
Sunset-Plattformen und KI-Sichtbarkeit: Übergänge managen
Erfahren Sie, wie Sie KI-Plattformübergänge managen und die Zitier-Sichtbarkeit erhalten, wenn Plattformen eingestellt werden. Strategischer Leitfaden für den U...
9 Min. Lesezeit

Erfahren Sie, wie Sie Ihre KI-Strategie anpassen, wenn sich Plattformen verändern. Entdecken Sie Migrationsstrategien, Überwachungstools und Best Practices für den Umgang mit der Außerdienststellung und Aktualisierung von KI-Plattformen.
Die Außerdienststellung der GPT-4o-API von OpenAI im Jahr 2026 markiert einen Wendepunkt für Unternehmen, die auf KI-Plattformen aufbauen – es ist kein theoretisches Problem mehr, sondern eine unmittelbare Realität, die strategische Aufmerksamkeit verlangt. Anders als bei klassischen Software-Außerdienststellungen, bei denen oft lange Übergangsfristen gelten, können KI-Plattformänderungen mit relativ kurzer Vorlaufzeit erfolgen und Organisationen zu schnellen Technologieentscheidungen zwingen. Plattformen stellen Modelle aus mehreren überzeugenden Gründen ein: Sicherheitsbedenken bei älteren Systemen, die heutigen Standards nicht mehr entsprechen, Haftungsschutz gegen möglichen Missbrauch oder schädliche Ausgaben, sich verändernde Geschäftsmodelle mit Fokus auf neuere Angebote und die Notwendigkeit, Ressourcen auf Spitzenforschung zu bündeln. Hat ein Unternehmen ein bestimmtes Modell tief in seine Abläufe integriert – sei es für kundenorientierte Anwendungen, interne Analysen oder kritische Entscheidungsprozesse –, führt die Ankündigung einer API-Abschaltung zu unmittelbarem Druck, Alternativen zu migrieren, zu testen und zu validieren. Die finanziellen Auswirkungen reichen über reine Entwicklungskosten hinaus: Es gibt Produktivitätsverluste während der Migration, potenzielle Serviceunterbrechungen und das Risiko von Performance-Einbußen, wenn Alternativmodelle nicht die Fähigkeiten des Originals erreichen. Unvorbereitete Organisationen geraten oft in einen reaktiven Ausnahmezustand, handeln verlängerte Supportzeiträume aus oder akzeptieren suboptimale Alternativen, weil ihnen eine durchdachte Migrationsstrategie fehlt. Die zentrale Erkenntnis ist: Plattform-Außerdienststellung ist kein Randfall mehr – sie ist ein vorhersehbares Merkmal der KI-Landschaft, das proaktiver Planung bedarf.
Traditionelle Business-Continuity-Frameworks wie ISO 22301 sind auf Infrastrukturausfälle ausgelegt – Systeme fallen aus, und Sie stellen sie aus Backups oder über Failover-Systeme wieder her. Diese Frameworks setzen auf Metriken wie Recovery Time Objective (RTO) und Recovery Point Objective (RPO), um zu messen, wie schnell Sie Dienste wiederherstellen und wie viel Datenverlust akzeptabel ist. KI-Ausfälle funktionieren jedoch grundlegend anders – und diese Unterscheidung ist entscheidend: Das System läuft weiter, liefert Ausgaben und bedient Nutzer, während es stillschweigend falsche Entscheidungen trifft. Ein Fraud-Detection-Modell könnte zunehmend betrügerische Transaktionen durchwinken; eine Preis-Engine könnte systematisch zu niedrige Preise setzen; ein Kreditentscheidungsmodell könnte versteckte Vorurteile gegen geschützte Gruppen entwickeln – alles, während das System äußerlich normal funktioniert. Klassische Kontinuitätspläne erkennen solche Fehler nicht, da sie nicht nach abnehmender Genauigkeit oder neu auftretender Voreingenommenheit suchen, sondern nach Systemabstürzen und Datenverlust. Die neue Realität verlangt zusätzliche Metriken: Recovery Accuracy Objective (RAO) für akzeptable Leistungsgrenzen und Recovery Fairness Objective (RFO), um sicherzustellen, dass Modelländerungen keine Diskriminierung verursachen oder verstärken. Beispiel: Ein Finanzdienstleister nutzt ein KI-Modell für Kreditentscheidungen; driften die Ergebnisse und werden bestimmte Gruppen systematisch abgelehnt, sieht der klassische Plan kein Problem – das System ist ja „up and running“. Doch das Unternehmen steht vor regulatorischen Verstößen, Reputationsschäden und möglicher Haftung.
