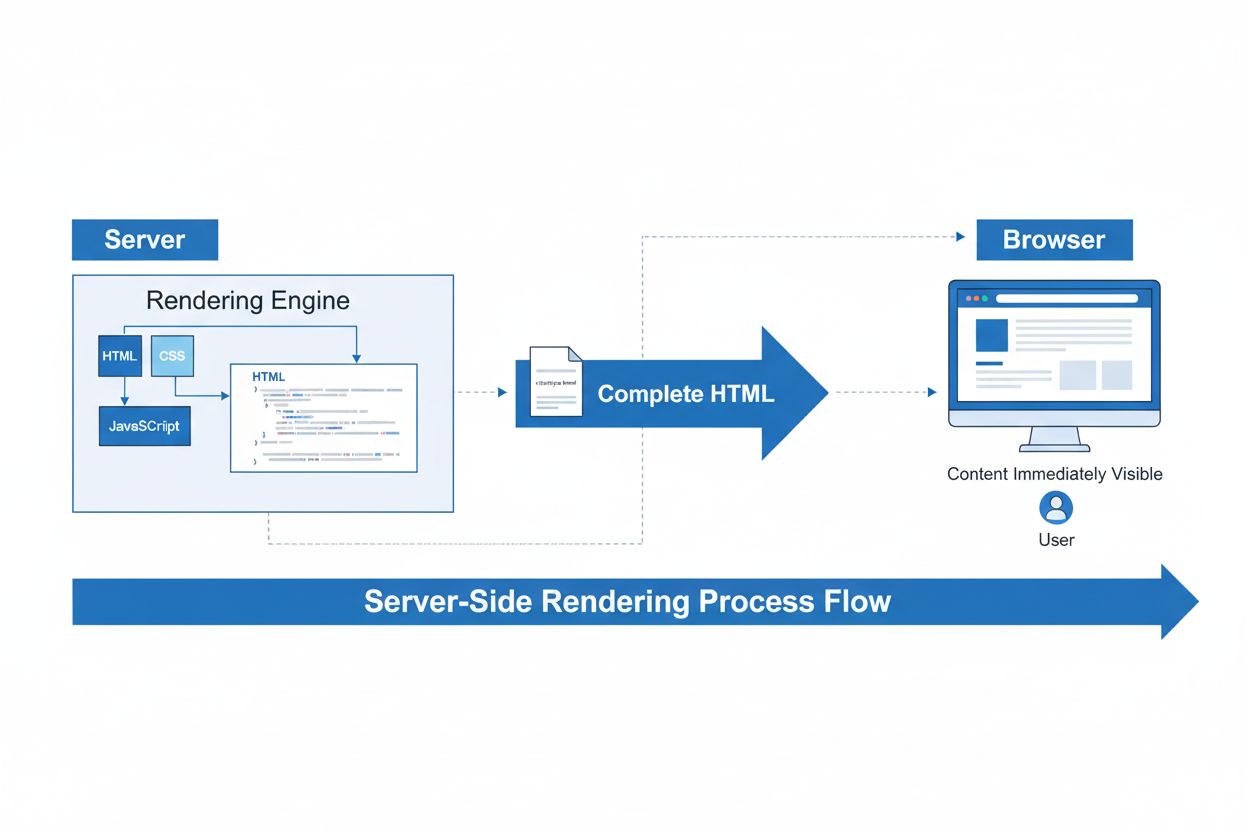
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) ist eine Webtechnik, bei der Server vollständige HTML-Seiten rendern, bevor sie an Browser gesendet werden. Erfahren Sie, wie SSR SE...
10 Min. Lesezeit

Erfahren Sie, wie server-seitiges Rendering eine effiziente KI-Verarbeitung, Modellbereitstellung und Echtzeit-Inferenz für KI-gestützte Anwendungen und LLM-Workloads ermöglicht.
Server-seitiges Rendering für KI ist ein architektonischer Ansatz, bei dem künstliche Intelligenz-Modelle und Inferenzverarbeitung auf dem Server und nicht auf Client-Geräten stattfinden. Dies ermöglicht eine effiziente Ausführung rechenintensiver KI-Aufgaben, sorgt für eine konsistente Leistung für alle Nutzer und vereinfacht die Bereitstellung und Aktualisierung von Modellen.
