
Token
Erfahren Sie, was Tokens in Sprachmodellen sind. Tokens sind grundlegende Einheiten der Textverarbeitung in KI-Systemen und repräsentieren Wörter, Teilwörter od...
10 Min. Lesezeit

Erfahren Sie, wie sich Token-Limits auf die KI-Leistung auswirken, und entdecken Sie praktische Strategien zur Inhaltsoptimierung, einschließlich RAG-, Chunking- und Zusammenfassungstechniken.
Tokens sind die grundlegenden Bausteine, mit denen KI-Modelle Informationen verarbeiten und verstehen. Anstatt mit vollständigen Wörtern oder Sätzen zu arbeiten, zerlegen große Sprachmodelle Text in kleinere Einheiten, sogenannte Tokens, die – je nach Tokenisierungsalgorithmus – einzelne Zeichen, Teilwörter oder vollständige Wörter sein können. Jedem Token wird eine eindeutige numerische Kennung zugewiesen, die das Modell intern für Berechnungen verwendet. Dieser Tokenisierungsprozess ist essenziell, da er KI-Systemen ermöglicht, Eingaben variabler Länge effizient zu verarbeiten und eine konsistente Bearbeitung unterschiedlicher Inhalte sicherzustellen. Das Verständnis von Tokens ist für jeden, der mit KI-Systemen arbeitet, von entscheidender Bedeutung, da sie sich direkt auf Leistung, Kosten und die Qualität der erzielbaren Ergebnisse auswirken.
Verschiedene KI-Modelle verfügen über sehr unterschiedliche Token-Limits, die die maximale Informationsmenge definieren, die sie in einer einzelnen Anfrage verarbeiten können. Diese Limits haben sich in den letzten Jahren dramatisch weiterentwickelt, wobei neuere Modelle deutlich größere Kontextfenster unterstützen. Das Token-Limit umfasst sowohl Eingabetokens (Ihr Prompt und Ihre Daten) als auch Ausgabetokens (die Antwort des Modells) und schafft so ein gemeinsames Budget, das sorgfältig verwaltet werden muss. Das Verständnis dieser Limits ist entscheidend, um das richtige Modell für Ihren Anwendungsfall auszuwählen und Ihre Anwendungsarchitektur entsprechend zu planen.
| Modell | Token-Limit | Hauptanwendungsfall | Kostenstufe |
|---|---|---|---|
| GPT-3.5 Turbo | 4.096 | Kurze Gespräche, schnelle Aufgaben | Gering |
| GPT-4 | 8.192 | Standardanwendungen, mittlere Komplexität | Mittel |
| GPT-4 Turbo | 128.000 | Lange Dokumente, komplexe Analysen | Hoch |
| Claude 3.5 Sonnet | 200.000 | Ausgedehnte Dokumente, umfassende Analysen | Hoch |
| Gemini 1.5 Pro | 1.000.000 | Riesige Datensätze, ganze Bücher, Videoanalysen | Sehr hoch |
Wichtige Überlegungen bei der Bewertung von Token-Limits:
Token-Limits stellen erhebliche Einschränkungen dar, die sich direkt auf die Genauigkeit, Zuverlässigkeit und Kosteneffizienz von KI-Anwendungen auswirken. Wenn Sie das Token-Limit eines Modells überschreiten, schlägt die Anwendung komplett fehl – es gibt keine sanfte Degradierung oder Teilverarbeitung. Selbst bei Einhaltung der Limits können naive Ansätze wie einfache Trunkierung die Leistung stark beeinträchtigen, da sie wichtigen Kontext entfernen, den das Modell für genaue Antworten benötigt. Besonders problematisch ist dies in Bereichen wie juristischer Analyse, medizinischer Forschung und Softwareentwicklung, wo das Fehlen auch nur eines wichtigen Details zu falschen Schlussfolgerungen führen kann. Die Herausforderung wird noch komplexer, da verschiedene Inhaltstypen unterschiedlich viele Tokens verbrauchen – strukturierte Daten wie Code oder JSON benötigen aufgrund von Symbolen und Formatierungen deutlich mehr Tokens als reiner englischer Text.