| Aspekt | Traditionelle Infrastrukturausfälle | KI-Modell-Ausfälle |
|---|---|---|
| Erkennung | Sofort (Systemausfall) | Verzögert (Ausgaben scheinbar normal) |
| Sichtbarkeit der Auswirkung | Klar und messbar | Versteckt in Genauigkeitsmetriken |
| Wiederherstellungsmetrik | RTO/RPO | RAO/RFO notwendig |
| Ursache | Hardware-/Netzwerkprobleme | Drift, Bias, Datenänderungen |
| Nutzererfahrung | Dienst nicht verfügbar | Dienst verfügbar, aber falsch |
| Compliance-Risiko | Datenverlust, Ausfallzeit | Diskriminierung, Haftung |
Plattform-Außerdienststellungszyklen folgen in der Regel einem vorhersehbaren Muster, auch wenn die Zeiträume je nach Plattformreife und Nutzerbasis stark variieren. Meist kündigen Plattformen Außerdienststellungen mit 12-24 Monaten Vorlauf an und geben Entwicklerteams Zeit zur Migration – bei schnelllebigen KI-Plattformen mit großen Modellfortschritten ist dieser Zeitraum jedoch oft kürzer. Die Ankündigung erzeugt sofortigen Handlungsdruck: Entwicklungsteams müssen Auswirkungen bewerten, Alternativen prüfen, Migrationen planen und Budget sowie Ressourcen sichern – und dabei den laufenden Betrieb aufrechterhalten. Versionsmanagement-Komplexität nimmt erheblich zu, wenn Organisationen während Übergangsphasen mehrere Modelle parallel betreiben; praktisch werden zwei Systeme gleichzeitig gepflegt, was Test- und Monitoring-Aufwand verdoppelt. Die Migrationszeit betrifft nicht nur API-Umstellungen, sondern auch das Antrainieren auf neue Modellausgaben, die Validierung akzeptabler Performance für eigene Anwendungsfälle und ggf. die Anpassung von Parametern, die für das alte Modell optimiert waren. Manche Unternehmen stehen vor zusätzlichen Hürden: regulatorische Prüfungen für neue Modelle, vertragliche Vorgaben bestimmter Modellversionen oder Legacy-Systeme, die tief mit einer bestimmten API verflochten sind und umfassende Entwicklungsarbeit erfordern. Wer diese Zyklen versteht, kann von reaktiver Hektik zu proaktiver Planung übergehen und Migrationen in Roadmaps einbauen, statt sie als Notfall zu behandeln.
Die direkten Kosten einer Plattformmigration werden oft unterschätzt und gehen weit über offensichtliche Entwicklungsstunden zur API-Anpassung und Modellauswahl hinaus. Entwicklungsaufwand umfasst nicht nur Codeänderungen, sondern oft auch Architekturmodifikationen – wenn Ihr System auf bestimmte Latenzen, Durchsatzgrenzen oder Ausgabeformate des alten Modells optimiert war, verlangt die neue Plattform möglicherweise tiefgreifendes Refactoring. Test und Validierung sind ein erheblicher, häufig übersehener Kostenfaktor: Sie können Modelle nicht einfach austauschen und „auf das Beste hoffen“, besonders in kritischen Anwendungen. Jeder Use Case, Edge Case und jede Integration muss gegen das neue Modell getestet werden, um akzeptable Ergebnisse sicherzustellen. Performanceunterschiede können dramatisch sein – das neue Modell ist eventuell schneller, aber weniger präzise, günstiger, aber mit anderen Ausgabecharakteristika, oder leistungsfähiger, aber mit anderen Eingabeanforderungen. Compliance- und Audit-Anforderungen kommen hinzu: In regulierten Branchen (Finanzen, Gesundheitswesen, Versicherungen) müssen Migrationen dokumentiert, regulatorische Anforderungen validiert und ggf. Genehmigungen eingeholt werden. Der Opportunitätsverlust von Entwicklern, die für Migrationen statt für Innovation und Wartung gebunden sind, ist erheblich. Oft zeigt sich erst im Verlauf, dass das „neue“ Modell andere Hyperparameter, Vorverarbeitung oder Monitoring erfordert – was Migrationsdauer und Kosten weiter erhöht.
