Cum să te asiguri că AI Crawlers văd tot conținutul tău
Află cum să faci conținutul tău vizibil pentru crawlerii AI precum ChatGPT, Perplexity și AI-ul Google. Descoperă cerințe tehnice, bune practici și strategii de...
12 min citire

Află cum să faci un audit al accesului crawlerelor AI la site-ul tău. Descoperă ce boturi îți pot vedea conținutul și rezolvă blocajele care împiedică vizibilitatea în ChatGPT, Perplexity și alte motoare de căutare AI.
Peisajul căutării și al descoperirii de conținut se schimbă dramatic. Odată cu creșterea exponențială a instrumentelor de căutare bazate pe AI, precum ChatGPT, Perplexity și Google AI Overviews, vizibilitatea conținutului tău pentru crawlerele AI a devenit la fel de critică precum optimizarea tradițională pentru motoarele de căutare. Dacă boturile AI nu pot accesa conținutul tău, site-ul tău devine invizibil pentru milioane de utilizatori care se bazează pe aceste platforme pentru răspunsuri. Miza este mai mare ca niciodată: în timp ce Google ar putea reveni pe site-ul tău dacă apare o problemă, crawlerele AI funcționează după un alt model—iar ratarea acelei prime accesări critice poate însemna luni de vizibilitate pierdută și oportunități ratate la nivel de citări, trafic și autoritate de brand.
Crawlerele AI funcționează după reguli fundamental diferite față de boturile Google și Bing pentru care ai optimizat în ultimii ani. Cea mai importantă diferență: crawlerele AI nu procesează JavaScript, ceea ce înseamnă că orice conținut dinamic încărcat prin scripturi pe partea de client este invizibil pentru ele—un contrast puternic cu capabilitățile sofisticate de randare ale Google. În plus, crawlerele AI vizitează site-urile cu o frecvență mult mai mare, uneori de 100 de ori mai des decât motoarele de căutare tradiționale, generând atât oportunități, cât și provocări la nivel de resurse server. Spre deosebire de modelul de indexare al Google, crawlerele AI nu mențin un index persistent care se reîmprospătează; în schimb, ele accesează la cerere, atunci când utilizatorii interoghează sistemele lor. Asta înseamnă că nu există coadă de re-indexare, nu există Search Console pentru a cere recrawl și nici a doua șansă dacă site-ul tău nu trece de prima impresie. Înțelegerea acestor diferențe este esențială pentru optimizarea strategiei de conținut.
| