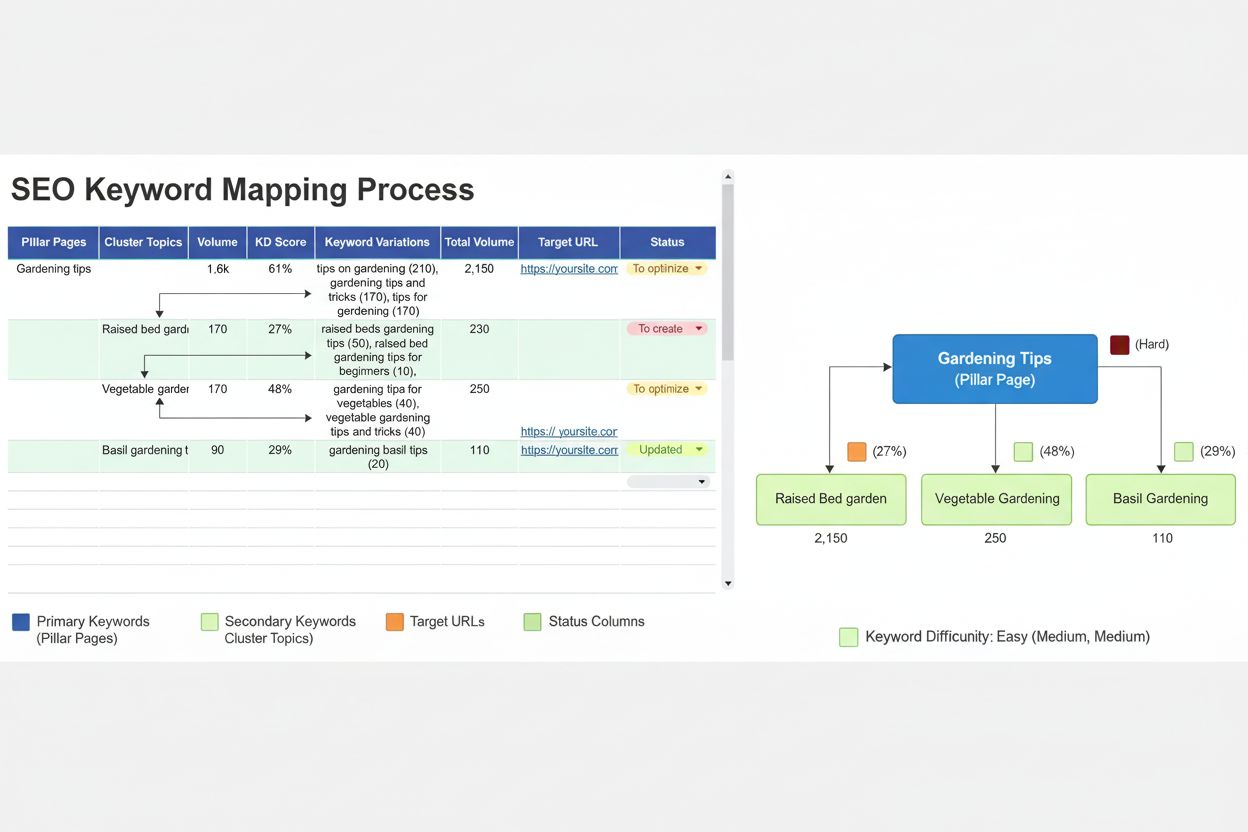
Keyword-Mapping
Erfahren Sie mehr über Keyword-Mapping: den Prozess der Zuweisung von Ziel-Keywords zu Webseiten. Lernen Sie, wie Sie Kannibalisierung verhindern, die Seitenstr...
12 Min. Lesezeit
Ko-Vorkommen bezieht sich auf das häufige gemeinsame Auftreten von zwei oder mehr Begriffen oder Konzepten innerhalb desselben Inhaltskontexts, etwa in einem Dokument, einer Webseite oder über mehrere Quellen hinweg. Diese semantische Beziehung hilft Suchmaschinen und KI-Systemen, den Kontext sowie die thematische Tiefe zu verstehen und verbessert dadurch die Sichtbarkeit und das Rankingpotenzial von Inhalten.