Die widerstandsfähigsten Organisationen gestalten ihre KI-Systeme mit Plattformunabhängigkeit als zentralem Architekturprinzip – im Bewusstsein, dass das heutige Spitzenmodell irgendwann außer Dienst gestellt wird. Abstraktionsschichten und API-Wrapper sind hierfür essenziell: Statt API-Aufrufe im gesamten Code zu verteilen, wird eine einheitliche Schnittstelle geschaffen, die den Modellanbieter abstrahiert. So muss bei einem Plattformwechsel nur der Wrapper angepasst werden und nicht zig Integrationspunkte. Multi-Modell-Strategien bieten zusätzliche Resilienz: Manche Unternehmen betreiben für kritische Entscheidungen mehrere Modelle parallel, nutzen Ensemble-Methoden zur Kombination von Vorhersagen oder halten ein Ersatzmodell als Fallback bereit. Dieser Ansatz erhöht Komplexität und Kosten, bietet aber Versicherung gegen Plattformänderungen – wird ein Modell außer Dienst gestellt, ist bereits ein anderes produktiv. Fallback-Mechanismen sind ebenso wichtig: Fällt das Hauptmodell aus oder liefert verdächtige Ausgaben, sollte Ihr System auf eine sekundäre Option umschalten, statt komplett zu versagen. Robustes Monitoring und Alarming erlaubt, Performanceeinbußen, Genauigkeitsdrift oder unerwartete Verhaltensänderungen frühzeitig zu erkennen. Dokumentations- und Versionskontrolle sollten explizit festhalten, welche Modelle im Einsatz sind, wann sie produktiv gingen und wie sie performen – dieses institutionelle Wissen ist bei schnellen Migrationsentscheidungen Gold wert. Unternehmen, die in diese Muster investieren, erleben Plattformänderungen als beherrschbare Ereignisse statt als Krise.
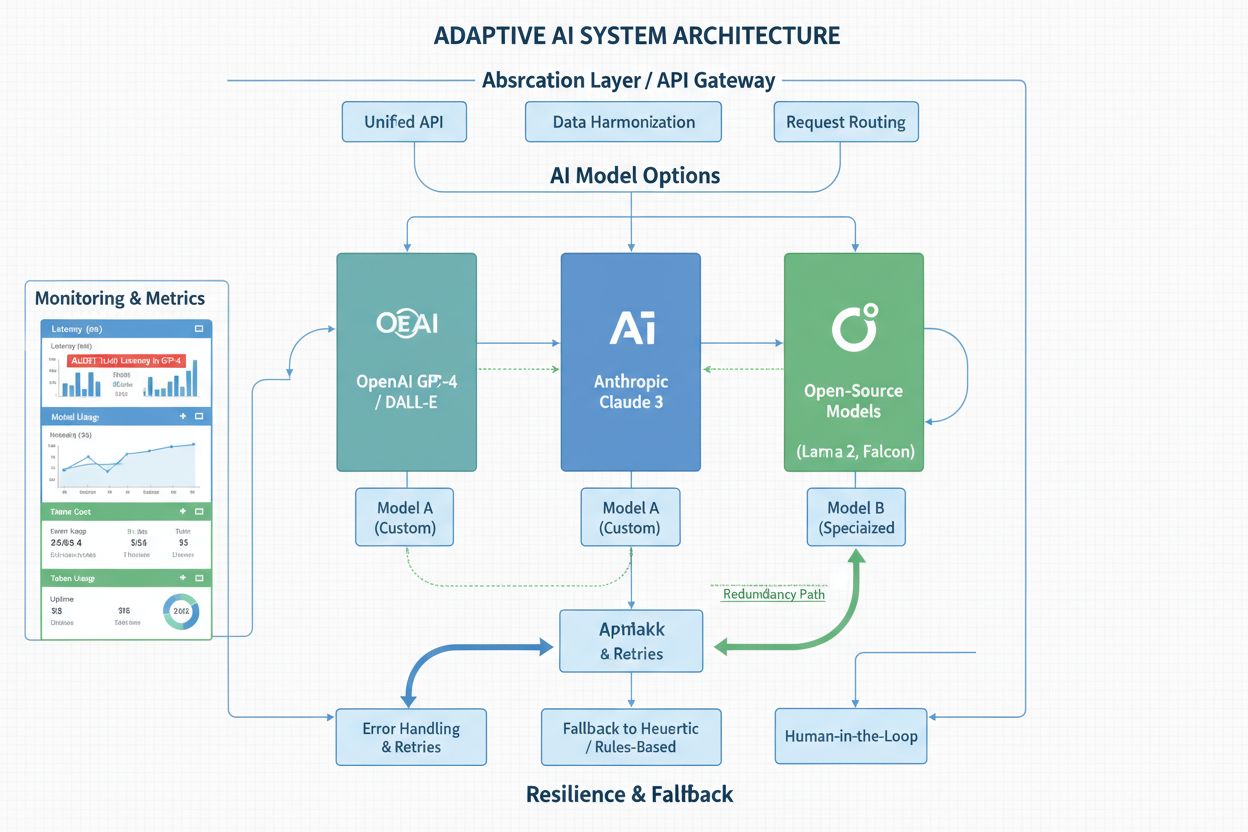
Über Plattformankündigungen und Außerdienststellungsnotizen informiert zu bleiben, erfordert systematische Überwachung – nicht bloß das Hoffen, dass wichtige Nachrichten per E-Mail eintrudeln. Die meisten großen KI-Plattformen veröffentlichen Zeitpläne für Außerdienststellungen auf ihren Blogs, in der Dokumentation und in Entwicklerportalen, doch diese Ankündigungen gehen zwischen Produkt- und Feature-Updates leicht unter. Automatisierte Alerts für bestimmte Plattformen – per RSS, E-Mail oder spezialisierte Monitoring-Services – stellen sicher, dass Sie bereits beim Bekanntwerden informiert werden und nicht erst Monate später. Über offizielle Ankündigungen hinaus ist das Überwachen von KI-Modell-Performance im Produktivbetrieb entscheidend; Plattformen ändern Modelle manchmal subtil, sodass Genauigkeitseinbußen oder Verhaltensänderungen auffallen, bevor