Auditoría de Acceso de Crawlers de IA: ¿Los Bots Correctos Ven Tu Contenido?
Aprende cómo auditar el acceso de crawlers de IA a tu sitio web. Descubre qué bots pueden ver tu contenido y corrige los bloqueos que impiden la visibilidad de la IA en ChatGPT, Perplexity y otros motores de búsqueda de IA.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
El panorama de la búsqueda y el descubrimiento de contenido está cambiando drásticamente. Con herramientas de búsqueda impulsadas por IA como ChatGPT, Perplexity y Google AI Overviews creciendo exponencialmente, la visibilidad de tu contenido para los crawlers de IA se ha vuelto tan crítica como el SEO tradicional. Si los bots de IA no pueden acceder a tu contenido, tu sitio se vuelve invisible para millones de usuarios que dependen de estas plataformas para obtener respuestas. Las apuestas nunca han sido tan altas: mientras que Google podría volver a visitar tu sitio si algo sale mal, los crawlers de IA operan bajo un paradigma diferente—y perder ese primer rastreo crítico puede significar meses de visibilidad perdida y oportunidades perdidas de citas, tráfico y autoridad de marca.
Cómo se Diferencian los Crawlers de IA de los Bots Tradicionales
Los crawlers de IA operan bajo reglas fundamentalmente diferentes a las de los bots de Google y Bing para los que has optimizado durante años. La diferencia más crítica: los crawlers de IA no renderizan JavaScript, lo que significa que el contenido dinámico cargado mediante scripts del lado del cliente es invisible para ellos—un marcado contraste con las sofisticadas capacidades de renderizado de Google. Además, los crawlers de IA visitan los sitios con una frecuencia mucho mayor, a veces 100 veces más a menudo que los motores de búsqueda tradicionales, lo que crea tanto oportunidades como desafíos para los recursos del servidor. A diferencia del modelo de indexación de Google, los crawlers de IA no mantienen un índice persistente que se actualiza; en su lugar, rastrean bajo demanda cuando los usuarios consultan sus sistemas. Esto significa que no hay una cola de reindexación, no hay Search Console para solicitar un nuevo rastreo y no hay segundas oportunidades si tu sitio falla en esa primera impresión. Comprender estas diferencias es esencial para optimizar tu estrategia de contenido.
Característica
Crawlers de IA
Bots Tradicionales
Renderizado de JavaScript
No (solo HTML estático)
Sí (renderizado completo)
Frecuencia de Rastreo
Muy alta (100x+ más frecuente)
Moderada (semanal/mensual)
Capacidad de Reindexación
Ninguna (solo bajo demanda)
Sí (actualizaciones continuas)
Requisitos de Contenido
HTML plano, marcado de esquema
Flexible (maneja contenido dinámico)
Bloqueo por User-Agent
Específico por bot (GPTBot, ClaudeBot, etc.)
Genérico (Googlebot, Bingbot)
Estrategia de Caché
Instantáneas a corto plazo
Mantenimiento de índice a largo plazo
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Bloqueadores Comunes que Impiden el Acceso de la IA
Tu contenido podría ser invisible para los crawlers de IA por razones en las que nunca has pensado. Estos son los principales obstáculos que impiden a los bots de IA acceder y comprender tu contenido:
Contenido dependiente de JavaScript: Si tu sitio depende de JavaScript del lado del cliente para renderizar texto, imágenes o datos estructurados, los crawlers de IA no lo verán—solo procesan HTML estático
Falta de marcado de esquema: Sin datos estructurados adecuados (JSON-LD, microdatos), los crawlers de IA tienen dificultades para entender el contexto, la autoría, fechas de publicación y relaciones de contenido
Problemas de infraestructura técnica: Tiempos de respuesta lentos del servidor, errores 5xx, cadenas de redirecciones y malas Core Web Vitals pueden hacer que los crawlers abandonen tu sitio a mitad del rastreo
Contenido restringido o de pago: El contenido detrás de muros de acceso, sistemas de pago o CAPTCHAs es completamente inaccesible para los crawlers de IA
Reglas demasiado restrictivas en robots.txt: Bloquear directorios completos o user-agents impide que los crawlers accedan a contenido que realmente quieres que vean
Bloqueos por firewall y seguridad: Las reglas de WAF (Firewall de Aplicaciones Web), bloqueo de IPs o limitaciones de velocidad pueden identificar erróneamente a los crawlers de IA como amenazas y bloquearlos por completo
Entendiendo robots.txt y Reglas de User-Agent
Tu archivo robots.txt es el principal mecanismo para controlar qué bots de IA pueden acceder a tu contenido y funciona mediante reglas específicas de User-Agent que apuntan a crawlers individuales. Cada plataforma de IA utiliza cadenas de user-agent distintas—GPTBot de OpenAI, ClaudeBot de Anthropic, PerplexityBot de Perplexity—y puedes permitir o denegar cada uno de forma independiente. Este control granular te permite decidir qué sistemas de IA pueden entrenar o citar tu contenido, lo cual es crucial para proteger información confidencial o gestionar preocupaciones competitivas. Sin embargo, muchos sitios bloquean sin saberlo a los crawlers de IA mediante reglas demasiado amplias diseñadas para bots antiguos, o simplemente no implementan reglas adecuadas.
