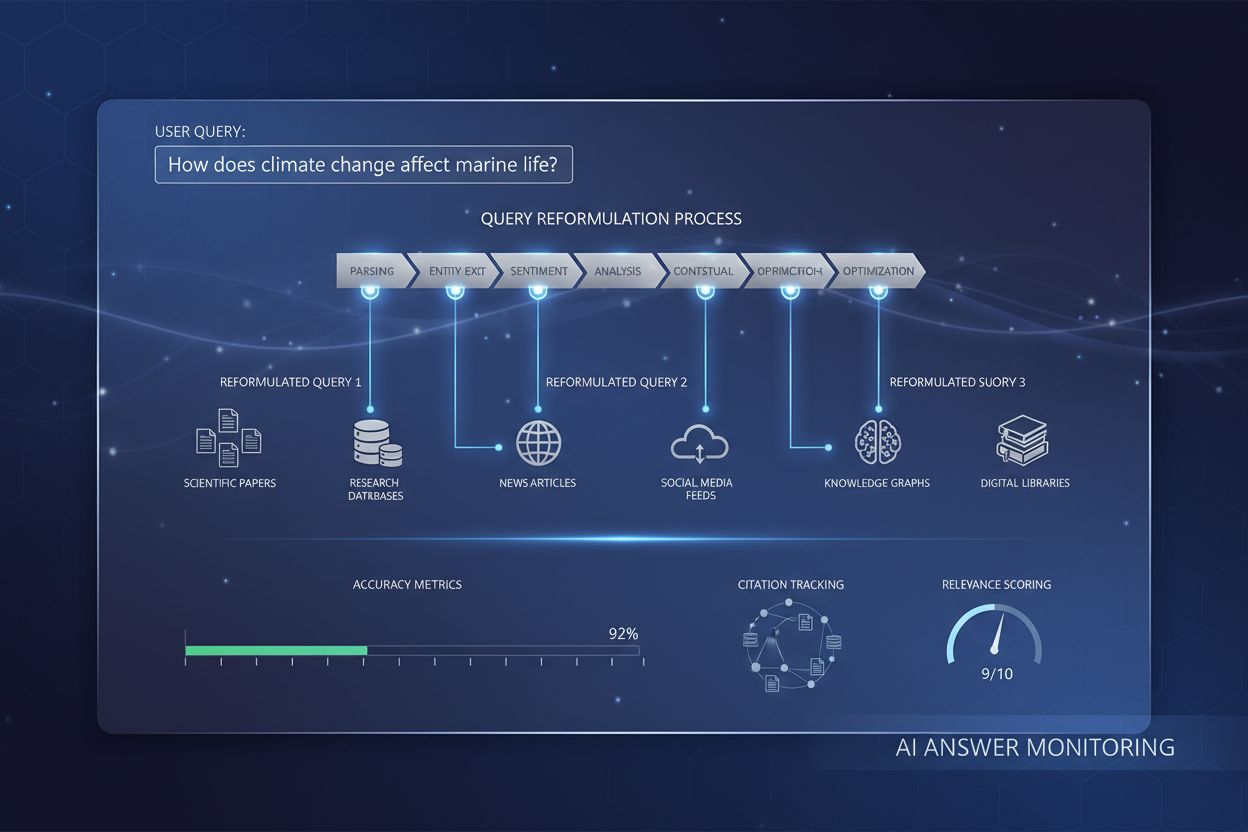
Query-Reformulierung
Erfahren Sie, wie die Query-Reformulierung KI-Systemen hilft, Benutzeranfragen zu interpretieren und zu verbessern, um die Informationsbeschaffung zu optimieren...