offiziell kommuniziert wird. Tools wie AmICited bieten wertvolle Monitoring-Funktionen, indem sie erfassen, wie KI-Plattformen Ihre Marke und Inhalte referenzieren und so Hinweise auf Veränderungen und Updates liefern, die Ihr Geschäft betreffen könnten. Wettbewerbsbeobachtung zu Plattform-Updates hilft, Branchentrends zu erkennen und zu prognostizieren, welche Modelle wohl als nächste außer Dienst gestellt werden – wenn Wettbewerber bereits migrieren, ist das ein Signal für bevorstehende Änderungen. Manche Unternehmen abonnieren plattformspezifische Newsletter, beteiligen sich an Entwicklercommunities oder pflegen Beziehungen zu Account-Managern, die frühzeitig vor Änderungen warnen. Die Investition in Monitoring-Infrastruktur zahlt sich aus, wenn Sie Monate Vorlaufzeit gewinnen und Migrationen mit Planung statt Hektik angehen können.
Ein gut strukturierter Reaktionsplan für Plattformänderungen verwandelt was eine Notfallkrise sein könnte in einen geordneten Prozess mit klaren Phasen und Entscheidungsstufen. Die Bewertungsphase beginnt unmittelbar nach einer Außerdienststellungs-Ankündigung: Ihr Team analysiert alle betroffenen Systeme, schätzt Migrationsaufwand ab und identifiziert regulatorische oder vertragliche Vorgaben, die den Zeitplan beeinflussen könnten. Diese Phase liefert ein detailliertes Inventar betroffener Systeme, deren Kritikalität und Abhängigkeiten – Grundlage für alle weiteren Entscheidungen. Die Planungsphase entwickelt einen detaillierten Migrationsfahrplan, verteilt Ressourcen, legt Zeitpläne fest und bestimmt, welche Systeme zuerst migrieren (meist nicht-kritische Systeme zum Sammeln von Erfahrung, bevor die Kernanwendungen folgen). In der Testphase findet die Hauptarbeit statt: Teams prüfen, ob Alternativmodelle für die eigenen Use Cases akzeptabel performen, erkennen Leistungslücken oder Verhaltensunterschiede und entwickeln Workarounds oder Optimierungen. Die Rolloutphase führt die Migration gestuft durch – beginnend mit Canary-Deployments für einen kleinen Teil des Traffics, Monitoring auf Probleme und schrittweise Erhöhung des Anteils für das neue Modell. Post-Migrations-Monitoring läuft Wochen bis Monate weiter, überwacht Performance-Kennzahlen, Nutzerfeedback und Systemverhalten, um sicherzugehen, dass die Migration erfolgreich war und das neue Modell wie erwartet arbeitet. Organisationen mit diesem strukturierten Vorgehen berichten konsistent von reibungsloseren Migrationen, weniger Überraschungen und geringerer Nutzerbeeinträchtigung.
