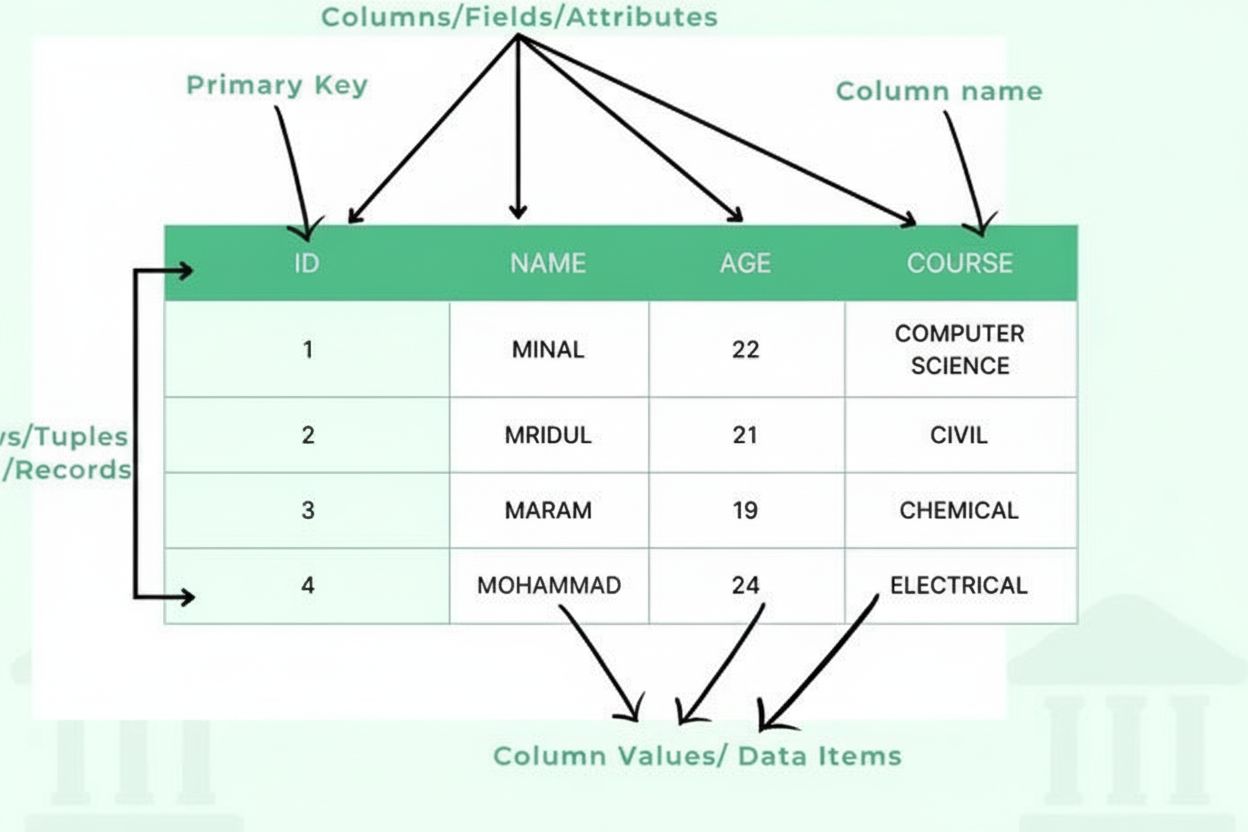
Definition von Tabelle: Organisierte Daten in Zeilen und Spalten
Eine Tabelle ist eine grundlegende Datenstruktur, die Informationen in einem zweidimensionalen Raster mit horizontalen Zeilen und vertikalen Spalten organisiert. In ihrer einfachsten Form stellt eine Tabelle eine Sammlung verwandter Daten dar, die in strukturierter Weise angeordnet sind, wobei jede Schnittstelle von Zeile und Spalte ein einzelnes Datenelement oder eine Zelle enthält. Tabellen dienen als Eckpfeiler relationaler Datenbanken, Tabellenkalkulationen, Data Warehouses und praktisch jedes Systems, das organisierte Informationsspeicherung und -abfrage erfordert. Die Stärke von Tabellen liegt in ihrer Fähigkeit, ein schnelles visuelles Scannen, einen logischen Vergleich von Daten über mehrere Dimensionen hinweg und einen programmatischen Zugriff auf spezifische Informationen durch standardisierte Abfragesprachen zu ermöglichen. Ob in der Geschäftsanalytik, der wissenschaftlichen Forschung oder in KI-Überwachungsplattformen – Tabellen bieten ein universell verstandenes Format zur Darstellung strukturierter Daten, das sowohl von Menschen als auch von Maschinen leicht interpretiert werden kann.
