GEO-Experimente durchführen: Kontrollgruppen und Variablen
Beherrschen Sie GEO-Experimente mit unserem umfassenden Leitfaden zu Kontrollgruppen und Variablen. Lernen Sie, wie Sie geografische Experimente für präzise Marketingmessung und KI-Sichtbarkeit entwerfen, ausführen und auswerten.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Was sind GEO-Experimente und warum sind sie wichtig?
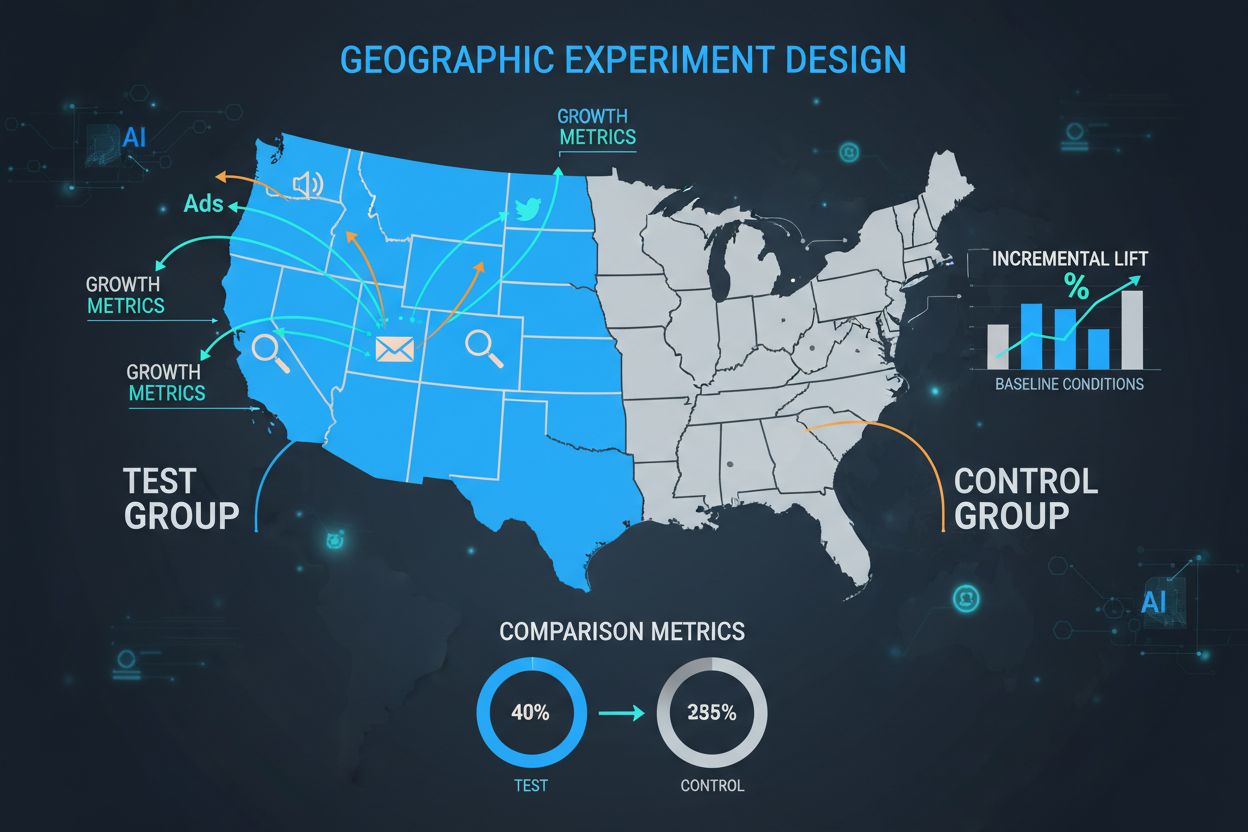
GEO-Experimente, auch bekannt als Geo-Lift-Tests oder geografische Experimente, stellen einen grundlegenden Wandel in der Messung des tatsächlichen Kampagneneffekts dar. Diese Experimente teilen geografische Regionen in Test- und Kontrollgruppen auf und ermöglichen es Marketern, den inkrementellen Effekt von Marketingmaßnahmen zu isolieren, ohne auf individuelles Tracking angewiesen zu sein. In einer Zeit, in der Datenschutzregulierungen wie DSGVO und CCPA verschärft werden und Third-Party-Cookies abgeschafft werden, bieten GEO-Experimente eine datenschutzfreundliche, statistisch robuste Alternative zu traditionellen Messmethoden. Durch den Vergleich der Ergebnisse zwischen Regionen mit und ohne Marketingmaßnahmen können Unternehmen sicher beantworten: „Was wäre ohne unsere Kampagne passiert?“ Diese Methodik ist für Marken, die wahre Inkrementalität verstehen und ihr Marketingbudget präzise optimieren möchten, unverzichtbar geworden.