Ko-Vorkommen bezieht sich auf das häufige gemeinsame Auftreten von zwei oder mehr Begriffen oder Konzepten innerhalb desselben Inhaltskontexts, etwa in einem Dokument, einer Webseite oder über mehrere Quellen hinweg. Diese semantische Beziehung hilft Suchmaschinen und KI-Systemen, den Kontext sowie die thematische Tiefe zu verstehen und verbessert dadurch die Sichtbarkeit und das Rankingpotenzial von Inhalten.
Ko-Vorkommen beschreibt das Phänomen, dass zwei oder mehr Begriffe, Konzepte oder Entitäten häufig gemeinsam im selben Inhaltskontext auftreten – sei es in einem einzelnen Dokument, auf einer Webseite oder über mehrere Quellen im Web hinweg. Im Kontext von Natural Language Processing (NLP) und Suchmaschinenoptimierung (SEO) bezeichnet Ko-Vorkommen speziell die statistische Häufigkeit, mit der verwandte Begriffe gemeinsam gruppiert werden und dadurch Suchalgorithmen und KI-Systemen semantische Relevanz und Kontexttiefe signalisieren. Statt auf exakte Keyword-Übereinstimmungen angewiesen zu sein, helfen Ko-Vorkommensmuster modernen Suchmaschinen und KI-Assistenten, die tatsächliche Bedeutung und den Umfang von Inhalten zu verstehen, indem analysiert wird, welche Wörter auf natürliche Weise miteinander assoziiert werden. Dieses Konzept ist immer wichtiger geworden, da sich Suchmaschinen von einfacher Keyword-Erkennung hin zu ausgefeiltem semantischen Verständnis entwickelt haben und KI-Sichtbarkeit neben klassischem SEO zu einem entscheidenden Bestandteil der Digitalstrategie geworden ist.
Das Konzept des Ko-Vorkommens hat seinen Ursprung in der linguistischen und statistischen Analyse der vergangenen Jahrzehnte, seine Anwendung im digitalen Marketing und SEO ist jedoch relativ neu. Frühe Suchmaschinen setzten vor allem auf exakte Keyword-Übereinstimmungen und Keyword-Dichte, wobei jeder Begriff isoliert betrachtet wurde. Mit der Weiterentwicklung des Google-Algorithmus – insbesondere durch Updates wie Hummingbird (2013) und RankBrain (2015) – rückte jedoch das semantische Verständnis und die Kontextrelevanz in den Vordergrund, während einfache Keyword-Wiederholung an Bedeutung verlor. Dieser Wandel spiegelt einen grundlegenden Wechsel darin wider, wie Algorithmen Inhalte interpretieren: Statt nur Keywords zu zählen, analysieren sie heute die Beziehungen zwischen Begriffen und Konzepten. Forschungen aus Googles eigenen Veröffentlichungen zur semantischen Suche belegen, dass das Verständnis von Ko-Vorkommensstatistiken es Algorithmen ermöglicht, Bedeutungen besser zu unterscheiden und die Nutzerintention genauer zu treffen. Laut Branchendaten nutzen inzwischen etwa 78 % der Unternehmen KI-basierte Tools zur Inhaltsanalyse, die Ko-Vorkommensmetriken zur Optimierung ihrer Content-Strategie einbeziehen. Der Aufstieg von generativen KI-Systemen wie ChatGPT, Perplexity und Google AI Overviews hat die Bedeutung des Ko-Vorkommens weiter verstärkt, da diese Systeme stark auf erlernte statistische Muster aus Trainingsdaten angewiesen sind, um relevante Quellen und Marken in ihren Antworten zu nennen.
