Informationsdichte
Erfahren Sie, was Informationsdichte ist und wie sie die Wahrscheinlichkeit von KI-Zitationen erhöht. Entdecken Sie praxisnahe Techniken zur Optimierung von Inh...
14 Min. Lesezeit

Erfahren Sie, wie Sie informationsdichte Inhalte erstellen, die von KI-Systemen bevorzugt werden. Meistern Sie die Hypothese der gleichmäßigen Informationsdichte und optimieren Sie Ihre Inhalte für KI Overviews, LLMs und bessere Zitationen.
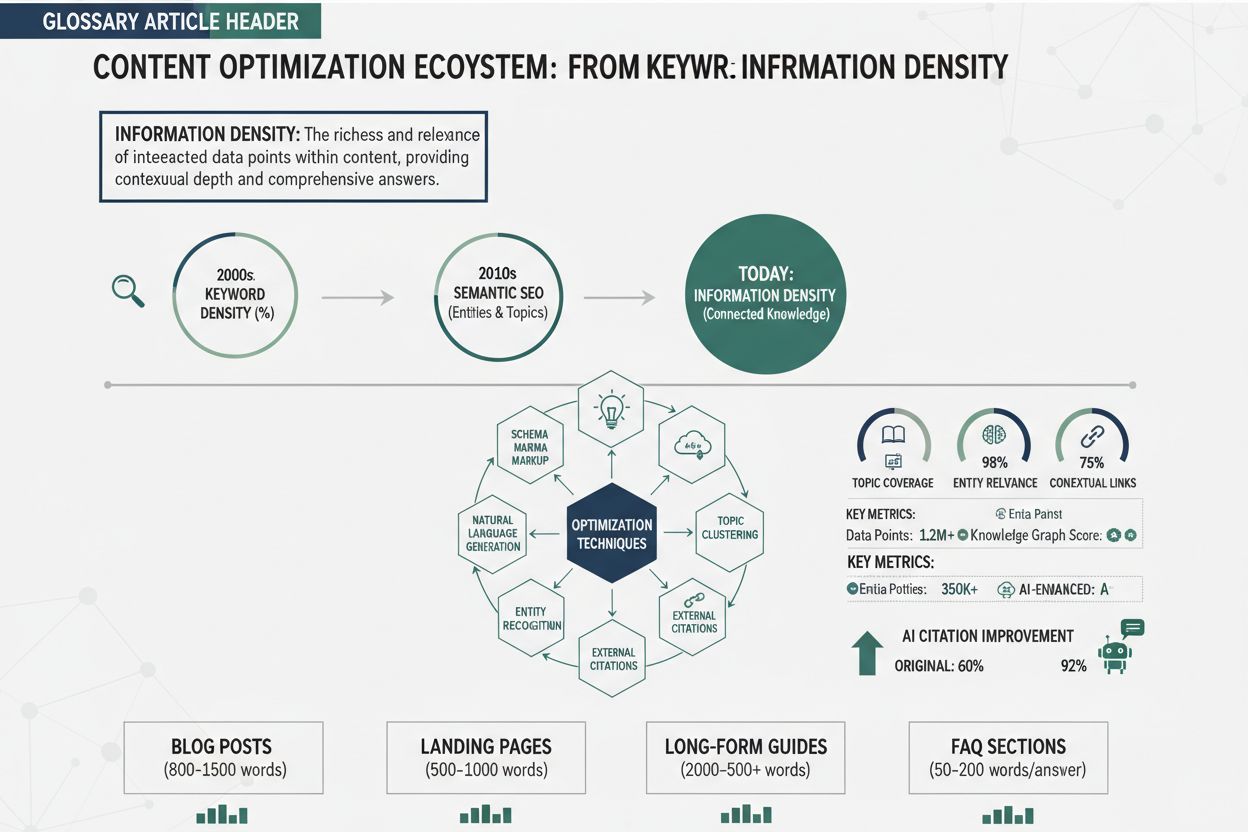
Informationsdichte bezeichnet die Konzentration bedeutungsvoller, umsetzbarer Erkenntnisse innerhalb eines Inhalts – also, wie viel Wert in jedem Wort, Satz oder Absatz steckt. Dieses Konzept ist im Zeitalter der KI-gesteuerten Suche, insbesondere mit dem Aufstieg von Large Language Models (LLMs) und KI Overviews, immer wichtiger geworden. Die Hypothese der gleichmäßigen Informationsdichte (UID), ein sprachwissenschaftliches Prinzip, das durch aktuelle ArXiv-Forschung gestützt wird, legt nahe, dass sowohl Menschen als auch KI-Systeme Informationen effektiver verarbeiten, wenn die kognitive Belastung gleichmäßig über den gesamten Inhalt verteilt und nicht auf einzelne Abschnitte konzentriert wird. Für KI-Systeme, die Inhalte bewerten, beeinflusst die Informationsdichte direkt, wie wahrscheinlich es ist, dass Ihr Inhalt ausgewählt, zitiert und in den KI-Suchergebnissen gerankt wird. Wenn Sie wertvolle, dichte Inhalte erstellen, schreiben Sie nicht nur für menschliche Leser – Sie optimieren auch dafür, wie LLMs Informationen aus Ihrer Arbeit extrahieren, zusammenfassen und referenzieren.
LLMs bewerten die Inhaltsdichte mit mehreren ausgefeilten Mechanismen, die weit über reine Wortanzahl oder Keyword-Häufigkeit hinausgehen. Diese Systeme analysieren Inhaltsmetriken mithilfe entropiebasierter Berechnungen, die messen, wie viel Information im Verhältnis zur Gesamtlänge des Textes vermittelt wird. Dabei wird untersucht, was Forscher als “step-level uniformity” – die Gleichmäßigkeit der Informationsverteilung über