Kontrollgruppen in GEO-Experimenten verstehen
Die Kontrollgruppe ist das Fundament jedes GEO-Experiments und dient als entscheidender Referenzpunkt für alle gemessenen Effekte. Eine Kontrollgruppe besteht aus geografischen Regionen, die keine Marketingintervention erhalten, sodass beobachtet werden kann, was ohne die Kampagne natürlicherweise passieren würde. Die Stärke der Kontrollgruppe liegt darin, externe Faktoren – Saisonalität, Wettbewerberaktivität, wirtschaftliche Bedingungen und Marktentwicklungen – zu berücksichtigen, die sonst die Ergebnisse verfälschen würden. Bei sorgfältigem Design ermöglichen Kontrollgruppen die Isolierung des tatsächlichen Kausaleffekts von Marketingmaßnahmen, anstatt bloße Korrelationen zu beobachten. Die Auswahl der Kontrollregionen erfordert sorgfältiges Matching über mehrere Dimensionen hinweg, darunter demografische Merkmale, historische Leistungskennzahlen, Marktgröße und Konsumverhalten. Eine schlechte Auswahl der Kontrollgruppe führt zu hoher Varianz, weiten Konfidenzintervallen und letztlich zu unzuverlässigen Schlussfolgerungen, die teure Fehlallokationen des Marketingbudgets verursachen können.
Aspekt
Kontrollgruppe
Testgruppe
Marketingintervention
Keine (Business as Usual)
Aktive Kampagne
Zweck
Referenzwert festlegen
Effekt messen
Geografische Auswahl
An Test angepasst
Hauptfokus
Datenerhebung
Gleiche Metriken
Gleiche Metriken
Stichprobengröße
Vergleichbar
Vergleichbar
Störvariablen
Minimiert
Minimiert
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Erfolgreiche GEO-Experimente erfordern die sorgfältige Steuerung mehrerer Variablentypen, die Ergebnisse und Interpretierbarkeit beeinflussen. Das Verständnis der Unterscheidung zwischen unabhängigen, abhängigen, Kontroll- und Störvariablen ist entscheidend für ein experimentelles Design mit umsetzbaren Erkenntnissen.
Unabhängige Variablen: Das sind die Marketingtaktiken, die Sie aktiv steuern und testen – z.B. Werbebudget, kreative Varianten, Kanalauswahl, Targeting-Parameter oder Angebotsstruktur. Die unabhängige Variable ist das, dessen Effekt Sie messen wollen.
Abhängige Variablen: Das sind die Ergebnisse, die Sie messen, um den Einfluss Ihrer Marketingintervention zu bewerten – z.B. Umsatz, Conversions, Neukundengewinnung, Markenbekanntheit, Website-Traffic und zunehmend für moderne Marketer: KI-Zitatsichtbarkeit und Markennennungen in KI-Systemen.
Kontrollvariablen: Das sind Faktoren, die Sie in Test- und Kontrollgruppe konstant halten, um faire Vergleiche zu gewährleisten – z.B. Messaging-Konsistenz, Angebotsstruktur, Kampagnendauer und Medienmix.
Störvariablen: Das sind unerwartete externe Faktoren, die unabhängig von Ihrer Marketingintervention die Ergebnisse beeinflussen können – z.B. Wettbewerberkampagnen, Naturkatastrophen, große Nachrichtenereignisse, saisonale Schwankungen und wirtschaftliche Veränderungen.
Messvariablen: Das sind die spezifischen KPIs und Metriken, die Sie verfolgen – z.B. inkrementeller Lift, inkrementeller ROAS (iROAS), inkrementeller CAC (iCAC) und Konfidenzintervalle Ihrer Schätzungen.