10 Min. Lesezeit
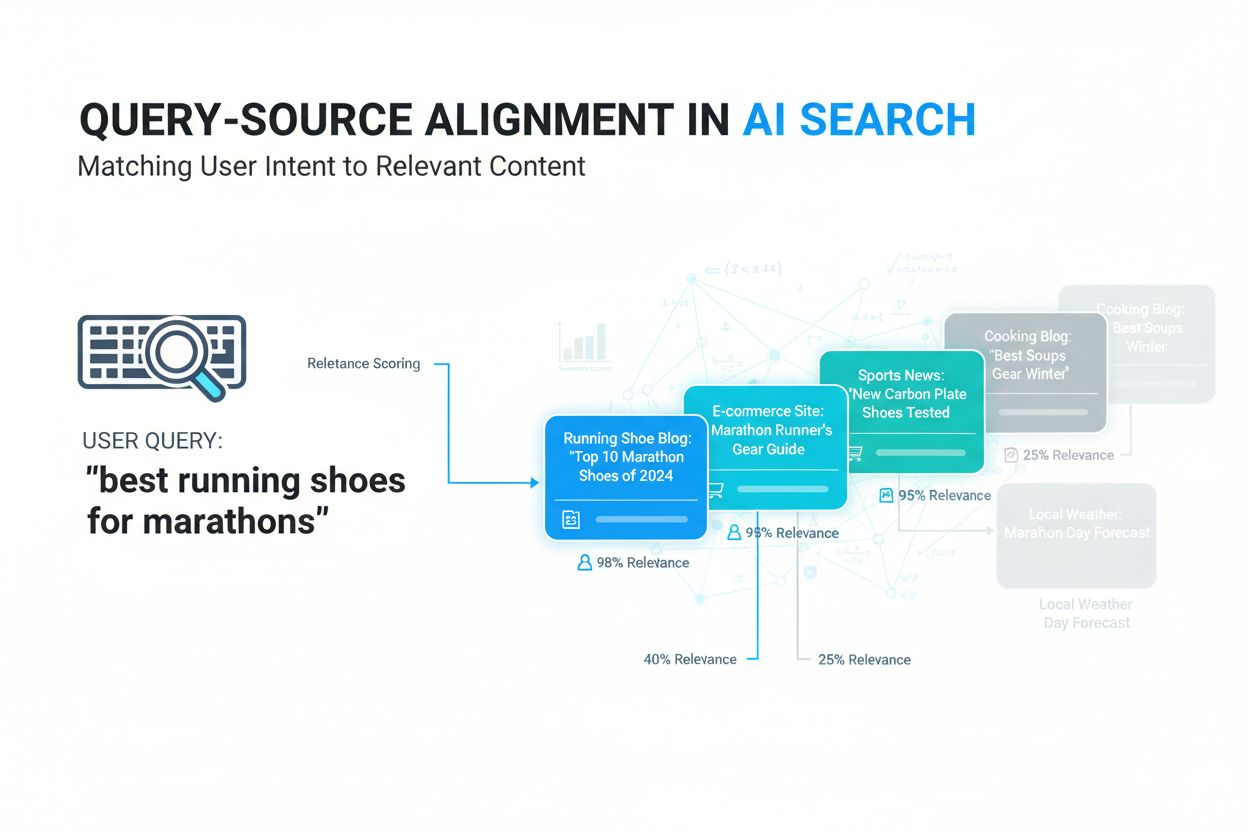
Query-Source-Alignment ist der Prozess, bei dem Benutzeranfragen mit den relevantesten Informationsquellen basierend auf semantischer Bedeutung und kontextueller Relevanz abgeglichen werden. Dabei werden KI und maschinelles Lernen eingesetzt, um die Intention hinter Suchanfragen zu verstehen und sie mit Quellen zu verbinden, die tatsächlich das Informationsbedürfnis der Nutzer erfüllen, anstatt sich nur auf einfaches Keyword-Matching zu verlassen. Diese Technologie bildet die Grundlage moderner KI-Suchsysteme wie Google AI Overviews, ChatGPT und Perplexity. Eine effektive Ausrichtung stellt sicher, dass KI-Systeme präzise und relevante Ergebnisse liefern, die die Nutzerzufriedenheit und die Sichtbarkeit von Inhalten verbessern.
Query-Source-Alignment ist der Prozess, bei dem Benutzeranfragen mit den relevantesten Informationsquellen basierend auf semantischer Bedeutung und kontextueller Relevanz abgeglichen werden. Dabei werden KI und maschinelles Lernen eingesetzt, um die Intention hinter Suchanfragen zu verstehen und sie mit Quellen zu verbinden, die tatsächlich das Informationsbedürfnis der Nutzer erfüllen, anstatt sich nur auf einfaches Keyword-Matching zu verlassen. Diese Technologie bildet die Grundlage moderner KI-Suchsysteme wie Google AI Overviews, ChatGPT und Perplexity. Eine effektive Ausrichtung stellt sicher, dass KI-Systeme präzise und relevante Ergebnisse liefern, die die Nutzerzufriedenheit und die Sichtbarkeit von Inhalten verbessern.