Die Auswahl eines Ersatzmodells oder einer Ersatzplattform erfordert eine systematische Bewertung nach klaren Auswahlkriterien, die zu den spezifischen Anforderungen und Randbedingungen Ihres Unternehmens passen. Performance-Charakteristika wie Genauigkeit, Latenz, Durchsatz und Kosten sind offensichtlich – ebenso wichtig sind jedoch weniger sichtbare Faktoren wie Anbieterstabilität (gibt es die Plattform in fünf Jahren noch?), Supportqualität, Dokumentation und Community-Größe. Der Open-Source- vs. proprietär-Trade-off sollte gut abgewogen werden: Open-Source-Modelle bieten Unabhängigkeit von Anbieterentscheidungen und die Möglichkeit zum Eigenbetrieb, verlangen aber mehr Entwicklungsaufwand. Proprietäre Plattformen bieten Komfort, regelmäßige Updates und Support, führen aber zum Vendor-Lock-in – Ihr Geschäft hängt dann vom Fortbestand und den Preisen des Anbieters ab. Kosten-Nutzen-Analysen müssen die Gesamtkosten des Betriebs einbeziehen, nicht nur Preise pro API-Aufruf; ein günstigeres Modell, das mehr Entwicklungsaufwand oder schlechtere Ergebnisse bringt, kann teurer sein. Langfristige Nachhaltigkeit ist ein kritischer, oft übersehener Faktor: Ein Modell eines finanzstarken, stabilen Anbieters senkt das Risiko künftiger Außerdienststellungen; ein Modell eines Start-ups oder Forschungsprojekts birgt mehr Risiko für Plattformänderungen. Manche Firmen wählen bewusst mehrere Plattformen, um Abhängigkeiten zu reduzieren und akzeptieren dafür höhere Komplexität. Die Bewertung sollte dokumentiert und regelmäßig überprüft werden, da sich das Modell- und Plattformangebot laufend wandelt.
Erfolgreiche Organisationen in der sich schnell wandelnden KI-Landschaft leben kontinuierliches Lernen und Anpassung als Grundprinzip – Plattformänderungen sind keine seltenen Störungen, sondern Alltag. Beziehungen zu Plattformanbietern aufbauen – etwa durch Account-Management, User-Boards oder Austausch mit Produktteams – bringt frühe Einblicke in kommende Änderungen und manchmal Mitsprache bei Außerdienststellungsfristen. Teilnahme an Beta-Programmen für neue Modelle und Plattformen ermöglicht es, Alternativen zu testen, bevor sie allgemein verfügbar sind – ein klarer Vorteil bei der Migrationsplanung. Wer sich über Branchentrends informiert und Prognosen verfolgt, erkennt früh, welche Modelle und Plattformen dominieren werden und welche verschwinden könnten – so lassen sich strategische Investitionen gezielter tätigen. Interne Expertise für Modellauswahl, Deployment und Monitoring aufzubauen, senkt die Abhängigkeit von externen Beratern und Anbietern bei Plattformentscheidungen. Dazu gehört das Verständnis, wie Modellleistung bewertet, Drift und Bias erkannt, Systeme an Modelländerungen angepasst und fundierte technische Entscheidungen unter Unsicherheit getroffen werden. Unternehmen, die in diese Fähigkeiten investieren, erleben Plattformänderungen als handhabbare Herausforderungen und sind besser aufgestellt, von neuen Modellen und Technologien zu profitieren, sobald sie verfügbar werden.
Die meisten KI-Plattformen geben 12-24 Monate Vorlaufzeit, bevor ein Modell außer Dienst gestellt wird, auch wenn dieser Zeitraum variieren kann. Wichtig ist, sofort nach der Ankündigung mit der Planung zu beginnen, statt bis zur Frist zu warten. Frühe Planung gibt Ihnen Zeit, Alternativen gründlich zu testen und überstürzte Migrationen mit Fehlern oder Performance-Problemen zu vermeiden.