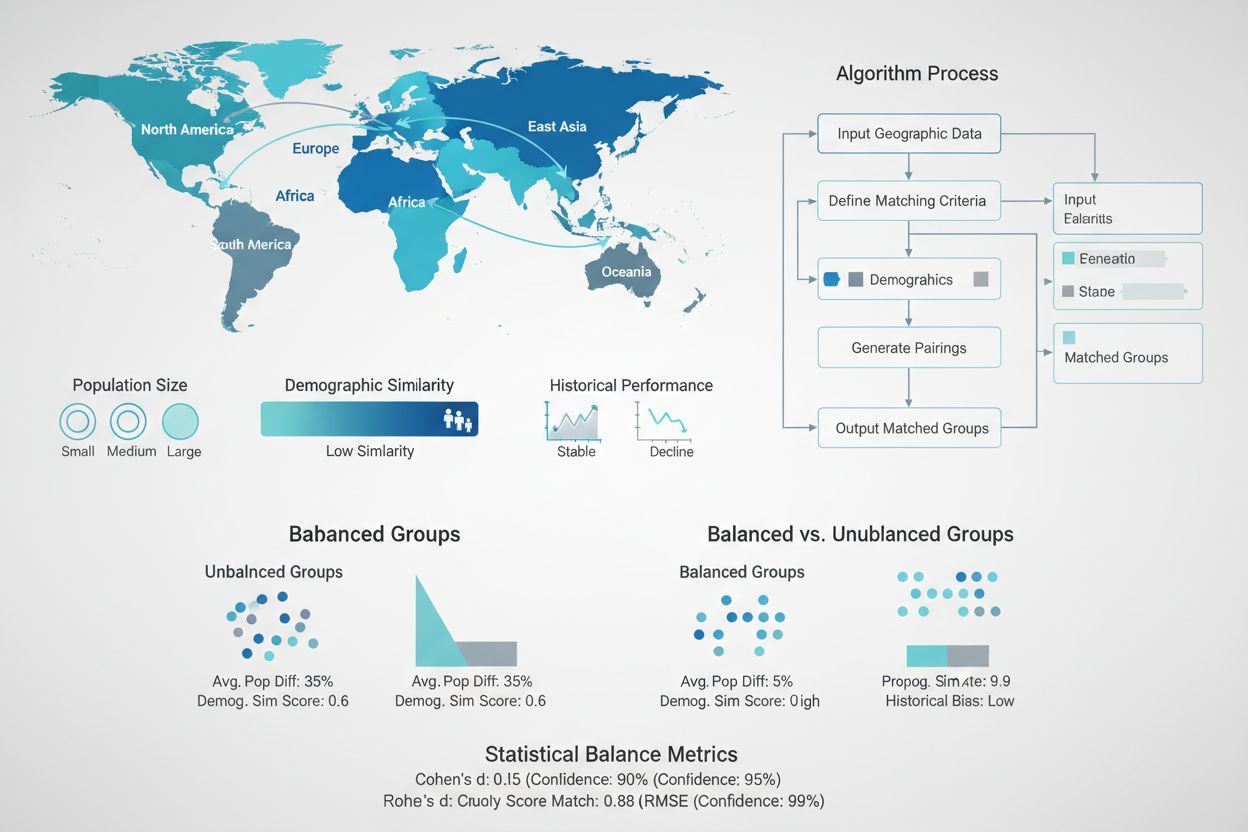
Ausgewogene Test- und Kontrollgruppen gestalten
Die Schaffung statistisch äquivalenter Test- und Kontrollgruppen ist einer der wichtigsten, aber auch herausforderndsten Aspekte des GEO-Experiment-Designs. Im Gegensatz zu randomisierten Kontrollstudien mit Millionen von Nutzern arbeitet man im GEO-Experiment oft nur mit Dutzenden bis Hunderten geografischer Einheiten, sodass reine Zufallszuteilung meist nicht ausreicht. Fortschrittliche Matching-Algorithmen und Optimierungstechniken helfen, diese Herausforderung zu meistern. Sogenannte „synthetische Kontrollmethoden“, entwickelt von Ökonometrikern und bekannt durch Unternehmen wie Wayfair und Haus, nutzen historische Daten, um Kontrollregionen zu identifizieren und zu gewichten, die den Testregionen möglichst ähnlich sind. Diese Algorithmen berücksichtigen gleichzeitig mehrere Dimensionen – Einwohnerzahl, demografische Zusammensetzung, historische Umsatzmuster, Mediennutzung und Wettbewerbssituation – um Kontrollgruppen zu schaffen, die als möglichst realistische Gegenfaktualen dienen. Ziel ist es, den Unterschied zwischen Test- und Kontrollgruppe bei allen Vorkampagnenmetriken zu minimieren, damit beobachtete Unterschiede nach der Intervention sicher dem Marketing zugeordnet werden können.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Statistische Grundlagen und Konfidenzintervalle
Die statistische Strenge unterscheidet GEO-Experimente von bloßen Beobachtungen oder Anekdoten. Konfidenzintervalle geben den Bereich an, in dem der wahre Effekt mit einer bestimmten Wahrscheinlichkeit (meist 95 %) liegt. Ein schmales Intervall weist auf hohe Präzision und Zuversicht hin, ein weites Intervall auf große Unsicherheit. Zeigt ein GEO-Experiment z.B. einen 10%igen Lift mit einem 95%-Konfidenzintervall von ±2 %, können Sie ziemlich sicher sein, dass der tatsächliche Effekt zwischen 8 % und 12 % liegt. Ein 10%iger Lift mit ±8 % Intervall (2–18 %) ist hingegen wenig handlungsrelevant. Die Breite des Intervalls hängt von mehreren Faktoren ab: Stichprobengröße (Anzahl Regionen), Ergebnisvarianz, Testdauer und erwarteter Effektgröße. Die