Query-Source-Alignment bezeichnet den Prozess, bei dem Benutzeranfragen mit den relevantesten Informationsquellen auf der Grundlage von semantischer Bedeutung und kontextueller Relevanz abgeglichen werden – und nicht nur über eine einfache Keyword-Überschneidung. Im Kern steht dahinter die grundlegende Herausforderung der Informationsbeschaffung: Sicherzustellen, dass die Suchergebnisse nicht nur technisch mit den Suchbegriffen verwandt sind, sondern das tatsächliche Informationsbedürfnis der Nutzer adressieren.
Traditionell basierten Suchsysteme auf Keyword-Matching – sie fanden Dokumente, die genau die eingegebenen Wörter oder Phrasen enthielten. Dieser Ansatz war zwar einfach, führte aber oft zu irrelevanten Treffern, da Kontext, Intention und die tiefere Bedeutung von Anfragen ignoriert wurden. Query-Source-Alignment löst dieses Problem durch semantische Matching-Techniken, die die konzeptionelle Beziehung zwischen Nutzeranfrage und Informationsquelle verstehen. So kann eine Suche nach „Fahrzeugwartung“ effektiv Artikel über „Autopflege“ oder „Autoservice“ liefern, auch wenn keine exakten Keywords übereinstimmen.
Gerade im Kontext moderner KI-Suchsysteme gewinnt Query-Source-Alignment an Bedeutung, da künstliche Intelligenz eine immer differenziertere Sprach- und Intentionserkennung ermöglicht. Anfragen werden nicht mehr als bloße Wortansammlungen behandelt – KI-gestützte Systeme analysieren den semantischen Gehalt sowohl der Nutzerfrage als auch der verfügbaren Quellen und schaffen so sinnvolle Verbindungen auf Basis von Relevanz statt oberflächlicher Ähnlichkeit.
Diese Unterscheidung ist wesentlich, weil sie die Suchqualität und Nutzerzufriedenheit direkt beeinflusst. Effektives Query-Source-Alignment sorgt dafür, dass Suchsysteme tatsächlich hilfreiche Antworten liefern, irrelevante Ergebnisse reduzieren und Nutzern Informationen zugänglich machen, die sie mit klassischen Keyword-Strategien nicht gefunden hätten. Mit dem Fortschritt der KI-Suchtechnologie bleibt Query-Source-Alignment ein Eckpfeiler für Systeme, die Nutzerbedürfnisse wirklich verstehen und bedienen.
Der technische Ablauf des Query-Source-Alignment umfasst mehrere anspruchsvolle Schritte, um Nutzeranfragen mit relevanten Quellen sinnvoll zu verbinden:
Anfrageverarbeitung und Tokenisierung – Bei Absenden einer Suchanfrage zerlegt das System diese zunächst in einzelne Token (Wörter und Phrasen) und analysiert die grammatikalische Struktur. Algorithmen der natürlichen Sprachverarbeitung identifizieren Kernthemen, Entitäten und die Intention hinter der Anfrage, entfernen Füllwörter und extrahieren die wichtigsten Komponenten für den Alignment-Prozess.
Generierung von Query-Embeddings – Die verarbeitete Anfrage wird in einen semantischen Vektor umgewandelt – eine mathematische Repräsentation, die Bedeutung und Kontext der Anfrage im mehrdimensionalen Raum abbildet. Dieses Embedding entsteht mithilfe neuronaler Sprachmodelle, die auf umfangreichen Textdaten trainiert wurden. So wird das semantische Wesen der Anfrage erfasst, nicht nur die exakten Wörter.
Vektorisierung der Quelldokumente – Gleichzeitig werden alle verfügbaren Quelldokumente im System mit demselben Embedding-Modell in semantische Vektoren umgewandelt. Dadurch stehen Anfragen und Quellen im selben semantischen Raum und können direkt verglichen werden. Jeder Dokumentenvektor spiegelt die Gesamtaussage, Themen und Relevanzsignale des Inhalts wider.
Berechnung der Vektorähnlichkeit – Das System berechnet die Ähnlichkeit zwischen dem Query-Vektor und jedem Dokumentenvektor mithilfe mathematischer Distanzmetriken, meist Kosinus-Ähnlichkeit. So wird ermittelt, wie eng die semantische Bedeutung der Quelle mit der Anfrage übereinstimmt – das Ergebnis ist ein Ähnlichkeitswert zwischen 0 und 1.
Relevanzbewertung und Ranking – Zusätzlich zur semantischen Ähnlichkeit berücksichtigt das System weitere Rankingfaktoren wie Domain-Autorität, Aktualität der Inhalte, Nutzerinteraktionsmetriken und thematische Relevanz. Diese Faktoren werden mit den Ähnlichkeitswerten kombiniert und ergeben einen umfassenden Relevanzscore, der die Platzierung in den Suchergebnissen bestimmt.