Im Kern basiert die Ko-Vorkommensanalyse auf der statistischen Messung von Wortfrequenzmustern innerhalb definierter Kontextfenster. Eine Ko-Vorkommensmatrix ist eine mathematische Darstellung – typischerweise ein N×N-Raster, wobei N für die Anzahl der einzigartigen Wörter in einem Korpus steht –, in der erfasst wird, wie oft Wortpaare gemeinsam auftreten. Jede Zelle der Matrix enthält eine Zählung, wie häufig zwei Wörter innerhalb einer bestimmten Nähe (dem sogenannten „Kontextfenster“, meist zwischen 2 und 10 Wörtern) gemeinsam erscheinen. In einem Artikel über „Elektrofahrzeuge“ würden beispielsweise die Wörter „Batterie“, „Laden“, „Reichweite“ und „Emissionen“ hohe Ko-Vorkommenswerte aufweisen, da sie oft in der Nähe des Hauptbegriffs auftreten. Diese statistische Grundlage ermöglicht zahlreiche Weiterentwicklungen: Wort-Embeddings wie GloVe (Global Vectors for Word Representation) verwenden Ko-Vorkommensmatrizen, um dichte Vektorrepräsentationen von Wörtern zu erstellen – semantisch ähnliche Begriffe erhalten ähnliche Vektoren. NLP-Systeme nutzen diese Muster für Aufgaben wie Themenmodellierung, Sentiment-Analyse und Messung semantischer Ähnlichkeiten. Die mathematische Eleganz der Ko-Vorkommensanalyse liegt darin, implizite semantische Beziehungen zu erfassen, ohne dass explizite menschliche Annotationen erforderlich wären – der Algorithmus beobachtet einfach, welche Begriffe gemeinsam auftreten, und leitet ihre Verwandtschaft aus den Häufigkeitsmustern ab.
| Konzept | Definition | Fokus | Anwendung | Ranking-Einfluss |
|---|---|---|---|---|
| Ko-Vorkommen | Verwandte Begriffe, die häufig gemeinsam in Inhalten erscheinen | Semantische Beziehungen und Kontexttiefe | Inhaltsoptimierung, Themenclustering | Mittel bis hoch (unterstützt Relevanzsignale) |
| Keyword-Dichte | Prozentsatz, wie oft ein Keyword im Text erscheint | Keyword-Häufigkeit und -Prominenz | Traditionelles SEO (heute veraltet) | Gering (bei Übermaß wird abgestraft) |
| Ko-Zitation | Zwei Entitäten, die durch Dritte gemeinsam genannt werden | Autorität und thematische Zuordnung | Linkaufbau und Markenautorität | Mittel (unterstützt E-E-A-T-Signale) |
| Semantisches SEO | Optimierung auf Bedeutung und Nutzerintention statt nur Keywords | Umfassende Themenabdeckung | Content-Strategie und Struktur | Hoch (im Einklang mit modernen Algorithmen) |
| Latent Semantic Indexing (LSI) | Mathematische Methode zur Erkennung versteckter semantischer Muster | Konzeptuelle Beziehungen im Text | Inhaltsanalyse und Keyword-Recherche | Mittel (grundlegend, aber weniger im Fokus) |
| Entity Recognition | Erkennen und Kategorisieren benannter Entitäten im Text | Spezifische Personen, Orte, Organisationen | Knowledge Graphs und strukturierte Daten | Hoch (kritisch für KI-Systeme) |
Semantische Suche steht für einen grundlegenden Wandel darin, wie Suchmaschinen Nutzeranfragen interpretieren und mit relevanten Inhalten verknüpfen. Statt eine Suchanfrage als Ansammlung isolierter Keywords zu behandeln, analysieren semantische Suchmaschinen die Intention dahinter sowie die konzeptuellen Beziehungen zwischen Begriffen. Ko-Vorkommensmuster sind hierfür zentral, da sie statistische Hinweise darauf liefern, welche Konzepte semantisch zusammenhängen. Wenn der Google-Algorithmus Inhalte zu „nachhaltiger Mode“ analysiert, erkennt er, dass Begriffe wie „umweltfreundliche Materialien“, „ethische Produktion“, „CO₂-Fußabdruck“ und „Fairtrade“ häufig mit diesem Thema gemeinsam auftreten. Diese Ko-Vorkommensdaten helfen dem Algorithmus dabei zu verstehen, dass eine Seite das Thema umfassend behandelt und somit für Nutzeranfragen zu verwandten Suchbegriffen besonders relevant ist. Studien aus der Kognitionsforschung zeigen, dass statistische Regelmäßigkeiten im Ko-Vorkommen von Wörtern grundlegend für die menschliche Entwicklung semantischer Bedeutung sind – und moderne KI-Systeme bilden diesen Prozess rechnerisch nach. Für Content Creators hat das praktische Auswirkungen: Statt sich auf Keyword-Dichte oder exakte Phrasen zu versteifen, sollten Autoren darauf achten, semantisch verwandte Begriffe natürlich in ihre Inhalte einzubinden. Ein guter Artikel über „Machine Learning“ enthält automatisch Begriffe wie „Algorithmen“, „neuronale Netze“, „Trainingsdaten“, „Modellgenauigkeit“ und „überwachtes Lernen“ – und dieses natürliche Ko-Vorkommen signalisiert Suchmaschinen, dass der Inhalt fundiert und umfassend ist.