Aquí tienes un ejemplo de cómo configurar tu robots.txt para distintos bots de IA:
# Permitir GPTBot de OpenAI
User-agent: GPTBot
Allow: /
# Bloquear ClaudeBot de Anthropic
User-agent: ClaudeBot
Disallow: /
# Permitir Perplexity pero restringir ciertos directorios
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Regla por defecto para todos los demás bots
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
La Importancia de la Primera Impresión
A diferencia de Google, que rastrea e indexa continuamente tu sitio, los crawlers de IA operan en una sola oportunidad—te visitan cuando un usuario consulta su sistema, y si tu contenido no está accesible en ese momento, has perdido la oportunidad. Esta diferencia fundamental significa que tu sitio debe estar técnicamente listo desde el primer día; no hay periodo de gracia ni segunda oportunidad para corregir problemas antes de perder visibilidad. Una mala experiencia en el primer rastreo—ya sea por errores de renderizado de JavaScript, falta de esquema o errores del servidor—puede hacer que tu contenido sea excluido de las respuestas generadas por IA durante semanas o meses. No existe una opción de reindexación manual, ni un botón de “Solicitar Indexación” en una consola, lo que hace que la monitorización y optimización proactiva sean innegociables. La presión por hacerlo bien a la primera nunca ha sido tan alta.
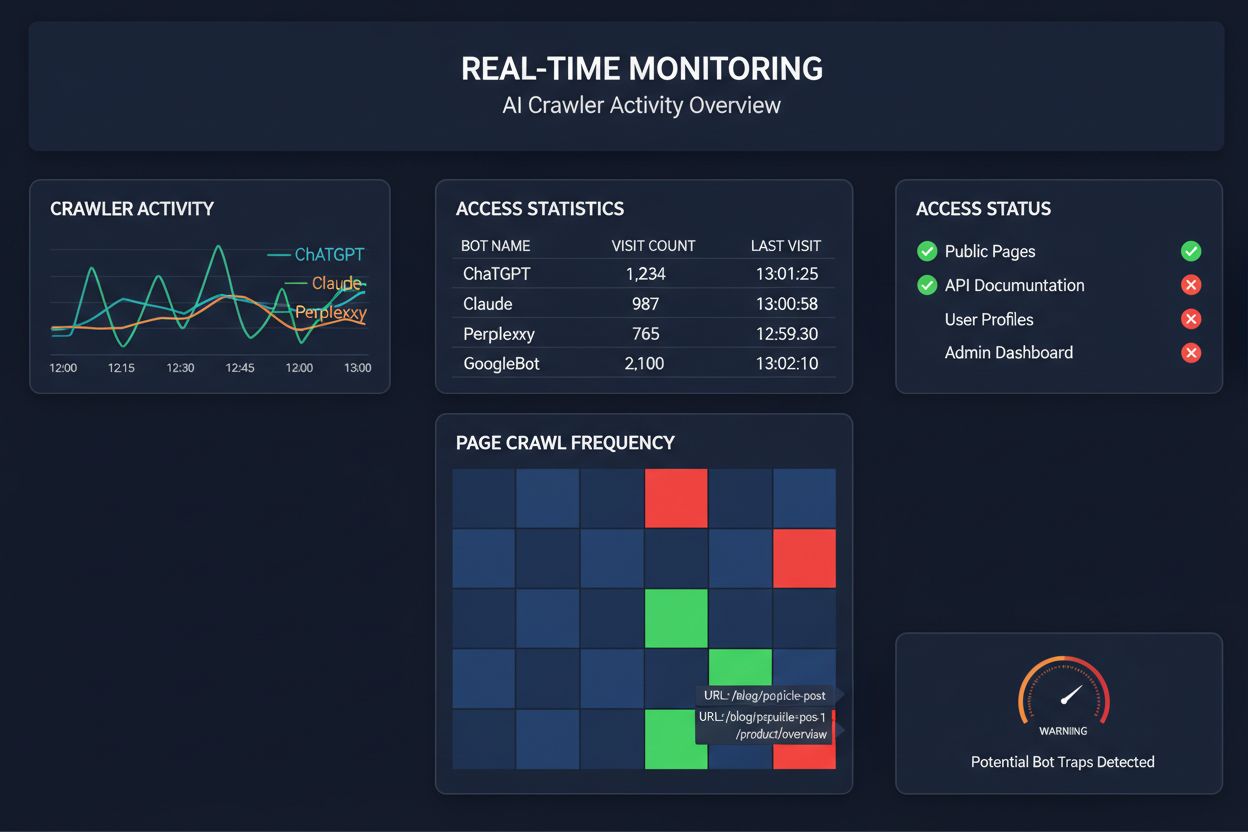
Monitorización en Tiempo Real vs. Rastreos Programados
Depender de rastreos programados para monitorear el acceso de crawlers de IA es como revisar tu casa por incendios una vez al mes—te perderás los momentos críticos cuando ocurren los problemas. La monitorización en tiempo real detecta los problemas en el momento en que suceden, permitiéndote responder antes de que tu contenido se vuelva invisible para los sistemas de IA. Las auditorías programadas, que suelen ejecutarse semanal o mensualmente, crean puntos ciegos peligrosos en los que tu sitio podría estar fallando para los crawlers de IA durante días sin que te des cuenta. Las soluciones en tiempo real rastrean el comportamiento de los crawlers continuamente, alertándote sobre fallos de renderizado de JavaScript, errores de marcado de esquema, bloqueos de firewall o problemas de servidor en cuanto ocurren. Este enfoque proactivo transforma tu auditoría de un chequeo reactivo de cumplimiento a una estrategia activa de gestión de visibilidad. Con el tráfico de crawlers de IA potencialmente 100 veces mayor que el de los motores de búsqueda tradicionales, el costo de perder incluso unas horas de accesibilidad puede ser considerable.
Herramientas y Soluciones para Auditorías de Crawlers de IA