aufeinanderfolgende Abschnitte Ihres Inhalts – bezeichnen. Wenn ein LLM Ihren Artikel verarbeitet, berechnet es den Informationsgewinn bei jedem Token und beurteilt, ob Sie durchgehend Mehrwert liefern oder ob bestimmte Abschnitte redundant, abschweifend oder wenig wertvoll sind. Verschiedene Bewertungsrahmen priorisieren unterschiedliche Aspekte von Inhaltsqualität, wie der folgende Vergleich zeigt:
| Metrik | Was wird gemessen | KI-Relevanz | Am besten geeignet für |
|---|---|---|---|
| BLEU Score | Präzision von Wortübereinstimmungen | Geringere Relevanz für Dichte | Bewertung maschineller Übersetzungen |
| ROUGE Score | Recall von Inhaltsüberschneidungen | Mittlere Relevanz | Zusammenfassungsqualität |
| Perplexity | Vorhersagbarkeit von Textsequenzen | Hohe Relevanz | LLM-Confidence-Bewertung |
| Informationsdichte | Bedeutungsinhalt pro Längeneinheit | Höchste Relevanz | KI-Zitation und Auswahl |
Das Verständnis dieser LLM-Bewertungsmodelle hilft Ihnen zu erkennen, dass KI-Systeme nicht einfach nur umfassende Inhalte suchen – sie suchen Inhalte, die durchgehend gleichbleibenden Informationswert liefern und den häufigen Fehler von Füllmaterial oder unnötigen Ausschweifungen vermeiden.
Der Unterschied zwischen dichten und dünnen Inhalten prägt grundlegend, wie KI-Systeme mit Ihren Materialien umgehen. Dichte Inhalte liefern hohen Informationswert mit minimalem Füllmaterial, während dünne Inhalte viel Wiederholung, Füllwörter oder wenig wertvolle Ausschmückungen enthalten. Wichtige Unterschiede:
Ein praktisches Beispiel: Ein dünner Artikel zur Optimierung von KI-Inhalten widmet vielleicht drei Absätze der Erklärung, was KI ist, dann drei weitere, warum Inhalte wichtig sind, bevor schließlich auf Optimierungstechniken eingegangen wird. Eine dichte Version geht von Grundwissen aus, integriert Kontext natürlich und widmet den Großteil dem Handlungsleitfaden. KI-Systeme erkennen und belohnen diese Effizienz, weil sie zeigt, dass der Autor das Thema tief genug versteht, um es prägnant zu vermitteln.