Trunkierung ist die einfachste Methode, um mit Token-Limits umzugehen – Sie schneiden einfach überflüssige Inhalte ab, sobald das Modell seine Kapazität überschreitet. Auch wenn diese Methode leicht zu implementieren ist, birgt sie erhebliche Risiken. Beim Trunkieren von Texten gehen zwangsläufig Informationen verloren, und das Modell weiß nicht, was entfernt wurde. Dies kann zu unvollständigen Analysen, fehlendem Kontext und Halluzinationen führen, bei denen das Modell plausibel klingende, aber falsche Informationen generiert, um Lücken im Verständnis zu füllen.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Eine ausgefeiltere Trunkierungsstrategie unterscheidet zwischen essenziellen und optionalen Inhalten. Sie können zwingend erforderliche Elemente wie die aktuelle Nutzeranfrage und Kernanweisungen priorisieren und optionalen Kontext wie Gesprächsverlauf nur dann anhängen, wenn noch Platz vorhanden ist. So bleibt wichtige Information erhalten, während das Token-Limit eingehalten wird.
Statt zu trunkieren, unterteilt Chunking Ihren Inhalt in kleinere, handhabbare Abschnitte, die unabhängig oder selektiv verarbeitet werden können. Fixed-Size-Chunking teilt den Text in gleichmäßige Segmente, während semantisches Chunking Embeddings verwendet, um natürliche Trennstellen anhand der Bedeutung statt nach willkürlicher Tokenzahl zu identifizieren. Gleitende Fenster mit Überlappung bewahren Kontext zwischen den Chunks, sodass wichtige Informationen, die Chunk-Grenzen überschreiten, nicht verloren gehen.
Hierarchisches Chunking schafft mehrere Abstraktionsebenen – einzelne Absätze auf der feinsten Ebene, Abschnitte auf der nächsten und Kapitel auf der höchsten Ebene. Dieser Ansatz ermöglicht ausgefeilte Retrieval-Strategien, mit denen relevante Abschnitte schnell identifiziert werden können, ohne das gesamte Dokument zu verarbeiten. In Kombination mit Vektordatenbanken und semantischer Suche wird Chunking zu einem leistungsstarken Werkzeug für das Management großer Wissensbasen bei gleichzeitiger Wahrung von Relevanz und Genauigkeit.
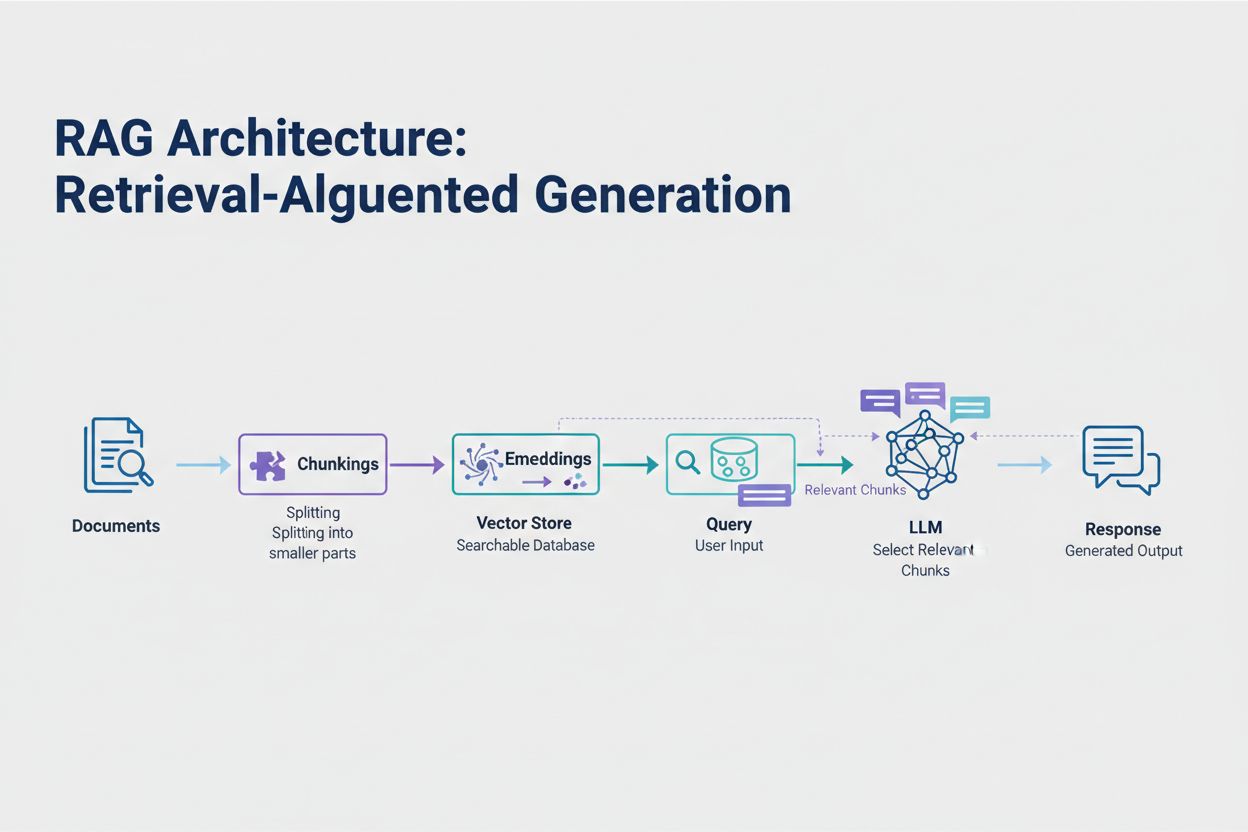