Existen varias plataformas que ahora ofrecen herramientas especializadas para monitorear y optimizar el acceso de crawlers de IA. Cloudflare AI Crawl Control proporciona gestión a nivel de infraestructura del tráfico de bots de IA, permitiéndote establecer límites de velocidad y políticas de acceso. Conductor ofrece paneles de monitoreo completos que rastrean cómo interactúan los diferentes crawlers de IA con tu contenido. Elementive se especializa en auditorías técnicas de SEO con atención específica a los requisitos de los crawlers de IA. AdAmigo y MRS Digital brindan servicios especializados de consultoría y monitoreo para visibilidad en IA. Sin embargo, para una monitorización continua y en tiempo real diseñada específicamente para rastrear patrones de acceso de crawlers de IA y alertarte sobre problemas antes de que impacten la visibilidad, AmICited destaca como una solución dedicada. AmICited se especializa en monitorear qué sistemas de IA acceden a tu contenido, con qué frecuencia rastrean y si encuentran barreras técnicas. Este enfoque especializado en el comportamiento de crawlers de IA—en lugar de métricas tradicionales de SEO—lo convierte en una herramienta esencial para organizaciones que se toman en serio la visibilidad en IA.
Proceso de Auditoría Paso a Paso
Realizar una auditoría integral de crawlers de IA requiere un enfoque sistemático. Paso 1: Establece una línea base revisando tu archivo robots.txt actual e identificando qué bots de IA estás permitiendo o bloqueando. Paso 2: Audita tu infraestructura técnica probando la accesibilidad de tu sitio para crawlers sin JavaScript, verificando tiempos de respuesta del servidor y asegurando que el contenido crítico se sirva en HTML estático. Paso 3: Implementa y valida el marcado de esquema en tu contenido, asegurándote de que autoría, fechas de publicación, tipo de contenido y otros metadatos estén estructurados adecuadamente en formato JSON-LD. Paso 4: Monitorea el comportamiento de los crawlers usando herramientas como AmICited para rastrear qué bots de IA acceden a tu sitio, con qué frecuencia y si encuentran errores. Paso 5: Analiza los resultados revisando los registros de rastreo, identificando patrones en las fallas y priorizando las correcciones según el impacto. Paso 6: Implementa las correcciones comenzando por los problemas de mayor impacto como errores de renderizado de JavaScript o falta de esquema, para luego pasar a optimizaciones secundarias. Paso 7: Establece una monitorización continua para detectar nuevos problemas antes de que afecten la visibilidad, configurando alertas para fallos de rastreo o bloqueos de acceso.