Validierung des Content-Matchings – Das System prüft, ob die ausgewählten Quellen tatsächlich relevante Informationen enthalten, indem spezifische Abschnitte des Inhalts analysiert werden. So wird sichergestellt, dass Quellen nicht nur wegen passender Keywords hochrangieren, sondern weil sie das Informationsbedürfnis der Nutzer mit substanziellem, präzisem Content abdecken.
Endauswahl und Ranking der Quellen – Die am besten platzierten Quellen werden dem Nutzer angezeigt oder als Zitate in KI-generierten Antworten verwendet. Das finale Ranking spiegelt die kombinierte Bewertung von semantischer Ausrichtung, Autorität, Relevanz und Inhaltsqualität wider – so erhalten Nutzer die passendsten Quellen zu ihrer spezifischen Anfrage.
| Methode/Ansatz | Funktionsweise | Vorteile | Nachteile | Beste Anwendung |
|---|---|---|---|---|
| Keyword-Matching (traditionell) | Sucht nach exakten Wörtern oder Phrasen in Dokumenten; Ranking nach Häufigkeit und Position | Einfach zu implementieren; schnelle Verarbeitung; transparente Logik | Ignoriert Kontext und Intention; viele irrelevante Ergebnisse; Probleme bei Synonymen | Einfache, faktenbasierte Suchanfragen; Altsysteme |
| Semantische Ähnlichkeit (vektorbasiert) | Wandelt Anfragen und Dokumente in semantische Vektoren um; berechnet Ähnlichkeit mittels Distanzmetriken | Versteht Bedeutung über Keywords hinaus; behandelt Synonyme und Kontext; sehr genau | Rechenintensiv; benötigt große Trainingsdatensätze; weniger transparent | Komplexe Anfragen; Intent-gesteuerte Suche; moderne KI-Systeme |
| Entity Recognition | Erkennt und klassifiziert Entitäten (Personen, Orte, Organisationen, Produkte) in Anfragen und Inhalten | Bessere Themenverständnis; disambiguiert Begriffe; ermöglicht Knowledge-Graph-Integration | Bedarf großer Entitätsdatenbanken; Probleme bei neuen oder Nischenthemen | Anfragen zu spezifischen Entitäten; wissensbasierte Suche |
| Kontextuelles Verständnis | Analysiert Kontext, Nutzerhistorie und Anfragemuster zur Sinnermittlung | Erfasst nuancierte Intention; personalisierte Ergebnisse; besser bei mehrdeutigen Anfragen | Datenschutzprobleme; benötigt Verlaufsdaten; komplexe Implementierung | Konversationelle Suche; personalisierte Empfehlungen |
| Hybridansatz | Kombiniert mehrere Methoden (semantische Ähnlichkeit, Entity Recognition, Kontextanalyse) für umfassendes Matching | Nutzt Vorteile verschiedener Methoden; robuster und genauer; für diverse Anfragen geeignet | Komplex in Entwicklung und Wartung; höherer Rechenaufwand; schwerer zu debuggen | Enterprise Search; KI-Suchplattformen |
| Knowledge-Graph-basiert | Nutzt verknüpfte Entitäten und Beziehungen zur Query- und Quellenauswertung | Erfasst reale Zusammenhänge; ermöglicht komplexes Schließen; unterstützt anspruchsvolle Anfragen | Aufwendig in Aufbau und Pflege; domänenspezifisch | Komplexe Rechercheanfragen; Semantic-Web-Anwendungen |
Query-Source-Alignment ist das Fundament moderner KI-Suchsysteme und entscheidet, welche Quellen für Antworten ausgewählt werden:
Google AI Overviews – Nutzt Query-Source-Alignment, um die relevantesten Quellen für KI-gestützte Suchzusammenfassungen zu bestimmen. Das System analysiert die semantische Ausrichtung zwischen Nutzeranfrage und Webseiten, wobei Quellen mit hoher semantischer Relevanz und Autorität bevorzugt werden. Studien zeigen, dass rund 70 % der Quellen in AI Overviews aus den Top-10-Suchergebnissen stammen – traditionelles Ranking und semantisches Alignment greifen ineinander.
ChatGPT mit Browsing – Ist das Browsing-Feature aktiviert, nutzt ChatGPT Query-Source-Alignment, um die relevantesten Webseiten für Nutzerfragen zu identifizieren und abzurufen. Autoritative Quellen mit starker semantischer Ausrichtung werden priorisiert, sodass die Antworten auf zuverlässigen und relevanten Informationen basieren.