Historischer Kontext und Entwicklung der tabellarischen Datenorganisation
Das Konzept, Informationen in Zeilen und Spalten zu organisieren, existiert bereits seit Jahrhunderten – lange vor der modernen Computertechnik. Alte Zivilisationen verwendeten tabellarische Formate, um Bestände, Finanztransaktionen und astronomische Beobachtungen zu erfassen. Die Formalisierung von Tabellenstrukturen in der Informatik begann jedoch mit der Entwicklung der relationalen Datenbanktheorie durch Edgar F. Codd im Jahr 1970, die die Art und Weise, wie Daten gespeichert und abgefragt werden konnten, revolutionierte. Das relationale Modell legte fest, dass Daten in Tabellen mit klar definierten Beziehungen organisiert werden sollten, was die Prinzipien des Datenbankdesigns grundlegend veränderte. In den 1980er und 1990er Jahren demokratisierten Tabellenkalkulationsprogramme wie Lotus 1-2-3 und Microsoft Excel die Tabellennutzung und machten die tabellarische Datenorganisation auch für nicht-technische Anwender zugänglich. Heute nutzen etwa 97 % der Unternehmen Tabellenkalkulationsprogramme für Datenmanagement und -analyse, was die anhaltende Bedeutung der tabellarischen Datenorganisation zeigt. Die Entwicklung setzt sich fort mit modernen Fortschritten in spaltenbasierten Datenbanken, NoSQL-Systemen und Data Lakes, die traditionelle zeilenorientierte Ansätze herausfordern, dabei aber weiterhin grundlegende, tabellenähnliche Strukturen zur Informationsorganisation beibehalten.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Zentrale Komponenten und Struktur von Tabellen
Eine Tabelle besteht aus mehreren wesentlichen Strukturkomponenten, die gemeinsam einen organisierten Datenrahmen schaffen. Spalten (auch Felder oder Attribute genannt) verlaufen vertikal und repräsentieren Informationskategorien wie „Kundenname“, „E-Mail-Adresse“ oder „Kaufdatum“. Jede Spalte besitzt einen definierten Datentyp, der angibt, welche Art von Informationen sie enthalten kann – Ganzzahlen, Textzeichenfolgen, Daten, Dezimalzahlen oder komplexere Strukturen. Zeilen (auch Datensätze oder Tupel) verlaufen horizontal und stellen einzelne Dateneinträge oder Entitäten dar, wobei jede Zeile einen vollständigen Datensatz enthält. Die Schnittstelle von Zeile und Spalte bildet eine Zelle oder ein Datenelement, das einen einzelnen Informationswert hält. Spaltenüberschriften kennzeichnen jede Spalte und stehen am oberen Rand der Tabelle, um dem darunterliegenden Dateninhalt Kontext zu geben. Primärschlüssel sind spezielle Spalten, die jede Zeile eindeutig identifizieren und so doppelte Datensätze verhindern. Fremdschlüssel stellen Beziehungen zwischen Tabellen her, indem sie Primärschlüssel in anderen Tabellen referenzieren. Diese hierarchische Organisation ermöglicht es Datenbanken, Datenintegrität zu wahren, Redundanzen zu vermeiden und komplexe Abfragen zu unterstützen, die Informationen anhand mehrerer Kriterien abrufen.
