
PerplexityBot: Was jeder Website-Betreiber wissen muss
Vollständiger Leitfaden zum PerplexityBot-Crawler – erfahren Sie, wie er funktioniert, wie Sie den Zugriff steuern, Zitate überwachen und die Sichtbarkeit bei P...
8 Min. Lesezeit

Amazons Webcrawler, der zur Verbesserung von Produkten und Services wie Alexa, dem Rufus Shopping-Assistenten und Amazons KI-gestützten Suchfunktionen eingesetzt wird. Er beachtet das Robots Exclusion Protocol und kann über robots.txt-Anweisungen gesteuert werden. Kann für das Training von KI-Modellen verwendet werden.
Amazons Webcrawler, der zur Verbesserung von Produkten und Services wie Alexa, dem Rufus Shopping-Assistenten und Amazons KI-gestützten Suchfunktionen eingesetzt wird. Er beachtet das Robots Exclusion Protocol und kann über robots.txt-Anweisungen gesteuert werden. Kann für das Training von KI-Modellen verwendet werden.
Amazonbot ist Amazons offizieller Webcrawler, der entwickelt wurde, um die Produkte und Dienste des Unternehmens durch das Sammeln und Analysieren von Webinhalten zu verbessern. Dieser hochentwickelte Crawler treibt zentrale Amazon-Funktionen an, darunter den Sprachassistenten Alexa, den KI-Shopping-Assistenten Rufus und Amazons KI-gestützte Sucherlebnisse. Amazonbot arbeitet mit dem User-Agent-String Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, der ihn gegenüber Webservern identifiziert. Die von Amazonbot gesammelten Daten können zum Training von Amazons KI-Modellen genutzt werden, was ihn zu einem wichtigen Bestandteil von Amazons übergreifender KI-Infrastruktur und Produktentwicklungsstrategie macht.
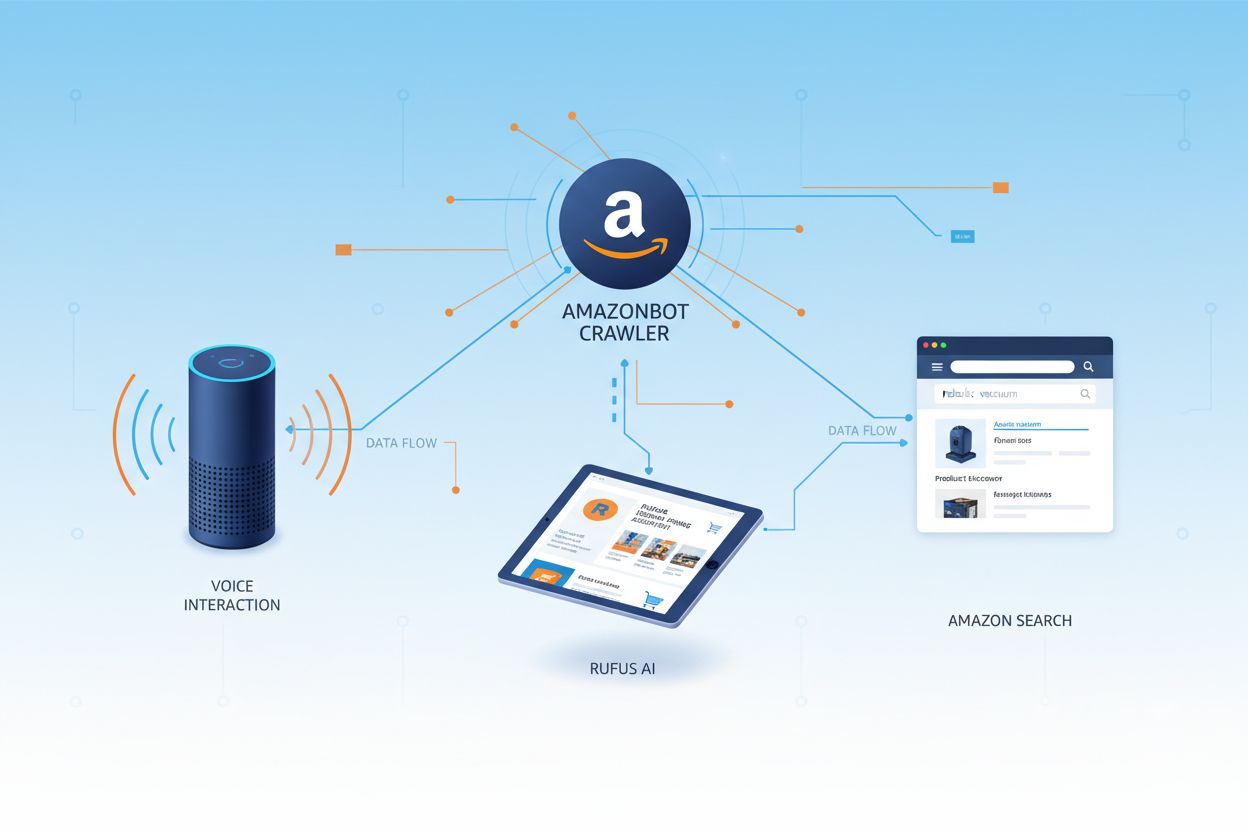
Amazon betreibt drei verschiedene Webcrawler, die jeweils bestimmte Aufgaben im Ökosystem erfüllen. Amazonbot ist der primäre Crawler für die allgemeine Verbesserung von Produkten und Services und kann für das Training von KI-Modellen eingesetzt werden. Amzn-SearchBot ist speziell dafür vorgesehen, Sucherlebnisse in Amazon-Produkten wie Alexa und Rufus zu verbessern, crawlt aber ausdrücklich NICHT für generatives KI-Training. Amzn-User