Retrieval-Augmented Generation (RAG) ist der derzeit effektivste Ansatz zur Bewältigung von Token-Limits. Anstatt zu versuchen, alle Daten in das Kontextfenster des Modells zu zwängen, ruft RAG zur Anfragezeit nur die relevantesten Informationen ab. Der Prozess beginnt damit, dass Ihre Dokumente in Embeddings – numerische Repräsentationen der semantischen Bedeutung – umgewandelt werden. Diese Embeddings werden in einer Vektordatenbank gespeichert und ermöglichen schnelle Ähnlichkeitssuchen.
Wenn ein Nutzer eine Anfrage stellt, wird diese als Embedding verarbeitet und die relevantesten Dokument-Chunks aus dem Vektorstore abgerufen. Nur diese relevanten Chunks werden zusammen mit der Nutzerfrage in den Prompt eingefügt, was den Tokenverbrauch drastisch reduziert und die Genauigkeit erhöht. Beispielsweise kann die Analyse eines 100-seitigen Vertrags mittels RAG nur 3–5 Schlüsselklauseln im Prompt erfordern, statt der Tausenden Tokens, die das vollständige Dokument benötigen würde.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Zusammenfassungen komprimieren umfangreiche Inhalte, während wichtige Informationen erhalten bleiben – so wird der Tokenverbrauch effektiv reduziert. Extraktive Zusammenfassungen wählen Schlüsselsätze aus dem Originaltext aus, während abstraktive Zusammenfassungen neuen, kompakten Text erzeugen, der die Hauptideen wiedergibt. Hierarchische Zusammenfassungen erstellen mehrere Ebenen von Zusammenfassungen – zuerst für einzelne Abschnitte, dann werden diese zu übergeordneten Übersichten kombiniert. Dieser Ansatz eignet sich besonders gut für strukturierte Dokumente wie wissenschaftliche Arbeiten oder technische Berichte.
Kontextkomprimierung verfolgt einen anderen Ansatz, indem sie Redundanzen und Füllwörter entfernt, aber die Originalformulierungen beibehält. Wissensgraph-Ansätze extrahieren Entitäten und Beziehungen aus Texten und rekonstruieren den Kontext mit nur den relevantesten Fakten. Diese Techniken können eine Token-Reduktion von 40–60 % erreichen, während die semantische Genauigkeit erhalten bleibt – ein wertvoller Ansatz zur Kostenoptimierung in Produktionssystemen.