Berechnung des Minimal Detectable Effect (MDE) hilft im Vorfeld zu entscheiden, ob das geplante Experiment Ihren gewünschten Lift sicher erkennen kann. Power-Analysen stellen sicher, dass Sie eine ausreichende Teststärke haben (typisch ≥80 %), um echte Effekte zu erkennen und sowohl Fehler 1. wie 2. Art zu kontrollieren.
Häufige Fallstricke und wie man sie vermeidet
Auch gut gemeinte GEO-Experimente liefern irreführende Ergebnisse, wenn typische Fallstricke nicht vermieden werden. Das Verständnis dieser Risiken und die Implementierung von Schutzmaßnahmen sind essenziell für verlässliche Messung.
Unausgewogene Gruppen: Unterscheiden sich Test- und Kontrollregionen signifikant in Vorkampagnenmetriken, erschwert die zusätzliche Varianz das Erkennen echter Effekte. Lösung: Matching-Algorithmen und synthetische Kontrollmethoden nutzen, um Gruppen auf allen wichtigen Dimensionen statistisch auszugleichen.
Spillover-Effekte: Nutzer und Werbekontakte halten sich nicht an geografische Grenzen. Menschen reisen, digitale Werbung erreicht versehentlich andere Regionen. Lösung: Geografische Grenzen so wählen, dass Kreuzkontamination minimiert wird, Pendlerbewegungen berücksichtigen und Geofencing einsetzen.
Zu kurze Testdauer: Kampagnen brauchen Zeit für Ergebnisse, und Customer Journeys können lang sein. Kurze Tests übersehen verzögerte Konversionen und saisonale Muster. Lösung: Mindestens 4–6 Wochen testen, bei langen Entscheidungszyklen länger, und Nachlaufzeit berücksichtigen.
Post-hoc-Analyseänderungen: Die Analyse nach Sichtung erster Ergebnisse zu ändern, führt zu Verzerrung und erhöht die Rate von Fehlalarmen. Lösung: Analyseplan, KPIs und Erfolgskriterien vor Teststart festlegen.
Externe Schocks ignorieren: Naturkatastrophen, Wettbewerberaktionen, Nachrichten oder Wirtschaftslage können Ergebnisse verfälschen. Lösung: Während des Tests auf Störeinflüsse achten und ggf. Test verlängern oder wiederholen.
Unzureichende Stichprobengröße: Zu wenig Regionen schränken die Teststärke ein und führen zu breiten Konfidenzintervallen. Lösung: Power-Analyse vorab durchführen, um die nötige Anzahl an Regionen zu bestimmen.