unterstützt von Nutzern initiierte Aktionen, etwa das Abrufen aktueller Informationen, wenn Alexa-Anfragen aktuelle Webdaten erfordern, und crawlt ebenfalls nicht für KI-Training. Alle drei Crawler halten sich an das Robots Exclusion Protocol und beachten robots.txt-Anweisungen, sodass Website-Betreiber den Zugang steuern können. Amazon veröffentlicht die IP-Adressen jedes Crawlers auf seinem Entwicklerportal, sodass Website-Betreiber legitimen Traffic verifizieren können. Zudem respektieren alle Amazon-Crawler Link-Ebene rel=nofollow-Anweisungen und robots-Meta-Tags auf Seitenebene wie noarchive (verhindert Nutzung fürs Modelltraining), noindex (verhindert Indizierung) und none (verhindert beides).
| Crawler-Name | Hauptzweck | KI-Modelltraining | User-Agent | Zentrale Anwendungsfälle |
|---|---|---|---|---|
| Amazonbot | Allgemeine Produkt-/Serviceverbesserung | Ja | Amazonbot/0.1 | Allgemeine Amazon-Optimierung, KI-Training |
| Amzn-SearchBot | Verbesserung der Sucherfahrung | Nein | Amzn-SearchBot/0.1 | Alexa-Suche, Rufus-Shopping-Assistent-Indexierung |
| Amzn-User | Nutzerinitiierte Live-Datenabfrage | Nein | Amzn-User/0.1 | Echtzeit-Alexa-Anfragen, aktuelle Info-Anforderungen |
Amazon hält sich an das branchenübliche Robots Exclusion Protocol (RFC 9309), sodass Website-Betreiber den Zugriff von Amazonbot über ihre robots.txt steuern können. Amazon ruft robots.txt-Dateien auf Hostebene aus dem Stammverzeichnis Ihrer Domain ab (z. B. example.com/robots.txt) und verwendet eine zwischengespeicherte Version der letzten 30 Tage, wenn die Datei nicht abgerufen werden kann. Änderungen an Ihrer robots.txt werden in der Regel innerhalb von etwa 24 Stunden in Amazons Systemen übernommen. Das Protokoll unterstützt die üblichen user-agent- und allow/disallow-Anweisungen, womit eine feingranulare Steuerung möglich ist, welche Crawler auf welche Verzeichnisse oder Dateien zugreifen dürfen. Es ist jedoch wichtig zu beachten, dass Amazon-Crawler die crawl-delay-Anweisung NICHT unterstützen – dieser Parameter wird in robots.txt ignoriert.
So können Sie den Zugriff von Amazonbot steuern:
# Amazonbot vom Crawlen der gesamten Website ausschließen
User-agent: Amazonbot
Disallow: /
# Amzn-SearchBot für Sichtbarkeit in der Suche erlauben
User-agent: Amzn-SearchBot
Allow: /
# Ein bestimmtes Verzeichnis für Amazonbot sperren
User-agent: Amazonbot
Disallow: /private/
# Allen anderen Crawlern den Zugriff auf /admin/ verweigern
User-agent: *
Disallow: /admin/
Website-Betreiber, die sich Sorgen über Bot-Traffic machen, sollten überprüfen, ob Crawler, die sich als Amazonbot ausgeben, tatsächlich legitime Amazon-Crawler sind. Amazon stellt dazu einen Verifizierungsprozess mittels DNS-Lookups bereit. Um die Legitimität eines Crawlers zu prüfen, ermitteln Sie zunächst die zugreifende IP-Adresse aus Ihren Serverlogs und führen einen Reverse-DNS-Lookup mit dem host-Befehl durch. Der zurückgegebene Domainname sollte eine Subdomain von crawl.amazonbot.amazon sein. Führen Sie anschließend einen Forward-DNS-Lookup auf den ermittelten Domainnamen aus, um zu prüfen, ob dieser wieder auf die ursprüngliche IP-Adresse zeigt. Dieser bidirektionale Prüfvorgang hilft, Spoofing-Angriffe zu vermeiden, da böswillige Akteure andernfalls Reverse-DNS-Einträge fälschen könnten, um sich als Amazonbot auszugeben. Amazon veröffentlicht verifizierte IP-Adressen aller Crawler auf dem Entwicklerportal unter developer.amazon.com/amazonbot/ip-addresses/ als zusätzliche Referenz.
Beispiel für den Verifizierungsprozess:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Wenn Sie Fragen zu Amazonbot haben oder verdächtige Aktivitäten melden möchten, kontaktieren Sie Amazon direkt unter amazonbot@amazon.com und geben Sie relevante Domainnamen mit an.
Bei Amazons Crawlern besteht ein entscheidender Unterschied hinsichtlich des Trainings von KI-Modellen. Amazonbot kann zum Training von Amazons künstlichen Intelligenz-Modellen verwendet werden, was für Inhaltsanbieter relevant ist, die verhindern möchten, dass ihre Werke zum KI-Training genutzt werden. Im Gegensatz dazu crawlen Amzn-SearchBot und Amzn-User ausdrücklich NICHT für generatives KI-Modelltraining, sondern dienen ausschließlich der Verbesserung von Sucherlebnissen und der Unterstützung von Nutzeranfragen. Wenn Sie verhindern möchten, dass Ihre Inhalte zum Training von KI-Modellen verwendet werden, können Sie das robots-Meta-Tag noarchive im HTML-Header Ihrer Seite verwenden, welches Amazonbot anweist, die Seite nicht für Modelltraining zu nutzen. Diese Unterscheidung ist wichtig für Publisher, Kreative und Website-Betreiber, die kontrollieren möchten, wie ihre Inhalte in Amazons KI-Trainingspipeline verwendet werden, während sie gleichzeitig die Sichtbarkeit in der Amazon-Suche und in den Rufus-Empfehlungen beibehalten.
Rufus ist Amazons fortschrittlicher KI-Shopping-Assistent, der Webcrawling und KI nutzt, um personalisierte Einkaufsempfehlungen und Unterstützung zu bieten. Während Amazonbot zur allgemeinen KI-Infrastruktur von Amazon beiträgt, verwendet Rufus speziell den Amzn-SearchBot für die Indexierung von Produktinformationen und webrelevanten Inhalten für Shopping-Anfragen. Rufus basiert auf Amazon Bedrock und nutzt fortschrittliche Large-Language-Modelle, darunter Claude Sonnet von Anthropic und Amazon Nova, kombiniert mit einem eigenen Modell, das auf Amazons umfangreichem Produktkatalog, Kundenbewertungen, Community-Fragen und Webinformationen trainiert wurde. Der Shopping-Assistent hilft Kunden dabei, Produkte zu recherchieren, Optionen zu vergleichen, Preise zu verfolgen, Angebote zu finden und sogar automatisch zu kaufen, wenn Zielpreise erreicht werden. Seit seiner Einführung ist Rufus äußerst beliebt: Über 250 Millionen Kunden nutzen ihn, die Zahl der monatlich aktiven Nutzer ist um 149 % gestiegen und die Interaktionen sind im Jahresvergleich um 210 % gewachsen. Kunden, die Rufus beim Einkaufen nutzen, tätigen zu über 60 % häufiger einen Kauf während dieser Session, was die große Bedeutung von KI-gestützter Einkaufsunterstützung für das Konsumentenverhalten zeigt.
