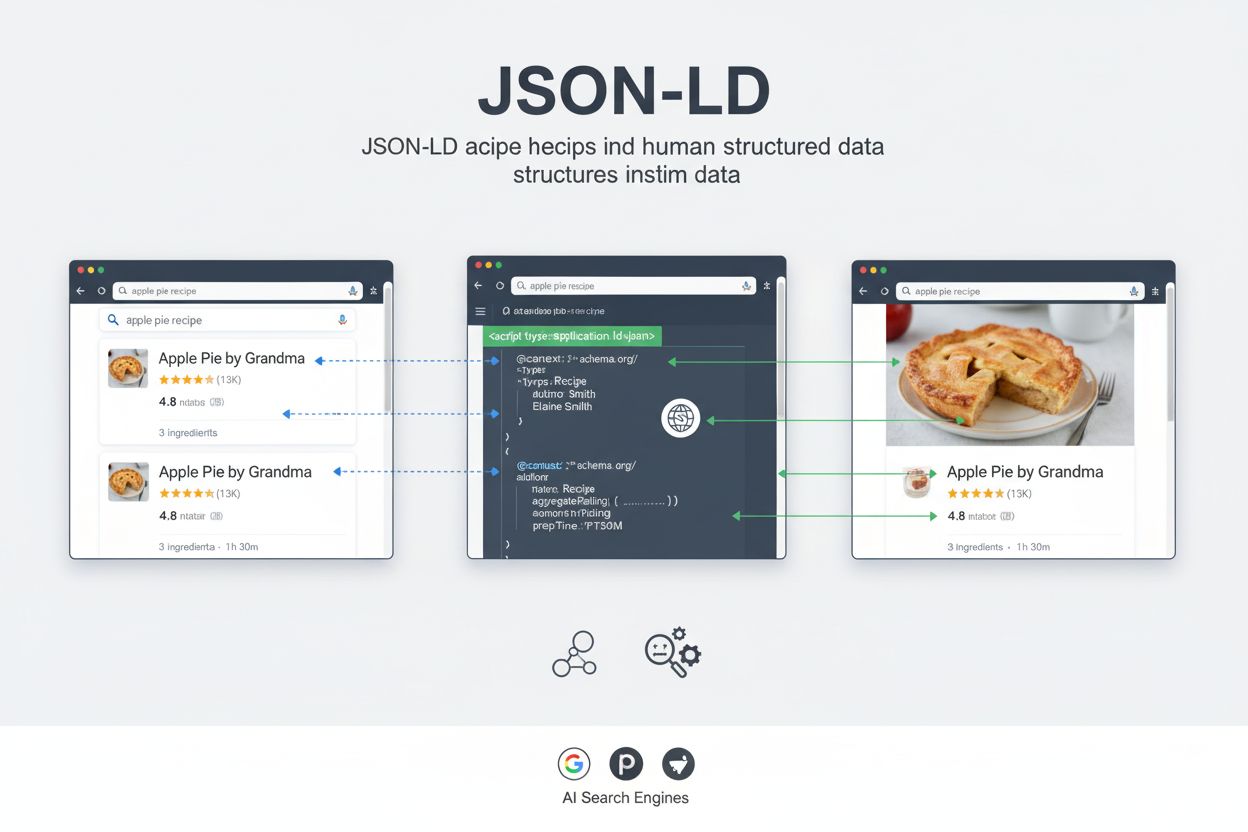
Definition von JSON-LD
JSON-LD steht für JavaScript Object Notation for Linked Data und stellt ein leichtgewichtiges, standardisiertes Format zur Darstellung strukturierter Daten auf Webseiten dar. Seit Januar 2014 ist JSON-LD eine W3C-Empfehlung und vereint die Einfachheit der JSON-Syntax mit der semantischen Kraft von Linked-Data-Vokabularen, insbesondere schema.org. Im Gegensatz zu anderen Formaten für strukturierte Daten, die Markup mit HTML-Inhalten vermischen, wird JSON-LD als separates <script>-Tag im Seitenkopf oder -körper eingebettet, wodurch Daten von der Präsentation getrennt bleiben. Diese Trennung macht JSON-LD besonders einfach in der Implementierung, Wartung und Skalierung für große Websites und Content-Management-Systeme.