Das Token-Management wirkt sich direkt auf die Kosten Ihrer KI-Anwendung aus. Jeder während der Inferenz verbrauchte Token verursacht Kosten, und diese skalieren linear mit der Token-Nutzung. Das Monitoring des Tokenverbrauchs ist entscheidend, um Ihre Kostenstruktur zu verstehen und Optimierungspotenziale zu identifizieren. Viele KI-Plattformen bieten inzwischen Token-Zählwerkzeuge und Echtzeit-Dashboards, mit denen Sie Nutzungsmuster verfolgen und erkennen können, welche Anfragen oder Funktionen die meisten Tokens verbrauchen.
Effektives Monitoring offenbart Optimierungsmöglichkeiten – vielleicht überschreiten bestimmte Fragetypen regelmäßig die Token-Limits, oder einzelne Funktionen verbrauchen unverhältnismäßig viele Ressourcen. Durch die Analyse dieser Muster können Sie fundierte Entscheidungen darüber treffen, welche Optimierungsstrategie Sie umsetzen. Manche Anwendungen profitieren davon, große Anfragen an leistungsfähigere (aber teurere) Modelle weiterzuleiten, andere mehr von der Implementierung von RAG oder Zusammenfassung. Entscheidend ist, tatsächliche Leistung und Kosten zu messen, um Ihre Optimierungsentscheidungen zu validieren.
Die Wahl der richtigen Token-Management-Strategie hängt von Ihrem Anwendungsfall, Leistungsanforderungen und Kostenrahmen ab. Anwendungen, die höchste Genauigkeit mit belegbaren Antworten erfordern, profitieren am meisten von RAG, das Informationsintegrität bewahrt und den Tokenverbrauch steuert. Langlaufende Konversationsanwendungen profitieren von Speicherpuffertechniken, die Gesprächsverläufe zusammenfassen und dabei Schlüsselinformationen und Kontext erhalten. Dokumentenlastige Anwendungen wie juristische Analysen oder Recherchetools gewinnen oft durch hierarchische Zusammenfassungen in Kombination mit semantischem Chunking.
Tests und Validierung sind unerlässlich, bevor Sie eine Token-Management-Strategie in die Produktion überführen. Erstellen Sie Testfälle, die die Token-Limits Ihres Modells überschreiten, und bewerten Sie, wie sich verschiedene Strategien auf Genauigkeit, Latenz und Kosten auswirken. Messen Sie Kennzahlen wie Antwortrelevanz, Faktengenauigkeit und Tokeneffizienz, um sicherzustellen, dass Ihr Ansatz die Anforderungen erfüllt. Häufige Fallstricke sind zu aggressive Zusammenfassungen, die wichtige Details verlieren, Retrieval-Systeme, die relevante Informationen übersehen, und Chunking-Strategien, die Inhalte an semantisch ungünstigen Stellen aufteilen.
Token-Limits werden weiter steigen, da Modelle immer ausgefeilter und effizienter werden. Neue Techniken wie Sparse-Attention-Mechanismen und effiziente Transformer-Architekturen versprechen, die Rechenkosten für große Kontextfenster zu senken. Multimodale Modelle, die Text, Bilder, Audio und Video gleichzeitig verarbeiten, bringen neue Herausforderungen und Chancen bei der Tokenisierung. Reasoning Tokens – spezielle Tokens, die Modelle zum “Durchdenken” komplexer Probleme verwenden – stellen eine neue Kategorie des Tokenverbrauchs dar, die anspruchsvolleres Problemlösen ermöglicht, aber sorgfältiges Management erfordert.
Die Entwicklung ist eindeutig: Während Kontextfenster wachsen und die Tokenverarbeitung effizienter wird, verlagert sich der Engpass von der reinen Kapazität hin zur intelligenten Inhaltsauswahl. Die Zukunft gehört Systemen, die relevante Informationen aus riesigen Wissensbasen gezielt identifizieren und abrufen können, statt einfach mehr Daten zu verarbeiten. Damit gewinnen Techniken wie RAG und semantische Suche für den Aufbau skalierbarer, kosteneffizienter KI-Anwendungen zunehmend an Bedeutung.