Informationsdichte hat sich zu einem entscheidenden Rankingsignal in KI-getriebenen Suchumgebungen entwickelt und bestimmt direkt, ob Ihre Inhalte in KI Overviews erscheinen und wie oft sie von KI-Systemen zitiert werden. Untersuchungen aus der Analyse von KI-Algorithmen durch BrightEdge zeigen, dass Inhalte, die für KI Overviews ausgewählt werden, etwa 40 % höhere Informationsdichte-Werte aufweisen als nicht ausgewählte Inhalte. Das legt nahe, dass KI-Systeme bei der Synthese von Antworten aktiv dichte, wertvolle Inhalte priorisieren. Das Verhältnis zwischen Informationsdichte und Zitationsrate ist für die Perspektive von AmICited.com besonders wichtig: Wenn KI-Systeme wie Perplexity oder die Google KI Overviews Quellen referenzieren müssen, zitieren sie bevorzugt Inhalte, die konzentrierten Wert liefern, da so weniger Quellen für eine vollständige Antwort benötigt werden. Inhalte mit hoher Informationsdichte ranken zudem besser, weil sie die Nutzerabsicht umfassender erfüllen – KI-Systeme erkennen, dass dichte Inhalte gründlichere Antworten liefern, sodass Nutzer mit geringerer Wahrscheinlichkeit weitere Quellen konsultieren müssen. Außerdem prüfen KI Overviews-Algorithmen speziell, ob Inhalte effektiv zusammengefasst und synthetisiert werden können; dichte Inhalte lassen sich naturgemäß besser zusammenfassen, da sie weniger Überflüssiges enthalten, das beim Synthetisieren herausgefiltert werden müsste.
Wertvolle, dichte Inhalte zu erstellen, erfordert bewusste Struktur- und Redaktionsentscheidungen, bei denen die Informationsvermittlung Vorrang vor der Wortanzahl hat. Beginnen Sie mit einer schonungslosen Prüfung Ihrer bestehenden Inhalte: Identifizieren Sie jeden Satz, der Ihr Kernthema nicht voranbringt oder keinen umsetzbaren Wert liefert, und streichen Sie ihn oder integrieren Sie ihn in umgebende Sätze mit Mehrfachnutzen. Verwenden Sie strukturierte Inhaltsformate – nummerierte Listen, Vergleichstabellen, hierarchische Überschriften und Definitionselemente –, die es Lesern und KI-Systemen ermöglichen, Schlüsselinformationen schnell zu extrahieren, ohne durch Fließtext navigieren zu müssen. Wenden Sie das Prinzip “eine Idee pro Absatz” an und sorgen Sie dafür, dass jeder Abschnitt einen klaren Zweck erfüllt und seine Aussage nicht durch Abschweifungen verwässert; das unterstützt die UID-Hypothese, indem die kognitive Belastung gleichmäßig verteilt wird. Erklären Sie komplexe Konzepte mit progressiver Offenlegung: Erst die wesentliche Information, dann unterstützende Details, Beispiele und Nuancen – das kommt sowohl menschlichen Lesern als auch LLMs zugute, die Inhalte auf unterschiedlichem Detaillierungsgrad extrahieren. Fügen Sie konkrete Datenpunkte, Statistiken und Beispiele ein statt abstrakter Verallgemeinerungen; “etwa 40 % höhere Informationsdichte” ist für KI-Systeme wertvoller als “deutlich höhere Dichte”. Optimieren Sie Ihren Content-Optimierungsprozess, indem Sie Informationsdichte als primäre Kennzahl neben klassischen SEO-Faktoren behandeln – prüfen Sie Entwürfe gezielt darauf, ob Abschnitte gekürzt, kombiniert oder gestrichen werden können, ohne wesentlichen Wert zu verlieren.