Website-Betreiber sollten eine strategische Herangehensweise im Umgang mit Amazons Crawlern wählen, basierend auf ihren individuellen Geschäfts- und Inhaltszielen:
noarchive oder blockieren Sie ihn vollständig über robots.txtamazonbot@amazon.com für individuelle BeratungAmazonbot ist Amazons universeller Crawler zur Verbesserung von Produkten und Services und kann für das Training von KI-Modellen genutzt werden. Amzn-SearchBot ist speziell für Sucherlebnisse in Alexa und Rufus konzipiert und crawlt NICHT für das Training von KI-Modellen. Wenn Sie die Nutzung für KI-Training verhindern möchten, blockieren Sie Amazonbot, erlauben Sie aber Amzn-SearchBot für die Such-Sichtbarkeit.
Fügen Sie folgende Zeilen in Ihre robots.txt im Stammverzeichnis Ihrer Domain ein: User-agent: Amazonbot gefolgt von Disallow: /. Dies verhindert, dass Amazonbot Ihre gesamte Seite crawlt. Sie können auch Disallow: /spezifischer-pfad/ verwenden, um nur bestimmte Verzeichnisse zu blockieren.
Ja, Amazonbot kann zum Training von Amazons künstlichen Intelligenz-Modellen genutzt werden. Wenn Sie das verhindern möchten, verwenden Sie das robots-Meta-Tag im HTML-Header Ihrer Seite. Dies weist Amazonbot an, die Seite nicht für das Modelltraining zu verwenden.
Führen Sie einen Reverse-DNS-Lookup auf die IP-Adresse des Crawlers durch und vergewissern Sie sich, dass die Domain eine Subdomain von crawl.amazonbot.amazon ist. Danach führen Sie einen Forward-DNS-Lookup durch, um zu bestätigen, dass die Domain wieder auf die ursprüngliche IP zeigt. Sie können außerdem die von Amazon veröffentlichten IP-Adressen unter developer.amazon.com/amazonbot/ip-addresses/ prüfen.
Verwenden Sie die Standard-Syntax für robots.txt: User-agent: Amazonbot, um den Crawler anzusprechen, gefolgt von Disallow: /, um den Zugriff komplett zu sperren, oder Disallow: /pfad/, um bestimmte Verzeichnisse zu blockieren. Sie können außerdem Allow: / verwenden, um den Zugriff explizit zu erlauben.
Amazon übernimmt Änderungen an robots.txt in der Regel innerhalb von etwa 24 Stunden. Amazon ruft Ihre robots.txt regelmäßig ab und behält eine zwischengespeicherte Kopie für bis zu 30 Tage, daher kann es einen Tag dauern, bis Änderungen im System sichtbar sind.
Ja, absolut. Sie können in Ihrer robots.txt getrennte Regeln für jeden Crawler erstellen. Zum Beispiel: Erlauben Sie Amzn-SearchBot mit User-agent: Amzn-SearchBot und Allow: /, während Sie Amazonbot mit User-agent: Amazonbot und Disallow: / blockieren.
Kontaktieren Sie Amazon direkt unter amazonbot@amazon.com. Geben Sie immer Ihren Domainnamen und relevante Details zu Ihrem Anliegen an. Das Support-Team von Amazon kann Ihnen individuelle Unterstützung für Ihre Situation bieten.
Verfolgen Sie Erwähnungen Ihrer Marke in KI-Systemen wie Alexa, Rufus und Google AI Overviews mit AmICited – der führenden Plattform zur Überwachung von KI-Antworten.
Vollständiger Leitfaden zum PerplexityBot-Crawler – erfahren Sie, wie er funktioniert, wie Sie den Zugriff steuern, Zitate überwachen und die Sichtbarkeit bei P...

Erfahren Sie mehr über PerplexityBot, den Web-Crawler von Perplexity, der Inhalte für die KI-Antwortmaschine indexiert. Verstehen Sie, wie er funktioniert, robo...

Entdecken Sie die entscheidenden Unterschiede zwischen KI-Trainingscrawlern und Suchcrawlern. Erfahren Sie, wie sie die Sichtbarkeit Ihrer Inhalte, Optimierungs...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.