Perplexity AI – Setzt Query-Source-Alignment zur Auswahl von Quellen für konversationelle Antworten ein. Das System zeigt die zitierten Quellen direkt an, wodurch der Alignment-Prozess für Nutzer nachvollziehbar wird. Starke semantische Ausrichtung sorgt für fundierte, überprüfbare Antworten.
Bing AI Chat – Verwendet Query-Source-Alignment, um Suchergebnisse in Konversationsantworten zu integrieren. Das System gleicht Anfragen semantisch mit Bing-Suchergebnissen ab und kombiniert Informationen aus mehreren passenden Quellen zu kohärenten Antworten.
Core-Source-Konzept – KI-Systeme identifizieren „Core Sources“ – URLs, die wiederholt in Antworten zu verwandten Anfragen erscheinen. Diese Quellen sind besonders stark semantisch ausgerichtet und gelten als sehr autoritativ. Das Ziel, für Nischenanfragen als Core Source zu gelten, ist entscheidend für Sichtbarkeit.
Semantisches Relevanz-Scoring – KI-Plattformen vergeben Relevanz-Scores basierend darauf, wie gut der Inhalt einer Quelle semantisch zur Nutzeranfrage passt. Quellen mit höheren Alignment-Scores werden bevorzugt ausgewählt, zitiert und prominent in KI-Antworten platziert.
Multi-Query-Alignment – KI-Systeme zerlegen Anfragen oft in mehrere Unteranfragen. Query-Source-Alignment wird auf jede dieser Subqueries angewandt, und Quellen, die zu mehreren Teilanfragen passen, werden bevorzugt – für umfassende, gut belegte Antworten.
AmICited Monitoring – AmICited verfolgt Query-Source-Alignment, indem überwacht wird, welche eigenen Seiten als Quellen für spezifische Anfragen auf KI-Plattformen ausgewählt werden. Das Tool zeigt Alignment-Scores, Core-Source-Status und Optimierungspotenziale für wichtige Nischenanfragen.
Balance zwischen Autorität und Semantik – Obwohl Domain-Autorität weiterhin wichtig ist, gewinnen semantische Ausrichtung und Relevanz an Gewicht. Quellen mit starker semantischer Ausrichtung, aber mittlerer Autorität, können solche mit hoher Autorität, aber schwacher Ausrichtung überholen – Bedeutung zählt genauso wie Reputation.
Echtzeit-Alignment-Tracking – Moderne KI-Monitoring-Plattformen verfolgen, wie sich Query-Source-Alignment im Zeitverlauf mit Inhaltsaktualisierungen und neuen Quellen entwickelt. So können Marketer nachvollziehen, welche Updates die Ausrichtung verbessern und welche Anfragen die besten Sichtbarkeitschancen bieten.
Das Verständnis und die Optimierung des Query-Source-Alignment sind für Content-Ersteller, Marketer und Marken im Zeitalter der KI-Suche essenziell:
Brand-Citation-Tracking – Query-Source-Alignment entscheidet direkt, ob Ihre Marke und Ihre Inhalte in KI-generierten Antworten zitiert werden. Plattformen wie AmICited überwachen diese Ausrichtung und zeigen, für welche Anfragen Ihre Inhalte in KI-Antworten ranken und wie oft Ihre Marke auf KI-Plattformen erwähnt wird.
Semantische Relevanz & Discovery – Starke semantische Ausrichtung auf Nutzeranfragen erhöht die Wahrscheinlichkeit, dass Ihre Inhalte von KI-Systemen gefunden und zitiert werden. Das ist besonders für Long-Tail- und Nischenthemen wichtig, bei denen klassische SEO-Konkurrenz gering, semantische Relevanz aber entscheidend ist.
Wettbewerbsvorteil in der KI-Suche – Mit zunehmender Bedeutung der KI-Suche erzielen Marken mit starker Query-Source-Alignment für wertvolle Anfragen erhebliche Wettbewerbsvorteile. Wer früh für semantische Ausrichtung optimiert, sichert sich Sichtbarkeit, bevor Wettbewerber ihre Strategien anpassen.
Quellen-Tracking & Attribution – Query-Source-Alignment zeigt, welche Ihrer Seiten für welche Anfragen als Quelle ausgewählt werden. Diese Attributionsdaten zeigen, welche Inhalte in KI-Antworten am besten performen und in welchen Themenbereichen Verbesserungspotenzial besteht.