Informationsdichte zu messen, erfordert Verständnis für sowohl theoretische Rahmen als auch praktische Tools für Content-Ersteller. Der direkteste Ansatz ist die Berechnung des Informationsdichte-Scores mittels entropiebasierter Metriken: Teilen Sie den gesamten Informationsgehalt (gemessen in Bits oder mittels semantischer Analyse) durch die Wortzahl, um zu bestimmen, wie viel bedeutungsvolle Information pro Textelement vermittelt wird. Verschiedene Tools helfen bei der Einschätzung: NLP-Plattformen analysieren semantische Vielfalt und Konzeptverteilung, Lesbarkeits-Tools erkennen Redundanzen und eigene Skripte mit Python-Bibliotheken wie NLTK berechnen Entropiewerte Ihrer Inhalte. Ein praktisches Beispiel: Wenn ein 2.000-Wörter-Artikel etwa 150 unterschiedliche semantische Konzepte mit gleichmäßiger Verteilung enthält, ist seine Informationsdichte höher als die eines 2.000-Wörter-Artikels, bei dem nur 80 Konzepte in der ersten Hälfte konzentriert sind. Auch Proxy-Metriken wie das Verhältnis einzigartiger Begriffe zur Gesamtwortzahl, durchschnittlicher Informationsgewinn pro Absatz oder die Anzahl umsetzbarer Erkenntnisse pro 500 Wörter sind nützlich – sie sind zwar keine perfekten Messgrößen, liefern aber hilfreiche Richtungswerte. BrightEdge empfiehlt, zu beobachten, wie oft Ihre Inhalte von KI-Systemen zitiert werden, als realitätsnahe Validierung der Informationsdichte; wenn Ihre Inhalte regelmäßig in KI Overviews erscheinen und zitiert werden, treffen Sie wahrscheinlich die richtigen Dichteziele.
Der häufigste Fehler bei dem Streben nach Informationsdichte ist Überoptimierung, bei der Autoren so aggressiv auf maximale Dichte hinarbeiten, dass der Inhalt schwer lesbar wird oder notwendiger Kontext und Erklärungen fehlen. Das zeigt sich oft als Keyword-Stuffing unter dem Deckmantel der Dichteoptimierung – mehrere Zielbegriffe werden in Sätze gepresst, wo sie nicht hingehören, was den Informationswert tatsächlich senkt und KI-Strafen auslöst. Ein weiterer Fehler ist Informationsüberflutung, wenn zu viele Themen in einem Beitrag behandelt werden; das widerspricht der UID-Hypothese, da die kognitive Belastung auf einzelne Abschnitte konzentriert und andere dünn bleiben. Schlechte Struktur ist ein weiteres Problem: Selbst dichte Inhalte verlieren an Wirkung, wenn sie nicht hierarchisch und mit klaren Konzeptbeziehungen aufgebaut sind – das erschwert es sowohl Lesern als auch KI-Systemen, den Wert zu extrahieren. Manche Autoren verwechseln Dichte mit Kürze und erstellen Inhalte, die zwar kurz, aber inhaltlich zu oberflächlich sind, um die Nutzerabsicht zu erfüllen oder KI-Systemen den nötigen Kontext für korrekte Synthese und Zitation zu liefern. Schließlich führt mangelnde Konsistenz in der Informationsverteilung dazu, dass die kognitive Belastung im Text schwankt – z.B. wenn alle Daten und Statistiken im Intro stehen und danach nur noch narrative Erklärungen folgen, was der UID-Prinzip widerspricht und die Effektivität für KI-Systeme reduziert.