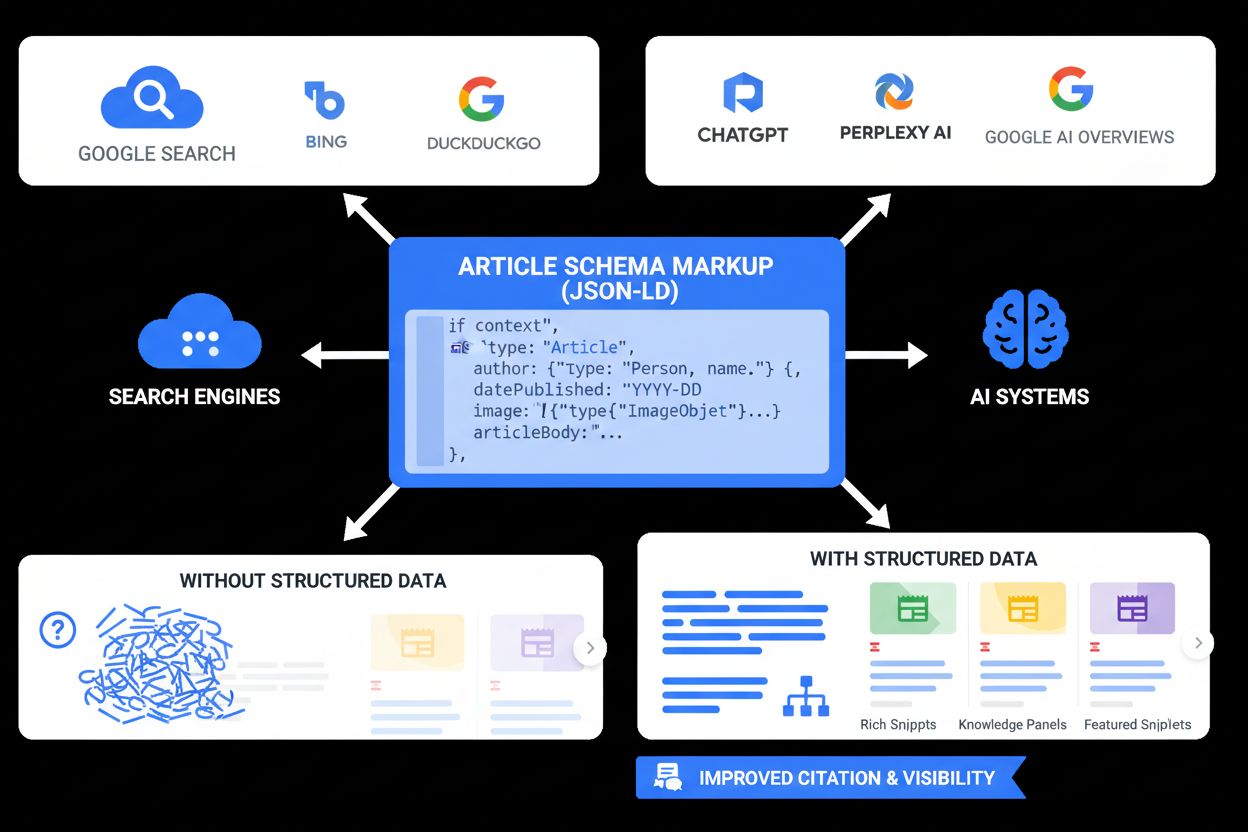
Der Hauptzweck von JSON-LD ist es, maschinenlesbaren Kontext bereitzustellen, der Suchmaschinen, KI-Systemen und anderen Webanwendungen hilft, die Bedeutung und Beziehungen innerhalb von Webseiteninhalten zu verstehen. Richtig implementiert ermöglicht JSON-LD Suchmaschinen die Anzeige von Rich Results – erweiterte Suchsnippets, die Bewertungen, Preise, Bilder, Veranstaltungsdetails und andere strukturierte Informationen enthalten. Für KI-gestützte Suchplattformen wie ChatGPT, Perplexity, Google AI Overviews und Claude dient JSON-LD als wichtige Brücke zwischen menschenlesbaren Inhalten und maschineninterpretierbaren Daten, wodurch die Genauigkeit und Relevanz von KI-generierten Antworten und Zitaten verbessert wird.