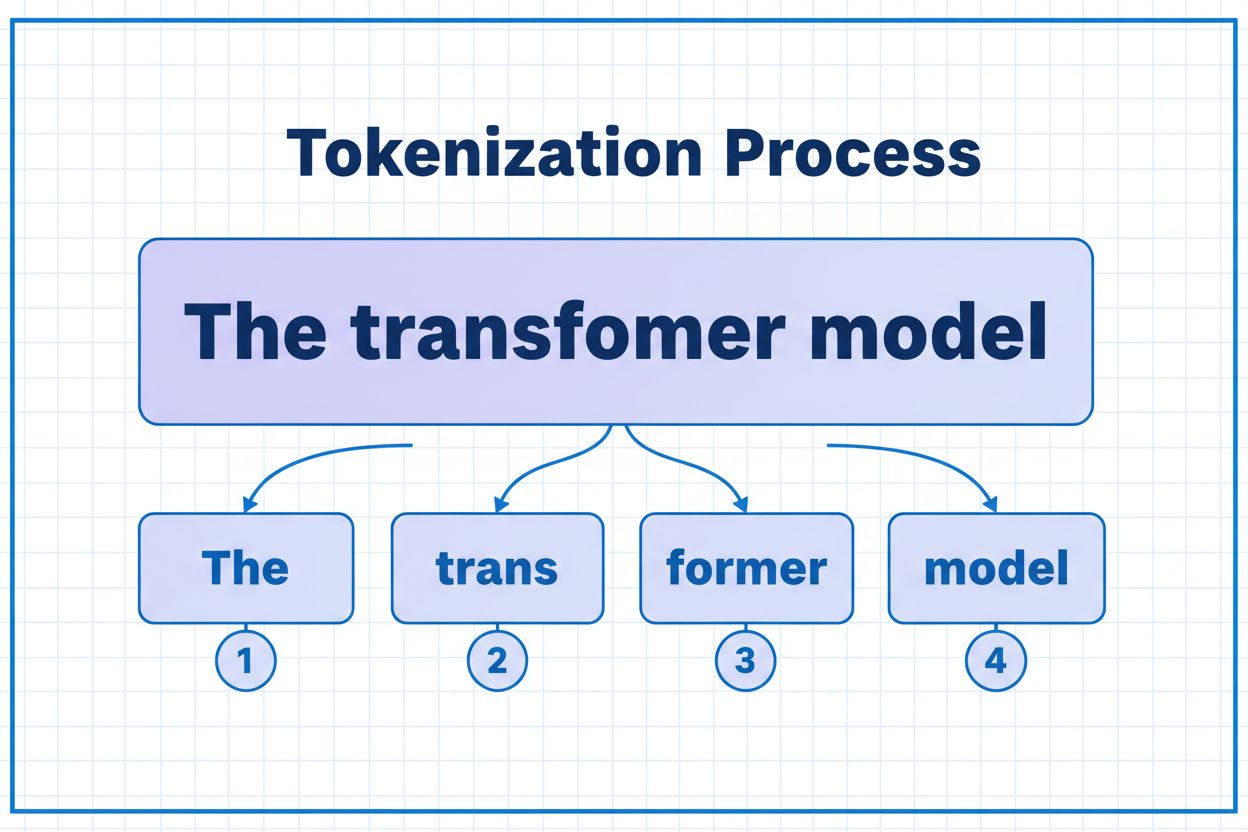
Ein Token ist die kleinste Dateneinheit, die ein KI-Modell verarbeitet. Tokens können einzelne Zeichen, Teilwörter oder vollständige Wörter sein, abhängig vom Tokenisierungsalgorithmus. Zum Beispiel könnte das Wort 'transformer' in 'trans' und 'former' als zwei separate Tokens aufgeteilt werden. Jedem Token wird eine eindeutige numerische Kennung zugewiesen, die das Modell intern für Berechnungen verwendet.