Mejoras Rápidas para Optimizar la Rastreabilidad de IA
No necesitas una revisión completa para mejorar el acceso de los crawlers de IA—varios cambios de alto impacto pueden implementarse rápidamente. Sirve el contenido crítico en HTML plano en lugar de depender de la renderización por JavaScript; si debes usar JavaScript, asegúrate de que el texto y los metadatos importantes también estén en la carga inicial de HTML. Agrega un marcado de esquema completo usando formato JSON-LD, incluyendo esquema de artículo, información de autor, fechas de publicación y relaciones de contenido—esto ayuda a los crawlers de IA a entender el contexto y atribuir correctamente el contenido. Asegura información clara de autoría mediante marcado de esquema y líneas de autor, ya que los sistemas de IA priorizan cada vez más citar fuentes autorizadas. Monitorea y optimiza las Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift) porque las páginas de carga lenta pueden ser abandonadas por los crawlers antes de procesarlas completamente. Revisa y actualiza tu robots.txt para asegurarte de no estar bloqueando accidentalmente bots de IA que quieres que accedan a tu contenido. Corrige problemas técnicos como cadenas de redirecciones, enlaces rotos y errores del servidor que pueden hacer que los crawlers abandonen tu sitio a mitad del rastreo.
Monitorización de Distintos Bots de IA
No todos los crawlers de IA cumplen la misma función, y entender estas diferencias te ayuda a tomar decisiones informadas sobre el control de acceso. GPTBot (OpenAI) se usa principalmente para la recopilación de datos de entrenamiento y mejorar las capacidades del modelo, por lo que es relevante si quieres que tu contenido alimente las respuestas de ChatGPT. OAI-SearchBot (OpenAI) rastrea específicamente para fines de citación en búsqueda, lo que significa que es el bot responsable de incluir tu contenido en las respuestas integradas de búsqueda de ChatGPT. ClaudeBot (Anthropic) cumple funciones similares para Claude, el asistente de IA de Anthropic. PerplexityBot (Perplexity) rastrea para citar en el motor de búsqueda impulsado por IA de Perplexity, que se ha convertido en una fuente de tráfico significativa para muchos editores. Cada bot tiene diferentes patrones, frecuencia y propósitos de rastreo—algunos se centran en datos de entrenamiento, otros en citas de búsqueda en tiempo real. Decidir qué bots permitir o bloquear debe alinearse con tu estrategia de contenido: si quieres citas en resultados de búsqueda de IA, permite los bots específicos de búsqueda; si te preocupa el uso para entrenamiento, puedes bloquear los bots de recopilación de datos mientras permites los de búsqueda. Este enfoque matizado de gestión de bots es mucho más sofisticado que la mentalidad tradicional de “permitir todo” o “bloquear todo”.
Preguntas frecuentes
¿Qué es una auditoría de crawler de IA?
Una auditoría de crawler de IA es una evaluación integral de la accesibilidad de tu sitio web para bots de IA como ChatGPT, Claude y Perplexity. Identifica bloqueos técnicos, problemas de renderizado de JavaScript, ausencia de marcado de esquema y otros factores que impiden que los crawlers de IA accedan y comprendan tu contenido. La auditoría proporciona recomendaciones accionables para mejorar tu visibilidad en motores de búsqueda y plataformas de respuestas impulsadas por IA.
¿Con qué frecuencia debo auditar el acceso de crawlers de IA a mi sitio?
Recomendamos realizar una auditoría completa al menos cada trimestre o cada vez que realices cambios significativos en la infraestructura técnica de tu sitio web, la estructura del contenido o el archivo robots.txt. Sin embargo, la monitorización continua y en tiempo real es ideal para detectar problemas inmediatamente cuando ocurren. Muchas organizaciones utilizan herramientas de monitoreo automatizadas que les alertan sobre fallos de rastreo en tiempo real, complementadas con auditorías profundas trimestrales.