JSON-LD ist das empfohlene Format für strukturierte Daten von Google und anderen großen Suchmaschinen, da es Implementierungsfehler minimiert und nahtlos mit modernen Webtechnologien wie JavaScript-Frameworks und dynamischer Inhaltserzeugung zusammenarbeitet. Die Flexibilität des Formats ermöglicht die Darstellung komplexer, verschachtelter Datenstrukturen und eignet sich für vielfältige Inhaltstypen – von einfachen Produktinformationen bis hin zu komplexen Organisationshierarchien und Veranstaltungsdetails.
Historischer Kontext und Entwicklung von JSON-LD
JSON-LD entstand aus dem Bedürfnis, traditionelle JSON-Datenformate mit Semantic-Web-Standards zu verbinden. Vor JSON-LD nutzen Entwickler für Linked Data meist RDF/XML oder Turtle – mächtige, aber komplexe Formate, die nicht optimal auf Webentwicklung zugeschnitten waren. Die Entwicklung von JSON-LD begann Anfang der 2010er Jahre innerhalb der W3C JSON-LD Community Group, da JSON zum De-facto-Standard für Web-APIs und Datenaustausch wurde. Das Format wurde 2014 von der W3C offiziell standardisiert, mit weiteren Verbesserungen, die 2020 zur JSON-LD 1.1 als vollwertige W3C-Empfehlung führten.
Die Verbreitung von JSON-LD nahm stark zu, nachdem Google und andere große Suchmaschinen es 2013 als bevorzugtes Format für schema.org-Markup empfahlen. Diese Empfehlung war wegweisend, da sie der Webentwicklungs-Community zeigte, dass JSON-LD nicht nur ein akademisches Projekt, sondern eine praxisnahe Lösung für reale SEO- und Auffindbarkeitsprobleme ist. In den letzten zehn Jahren ist die Nutzung von JSON-LD exponentiell gestiegen: Aktuelle Daten zeigen, dass 41 % aller Websites mittlerweile JSON-LD für strukturiertes Daten-Markup einsetzen – gegenüber nur 34 % im Jahr 2022. Unter den Websites, die überhaupt strukturiertes Daten-Markup verwenden, nutzen etwa 70 % JSON-LD und machen es damit zum dominanten Format im Bereich strukturierter Daten.
Die Weiterentwicklung von JSON-LD wurde auch durch den Aufstieg KI-gestützter Suchmaschinen und großer Sprachmodelle beeinflusst. Mit Plattformen wie ChatGPT, Perplexity und Google AI Overviews steigt die Bedeutung von JSON-LD, da diese Systeme stark auf strukturierte Daten angewiesen sind, um genaue, kontextuelle Informationen aus Webseiten zu extrahieren. Die Fähigkeit des Formats, Entitätstypen, Beziehungen und Eigenschaften klar zu definieren, macht es für das Training und den Betrieb von KI-Systemen unverzichtbar, die Webinhalte im großen Maßstab verstehen müssen.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technische Struktur und Kernelemente
JSON-LD-Dokumente folgen der Standard-JSON-Syntax, enthalten jedoch spezielle reservierte Schlüsselwörter mit vorangestelltem @, die semantische Bedeutung vermitteln. Die wichtigsten davon sind @context, @type und @id. Die Eigenschaft @context legt den Vokabular-Namespace fest – typischerweise https://schema.org –, der die Bedeutung aller im Markup verwendeten Eigenschaften und Typen definiert. Dieser Kontext fungiert wie eine Namespace-Deklaration, ähnlich wie bei XML, und stellt sicher, dass Eigenschaftsnamen system- und plattformübergreifend konsistent interpretiert werden.