Inkrementalität und Lift messen
Inkrementalität ist der wahre kausale Effekt von Marketing – also der Unterschied zwischen dem, was tatsächlich passiert ist, und dem, was ohne Intervention passiert wäre. Lift ist das quantitative Maß dieser Inkrementalität, berechnet als Differenz der wichtigsten Kennzahlen zwischen Test- und Kontrollgruppe. Haben Testregionen z.B. 1.000.000 € Umsatz erzielt, Kontrollregionen 900.000 €, ist der absolute Lift 100.000 €, der prozentuale Lift 11,1 % (100.000 / 900.000). Rohe Lift-Werte berücksichtigen jedoch nicht die Marketingkosten. Der inkrementelle ROAS (iROAS) teilt den zusätzlichen Umsatz durch die zusätzlichen Ausgaben und zeigt so die Rendite pro weiterem investierten Euro. Gibt die Testregion 50.000 € mehr aus und erzielt 100.000 € zusätzlichen Umsatz, beträgt der iROAS 2,0x. Ebenso misst der inkrementelle CAC (iCAC) die Kosten pro zusätzlichem Neukunden – wichtig zur Bewertung der Akquisitionskanäle. Besonders wertvoll werden diese Kennzahlen, wenn man sie mit Sichtbarkeitsmessung verknüpft: Es wird nicht nur der Absatzlift, sondern auch der Einfluss von Marketing auf KI-Zitate und Markennennungen in GPTs, Perplexity und Google KI-Overviews messbar.
GEO-Experimente für KI-Sichtbarkeit und Markenmonitoring
Da KI-Systeme zum primären Entdeckungskanal für Verbraucher werden, ist die Messung des Marketingeinflusses auf KIsichtbarkeit entscheidend. GEO-Experimente liefern einen rigorosen Rahmen, um verschiedene Inhaltsstrategien und deren Auswirkungen auf KI-Zitatfrequenz und -genauigkeit zu testen. Indem in bestimmten Regionen gezielte Optimierungen für KI-Sichtbarkeit (z.B. strukturierte Daten, klare Markenbotschaften, optimierte Inhaltsformate) durchgeführt werden, während Kontrollregionen beim Status quo bleiben, lässt sich der zusätzliche Effekt auf KI-Nennungen quantifizieren. Besonders wertvoll ist dies, um zu verstehen, welche Formate, Botschaften und Informationsstrukturen von KIs bevorzugt für Zitate genutzt werden. AmICited begleitet diese Experimente, indem es misst, wie oft Ihre Marke in KI-generierten Antworten in unterschiedlichen Regionen und Zeiträumen erscheint und so die Datenbasis für Sichtbarkeits-Lifts liefert. Die Inkrementalität der Sichtbarkeitssteigerung kann dann mit Geschäftsergebnissen verknüpft werden: Zeigen Regionen mit mehr KI-Zitaten auch mehr Traffic, Markensuchen oder Conversions? So wird KI-Sichtbarkeit von einer reinen Vanity-Metrik zu einem messbaren Treiber von Geschäftserfolg – und ermöglicht gezielte Budgetallokation für Sichtbarkeitsinitiativen.
Fortgeschrittene Methoden: Synthetische Kontrolle und Bayessche Ansätze
Neben einfachen Difference-in-Differences-Analysen etablieren sich fortgeschrittene Methoden, um Genauigkeit und Zuverlässigkeit von GEO-Experimenten zu erhöhen. Die synthetische Kontrollmethode erstellt eine gewichtete Kombination von Kontrollregionen, die die Vorkampagnenentwicklung der Testregionen am besten abbildet – eine deutlich realistischere Gegenfaktuale als jede einzelne Region. Besonders mächtig ist das, wenn viele Kontrollregionen zur Verfügung stehen und alle Informationen genutzt werden sollen. Bayessche Strukturelle Zeitreihenmodelle (BSTS), bekannt geworden durch Googles CausalImpact-Paket, erweitern synthetische Kontrolle um Unsicherheitsquantifizierung und probabilistische Prognosen. BSTS-Modelle lernen die historische Beziehung zwischen Test- und Kontrollregionen in der Vorkampagnenphase und prognostizieren, wie sich die Testregion ohne Intervention entwickelt hätte. Die Differenz zwischen tatsächlichen und prognostizierten Werten entspricht dem geschätzten Effekt, wobei Glaubwürdigkeitsintervalle die Unsicherheit angeben. Difference-in-Differences (DiD) vergleicht die Veränderung vor und nach der Intervention zwischen Test- und Kontrollgruppen und eliminiert so zeitinvariante Unterschiede. Jede Methode hat Vor- und Nachteile: Synthetische Kontrolle benötigt viele Kontrollregionen, setzt aber keine Paralleltrends voraus; BSTS bildet komplexe Zeitdynamiken ab, erfordert aber sorgfältige Modellierung; DiD ist einfach und intuitiv, aber empfindlich gegenüber Verletzungen der Paralleltrends-Annahme. Moderne Plattformen wie Lifesight und Haus automatisieren diese Methoden und machen sie auch ohne Statistikkenntnisse für Marketer nutzbar.