Vergleich von Tabellenorganisationsmethoden
| Aspekt | Zeilenorientierte Tabellen | Spaltenorientierte Tabellen | Hybride Ansätze |
|---|
| Speichermethode | Daten werden nach vollständigen Datensätzen gespeichert und abgerufen | Daten werden nach einzelnen Spalten gespeichert und abgerufen | Vereint Vorteile beider Ansätze |
| Abfrageleistung | Für transaktionale Abfragen mit vollständigen Datensätzen optimiert | Für analytische Abfragen auf spezifischen Spalten optimiert | Ausgewogene Leistung für gemischte Workloads |
| Anwendungsfälle | OLTP (Online Transaction Processing), Geschäftsprozesse | OLAP (Online Analytical Processing), Data Warehousing | Echtzeit-Analytik, operative Intelligenz |
| Beispiele für Datenbanken | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Kompressionseffizienz | Geringere Kompressionsraten durch Datenvielfalt | Höhere Kompressionsraten bei ähnlichen Spaltenwerten | Optimierte Kompression für spezifische Muster |
| Schreibleistung | Schnelle Schreibvorgänge bei vollständigen Datensätzen | Langsamere Schreibvorgänge durch Spaltenaktualisierungen | Ausgewogene Schreibleistung |
| Skalierbarkeit | Skaliert gut bei Transaktionsvolumen | Skaliert gut bei Datenmenge und Abfragekomplexität | Skaliert in beiden Dimensionen |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technische Implementierung und Datenbankarchitektur
In relationalen Datenbankmanagementsystemen (RDBMS) werden Tabellen als strukturierte Sammlungen von Zeilen implementiert, wobei jede Zeile einem vordefinierten Schema entspricht. Das Schema definiert die Struktur der Tabelle, einschließlich Spaltennamen, Datentypen, Einschränkungen und Beziehungen. Wenn Daten in eine Tabelle eingefügt werden, prüft das Datenbankmanagementsystem, ob jeder Wert zum Datentyp seiner Spalte passt und alle definierten Einschränkungen erfüllt. Zum Beispiel akzeptiert eine als INTEGER definierte Spalte keine Textwerte, und eine als NOT NULL markierte Spalte lässt keine leeren Einträge zu. Indizes werden auf häufig abgefragten Spalten erstellt, um die Datenabfrage zu beschleunigen. Sie fungieren als organisierte Verweise, mit denen die Datenbank bestimmte Zeilen finden kann, ohne die gesamte Tabelle durchsuchen zu müssen. Normalisierung ist ein Gestaltungsprinzip, das Tabellen so organisiert, dass Datenredundanz minimiert und Datenintegrität verbessert werden, indem Informationen in verwandte Tabellen aufgeteilt werden, die über Schlüssel miteinander verbunden sind. Moderne Datenbanken unterstützen Transaktionen, die sicherstellen, dass mehrere Operationen an Tabellen entweder alle erfolgreich sind oder alle gemeinsam scheitern, wodurch die Konsistenz auch bei Systemausfällen gewahrt bleibt. Der Query-Optimizer in Datenbank-Engines analysiert SQL-Abfragen und bestimmt den effizientesten Weg, auf Tabellendaten zuzugreifen, wobei vorhandene Indizes und Tabellenstatistiken berücksichtigt werden.
Datenpräsentation und Visualisierung in Tabellen
Tabellen dienen als primärer Mechanismus zur Präsentation strukturierter Daten für Benutzer – sowohl digital als auch in gedruckter Form. In Business-Intelligence- und Analyseanwendungen zeigen Tabellen aggregierte Kennzahlen, Leistungsindikatoren und detaillierte Transaktionsdaten, die Entscheidungsträgern ermöglichen, komplexe Datensätze auf einen Blick zu erfassen. Untersuchungen zeigen, dass 83 % der Geschäftsleute Datentabellen als ihr Hauptwerkzeug für die Informationsanalyse nutzen, da Tabellen einen präzisen Wertvergleich und die Erkennung von Mustern ermöglichen. HTML-Tabellen auf Websites verwenden semantisches Markup mit <table>, <tr> (Tabellenzeile), <td> (Tabellendaten) und <th> (Tabellenüberschrift), um Daten sowohl für die visuelle Darstellung als auch für die programmatische Interpretation zu strukturieren. Tabellenkalkulationsprogramme wie Microsoft Excel, Google Sheets und LibreOffice Calc erweitern die Grundfunktionalität von Tabellen mit Formeln, bedingter Formatierung und Pivot-Tabellen, die es Benutzern ermöglichen, Berechnungen durchzuführen und Daten dynamisch umzustrukturieren. Best Practices für die Datenvisualisierung empfehlen die Verwendung von Tabellen, wenn exakte Werte wichtiger sind als visuelle Muster, wenn mehrere Attribute einzelner Datensätze verglichen werden oder wenn Nutzer Nachschlagen oder Berechnungen durchführen müssen. Die W3C Web Accessibility Initiative betont, dass korrekt strukturierte Tabellen mit klaren Überschriften und geeignetem Markup unerlässlich sind, um Daten für Menschen mit Behinderungen, insbesondere für Screenreader-Nutzer, zugänglich zu machen.