Plattform-Außerdienststellung bedeutet in der Regel, dass ein Modell oder eine API-Version keine Updates mehr erhält und schließlich entfernt wird. API-Abschaltung ist der endgültige Schritt, bei dem der Zugriff komplett beendet wird. Dieses Verständnis hilft Ihnen, Ihren Migrationszeitplan zu planen – meist haben Sie Monate Vorlaufzeit zwischen Außerdienststellung und tatsächlicher Abschaltung.
Ja, und viele Organisationen tun dies für kritische Anwendungen. Mehrere Modelle parallel zu betreiben oder ein Ersatzmodell als Fallback vorzuhalten, bietet Absicherung gegen Plattformänderungen. Dieser Ansatz erhöht jedoch Komplexität und Kosten und wird meist für unternehmenskritische Systeme genutzt, bei denen Zuverlässigkeit oberste Priorität hat.
Dokumentieren Sie zunächst alle KI-Modelle und Plattformen, die Ihr Unternehmen nutzt, inklusive der abhängigen Systeme. Überwachen Sie offizielle Plattform-Ankündigungen, abonnieren Sie Außerdienststellungs-Benachrichtigungen und nutzen Sie Überwachungstools für Plattformänderungen. Regelmäßige Audits Ihrer KI-Infrastruktur helfen, mögliche Auswirkungen frühzeitig zu erkennen.
Das Versäumnis, sich an Plattformänderungen anzupassen, kann zu Dienstunterbrechungen führen, wenn Plattformen den Zugang abschalten, zu Performance-Einbußen, wenn Sie gezwungen sind, suboptimale Alternativen zu nutzen, zu regulatorischen Verstößen, falls Ihr System nicht mehr konform ist, und zu Reputationsschäden durch Ausfälle. Proaktive Anpassung verhindert diese kostspieligen Szenarien.
Entwerfen Sie Ihre Systeme mit Abstraktionsschichten, die plattformspezifischen Code isolieren, pflegen Sie Beziehungen zu mehreren Plattformanbietern, evaluieren Sie Open-Source-Alternativen und dokumentieren Sie Ihre Architektur für leichtere Migrationen. Diese Praktiken verringern Ihre Abhängigkeit von einem einzelnen Anbieter und bieten Flexibilität bei Plattformänderungen.
Tools wie AmICited überwachen, wie KI-Plattformen Ihre Marke referenzieren, und verfolgen Plattform-Updates. Zusätzlich sollten Sie offizielle Plattform-Newsletter abonnieren, RSS-Feeds für Außerdienststellungs-Ankündigungen einrichten, an Entwickler-Communities teilnehmen und Beziehungen zu Plattform-Account-Managern pflegen, um frühzeitig auf Änderungen aufmerksam zu werden.
Überprüfen Sie Ihre KI-Plattformstrategie mindestens vierteljährlich oder immer dann, wenn Sie von wichtigen Plattformänderungen erfahren. Häufigere Überprüfungen (monatlich) sind sinnvoll, wenn Sie in einer sich schnell entwickelnden Branche tätig sind oder von mehreren Plattformen abhängen. Regelmäßige Überprüfungen sorgen dafür, dass Sie auf neue Risiken vorbereitet sind und Migrationen proaktiv planen können.
Überwachen Sie, wie KI-Plattformen Ihre Marke referenzieren, und verfolgen Sie wichtige Plattform-Updates, bevor sie Ihr Unternehmen beeinflussen. Erhalten Sie Echtzeit-Benachrichtigungen über Außerdienststellungen und Plattformänderungen.
Erfahren Sie, wie Sie KI-Plattformübergänge managen und die Zitier-Sichtbarkeit erhalten, wenn Plattformen eingestellt werden. Strategischer Leitfaden für den U...

Erfahren Sie, wie Sie Ihr Unternehmen auf unbekannte zukünftige KI-Plattformen vorbereiten können. Entdecken Sie das KI-Readiness-Framework, wesentliche Säulen ...

Meistern Sie agile Optimierungsstrategien, um sich schnell an Algorithmusänderungen von KI-Plattformen anzupassen. Erfahren Sie, wie Sie ChatGPT-, Perplexity- u...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.