Die Eigenschaft @type gibt den Schema-Typ der beschriebenen Entität an, etwa Product, Article, Event, Organization oder LocalBusiness. Jeder Typ in schema.org verfügt über eigene Eigenschaften, mit denen Instanzen dieses Typs beschrieben werden können. Ein Typ Product könnte beispielsweise die Eigenschaften name, description, price, image, aggregateRating und offers enthalten. Die Eigenschaft @id liefert eine eindeutige Kennung für die Entität, meist eine URL, die auf weiterführende Informationen verweist.
Neben diesen zentralen Schlüsselwörtern enthalten JSON-LD-Dokumente individuelle Eigenschaften, die direkt auf das schema.org-Vokabular abgebildet sind. Diese Eigenschaften können einfache Werte (Strings, Zahlen, Daten) oder komplexe, verschachtelte Objekte enthalten, die verbundene Entitäten darstellen. Beispielsweise kann eine Product-Entität eine offers-Eigenschaft haben, die ein eingebettetes Offer-Objekt mit eigenem @type und Eigenschaften wie price und priceCurrency enthält. Diese Verschachtelungsfähigkeit ermöglicht es JSON-LD, anspruchsvolle Datenbeziehungen und Hierarchien darzustellen, die in flacheren Formaten wie Microdata nur schwer realisierbar wären.
| Aspekt | JSON-LD | Microdata | RDFa |
|---|
| Implementierungsort | Separates <script>-Tag im <head> oder <body> | Im HTML über Attribute eingebettet | Im HTML über Attribute eingebettet |
| Implementierungsaufwand | Sehr einfach; minimale Änderungen am HTML notwendig | Mittel; HTML-Attribute müssen ergänzt werden | Mittel bis komplex; Namespace-Deklarationen erforderlich |
| Wartungsaufwand | Gering; Daten getrennt von der Präsentation | Mittel; Markup ist mit Inhalt vermischt | Mittel bis hoch; mehrere Vokabulare möglich |
| Dynamische Inhalte | Exzellent; funktioniert mit JavaScript-Injektion | Eingeschränkt; serverseitiges Rendering nötig | Eingeschränkt; serverseitiges Rendering nötig |
| Google-Empfehlung | Empfohlen | Unterstützt | Unterstützt |
| Verbreitung (2024) | 41 % aller Websites; 70 % der strukturierten Daten-Sites | ca. 20 % der strukturierten Daten-Sites | ca. 15 % der strukturierten Daten-Sites |
| Vokabular-Flexibilität | Ein Vokabular pro Dokument (meist schema.org) | Ein Vokabular pro Dokument | Mehrere Vokabulare möglich |
| Verschachtelungskomplexität | Exzellent; natürliche JSON-Hierarchie | Gut; mehrere itemscope-Deklarationen nötig | Gut; komplexe Beziehungen möglich |
| Kompatibilität mit KI-Suchmaschinen | Exzellent; bevorzugt von ChatGPT, Perplexity, Claude | Gut; unterstützt, aber weniger bevorzugt | Gut; unterstützt, aber weniger bevorzugt |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wie JSON-LD mit Suchmaschinen und KI-Systemen funktioniert
Wenn ein Suchmaschinen-Crawler oder ein KI-System eine Webseite mit JSON-LD-Markup findet, parst es das <script type="application/ld+json">-Tag und extrahiert die strukturierten Daten. Der Crawler nutzt das @context, um das verwendete Vokabular zu verstehen, und interpretiert dann jede Eigenschaft gemäß den schema.org-Definitionen. So kann die Suchmaschine spezifische, maschinenlesbare Informationen über den Seiteninhalt extrahieren – ohne sich auf natürliche Sprachverarbeitung oder Heuristiken zu verlassen.