Server-seitiges Rendering für KI bezeichnet ein Architekturmodell, bei dem künstliche Intelligenz-Modelle, Inferenzprozesse und Rechenaufgaben auf Backend-Servern und nicht auf Client-Geräten wie Browsern oder Smartphones ausgeführt werden. Dieser Ansatz unterscheidet sich grundlegend vom traditionellen client-seitigen Rendering, bei dem JavaScript im Browser des Nutzers ausgeführt wird, um Inhalte zu generieren. In KI-Anwendungen bedeutet server-seitiges Rendering, dass große Sprachmodelle (LLMs), maschinelles Lernen und KI-gestützte Inhaltserstellung zentral auf leistungsfähiger Server-Infrastruktur stattfinden, bevor die Ergebnisse an die Nutzer gesendet werden. Dieser architektonische Wandel ist zunehmend wichtig geworden, da KI-Fähigkeiten immer rechenintensiver und zentraler für moderne Webanwendungen werden.
Das Konzept entstand aus der Erkenntnis eines entscheidenden Missverhältnisses zwischen den Anforderungen moderner KI-Anwendungen und dem, was Client-Geräte realistischerweise leisten können. Traditionelle Webentwicklung-Frameworks wie React, Angular und Vue.js machten client-seitiges Rendering in den 2010er Jahren populär, doch dieser Ansatz bringt erhebliche Herausforderungen mit sich, wenn er auf KI-intensive Workloads angewendet wird. Server-seitiges Rendering für KI begegnet diesen Herausforderungen durch den Einsatz spezialisierter Hardware, zentralisiertes Modellmanagement und optimierte Infrastruktur, die Client-Geräte nicht bieten können. Dies stellt einen grundlegenden Paradigmenwechsel in der Architektur KI-gestützter Anwendungen dar.
Die Rechenanforderungen moderner KI-Systeme machen server-seitiges Rendering nicht nur vorteilhaft, sondern oft notwendig. Client-Geräte, insbesondere Smartphones und günstige Laptops, verfügen nicht über die nötige Leistung, um Echtzeit-KI-Inferenz effizient zu bewältigen. Werden KI-Modelle auf Client-Geräten ausgeführt, kommt es für Nutzer zu spürbaren Verzögerungen, erhöhtem Akkuverbrauch und uneinheitlicher Leistung je nach Hardware. Server-seitiges Rendering beseitigt diese Probleme, indem die KI-Verarbeitung auf eine Infrastruktur mit GPUs, TPUs und spezialisierten KI-Beschleunigern zentralisiert wird, die eine um ein Vielfaches bessere Performance als Endgeräte liefert.
Über die reine Performance hinaus bietet server-seitiges Rendering für KI entscheidende Vorteile bei Modellmanagement, Sicherheit und Konsistenz. Werden KI-Modelle auf Servern ausgeführt, können Entwickler neue Versionen unmittelbar aktualisieren, feinjustieren und bereitstellen, ohne dass Nutzer Updates herunterladen oder verschiedene Modellversionen lokal verwalten müssen. Dies ist besonders wichtig für große Sprachmodelle und maschinelle Lernsysteme, die sich mit häufigen Verbesserungen und Sicherheitspatches schnell weiterentwickeln. Darüber hinaus schützt die zentrale Verwaltung der KI-Modelle auf Servern vor unbefugtem Zugriff, Modellextraktion und Diebstahl geistigen Eigentums, wie er bei verteilten Modellen auf Client-Geräten möglich wäre.