Das Aufkommen von generativen KI-Systemen als Discovery-Plattformen bringt eine neue Dimension für die Ko-Vorkommensanalyse mit sich. Im Gegensatz zu klassischen Suchmaschinen, die Links zu Webseiten liefern, generieren KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews eigene Textantworten, in denen Quellen genannt und Marken erwähnt werden. Die Häufigkeit und der Kontext dieser Erwähnungen hängen stark von den Ko-Vorkommensmustern in den Trainingsdaten der KI ab. Wenn eine Marke konsequent mit positiven Branchenbegriffen, autoritativen Quellen und relevanten Konzepten im Trainingskorpus gemeinsam auftritt, wird sie mit größerer Wahrscheinlichkeit in den Antworten der KI erwähnt. Das hat weitreichende Konsequenzen für die Markenüberwachung und die KI-Sichtbarkeitsstrategie. Tools wie AmICited analysieren nicht nur, ob eine Marke in KI-Antworten genannt wird, sondern auch, in welchem Kontext und mit welchen Begleitbegriffen. Erscheint Ihre Marke etwa zusammen mit „innovativ“, „branchenführend“ oder „von Unternehmen geschätzt“, stärkt dieses positive Ko-Vorkommensumfeld die Markenwahrnehmung. Tritt Ihre Marke hingegen häufig mit negativen Begriffen oder Wettbewerbern gemeinsam auf, kann dies die Positionierung schwächen. Studien zeigen, dass mittlerweile etwa 64 % der Nutzer KI-Assistenten zur Produktrecherche und Entscheidungsfindung verwenden – weshalb Ko-Vorkommensmuster in KI-Trainingsdaten für die Wettbewerbspositionierung immer wichtiger werden. Organisationen, die Ko-Vorkommen in KI-Kontexten verstehen und gezielt optimieren, verschaffen sich in dieser neuen Landschaft deutliche Vorteile.
Die Umsetzung der Ko-Vorkommensoptimierung erfordert einen strategischen Ansatz, der algorithmische Anforderungen und Nutzererlebnis in Einklang bringt. Der erste Schritt ist die Wettbewerbsanalyse: Identifizieren Sie Top-Ranking-Seiten zu Ihren Zielkeywords und analysieren Sie, welche semantischen Begriffe dort am häufigsten gemeinsam auftreten. Tools wie Surfer SEO, Clearscope und MarketMuse automatisieren diese Analyse, indem sie Ko-Vorkommensphrasen aus Wettbewerberinhalten extrahieren und Empfehlungen liefern. Der zweite Schritt ist die natürliche Integration: Bauen Sie die identifizierten Ko-Vorkommensbegriffe organisch in Ihre Inhalte ein, sodass sie die Lesbarkeit und den Mehrwert steigern. Wenn Sie beispielsweise über „Content Marketing“ schreiben und die Analyse zeigt, dass „Zielgruppenbindung“, „Storytelling“, „Markenstimme“ und „Conversion-Optimierung“ häufig gemeinsam in Top-Inhalten vorkommen, sollten Sie diese Konzepte sinnvoll in Ihren Text einbinden. Im Unterschied zum Keyword-Stuffing steht bei der Ko-Vorkommensoptimierung die semantische Kohärenz im Mittelpunkt – jeder Begriff muss tatsächlich zum Thema passen und den Lesern einen Mehrwert bieten. Der dritte Schritt ist die strukturelle Optimierung: Gliedern Sie Ihre Inhalte mit klaren Überschriften, Unterüberschriften und Abschnitten, die verwandte Konzepte bündeln. So werden Ko-Vorkommensmuster verstärkt, und sowohl Leser als auch Algorithmen verstehen die hierarchischen Beziehungen zwischen den Ideen besser. Schließlich gilt: Überwachen und iterieren: Beobachten Sie Ihre Rankings für Haupt- und Nebenkeywords und nutzen Sie Tools wie Google Search Console und Ahrefs, um herauszufinden, welche Ko-Vorkommensmuster mit Ranking-Verbesserungen korrelieren. Dieser datenbasierte Ansatz stellt sicher, dass Ihre Ko-Vorkommensstrategie messbare Ergebnisse liefert.