Tabellen im KI-Monitoring und Content-Tracking
Im Kontext von KI-Überwachungsplattformen wie AmICited spielen Tabellen eine Schlüsselrolle bei der Organisation und Präsentation von Daten darüber, wie Inhalte in verschiedenen KI-Systemen erscheinen. Überwachungstabellen verfolgen Kennzahlen wie Zitierhäufigkeit, Erscheinungsdaten, KI-Plattform-Quellen (ChatGPT, Perplexity, Google AI Overviews, Claude) und Kontextinformationen darüber, wie Domains und URLs referenziert werden. Diese Tabellen ermöglichen es Organisationen, ihre Markensichtbarkeit in KI-generierten Antworten zu verstehen und Trends zu erkennen, wie verschiedene KI-Systeme ihre Inhalte zitieren oder referenzieren. Die strukturierte Natur von Überwachungstabellen erlaubt das Filtern, Sortieren und Aggregieren von Zitierungsdaten, sodass sich Fragen beantworten lassen wie: „Welche unserer URLs erscheinen am häufigsten in Perplexity-Antworten?“ oder „Wie hat sich unsere Zitierungsrate im letzten Monat verändert?“ Datentabellen in Monitoring-Systemen ermöglichen auch Vergleiche über mehrere Dimensionen hinweg – etwa beim Vergleich von Zitierungsmustern zwischen verschiedenen KI-Plattformen, bei der Analyse des Zitierungswachstums im Zeitverlauf oder bei der Identifikation von Content-Typen mit den meisten KI-Referenzen. Die Möglichkeit, Überwachungsdaten aus Tabellen in Berichte, Dashboards und weitere Analysetools zu exportieren, macht Tabellen für Organisationen, die ihre Präsenz in KI-generierten Inhalten verstehen und optimieren möchten, unverzichtbar.
Best Practices für das Design und die Organisation von Tabellen
Effektives Tabellendesign erfordert eine sorgfältige Überlegung hinsichtlich Struktur, Namenskonventionen und Prinzipien der Datenorganisation. Spaltenbenennungen sollten klare, aussagekräftige Bezeichnungen verwenden, die den enthaltenen Daten genau entsprechen, und Abkürzungen vermeiden, die Nutzer oder Entwickler verwirren könnten. Die Auswahl des Datentyps ist entscheidend – die Wahl geeigneter Typen verhindert ungültige Dateneingaben und ermöglicht korrektes Sortieren und Vergleichen. Die Definition eines Primärschlüssels stellt sicher, dass jede Zeile eindeutig identifiziert werden kann, was für die Datenintegrität und das Herstellen von Beziehungen zu anderen Tabellen essenziell ist. Normalisierung reduziert Redundanzen, indem Informationen in verwandte Tabellen organisiert werden, anstatt doppelte Daten an mehreren Orten zu speichern. Die Indexierungsstrategie sollte das Gleichgewicht zwischen Abfrageleistung und dem Mehraufwand für die Indexpflege bei Datenänderungen berücksichtigen. Dokumentation der Tabellenstruktur, einschließlich Spaltendefinitionen, Datentypen, Einschränkungen und Beziehungen, ist für die langfristige Wartbarkeit unerlässlich. Zugriffskontrolle sollte implementiert werden, um sicherzustellen, dass sensible Daten in Tabellen vor unbefugtem Zugriff geschützt sind. Performance-Optimierung beinhaltet das Überwachen von Abfrageausführungszeiten und das Anpassen von Tabellenstrukturen, Indizes oder Abfragen zur Effizienzsteigerung. Backup- und Wiederherstellungsverfahren müssen eingerichtet werden, um Tabellendaten vor Verlust oder Beschädigung zu schützen.