| Aspekt | Client-seitige KI | Server-seitige KI |
|---|---|---|
| Verarbeitungsort | Browser oder Gerät des Nutzers | Backend-Server |
| Hardware-Anforderungen | Begrenzte Geräteleistung | Spezialisierte GPUs, TPUs, KI-Beschleuniger |
| Leistung | Variabel, geräteabhängig | Konsistent, optimiert |
| Modell-Updates | Nutzer muss herunterladen | Sofortige Bereitstellung |
| Sicherheit | Modelle können extrahiert werden | Modelle auf Servern geschützt |
| Latenz | Abhängig von Geräteleistung | Optimierte Infrastruktur |
| Skalierbarkeit | Pro Gerät begrenzt | Hoch skalierbar über Nutzer hinweg |
| Entwicklungskomplexität | Hoch (Gerätefragmentierung) | Geringer (zentrale Verwaltung) |
Netzwerk-Overhead und Latenz stellen große Herausforderungen in KI-Anwendungen dar. Moderne KI-Systeme erfordern ständige Kommunikation mit Servern für Modellupdates, Abruf von Trainingsdaten und hybride Verarbeitungsszenarien. Ironischerweise erhöhen client-seitige Renderings die Anzahl der Netzwerk-Anfragen im Vergleich zu traditionellen Anwendungen und mindern so die Performance-Vorteile client-seitiger Verarbeitung. Server-seitiges Rendering bündelt diese Kommunikation, reduziert Verzögerungen und ermöglicht Echtzeit-KI-Funktionen wie Live-Übersetzung, Inhaltserstellung und Bildverarbeitung ohne die Latenznachteile der client-seitigen Inferenz.
Synchronisationskomplexität entsteht, wenn KI-Anwendungen gleichzeitig den Status über mehrere KI-Dienste konsistent halten müssen. Moderne Anwendungen nutzen oft Embedding-Dienste, Completion-Modelle, feinjustierte Modelle und spezialisierte Inferenz-Engines, die miteinander koordiniert werden müssen. Die Verwaltung dieses verteilten Zustands auf Client-Geräten erhöht die Komplexität erheblich und birgt das Risiko von Dateninkonsistenzen, insbesondere bei Echtzeit-Kollaboration in KI-Funktionen. Server-seitiges Rendering zentralisiert das Zustandsmanagement, stellt konsistente Ergebnisse für alle Nutzer sicher und eliminiert den Entwicklungsaufwand für komplexe client-seitige Synchronisation.
Gerätefragmentierung stellt bei client-seitiger KI erhebliche Entwicklungsherausforderungen dar. Verschiedene Geräte verfügen über unterschiedliche KI-Fähigkeiten, darunter Neural Processing Units, GPU-Beschleunigung, WebGL-Unterstützung und unterschiedliche Speichergrenzen. Konsistente KI-Erlebnisse über diese fragmentierte Landschaft hinweg zu bieten, erfordert enormen Aufwand, Strategien zur Anpassung an verschiedene Leistungsniveaus und mehrere Codepfade für unterschiedliche Geräteeigenschaften. Server-seitiges Rendering beseitigt diese Fragmentierung vollständig, da alle Nutzer auf die gleiche optimierte KI-Infrastruktur zugreifen – unabhängig von ihren Geräten.
Server-seitiges Rendering ermöglicht einfachere und besser wartbare KI-Anwendungsarchitekturen durch die Zentralisierung kritischer Funktionen. Statt KI-Modelle und Inferenzlogik auf Tausende von Client-Geräten zu verteilen, pflegen Entwickler eine einzige, optimierte Implementierung auf Servern. Diese Zentralisierung bietet sofortige Vorteile wie schnellere Deployment-Zyklen, einfacheres Debugging und unkomplizierte Performance-Optimierung. Muss ein KI-Modell verbessert oder ein Fehler behoben werden, geschieht dies nur einmal auf dem Server, statt Updates an Millionen von Nutzern mit unterschiedlichen Adoptionsraten zu verteilen.
Ressourceneffizienz verbessert sich durch server-seitiges Rendering erheblich. Server-Infrastruktur ermöglicht effiziente Ressourcennutzung über alle Nutzer hinweg, mit Connection-Pooling, Caching-Strategien und Lastverteilung zur Optimierung der Hardware-Auslastung. Eine einzelne GPU auf einem Server kann Inferenzanfragen von Tausenden Nutzern nacheinander bearbeiten – auf Client-Geräten wären dafür Millionen GPUs nötig. Diese Effizienz führt zu niedrigeren Betriebskosten, geringerer Umweltbelastung und besserer Skalierbarkeit beim Wachstum der Anwendungen.
Sicherheit und Schutz geistigen Eigentums werden durch server-seitiges Rendering wesentlich einfacher. KI-Modelle stellen erhebliche Investitionen in Forschung, Trainingsdaten und Rechenressourcen dar. Die Speicherung der Modelle auf Servern verhindert Modellextraktionsangriffe, unbefugten Zugriff und Diebstahl geistigen Eigentums, wie sie bei verteilten Client-Modellen möglich wären. Zusätzlich ermöglicht server-seitige Verarbeitung feingranulare Zugriffskontrolle, Audit-Logging und Compliance-Monitoring, die auf verteilten Geräten nicht durchsetzbar wären.