Die Prinzipien der Informationsdichte gelten für alle Inhaltsformate, aber das optimale Dichteniveau und die Umsetzungsstrategie variieren je nach Inhaltstyp. Blogbeiträge profitieren meist von mittlerer bis hoher Dichte mit gezielten Beispielen und Erklärungen, die komplexe Inhalte zugänglich machen; ein technischer Blogpost kann 70–80 % Informationsdichte erreichen, ein einsteigerorientierter Beitrag eher 50–60 % zur besseren Verständlichkeit. Technische Dokumentation erfordert höchste Dichte, da Leser konzentrierten Mehrwert und kaum Füllmaterial erwarten – Dokumentation mit über 85 % Informationsdichte erzielt in KI-Systemen meist bessere Ergebnisse, da sie leichter zusammengefasst und zitiert werden kann. Produktseiten brauchen einen anderen Ansatz und balancieren Informationsdichte mit Überzeugungskraft und Nutzererlebnis; zwar sollten Funktionsbeschreibungen und Vorteile wertvoll formuliert sein, aber zu hohe Dichte kann Kunden überfordern und Konversionsraten senken. Nachrichtenartikel und journalistische Inhalte unterliegen anderen Anforderungen, da Narration und Kontext oft geringere Dichte erfordern – dennoch bevorzugen KI-Systeme auch hier effiziente Faktenvermittlung ohne übermäßigen Kommentar. Fachartikel und Whitepaper halten sehr hohe Informationsdichte aus, weil das Publikum technische Tiefe erwartet, profitieren aber trotzdem von klarer Struktur und gezielten Zusammenfassungen zur Wahrung der UID-Prinzipien. Wer diese Unterschiede kennt, kann die Informationsdichte für den jeweiligen Inhaltstyp optimal auswählen und dabei sowohl menschliche Leser als auch KI-Systeme zufriedenstellen.
Mit zunehmender Raffinesse von KI-Systemen wird Informationsdichte wohl ein noch zentraleres Ranking- und Zitationssignal, besonders da der Wettbewerb um die Aufnahme in KI Overviews steigt. Neue Forschung legt nahe, dass künftige LLMs immer nuanciertere Methoden zur Bewertung von Informationsqualität und -dichte entwickeln werden – wahrscheinlich über einfache Entropieberechnungen hinaus, hin zu semantischer Analyse, die nicht nur Dichte, sondern auch optimale Struktur für Synthese und Zitation belohnt. Die Entwicklung der KI-Suche wird Autoren bevorzugen, die verstehen, dass KI-Evolution nicht darin besteht, Algorithmen auszutricksen, sondern die Nutzerabsicht tatsächlich besser zu bedienen – dichte, gut strukturierte Inhalte dienen diesem Zweck, indem sie KI-Systemen reichhaltigeres Material bieten. Content-Ersteller sollten sich auf eine Zukunft vorbereiten, in der Content-Strategie zunehmend Qualität vor Quantität betont, in der ein 1.500-Wörter-Artikel mit außergewöhnlicher Dichte einen 5.000-Wörter-Artikel mit mittlerer Dichte übertrifft und die Fähigkeit, komplexe Ideen prägnant zu kommunizieren, zum Wettbewerbsvorteil wird. Organisationen, die ihre Präsenz in KI Overviews überwachen und Zitationsraten mit Tools wie AmICited.com verfolgen, haben einen entscheidenden Vorteil, da sie direkt beobachten können, wie Veränderungen der Informationsdichte ihre Sichtbarkeit in KI-Suchergebnissen beeinflussen. Diejenigen, die schon jetzt in das Verständnis und die Optimierung von Informationsdichte investieren, sind am besten darauf vorbereitet, wenn KI-Suche zum dominierenden Entdeckungsmechanismus für Online-Inhalte wird.

Informationsdichte bezieht sich auf die Konzentration bedeutungsvoller, umsetzbarer Erkenntnisse innerhalb von Inhalten – also wie viel Wert in jedem Wort oder Satz steckt. KI-Systeme bewerten diese Kennzahl, um zu entscheiden, welche Inhalte sie zitieren und in KI Overviews hervorheben. Eine höhere Informationsdichte führt in der Regel zu besserer Sichtbarkeit in KI-Suchergebnissen.