Ko-Vorkommensmatrizen sind grundlegende Datenstrukturen im NLP, die Wortbeziehungen im großen Maßstab quantifizieren. Eine typische Matrix für einen Korpus mit 10.000 einzigartigen Wörtern wäre ein 10.000×10.000-Raster mit Häufigkeiten für jedes mögliche Wortpaar. Zwar ergeben sich daraus rechnerische Herausforderungen (viele Nullwerte in der Matrix), doch die gewonnenen Erkenntnisse sind äußerst wertvoll. Techniken zur Dimensionsreduktion wie Singular Value Decomposition (SVD) komprimieren diese Matrizen auf niedrigere Dimensionen und erfassen dabei die wichtigsten semantischen Beziehungen, während der Rechenaufwand reduziert wird. Aus diesen reduzierten Matrizen entstehen Wort-Embeddings, die jedes Wort als dichten Vektor im semantischen Raum abbilden. Bedeutungsverwandte Wörter erhalten ähnliche Vektoren, was Algorithmen semantische Ähnlichkeitsberechnungen ermöglicht. Die Vektoren für „Hund“, „Welpe“ und „Canide“ liegen z. B. eng beieinander, während „Hund“ und „Fahrrad“ weit auseinanderliegen würden. Diese mathematische Abbildung ermöglicht es KI-Systemen, zu verstehen, dass „Ich habe einen Welpen“ und „Ich habe einen jungen Hund“ dieselbe Bedeutung vermitteln, obwohl unterschiedliche Wörter verwendet werden. Die Praxisanwendungen gehen weit über Ähnlichkeitsberechnungen hinaus: Ko-Vorkommensmatrizen ermöglichen Themenmodellierung (Erkennung von Wortclustern, die eigenständige Themen darstellen), Wortbedeutungs-Disambiguierung (Ermittlung der gemeinten Bedeutung eines mehrdeutigen Begriffs im Kontext) und semantische Suche (Abgleich von Anfragen und Dokumenten auf Basis konzeptueller Relevanz statt Keyword-Matching).
Unterschiedliche KI-Plattformen gewichten Ko-Vorkommensmuster je nach Trainingsdaten, Architektur und Optimierungszielen unterschiedlich stark. ChatGPT, trainiert auf vielfältigen Internettexten, erkennt Ko-Vorkommensmuster, die einen breiten Konsens zu Themenbeziehungen widerspiegeln. Bei einer Anfrage zu den „besten Projektmanagement-Tools“ nennt ChatGPT Marken, die in den Trainingsdaten häufig mit positiven Bewertungen, Branchenanerkennung und Funktionsbeschreibungen gemeinsam auftreten. Perplexity, das Quellzitate und aktuelle Informationen betont, gewichtet Ko-Vorkommensmuster möglicherweise anders und bevorzugt Quellen, die mit neueren, autoritativen Inhalten gemeinsam auftreten. Google AI Overviews integrieren Ko-Vorkommensanalysen mit bestehenden Rankingfaktoren von Google; das heißt, Marken, die für verwandte Keywords gut ranken und mit vertrauenswürdigen Quellen gemeinsam auftreten, haben in KI-generierten Zusammenfassungen eine höhere Sichtbarkeit. Claude, der KI-Assistent von Anthropic, gewichtet Ko-Vorkommen je nach Trainingsansatz etwas anders und legt Wert auf Hilfsbereitschaft und Harmlosigkeit. Das Wissen um diese plattformspezifischen Unterschiede ist entscheidend für die GEO-Strategie (Generative Engine Optimization). Eine Marke, die Ko-Vorkommen mit „Enterprise-Lösungen“, „Skalierbarkeit“ und „Sicherheit“ optimiert, ist bei ChatGPT und Claude gut aufgestellt, während für Perplexity eventuell Ko-Vorkommen mit „innovativ“, „start-up-freundlich“ und „kosteneffizient“ wichtiger sind. Diese plattformspezifische Optimierung ist die nächste Ausbaustufe der KI-Sichtbarkeitsstrategie – Marketer müssen nicht nur wissen, welche Begriffe ko-vorkommen, sondern auch, wie unterschiedliche KI-Systeme diese Muster gewichten.