Moderne Frameworks haben sich weiterentwickelt, um server-seitiges Rendering für KI-Workloads effektiv zu unterstützen. Next.js führt diese Entwicklung mit Server Actions an, die nahtlose KI-Verarbeitung direkt aus Server-Komponenten ermöglichen. Entwickler können KI-APIs aufrufen, große Sprachmodelle verarbeiten und Antworten mit minimalem Boilerplate-Code an Clients streamen. Das Framework übernimmt die Komplexität der Server-Client-Kommunikation, sodass Entwickler sich auf KI-Logik statt auf Infrastruktur konzentrieren können.
SvelteKit bietet einen performance-orientierten Ansatz für server-seitiges KI-Rendering mit Load-Funktionen, die auf dem Server vor dem Rendering ausgeführt werden. Dies ermöglicht Vorverarbeitung von KI-Daten, Generierung von Empfehlungen und Vorbereitung KI-optimierter Inhalte, bevor das HTML an die Clients gesendet wird. Die resultierenden Anwendungen haben minimale JavaScript-Anteile bei voller KI-Funktionalität und bieten außergewöhnlich schnelle Nutzererlebnisse.
Spezialisierte Tools wie das Vercel AI SDK abstrahieren die Komplexität des Streamings von KI-Antworten, Token-Zählung und die Anbindung verschiedener KI-Anbieter. Diese Werkzeuge ermöglichen es Entwicklern, fortschrittliche KI-Anwendungen ohne tiefgehende Infrastrukturkenntnisse zu erstellen. Infrastruktur-Optionen wie Vercel Edge Functions, Cloudflare Workers und AWS Lambda bieten global verteilte server-seitige KI-Verarbeitung, reduzieren die Latenz durch Verarbeitung nah am Nutzer und erhalten dennoch zentrales Modellmanagement.
Effektives server-seitiges KI-Rendering erfordert ausgefeilte Caching-Strategien zur Steuerung der Rechenkosten und Latenz. Redis-Caching speichert häufig abgefragte KI-Antworten und Nutzersitzungen, wodurch doppelte Berechnungen für ähnliche Anfragen entfallen. CDN-Caching verteilt statische, KI-generierte Inhalte weltweit und stellt sicher, dass Nutzer Antworten von geografisch nahen Servern erhalten. Edge-Caching-Strategien verteilen KI-verarbeitete Inhalte über Edge-Netzwerke und bieten extrem niedrige Latenzzeiten bei zentralisiertem Modellmanagement.
Diese Caching-Ansätze greifen ineinander und schaffen effiziente KI-Systeme, die auf Millionen Nutzer skalieren, ohne dass die Rechenkosten proportional steigen. Durch Caching von KI-Antworten auf mehreren Ebenen können Anwendungen den Großteil aller Anfragen aus dem Cache bedienen und müssen neue Antworten nur bei wirklich neuen Anfragen errechnen. Das senkt die Infrastrukturkosten erheblich und verbessert die Nutzererfahrung durch kürzere Reaktionszeiten.
Die Entwicklung hin zum server-seitigen Rendering stellt eine Reifung der Webentwicklung als Reaktion auf KI-Anforderungen dar. Da KI zum Kernbestandteil von Webanwendungen wird, verlangen die rechnerischen Realitäten server-zentrierte Architekturen. Die Zukunft liegt in ausgefeilten hybriden Ansätzen, die je nach Inhaltstyp, Gerätefähigkeit, Netzwerkbedingungen und KI-Anforderungen automatisch entscheiden, wo gerendert wird. Frameworks werden Anwendungen schrittweise mit KI-Fähigkeiten anreichern und sicherstellen, dass Kernfunktionen universell funktionieren und Erlebnisse dort verbessert werden, wo es möglich ist.
Dieser Paradigmenwechsel integriert die Lehren der Single-Page-Application-Ära und adressiert die Herausforderungen KI-nativer Anwendungen. Die Tools und Frameworks sind bereit, damit Entwickler die Vorteile server-seitigen Renderings im KI-Zeitalter nutzen können – und die nächste Generation intelligenter, reaktiver und effizienter Webanwendungen ermöglichen.