¿Cuál es la diferencia entre bloquear y permitir crawlers de IA?
Permitir crawlers de IA significa que tu contenido puede ser accedido, analizado y potencialmente citado por sistemas de IA, lo que puede aumentar tu visibilidad en respuestas y recomendaciones generadas por IA. Bloquear crawlers de IA les impide acceder a tu contenido, protegiendo información confidencial pero reduciendo potencialmente tu visibilidad en los resultados de búsqueda de IA. La decisión correcta depende de tus objetivos de negocio, sensibilidad del contenido y posicionamiento competitivo.
¿Puedo bloquear bots de IA específicos mientras permito otros?
Sí, absolutamente. Tu archivo robots.txt permite un control detallado mediante reglas de User-Agent. Puedes bloquear a GPTBot mientras permites a PerplexityBot, o permitir bots enfocados en búsqueda (como OAI-SearchBot) mientras bloqueas bots de recopilación de datos (como GPTBot). Este enfoque matizado te permite optimizar tu estrategia de contenido en función de las plataformas de IA que más importan para tu negocio.
¿Qué significa si los crawlers de IA no pueden acceder a mi contenido?
Si los crawlers de IA no pueden acceder a tu contenido, significa que tu sitio es efectivamente invisible para motores de búsqueda y plataformas de respuestas impulsadas por IA. Tu contenido no será citado, recomendado ni incluido en respuestas generadas por IA, aunque sea muy relevante. Esto puede resultar en pérdida de tráfico, menor visibilidad de marca y oportunidades perdidas para establecer autoridad en los resultados de búsqueda de IA.
¿Cómo sé qué bots de IA están visitando mi sitio?
Puedes revisar los registros de tu servidor para ver cadenas de User-Agent de crawlers de IA conocidos (GPTBot, ClaudeBot, PerplexityBot, etc.), o utilizar herramientas especializadas de monitoreo como AmICited que rastrean la actividad de los crawlers de IA en tiempo real. Estas herramientas te muestran qué bots acceden a tu sitio, con qué frecuencia rastrean, qué páginas visitan y si encuentran errores o bloqueos.
¿Debo bloquear los crawlers de IA de mi sitio web?
Esto depende de tu situación específica. Si tu contenido es confidencial, sensible o te preocupa el uso como datos de entrenamiento, puede ser apropiado bloquear. Sin embargo, si buscas visibilidad en resultados de búsqueda de IA y citas de sistemas de IA, permitir crawlers es esencial. Muchas organizaciones adoptan un enfoque intermedio: permiten bots enfocados en búsqueda que generan citas mientras bloquean bots de recopilación de datos.
¿Cuál es el impacto de JavaScript en el acceso de crawlers de IA?
Los crawlers de IA no renderizan JavaScript, lo que significa que cualquier contenido cargado dinámicamente mediante scripts del lado del cliente es invisible para ellos. Si tu sitio depende en gran medida de JavaScript para contenido crítico, navegación o datos estructurados, los crawlers de IA solo verán el HTML bruto y se perderán información importante. Esto puede afectar significativamente cómo se entiende y representa tu contenido en las respuestas de IA. Servir contenido crítico en HTML estático es esencial para la rastreabilidad por IA.
Monitorea el Acceso de Crawlers de IA con AmICited
Obtén información en tiempo real sobre qué bots de IA están accediendo a tu contenido y cómo ven tu sitio web. Comienza tu auditoría gratuita hoy y asegúrate de que tu marca sea visible en todas las plataformas de búsqueda de IA.
Rastrea la Actividad de Crawlers de IA: Guía Completa de Monitoreo
Aprende cómo rastrear y monitorear la actividad de crawlers de IA en tu sitio web utilizando logs de servidor, herramientas y mejores prácticas. Identifica GPTB...
Auditoría de Contenido para Visibilidad en IA: Priorizando Actualizaciones
Aprende cómo auditar tu contenido para la visibilidad en IA y priorizar actualizaciones. Marco completo para ChatGPT, Perplexity y Google AI Overviews con estra...
La guía completa para bloquear (o permitir) rastreadores de IA
Aprende a bloquear o permitir rastreadores de IA como GPTBot y ClaudeBot usando robots.txt, bloqueo a nivel de servidor y métodos avanzados de protección. Guía ...
8 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.