Optimierung für KI-Antworten – Moderne Content-Strategien müssen Query-Source-Alignment berücksichtigen, nicht nur traditionelle Suchrankings. Inhalte, die im klassischen SEO gut ranken, aber schwache semantische Ausrichtung haben, werden von KI-Systemen oft nicht ausgewählt – Sichtbarkeitspotenziale bleiben ungenutzt.
Risikominderung & Markensteuerung – Monitoring von Query-Source-Alignment hilft zu verstehen, wie die eigene Marke in KI-Antworten präsentiert wird. Haben Wettbewerber eine stärkere Ausrichtung für wichtige Anfragen, können Sie gezielt Content schaffen, der die Nutzerintention besser trifft.
Content-Strategie-Optimierung – Alignment-Metriken zeigen, welche Themen, Keywords und Formate bei KI-Systemen besonders gut ankommen. Das ermöglicht eine gezielte Content-Strategie auf Bereiche mit hoher semantischer Ausrichtung und Mehrwert.
Wettbewerbsanalyse – Durch die Analyse des Query-Source-Alignment in der eigenen Branche lässt sich erkennen, welche Wettbewerber am häufigsten in KI-Antworten zitiert werden. So lassen sich Content-Lücken und Chancen für mehr Sichtbarkeit identifizieren.
Langfristige Sichtbarkeitsplanung – Query-Source-Alignment ist stabiler als klassische Suchrankings, da es auf semantischer Bedeutung basiert und weniger von häufigen Algorithmusänderungen abhängt. Starke semantische Ausrichtung sorgt für nachhaltige Sichtbarkeit in der KI-Suche.
Messbarer Content-ROI – Durch Tracking des Query-Source-Alignment und der daraus resultierenden Sichtbarkeit in KI-Antworten lassen sich Content-Investitionen direkt an Markenzitierungen und Traffic durch KI-Suchplattformen messen.
Die Optimierung für Query-Source-Alignment erfordert eine strategische Herangehensweise, die über klassisches SEO hinausgeht. Ziel ist es, Inhalte mit starker semantischer Ausrichtung auf die Suchanfragen der Zielgruppe zu schaffen, damit KI-Systeme sie als relevante Quellen auswählen.
Semantische Optimierung verstehen – Semantische Optimierung bedeutet, Inhalte zu erstellen, die gezielt auf spezifische Nutzerintentionen und Fragestellungen eingehen – nicht nur auf Keywords. Dazu gehört das Verständnis semantischer Beziehungen zwischen Konzepten, die Verwendung konsistenter Terminologie und die klare Strukturierung von Inhalten für Menschen und KI-Systeme.
Best Practices für Query-Source-Alignment:
Semantische Keyword-Recherche – Gehen Sie über klassische Keyword-Recherche hinaus und identifizieren Sie semantische Cluster verwandter Begriffe und Konzepte. Tools wie SEMrush oder Ahrefs helfen dabei, nicht nur Suchvolumen, sondern auch semantische Varianten und verwandte Anfragen zu finden. Gruppieren Sie diese zu Clustern und erstellen Sie umfassende Inhalte, die alle Varianten abdecken.
Semantisches HTML5-Markup nutzen – Strukturieren Sie Inhalte mit HTML5-Elementen wie <article>, <section>, <header>, <nav> und <main>. Diese helfen KI-Systemen, Aufbau und Hierarchie zu verstehen. Verwenden Sie Überschriften-Tags (<h1>, <h2> usw.) hierarchisch, um Themenbeziehungen klar darzustellen.
Entitätenreiche Inhalte erstellen – Identifizieren Sie zentrale Entitäten (Personen, Organisationen, Produkte, Konzepte) für Ihr Thema und benennen Sie sie explizit. Verwenden Sie konsistente Begriffe und bieten Kontext, damit KI-Systeme die Bedeutung erfassen. Beispielsweise sollte bei „Apple“ durch Kontext klar werden, ob das Unternehmen oder die Frucht gemeint ist.
Strukturierte Daten (JSON-LD) verwenden – Implementieren Sie schema.org-Markup im JSON-LD-Format, um explizite semantische Informationen bereitzustellen. Nutzen Sie passende Schema-Typen wie Article, NewsArticle, HowTo, FAQPage oder Product. So erkennen KI-Systeme, worum es auf Ihrer Seite geht und wie sie zu Nutzeranfragen passt.