Praxisbeispiele und Ergebnisse
Führende Unternehmen zeigen mit starken Ergebnissen die Kraft von GEO-Experimenten. Wayfair entwickelte einen ganzzahligen Optimierungsansatz, um Hunderte geografischer Einheiten auf Test- und Kontrollgruppen zu verteilen und mehrere KPIs gleichzeitig exakt auszubalancieren – so konnten empfindlichere Experimente mit kleineren Holdout-Anteilen durchgeführt werden. Polar Analytics analysierte Hunderte Geo-Tests und fand, dass synthetische Kontrollmethoden etwa viermal präzisere Ergebnisse als einfaches Matching liefern – engere Konfidenzintervalle ermöglichen sicherere Entscheidungen. Haus führte Fixed Geo Tests für Out-of-Home- und Retail-Kampagnen ein, bei denen Marketer Regionen nicht randomisiert zuteilen, aber dennoch den Effekt vordefinierter Rollouts messen müssen. Ihr Case mit Jones Road Beauty zeigte, wie Fixed Geo Tests den inkrementellen Effekt von Plakatkampagnen in bestimmten Märkten exakt messen. Lifesight verkürzte bei großen Marken aus Handel, FMCG und DTC die Testdauer von 8–12 auf 4–6 Wochen und erhöhte die Genauigkeit dank fortschrittlicher Matching-Algorithmen. Gemeinsam zeigen diese Beispiele: Richtig geplante und durchgeführte GEO-Experimente liefern überraschende Erkenntnisse – Kanäle, die als sehr effektiv galten, erweisen sich oft als wenig inkrementell, während unterschätzte Kanäle starke zusätzliche Effekte zeigen und so zu erheblichen Budgetumschichtungen führen.
Ein erfolgreiches GEO-Experiment erfordert systematisches Vorgehen in mehreren Phasen:
Klare Ziele und KPIs definieren: Legen Sie fest, was Sie messen möchten (Umsatz, Conversions, Markenbekanntheit, KI-Zitate) und setzen Sie spezifische, messbare Ziele. Stimmen Sie die Erwartungen mit den Unternehmenszielen ab und schätzen Sie realistische Effektgrößen ab.
Geografische Regionen auswählen und matchen: Wählen Sie Regionen, die Ihren Zielmarkt repräsentieren und genügend Datenvolumen bieten. Nutzen Sie Matching-Algorithmen, um Kontrollregionen mit möglichst ähnlichen historischen Werten zu identifizieren.
Datenbereitschaft sicherstellen: Prüfen Sie, ob Sie die KPIs in allen Regionen während des Testzeitraums genau tracken können. Führen Sie Daten-Audits auf Qualität, Vollständigkeit und Konsistenz durch.
Experimentparameter festlegen: Bestimmen Sie die Testdauer (meist mindestens 4–6 Wochen), definieren Sie die Intervention präzise und dokumentieren Sie alle Annahmen und Erfolgskriterien vor dem Start.
Kampagne simultan durchführen: Starten Sie die Kampagne in den Testregionen und halten Sie die Kontrollregionen im selben Zeitraum beim Status quo. Koordinieren Sie bereichsübergreifend für konsistente Umsetzung.
Laufend überwachen: Tracken Sie täglich die wichtigsten Metriken, um unerwartete Muster, externe Schocks oder Umsetzungsprobleme früh zu erkennen.
Daten sammeln und analysieren: Aggregieren Sie die Daten aller Regionen und wenden Sie die vordefinierte Analysemethodik an. Berechnen Sie Lift, Konfidenzintervalle und Sekundärmetriken.
Ergebnisse sorgfältig interpretieren: Bewerten Sie nicht nur die statistische, sondern auch die praktische Signifikanz. Berücksichtigen Sie Intervallbreite, Effektgröße und Business Impact bei der Ableitung von Schlüssen.
Dokumentieren und teilen: Erstellen Sie einen umfassenden Report zu Methodik, Ergebnissen und Learnings. Teilen Sie die Erkenntnisse mit Stakeholdern, um die weitere Strategie zu informieren.
Nächste Experimente planen: Nutzen Sie die Learnings für die nächste Testreihe und bauen Sie eine kontinuierliche Test- und Optimierungskultur auf.