Wesentliche Aspekte der Tabellenorganisation und -verwaltung
- Strukturelle Komponenten: Tabellen bestehen aus Spalten (Felder), Zeilen (Datensätze), Überschriften, Datenelementen (Zellen), Datentypen, Primärschlüsseln und Fremdschlüsseln, die gemeinsam organisierte Datenstrukturen schaffen
- Datenintegrität: Einschränkungen, Validierungsregeln und Schlüsselbeziehungen gewährleisten Datenkorrektheit und verhindern Inkonsistenzen oder doppelte Datensätze
- Abfrageeffizienz: Geeignete Indizierung, Normalisierung und Abfrageoptimierung ermöglichen den schnellen Zugriff auf spezifische Informationen aus großen Tabellen
- Barrierefreiheit: Semantisches HTML-Markup, klare Überschriften und eine ordentliche Struktur machen Tabellen für Menschen mit Behinderungen und assistiven Technologien zugänglich
- Skalierbarkeit: Gut gestaltete Tabellen können durch geeignete Indizierung, Partitionierung und Datenbankoptimierungstechniken wachsende Datenmengen effizient verarbeiten
- Beziehungsmanagement: Fremdschlüssel stellen Verbindungen zwischen Tabellen her und ermöglichen komplexe Abfragen, die Informationen aus mehreren Quellen kombinieren
- Durchsetzung von Datentypen: Definierte Datentypen stellen sicher, dass nur gültige Informationen in jeder Spalte gespeichert werden, vermeiden Fehler und ermöglichen korrektes Sortieren
- Dokumentation und Wartung: Klare Dokumentation der Tabellenstruktur und regelmäßige Wartung sichern langfristige Nutzbarkeit und Leistung
Entwicklung und Zukunft der tabellenbasierten Datenorganisation
Die Zukunft der tabellenbasierten Datenorganisation entwickelt sich weiter, um zunehmend komplexe Datenanforderungen zu erfüllen, während die grundlegenden Prinzipien, die Tabellen effektiv machen, erhalten bleiben. Spaltenorientierte Speicherformate wie Apache Parquet und ORC werden zum Standard in Big-Data-Umgebungen und optimieren Tabellen für analytische Workloads bei gleichzeitig tabellarischer Struktur. Semistrukturierte Daten in JSON- und XML-Formaten werden zunehmend in Tabellenspalten gespeichert, sodass Tabellen sowohl strukturierte als auch flexible Daten aufnehmen können. Maschinelles Lernen wird integriert und ermöglicht es Datenbanken, Tabellenstrukturen und Abfrageausführung automatisch anhand von Nutzungsmustern zu optimieren. Echtzeit-Analyseplattformen erweitern Tabellen, um Streaming-Daten und kontinuierliche Aktualisierungen zu unterstützen und gehen damit über traditionelle, batchorientierte Tabellenoperationen hinaus. Cloud-native Datenbanken gestalten Tabellenimplementierungen neu, um verteiltes Rechnen zu nutzen und Tabellen über mehrere Server und Regionen hinweg skalierbar zu machen. Data-Governance-Rahmenwerke legen verstärkt Wert auf Tabellenmetadaten, Herkunftsnachweise und Qualitätsmetriken, um Datenzuverlässigkeit sicherzustellen. Das Aufkommen von KI-gestützten Datenplattformen eröffnet neue Möglichkeiten, Tabellen als strukturierte Quellen für das Training von Machine-Learning-Modellen zu nutzen, wirft aber auch neue Fragen zur Gestaltung von Tabellen als hochwertige Trainingsdatenquelle auf. Da Organisationen weiterhin exponentiell mehr Daten generieren, bleiben Tabellen die grundlegende Struktur für Organisation, Abfrage und Analyse von Informationen – mit Innovationen, die auf Leistungssteigerung, Skalierbarkeit und Integration mit modernen Datentechnologien abzielen.