Die UID-Hypothese besagt, dass effektive Kommunikation einen stabilen Informationsfluss im gesamten Inhalt bewahrt. KI-Systeme verarbeiten Inhalte effektiver, wenn die kognitive Belastung gleichmäßig verteilt ist und nicht auf einzelne Abschnitte konzentriert wird. Dieses Prinzip beeinflusst direkt, wie LLMs Ihre Inhalte auswählen und zitieren.
Dichte Inhalte liefern hohen Informationswert mit minimalem Füllmaterial, verwenden präzise Sprache und vermeiden Redundanz. Dünne Inhalte enthalten viel Wiederholung und wenig wertvolle Ausschmückungen. KI-Systeme bevorzugen dichte Inhalte, weil sie effizienter zu verarbeiten und zu zitieren sind und weniger Quellreferenzen benötigen.
Sie können die Informationsdichte messen, indem Sie das Verhältnis bedeutungsvoller Informationen zur Gesamtwortzahl mit entropiebasierten Kennzahlen berechnen. Praktische Ansätze sind z.B. das Erfassen einzigartiger semantischer Konzepte pro Wort, das Zählen umsetzbarer Erkenntnisse pro 500 Wörter oder die Beobachtung, wie häufig Ihre Inhalte in KI Overviews von KI-Systemen zitiert werden.
Ja, erheblich. Studien zeigen, dass Inhalte, die für KI Overviews ausgewählt werden, etwa 40 % höhere Informationsdichte-Werte aufweisen als nicht ausgewählte Inhalte. KI-Systeme zitieren bevorzugt dichte, wertvolle Inhalte, weil sie umfassende Antworten mit weniger Quellreferenzen ermöglichen.
Häufige Fehler sind Überoptimierung, die die Lesbarkeit mindert, Keyword-Stuffing als angebliche Dichte, Informationsüberflutung durch zu viele Themen, schlechte Strukturierung, Verwechslung von Dichte mit Kürze und das Versäumnis, eine gleichmäßige Informationsverteilung im gesamten Inhalt zu gewährleisten.
Die Anforderungen an die Informationsdichte variieren je nach Format: Technische Dokumentation profitiert von 85 % und mehr Dichte, Blogbeiträge funktionieren gut mit 70-80 %, Produktseiten balancieren Dichte und Überzeugungskraft mit 50-70 % und Nachrichtenartikel arbeiten oft mit niedrigerer Dichte aufgrund erzählerischer Anforderungen. Optimieren Sie die Dichte passend zum jeweiligen Inhaltstyp.
Mit zunehmender Komplexität von KI-Systemen wird Informationsdichte vermutlich ein noch wichtigeres Rankingsignal. Zukünftige LLMs werden wahrscheinlich nuanciertere Methoden zur Bewertung der Informationsqualität entwickeln und bevorzugen Autoren, die verstehen, dass dichte, gut strukturierte Inhalte die Nutzerabsicht effektiver bedienen.
Verfolgen Sie, wie KI-Systeme wie ChatGPT, Perplexity und Google KI Overviews Ihre Marke zitieren und referenzieren. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Sichtbarkeit und Content-Performance.
Erfahren Sie, was Informationsdichte ist und wie sie die Wahrscheinlichkeit von KI-Zitationen erhöht. Entdecken Sie praxisnahe Techniken zur Optimierung von Inh...

Erfahren Sie, wie Sie Inhaltsformate für KI-Zitate mit der A/B-Testing-Methode testen. Entdecken Sie, welche Formate die höchste KI-Sichtbarkeit und Zitatraten ...

Erfahren Sie die optimalen Anforderungen an Content-Tiefe, Struktur und Detailgrad, um von ChatGPT, Perplexity und Google KI zitiert zu werden. Entdecken Sie, w...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.