Token-Limits definieren die maximale Informationsmenge, die Ihr KI-Modell in einer einzelnen Anfrage verarbeiten kann. Überschreiten Sie dieses Limit, schlägt Ihre Anwendung komplett fehl. Selbst wenn Sie innerhalb der Limits bleiben, können naive Ansätze wie Trunkierung die Genauigkeit beeinträchtigen, indem sie wichtigen Kontext entfernen. Token-Limits wirken sich auch direkt auf die Kosten aus, da Sie in der Regel pro verbrauchtem Token bezahlen.
Eingabetokens sind die Tokens in Ihrem Prompt und den Daten, die Sie an das Modell senden, während Ausgabetokens die Tokens sind, die das Modell als Antwort generiert. Beide teilen sich ein kombiniertes Budget, das durch das Kontextfenster des Modells definiert ist. Wenn Ihre Eingabe 90 % eines 128K-Token-Fensters verwendet, bleiben nur 10 % für die Ausgabe des Modells übrig.
Trunkierung ist einfach zu implementieren, aber riskant. Sie entfernt Informationen, ohne dass das Modell weiß, was verloren ging, was zu unvollständigen Analysen und möglichen Halluzinationen führen kann. Als letzter Ausweg kann sie nützlich sein, aber bessere Ansätze wie RAG, Chunking oder Zusammenfassung erhalten die Informationsintegrität und steuern den Tokenverbrauch effektiver.
Retrieval-Augmented Generation (RAG) ruft zur Anfragezeit nur die relevantesten Informationen ab, anstatt ganze Dokumente einzuschließen. Ihre Dokumente werden in Embeddings umgewandelt und in einer Vektordatenbank gespeichert. Bei einer Nutzeranfrage werden nur relevante Chunks abgerufen und in den Prompt eingefügt, was den Tokenverbrauch drastisch reduziert und die Genauigkeit erhöht.
Die meisten KI-Plattformen bieten Token-Zählwerkzeuge und Echtzeit-Dashboards zur Überwachung der Nutzungsmuster. Überwachen Sie, welche Anfragen oder Funktionen die meisten Tokens verbrauchen, und implementieren Sie dann Optimierungsstrategien wie RAG für dokumentenlastige Anwendungen, Zusammenfassungen für lange Gespräche oder das Routing zu größeren Modellen für komplexe Aufgaben. Messen Sie die tatsächliche Leistung und die Kosten, um Ihre Entscheidungen zu validieren.
KI-Dienste berechnen in der Regel pro verbrauchtem Token. Die Kosten steigen linear mit dem Tokenverbrauch, sodass eine Optimierung der Tokens direkt Ihre Ausgaben beeinflusst. Eine Reduzierung des Tokenverbrauchs um 20 % bedeutet eine Kostenersparnis von 20 %. Das Verständnis der Tokeneffizienz hilft Ihnen, die richtige Optimierungsstrategie für Ihr Budget zu wählen.
Token-Limits werden weiter steigen, da Modelle immer leistungsfähiger werden. Neue Techniken wie Sparse-Attention-Mechanismen versprechen, die Rechenkosten für die Verarbeitung großer Kontexte zu senken. Die Zukunft liegt im intelligenten Auswählen und Abrufen von Inhalten statt in reiner Verarbeitungskapazität – deshalb werden Techniken wie RAG für skalierbare KI-Anwendungen immer wichtiger.
Verstehen Sie die Tokeneffizienz und verfolgen Sie, wie KI-Modelle Ihre Marke zitieren – mit der umfassenden KI-Zitationsüberwachungsplattform von AmICited.
Erfahren Sie, was Tokens in Sprachmodellen sind. Tokens sind grundlegende Einheiten der Textverarbeitung in KI-Systemen und repräsentieren Wörter, Teilwörter od...

Erfahren Sie, wie KI-Modelle Text durch Tokenisierung, Embeddings, Transformer-Blöcke und neuronale Netze verarbeiten. Verstehen Sie die vollständige Pipeline v...
Erfahren Sie, wie Sie die Lesbarkeit von Inhalten für KI-Systeme, ChatGPT, Perplexity und KI-Suchmaschinen optimieren. Entdecken Sie Best Practices für Struktur...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.