Auf Suchintentionen optimieren – Identifizieren Sie verschiedene Formulierungen für das gleiche Nutzerbedürfnis und erstellen Sie Inhalte, die alle Varianten abdecken. Suchen Nutzer z. B. nach „Wie repariere ich einen tropfenden Wasserhahn“, „Wasserhahn Reparatur Anleitung“ oder „Lösung für undichten Hahn“, sollte Ihr Guide alle Varianten mit konsistenter Bedeutung behandeln.
Umfassende Themenabdeckung – Statt vieler kurzer Artikel zu ähnlichen Themen lieber umfassende Guides erstellen, die die Thematik vollumfänglich abdecken. KI-Systeme bevorzugen tiefgehende Inhalte, die Nutzerfragen vollständig beantworten. Clustern Sie Themen, um alle Aspekte mit starker semantischer Beziehung zu behandeln.
Konsistente Terminologie verwenden – Bleiben Sie bei Begriffen einheitlich – sowohl im einzelnen Artikel als auch über die gesamte Website hinweg. Wenn Sie ein Konzept mit einem bestimmten Begriff einführen, verwenden Sie ihn konsequent statt Synonyme zu mischen. Das erleichtert KI-Systemen die Erkennung gleichbleibender Inhalte.
Klare Content-Hierarchien schaffen – Strukturieren Sie Inhalte mit klaren Hierarchien, die Beziehungen zwischen Konzepten abbilden. Überschriften, Listen und Nummerierungen helfen KI-Systemen, die semantische Organisation und Zusammenhänge zu erkennen.
Meta-Descriptions und Titel optimieren – Verfassen Sie Meta-Descriptions und Seitentitel, die die semantische Aussage der Seite klar transportieren. Diese Elemente werden oft von KI-Systemen zur Inhaltserkennung genutzt, also sollten sie das Hauptthema und zentrale Begriffe enthalten.
Semantic-Alignment-Scores überwachen – Nutzen Sie Plattformen wie AmICited, um Ihre semantischen Alignment-Scores für wichtige Anfragen zu tracken. Überwachen Sie, wie sich das Alignment mit Inhaltsupdates verändert und welche Queries besonders stark ausgerichtet sind – darauf können Sie Ihre Content-Expansion fokussieren.
Praxisbeispiele aus verschiedenen Branchen:
E-Commerce – Ein Onlinehändler für Laufschuhe kann Query-Source-Alignment optimieren, indem er umfassende Guides zu „Marathon-Laufschuhen“, „beste Laufschuhe für verschiedene Fußtypen“ oder „Vergleich von Schuhtechnologien“ anbietet. Durch die Behandlung semantischer Varianten von Nutzerintentionen und konsistente Terminologie steigt die Wahrscheinlichkeit, als Quelle für KI-Antworten zum Thema Laufschuhe ausgewählt zu werden.
Gesundheitswesen – Eine Arztpraxis kann ihr Alignment verbessern, indem sie detaillierte Inhalte zu Erkrankungen, Therapien und Ärzten erstellt. Fachterminologie, Entitätenerkennung und strukturierte Daten helfen KI-Systemen, die Inhalte semantisch zu verstehen und mit entsprechenden Suchanfragen zu matchen.
Technologie – Ein Softwareunternehmen optimiert sein Alignment durch umfassende Dokumentationen und Guides, die verschiedene Nutzerprobleme semantisch adressieren. Konsistente Begriffe für Features, klare Hierarchien und strukturierte Daten sorgen dafür, dass KI-Systeme die Inhalte als relevante Quelle für Technologieanfragen erkennen.
Beim traditionellen Keyword-Matching werden einfach die exakten Wörter oder Phrasen in Dokumenten gesucht, während Query-Source-Alignment auf semantisches Verständnis setzt, um Bedeutung und Intention hinter Anfragen abzugleichen. Das bedeutet, dass eine Suche nach 'Fahrzeugwartung' auch Artikel über 'Autopflege' findet, selbst wenn die exakten Keywords nicht vorkommen. Query-Source-Alignment liefert relevantere Ergebnisse, weil Kontext und Nutzerabsicht verstanden werden, nicht nur oberflächliche Wortähnlichkeiten.
KI-Suchplattformen nutzen Query-Source-Alignment, um die relevantesten Quellen für ihre generierten Antworten auszuwählen. Das System analysiert sowohl die semantische Bedeutung der Nutzeranfrage als auch den Inhalt der verfügbaren Quellen und bewertet sie nach Relevanz, Autorität und semantischer Ausrichtung. So wird sichergestellt, dass KI-generierte Antworten auf hochwertigen, relevanten Quellen basieren, die das Informationsbedürfnis der Nutzer tatsächlich abdecken.