Tools und Plattformen für GEO-Experimente
Das GEO-Experimentier-Umfeld hat sich stark weiterentwickelt, spezialisierte Plattformen automatisieren heute viele Komplexitäten. Haus bietet GeoLift für klassische randomisierte Tests und Fixed Geo Tests für vordefinierte Rollouts, mit besonderer Stärke im Omnichannel-Monitoring. Lifesight automatisiert den gesamten Prozess von Design bis Analyse mit proprietären Matching-Algorithmen und synthetischer Kontrollmethodik, wodurch Tests kürzer und präziser werden. Polar Analytics konzentriert sich auf Inkrementalitätstests mit Fokus auf kausalen Lift und Intervallgenauigkeit. Paramark ist spezialisiert auf Marketing-Mix-Modellierung, validiert durch Geo-Experimente, und hilft Marken, MMM-Prognosen an realen Testergebnissen zu kalibrieren. Bei der Bewertung von Plattformen sollten Sie auf folgende Merkmale achten: automatisiertes Matching und Balancing, Support für digitale und Offline-Kanäle, Echtzeit-Monitoring und Early-Stopping, transparente Methodik und Intervallreporting sowie Integration in Ihre bestehende Dateninfrastruktur. AmICited ergänzt diese Plattformen um die Sichtbarkeitsmessung – es trackt, wie oft Ihre Marke in KI-generierten Antworten in Test- und Kontrollregionen erscheint, sodass Sie die Inkrementalität sichtbarkeitsorientierter Initiativen messen können.
Best Practices und Empfehlungen
Erfolgreiche GEO-Experimente erfordern die Einhaltung bewährter Praktiken, um Zuverlässigkeit und Umsetzbarkeit zu maximieren:
Mit klaren Hypothesen starten: Definieren Sie vor Teststart konkrete, überprüfbare Hypothesen. Vermeiden Sie „Fishing Expeditions“, die ohne klare Vorhersagen viele Variablen gleichzeitig testen.
In Matching investieren: Investieren Sie Zeit in sorgfältiges Matching der Gruppen. Schlechte Ausgangsgruppen untergraben jede spätere Analyse und vergeuden Ressourcen.
Testdauer einhalten: Vermeiden Sie vorzeitigen Abbruch bei vielversprechenden Zwischenergebnissen. Zu frühes Stoppen verzerrt die Ergebnisse und erhöht Fehlalarme. Halten Sie die geplante Dauer durch.
Auf Störfaktoren achten: Beobachten Sie externe Ereignisse, Wettbewerberaktionen und Marktveränderungen während des gesamten Tests. Seien Sie bereit, Tests bei gravierenden Störungen zu verlängern oder zu wiederholen.
Alles dokumentieren: Halten Sie Design, Durchführung, Analyse und Ergebnisse detailliert fest. Diese Dokumentation ermöglicht Lernen, Replikation und institutionelles Wissensmanagement.
Eine Testkultur aufbauen: Entwickeln Sie von einmaligen Experimenten hin zu systematischen Testprogrammen. Jedes Experiment sollte das nächste informieren und einen Kreislauf aus Lernen und Optimierung schaffen.
Mit Geschäftsergebnissen verknüpfen: Messen Sie Metriken, die direkt auf Geschäftsziele einzahlen. Vermeiden Sie Vanity-Kennzahlen ohne Verbindung zu Umsatz oder strategischen Zielsetzungen.
Häufig gestellte Fragen
Was ist der Unterschied zwischen GEO-Experimenten und A/B-Tests?
GEO-Experimente testen auf geografischer/regionaler Ebene, um die Inkrementalität von Kampagnen zu messen, die nicht auf individueller Nutzerbasis getestet werden können, während A/B-Tests einzelne Nutzer für digitale Optimierung randomisieren. GEO-Experimente eignen sich besser für Offline-Medien, Upper-Funnel-Kampagnen und die Messung des tatsächlichen Kausaleffekts, während A/B-Tests bei der Optimierung digitaler Erfahrungen mit schnelleren Ergebnissen glänzen.
Wie lange sollte ein GEO-Experiment laufen?
Typischerweise mindestens 4–6 Wochen, abhängig vom Konversionszyklus und der Saisonalität. Längere Tests liefern verlässlichere Ergebnisse, verursachen aber höhere Kosten. Die Testdauer sollte ausreichen, um die gesamte Customer Journey abzudecken und verzögerte Konversionseffekte zu berücksichtigen.
