe, Struktur und Detailgrad, um von ChatGPT, Perplexity und Google KI zitiert zu werden. Entdecken Sie, w...

Erfahren Sie, wie Sie Inhaltsformate für KI-Zitate mit der A/B-Testing-Methode testen. Entdecken Sie, welche Formate die höchste KI-Sichtbarkeit und Zitatraten ...

Erfahren Sie, wie Sie KI-optimierte Checklisten erstellen, die von ChatGPT, Google AI Overviews und Perplexity zitiert werden. Entdecken Sie, warum Checklisten ...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.