Für die Google-Suche ermöglicht JSON-LD die Darstellung von Rich Results – angereicherte Suchanzeigen mit visuellen Elementen wie Bewertungen, Preisen, Bildern und Veranstaltungsdetails. Wenn Google eine Produktseite mit korrekt implementiertem JSON-LD-Markup crawlt, kann es Produktname, Preis, Verfügbarkeit, Bewertungen und Bilder direkt aus den strukturierten Daten extrahieren. Diese Informationen werden verwendet, um ein Rich Result in den Suchergebnissen anzuzeigen, das in der Regel eine höhere Klickrate erzielt als Standard-Links. Studien großer Websites belegen den Effekt: Rotten Tomatoes verzeichnete eine 25 % höhere Klickrate auf Seiten mit strukturierten Daten, während Nestlé eine 82 % höhere Klickrate für Seiten mit Rich Results maß.
Für KI-Suchmaschinen wie Perplexity, ChatGPT und Google AI Overviews erfüllt JSON-LD eine ebenso wichtige Funktion. Diese Systeme nutzen strukturierte Daten, um die semantische Bedeutung von Inhalten zu verstehen, wichtige Entitäten und Beziehungen zu identifizieren und genaue Informationen in KI-generierten Antworten zu verwenden. Erkennt ein KI-System JSON-LD-Markup, kann es sicher bestimmen, welcher Entitätstyp beschrieben wird, welche Eigenschaften diese Entität besitzt und wie sie mit anderen Entitäten verbunden ist. Dieses strukturierte Verständnis ermöglicht präzisere, kontextuell relevante Antworten und eine korrekte Zuordnung der Informationen zur Ursprungswebsite.
Best Practices und technische Hinweise zur Implementierung
Eine effektive Implementierung von JSON-LD erfordert das Verständnis einiger zentraler Prinzipien und Best Practices. Erstens sollte JSON-LD im <head>-Bereich des HTML-Dokuments platziert werden, auch wenn eine Platzierung im <body> ebenfalls möglich ist. Die Platzierung im <head> ist in der Regel vorzuziehen, da dies sicherstellt, dass die strukturierten Daten vor dem Seiteninhalt geparst werden – moderne Suchmaschinen und KI-Systeme können JSON-LD jedoch überall auf der Seite erkennen.
Zweitens sollte @context immer explizit definiert werden, typischerweise als "@context": "https://schema.org". So wird sichergestellt, dass alle Eigenschaftsnamen und Typen im Sinne von schema.org interpretiert werden. Zwar sind mehrere Kontexte oder eigene Vokabulare technisch möglich, die meisten Webimplementierungen nutzen jedoch ausschließlich schema.org.
Drittens sollte das JSON-LD-Markup den sichtbaren Seiteninhalt akkurat widerspiegeln. Suchmaschinen und KI-Systeme erwarten, dass die strukturierten Daten mit dem übereinstimmen, was Nutzer auf der Seite sehen. Das Hinzufügen von JSON-LD-Markup zu Informationen, die für Nutzer unsichtbar sind oder dem sichtbaren Inhalt widersprechen, kann zu Abstrafungen oder zur kompletten Ignorierung des Markups führen. Dieses Prinzip ist entscheidend, um das Vertrauen von Suchmaschinen zu bewahren und eine korrekte Zitation Ihrer Inhalte durch KI-Systeme zu gewährleisten.
Viertens sollten für den gewählten Schema-Typ alle erforderlichen Eigenschaften angegeben werden. Während schema.org viele optionale Eigenschaften definiert, ermöglicht erst die Angabe der erforderlichen Eigenschaften, dass Suchmaschinen das Markup korrekt validieren und anzeigen. Für das Schema Product sind beispielsweise mindestens name, description und offers notwendig, um für Rich Results in Frage zu kommen.
Fünftens sollte JSON-LD vor dem Ausrollen mit Tools wie dem Google Rich Results Test oder dem Schema.org Validator validiert werden. Diese Tools prüfen auf Syntaxfehler, fehlende Pflichtfelder und andere Probleme, die verhindern könnten, dass das Markup erkannt wird. Eine gründliche Prüfung in der Entwicklungsphase verhindert Fehler in der Produktion und stellt sicher, dass das Markup wie gewünscht funktioniert.