Die Bedeutung von Ko-Vorkommen in der Digitalstrategie wird weiter zunehmen, je ausgefeilter und verbreiteter KI-Systeme werden. Mehrere Trends zeichnen eine Entwicklung ab: Erstens gewinnt multimodales Ko-Vorkommen an Relevanz, da KI-Systeme nicht nur Text, sondern auch Bilder, Videos und strukturierte Daten verarbeiten. Eine Marke, die mit hochwertigem Bildmaterial und positivem User-Generated Content gemeinsam auftritt, sendet stärkere Signale als eine, die nur im Text erscheint. Zweitens rücken zeitliche Ko-Vorkommensmuster in den Fokus – Begriffe, die kürzlich gemeinsam mit Ihrer Marke auftreten, können für KI-Systeme wichtiger sein als ältere Muster, da aktuelle Informationen bevorzugt werden. Drittens wird sentimentbasiertes Ko-Vorkommen zum kritischen Faktor: Die emotionale Bewertung der ko-vorkommenden Begriffe ist genauso bedeutend wie deren Häufigkeit. Eine Marke, die mit positiven Sentimentbegriffen („innovativ“, „zuverlässig“, „vertrauenswürdig“) gemeinsam auftritt, erzielt andere Effekte als eine, die mit neutralen oder negativen Begriffen erscheint. Viertens wird Entity-basiertes Ko-Vorkommen immer ausgefeilter – KI-Systeme erkennen nicht nur Wort-Ko-Vorkommen, sondern auch Beziehungen zwischen Entitäten (Personen, Organisationen, Orte, Produkte). Das ermöglicht eine differenzierte Analyse der Markenpositionierung im Verhältnis zu Wettbewerbern, Partnern und Branchenmeinungsführern. Schließlich wird plattformübergreifende Ko-Vorkommensanalyse zum Standard – Marketer verfolgen, wie ihre Marke auf verschiedenen KI-Systemen, Social-Media-Plattformen, Nachrichtenquellen und Bewertungsportalen gemeinsam mit anderen Begriffen auftritt, um eine umfassende Sichtbarkeitsstrategie zu entwickeln. Organisationen, die Ko-Vorkommensmuster frühzeitig verstehen und optimieren, sichern sich im Zuge der KI-getriebenen Transformation erhebliche Wettbewerbsvorteile.
Ko-Vorkommen ist die natürliche Gruppierung semantisch verwandter Begriffe, die inhaltliche Tiefe und bessere Lesbarkeit ermöglichen. Keyword-Stuffing bedeutet hingegen das künstliche und übermäßige Wiederholen desselben Keywords, um Rankings zu manipulieren. Ko-Vorkommen entsteht organisch beim Verfassen umfassender Inhalte, während Keyword-Stuffing eine bewusste Manipulation darstellt, die von Suchmaschinen abgestraft wird. Moderne Algorithmen wie die von Google bevorzugen sinnvolle Inhalte mit natürlichen Begriffszusammenhängen gegenüber erzwungener Keyword-Wiederholung.
Ko-Vorkommen ist entscheidend für die KI-Sichtbarkeit, da Systeme wie ChatGPT, Perplexity und Google AI Overviews semantisches Verständnis zur Generierung von Antworten nutzen. Wenn Ihre Marke oder Ihr Inhalt zusammen mit kontextuell relevanten Begriffen erscheint, signalisiert dies Autorität und Relevanz für KI-Systeme. Dadurch steigt die Wahrscheinlichkeit, dass Ihre Marke in KI-generierten Antworten erwähnt wird – was zunehmend wichtiger wird, da mittlerweile über 60 % der Nutzer auf KI-Assistenten zur Informationssuche und Entscheidungsfindung zurückgreifen.
Eine Ko-Vorkommensmatrix ist eine mathematische Darstellung (typischerweise ein N×N-Raster), in der Zeilen und Spalten für einzigartige Wörter eines Textkorpus stehen und jede Zelle die Häufigkeit enthält, mit der Wortpaare gemeinsam innerhalb eines bestimmten Kontextfensters auftreten. Im NLP bilden Ko-Vorkommensmatrizen die Grundlage für die Erstellung von Wort-Embeddings wie GloVe, ermöglichen semantische Analysen, Themenmodellierung und Messung von Textähnlichkeiten. Sie helfen Algorithmen dabei zu verstehen, welche Wörter semantisch zusammenhängen – basierend auf ihren statistischen Mustern.