Wie groß muss der Markt mindestens für ein GEO-Experiment sein?
Es gibt keine feste Mindestgröße, aber Sie benötigen ein ausreichendes Datenvolumen, um statistische Signifikanz zu erreichen. In der Regel brauchen Sie genügend Regionen und Transaktionen, um den erwarteten Effekt mit ausreichender Teststärke (meist 80 % oder mehr) zu erkennen. Kleinere Märkte erfordern längere Testphasen.
Wie verhindert man Spillover-Effekte zwischen Test- und Kontrollregionen?
Verwenden Sie geografische Grenzen, die Kreuzkontamination minimieren, berücksichtigen Sie Pendlerströme und Medienüberschneidungen, setzen Sie Geofencing-Technologie für präzise Steuerung ein und wählen Sie geografisch isolierte Regionen. Spillover-Effekte treten auf, wenn Nutzer oder Medienkontakte zwischen Test- und Kontrollregionen wechseln und so die Ergebnisse verwässern.
Welches Konfidenzniveau sollte ich für GEO-Experimente anstreben?
Der Standard ist 95 % Konfidenz (p < 0,05), das heißt, Sie können zu 95 % sicher sein, dass der beobachtete Effekt real ist und nicht zufällig. Berücksichtigen Sie jedoch Ihren Geschäftskontext – die Kosten von falsch-positiven im Vergleich zu falsch-negativen Ergebnissen – bei der Festlegung Ihres Konfidenzschwellenwerts.
Können GEO-Experimente Markenbekanntheit und KI-Sichtbarkeit messen?
Ja, durch Umfragen, Brand-Lift-Studien und KI-Zitat-Tracking. Sie können messen, wie Marketing die Markenbekanntheit, Beliebtheit und insbesondere die Häufigkeit beeinflusst, mit derIhre Marke in KI-generierten Antworten in verschiedenen Regionen erscheint – so lässt sich die Inkrementalität der Sichtbarkeit messen.
Wie wirken sich externe Ereignisse auf GEO-Experimente aus?
Naturkatastrophen, Wettbewerberkampagnen, große Nachrichtenereignisse und wirtschaftliche Veränderungen können die Ergebnisse verfälschen, indem sie Störvariablen einführen. Überwachen Sie solche Ereignisse während des gesamten Tests und seien Sie bereit, den Testzeitraum zu verlängern oder das Experiment bei erheblichen Störungen zu wiederholen.
Wie hoch ist der ROI von GEO-Experimenten?
GEO-Experimente amortisieren sich in der Regel, indem sie Fehlinvestitionen in unwirksame Kanäle verhindern und eine sichere Budgetumschichtung zu leistungsstarken Taktiken ermöglichen. Sie liefern die Faktenbasis, die alle nachgelagerten Messungen und Entscheidungen verbessert – von der MMM-Kalibrierung bis zur Kanaloptimierung.
Überwachen Sie die KI-Sichtbarkeit Ihrer Marke mit AmICited
GEO-Experimente zeigen, wie Ihr Marketing die Sichtbarkeit beeinflusst. AmICited verfolgt, wie KI-Systeme Ihre Marke in GPTs, Perplexityund Google KI-Overviews zitieren, damit Sie die wahre Inkrementalität von Sichtbarkeitssteigerungen messen können.
Wie testet man eigentlich, ob die GEO-Strategie funktioniert? Suche nach Messrahmen
Community-Diskussion über das Testen der GEO-Strategie-Wirksamkeit. Frameworks und Methoden zur Messung, ob Ihre Generative Engine Optimization-Maßnahmen tatsäc...
So testen Sie die Effektivität Ihrer GEO-Strategie: Wichtige Kennzahlen und Tools
Erfahren Sie, wie Sie die Effektivität der GEO-Strategie anhand von KI-Sichtbarkeitswerten, Attributierungshäufigkeit, Engagement-Raten und geografischen Perfor...
So messen Sie frühen GEO-Erfolg: Wichtige Metriken und KPIs für KI-Such-Sichtbarkeit
Erfahren Sie, wie Sie GEO-Erfolg mit KI-Zitateverfolgung, Marken-Nennungen und Sichtbarkeitsmetriken auf ChatGPT, Perplexity, Google AI Overviews und Claude mes...
14 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.