Zentrale Vorteile und geschäftlicher Nutzen von JSON-LD
Die Implementierung von JSON-LD-strukturierten Daten bringt messbare Vorteile in mehreren Bereichen. Aus SEO-Sicht ermöglicht JSON-LD Rich Results, die die Klickraten erheblich steigern. Das Food Network stellte 80 % seiner Seiten auf strukturierte Daten um und erzielte einen 35%igen Anstieg der Besuche. Rakuten stellte fest, dass Nutzer 1,5-mal länger auf Seiten mit strukturierten Daten verweilten als auf solchen ohne und erlebte eine 3,6-mal höhere Interaktionsrate auf AMP-Seiten mit Suchfunktionen.
Aus KI-Sicht ist JSON-LD zunehmend entscheidend, da KI-gestützte Suchmaschinen zum Standard werden. Websites mit JSON-LD-Markup werden mit höherer Wahrscheinlichkeit korrekt verstanden, zitiert und in KI-generierten Antworten hervorgehoben. Das ist besonders wichtig für AmICited-Nutzer, die verfolgen möchten, wie ihre Marke, Domain und URLs in KI-Suchergebnissen auf Plattformen wie ChatGPT, Perplexity, Google AI Overviews und Claude erscheinen. Eine korrekte JSON-LD-Implementierung gibt KI-Systemen den strukturierten Kontext, den sie für eine akkurate Zuordnung und Zitierung Ihrer Inhalte benötigen.
Aus technischer Sicht reduziert JSON-LD die Komplexität der Implementierung und den Wartungsaufwand. Da das Markup vom HTML-Inhalt getrennt ist, können Entwickler die strukturierten Daten unabhängig von Layout-Änderungen verwalten. Das ist besonders wertvoll für große Organisationen mit komplexen Content-Management-Systemen, wo verschiedene Teams für Inhalt und technische Umsetzung verantwortlich sind.
Aus Nutzersicht verbessert JSON-LD indirekt das Nutzererlebnis, weil es zu reichhaltigeren, informativeren Suchergebnissen führt. Nutzer klicken eher auf Suchergebnisse mit Bewertungen, Preisen, Bildern und anderen strukturierten Informationen – was zu mehr Traffic und besseren Konversionsraten für Websites mit effektiver JSON-LD-Implementierung führt.
JSON-LD im Kontext moderner Webtechnologien
JSON-LD lässt sich nahtlos in moderne Webentwicklung und -technologien integrieren. Im Gegensatz zu Microdata und RDFa, die serverseitiges Rendering für die korrekte Erkennung durch Suchmaschinen voraussetzen, kann JSON-LD dynamisch per JavaScript in Seiten eingefügt werden. Das ist entscheidend für Single-Page-Anwendungen (SPAs), Progressive Web Apps (PWAs) und andere JavaScript-lastige Websites mit dynamisch erzeugten Inhalten.
Content-Management-Systeme (CMS) wie WordPress, Shopify, Wix oder Drupal bieten zunehmend integrierte Unterstützung für JSON-LD, entweder nativ oder über Plugins. Dadurch können auch Nicht-Techniker strukturierte Daten zu ihren Seiten hinzufügen, ohne Code schreiben zu müssen. Viele CMS-Plattformen generieren JSON-LD-Markup automatisch auf Basis von Metadaten und Inhalten, was den Aufwand für Entwickler und Content-Ersteller reduziert.
JSON-LD harmoniert auch mit Headless-CMS-Architekturen, bei denen Inhalte getrennt von der Präsentation verwaltet werden. In solchen Systemen kann JSON-LD serverseitig erzeugt und im Seiten-Response ausgeliefert oder clientseitig mit Frameworks wie React, Vue oder Angular generiert werden. Diese Flexibilität macht JSON-LD für praktisch jede moderne Webarchitektur geeignet.
Wichtige Aspekte und Checkliste zur Implementierung
- @context explizit als
https://schema.org definieren, um konsistente Vokabular-Interpretation sicherzustellen - Geeigneten @type wählen je nach Seiteninhalt (Product, Article, Event, Organization, LocalBusiness usw.)