Query-Source-Alignment hat direkten Einfluss darauf, ob Ihre Inhalte als Quelle in KI-generierten Antworten ausgewählt werden. Wenn Ihre Inhalte eine starke semantische Übereinstimmung mit gängigen Anfragen in Ihrer Nische aufweisen, ist die Wahrscheinlichkeit höher, dass sie von KI-Systemen zitiert werden. Diese Sichtbarkeit in KI-Antworten bringt Traffic und stärkt die Markenautorität. Das Verständnis und die Optimierung des Query-Source-Alignment sind entscheidend, um im Zeitalter der KI-Suche sichtbar zu bleiben.
Um das Query-Source-Alignment zu verbessern, sollten Sie Inhalte erstellen, die gezielt auf spezifische Nutzerintentionen und Fragen eingehen. Verwenden Sie semantisches HTML-Markup, setzen Sie strukturierte Daten (JSON-LD) ein, sorgen Sie für klare Entitätenerkennung und eine konsistente Terminologie. Schreiben Sie umfassende, lösungsorientierte Inhalte, die Fragen vollständig beantworten. Überwachen Sie Ihre semantischen Alignment-Scores und verfolgen Sie mit Tools wie AmICited, wie Ihre Inhalte in KI-Antworten performen.
Semantische Ähnlichkeit ist der Kernmechanismus des Query-Source-Alignment. Sie misst, wie eng die Bedeutung einer Anfrage mit dem Inhalt einer Quelle übereinstimmt. Dies wird mit Vektor-Embeddings berechnet – mathematischen Textdarstellungen, die semantische Bedeutung erfassen. Quellen mit höheren semantischen Ähnlichkeitswerten zur Anfrage werden höher gerankt und eher von KI-Systemen als relevante Quellen zur Beantwortung von Nutzerfragen ausgewählt.
AmICited ist eine KI-Monitoring-Plattform, die verfolgt, wie Ihre Marke und Ihre Inhalte auf KI-Suchplattformen zitiert werden. Sie überwacht das Query-Source-Alignment, indem sie zeigt, welche Ihrer Seiten als Quellen für bestimmte Anfragen ausgewählt werden, wie oft Ihre Marke in KI-Antworten erwähnt wird und wie Ihre semantische Ausrichtung im Vergleich zu Mitbewerbern abschneidet. Diese Daten helfen Ihnen, Ihre Content-Strategie für bessere Sichtbarkeit in der KI-Suche zu optimieren.
Core Sources sind URLs, die regelmäßig in mehreren KI-generierten Antworten für gleiche oder verwandte Anfragen erscheinen. Diese Quellen weisen eine starke semantische Ausrichtung auf die jeweiligen Themen auf und werden von KI-Systemen als besonders relevant eingestuft. Core Sources rangieren meist auch in den traditionellen Suchergebnissen weit oben und sind inhaltlich eng mit der Nutzerintention verknüpft. Als Core Source für Ihre Nischenanfragen zu gelten, ist ein zentrales Ziel für die Sichtbarkeit in der KI-Suche.
Entity Recognition hilft KI-Systemen, zentrale Konzepte, Personen, Organisationen und Themen sowohl in Anfragen als auch in Inhalten zu erkennen und zu verstehen. Durch das Erkennen von Entitäten können KI-Systeme besser nachvollziehen, worum es in einer Anfrage wirklich geht, und sie mit Quellen abgleichen, die dieselben Entitäten im entsprechenden Kontext behandeln. Zum Beispiel sorgt die Erkennung, dass 'Apple' das Technologieunternehmen und nicht die Frucht meint, dafür, dass Anfragen zu Apple-Produkten mit relevanten Tech-Quellen abgeglichen werden.
Verfolgen Sie, wie Ihre Inhalte auf KI-Suchplattformen zitiert werden, und optimieren Sie Ihr Query-Source-Alignment mit der KI-Monitoring-Plattform von AmICited.
Erfahren Sie, wie die Query-Reformulierung KI-Systemen hilft, Benutzeranfragen zu interpretieren und zu verbessern, um die Informationsbeschaffung zu optimieren...

Query Refinement ist der iterative Prozess der Optimierung von Suchanfragen für bessere Ergebnisse in KI-Suchmaschinen. Erfahren Sie, wie es bei ChatGPT, Perple...

Erfahren Sie, was Query-to-Citation Mapping ist und wie Sie nachverfolgen, welche Suchanfragen Zitate zu Ihrer Marke in KI-generierten Antworten bei ChatGPT, Ge...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.