Verfolgen Sie, wie Ihre Domain und Marke in KI-generierten Antworten bei ChatGPT, Perplexity und anderen KI-Suchmaschinen erscheinen. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Sichtbarkeit.
Server-Side Rendering (SSR) ist eine Webtechnik, bei der Server vollständige HTML-Seiten rendern, bevor sie an Browser gesendet werden. Erfahren Sie, wie SSR SE...
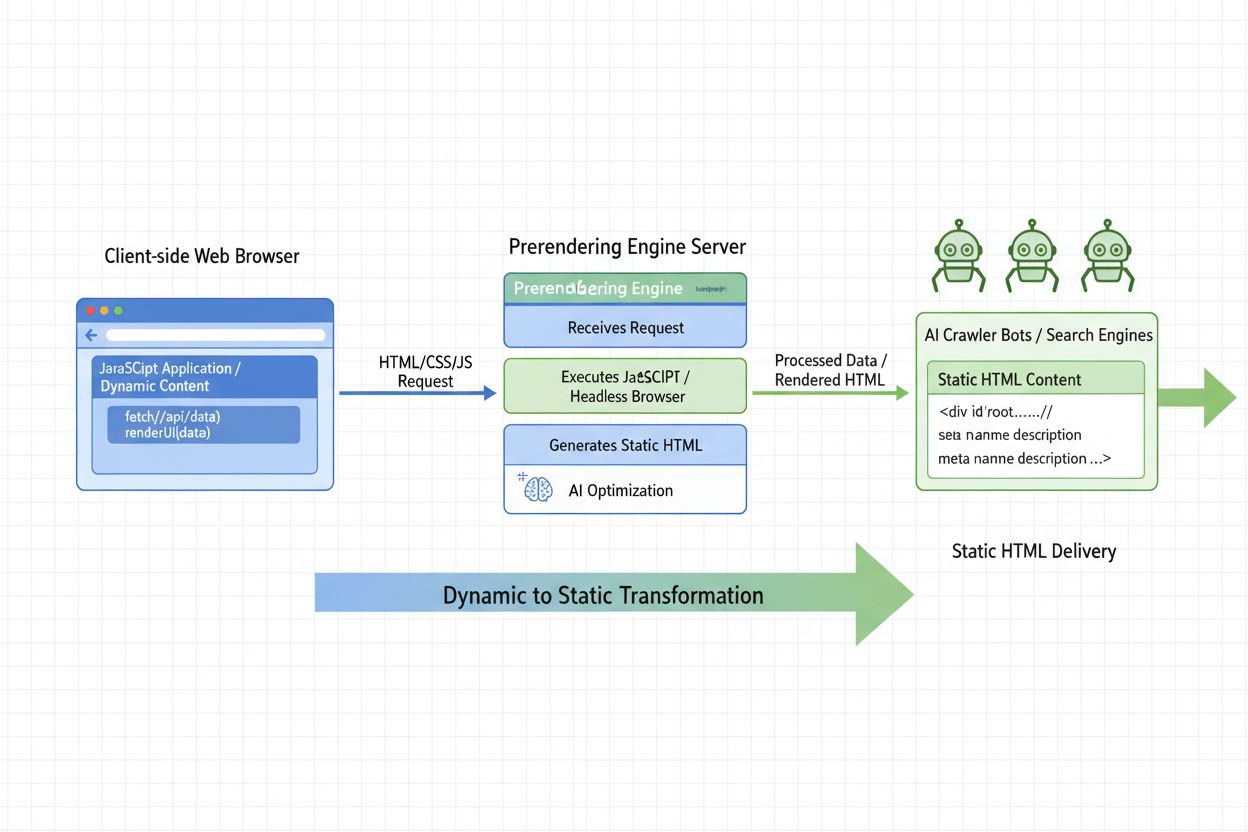
Erfahren Sie, was AI-Prerendering ist und wie serverseitige Rendering-Strategien Ihre Website für die Sichtbarkeit bei KI-Crawlern optimieren. Entdecken Sie Imp...

Erfahren Sie, wie dynamisches Rendering die Sichtbarkeit von KI-Crawlern, ChatGPT, Perplexity und Claude beeinflusst. Entdecken Sie, warum KI-Systeme kein JavaS...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.