- Alle erforderlichen Eigenschaften für den gewählten Schema-Typ angeben, um Rich Results zu ermöglichen
- Datenkonsistenz sicherstellen: JSON-LD-Markup muss mit sichtbarem Seiteninhalt übereinstimmen
- Verschachtelte Objekte nutzen für komplexe Beziehungen (z. B. Offer innerhalb von Product)
- Markup validieren mit Google Rich Results Test oder Schema.org Validator vor dem Ausrollen
- Platzierung im-Bereich für optimale Erkennung durch Suchmaschinen und KI-Systeme
- Versteckte oder unsichtbare Inhalte vermeiden im JSON-LD-Markup
- Mit mehreren Tools testen, um Kompatibilität mit verschiedenen Suchmaschinen und KI-Plattformen sicherzustellen
- Performance überwachen mit der Search Console, um Rich-Result-Impressionen und Klickraten zu verfolgen
- Regelmäßig aktualisieren, wenn sich Seiteninhalte ändern, um Genauigkeit und Relevanz zu wahren
- KI-Sichtbarkeit berücksichtigen bei der Implementierung von JSON-LD für neue Plattformen wie Perplexity und ChatGPT
Zukunft und strategische Bedeutung von JSON-LD
Die Bedeutung von JSON-LD wird in Zukunft eher zunehmen als abnehmen. Mit der Weiterentwicklung KI-gestützter Suchmaschinen und großer Sprachmodelle wächst der Bedarf an qualitativ hochwertigen, maschinenlesbaren strukturierten Daten. Suchmaschinen und KI-Systeme nutzen strukturierte Daten zunehmend nicht nur für die Darstellung, sondern als zentrales Element ihres Verständnisses und ihrer Ranking-Algorithmen.
Zu den neuen Entwicklungen von JSON-LD zählen JSON-LD-star, das komplexere Wissensgraph-Beziehungen unterstützt, sowie CBOR-LD, das eine kompaktere, binäre Darstellung von JSON-LD-Daten bietet. Diese Erweiterungen deuten darauf hin, dass das JSON-LD-Ökosystem sich weiterentwickeln wird, um die Anforderungen immer anspruchsvollerer Webanwendungen und KI-Systeme zu erfüllen.
Der Aufstieg von KI-Suchmaschinen markiert einen Paradigmenwechsel in der Nutzung strukturierter Daten. Während traditionelle Suchmaschinen strukturierte Daten vor allem für die Anzeige – etwa Rich Results – nutzen, dienen sie KI-Suchmaschinen als zentrales Input für deren Verständnis- und Analyseprozesse. Das bedeutet: Websites mit effektiver JSON-LD-Implementierung sichern sich einen wesentlichen Vorteil bei KI-Sichtbarkeit und Zitationshäufigkeit.
Zudem wird JSON-LD angesichts steigender Anforderungen an Datenschutz und Data Governance künftig auch eine größere Rolle bei der Angabe von Datenherkunft, Lizenzen und Nutzungsrechten spielen. Dank Flexibilität und Erweiterbarkeit eignet sich das Format hervorragend, um komplexe Metadaten über Datenquellen und Nutzungsbeschränkungen auszudrücken – ein Thema, das für Unternehmen mit Blick auf KI-Nutzung immer wichtiger wird.
Für Organisationen, die wie AmICited ihre Präsenz in KI-Suchergebnissen überwachen, ist die umfassende Implementierung von JSON-LD ein strategisch wichtiger Schritt. Indem Sie KI-Systemen einen klaren, strukturierten Kontext zu Ihren Inhalten liefern, erhöhen Sie die Wahrscheinlichkeit, dass Ihre Marke, Domain und URLs korrekt verstanden, zitiert und in KI-Antworten hervorgehoben werden. Mit dem Wachstum von KI-Suche wird JSON-LD zu einem unverzichtbaren Bestandteil jeder umfassenden SEO- und Sichtbarkeitsstrategie im Netz.