Um für Ko-Vorkommen zu optimieren, verfassen Sie umfassende Inhalte, in denen semantisch verwandte Begriffe natürlich neben Ihrem Hauptkeyword vorkommen. Ein Artikel über 'Elektrofahrzeuge' sollte beispielsweise Begriffe wie 'Batteriereichweite', 'EV-Förderungen', 'Ladeinfrastruktur' und 'CO₂-Emissionen' enthalten. Nutzen Sie Tools wie Surfer SEO oder Clearscope, um in Top-Wettbewerberinhalten häufig gemeinsam auftretende Phrasen zu identifizieren und integrieren Sie ähnliche semantische Cluster in Ihren Text – unter Wahrung von Lesbarkeit und Nutzerintention.
Ko-Vorkommen ist ein Kernbestandteil des semantischen SEO, das darauf abzielt, den Inhaltsbedeutung statt nur exakte Keywords zu verstehen. Semantisches SEO nutzt Ko-Vorkommensmuster, damit Suchmaschinen den vollständigen Kontext und die Intention eines Inhalts erfassen können. Wenn verwandte Begriffe natürlich im Text gruppiert werden, signalisieren Sie Algorithmen, dass Ihre Seite ein Thema umfassend abdeckt und verbessern so das Ranking für das Hauptkeyword sowie verwandte semantische Varianten.
Ko-Vorkommen beeinflusst die Markenüberwachung, da KI-Systeme analysieren, wie häufig Ihre Marke zusammen mit branchenspezifischen Begriffen und Wettbewerbern genannt wird. Wenn Ihre Marke konsequent mit positiv konnotierten Begriffen ('innovativ', 'zuverlässig', 'branchenführend') vorkommt, stärkt das Ihre wahrgenommene Autorität. Tools wie AmICited erfassen diese Ko-Vorkommensmuster über KI-Plattformen hinweg und zeigen, wie Ihre Marke in KI-generierten Antworten im Vergleich zur Konkurrenz positioniert ist.
Ja, Ko-Vorkommen verbessert das Ranking für Long-Tail-Keywords deutlich. Diese Suchanfragen haben oft geringeres Suchvolumen, aber eine höhere Intentionsspezifik. Durch die natürliche Einbindung semantisch verwandter Begriffe schaffen Sie ein reiches Kontextumfeld, das Suchmaschinen hilft, Ihre Inhalte mit verschiedenen Long-Tail-Variationen zu verknüpfen. Dieser Ansatz ist wirksamer als klassische Keyword-Fokussierung, da er die Nutzerintention umfassend bedient und nicht nur isolierte Keywords anvisiert.
KI-Systeme nutzen Ko-Vorkommensstatistiken aus den Trainingsdaten, um Wortbeziehungen zu verstehen und kontextgerechte Antworten zu generieren. Bei einer Anfrage an ChatGPT oder Perplexity greifen diese Systeme auf gelernte Ko-Vorkommensmuster zurück, um zu bestimmen, welche Quellen und Marken am relevantesten erwähnt werden sollten. Eine hohe Ko-Vorkommensfrequenz zwischen Ihrer Marke und relevanten Branchenbegriffen erhöht die Wahrscheinlichkeit, dass Ihre Marke in KI-Antworten genannt wird – was für GEO-Strategien (Generative Engine Optimization) essenziell ist.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Erfahren Sie mehr über Keyword-Mapping: den Prozess der Zuweisung von Ziel-Keywords zu Webseiten. Lernen Sie, wie Sie Kannibalisierung verhindern, die Seitenstr...

Co-Citation liegt vor, wenn zwei Websites gemeinsam von Dritten erwähnt werden und dadurch Suchmaschinen und KI-Systemen eine semantische Verwandtschaft signali...
Keyword-Clustering gruppiert verwandte Suchbegriffe nach Suchintention und semantischer Relevanz. Erfahren Sie, wie diese SEO-Technik Rankings, Content-Strategi...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.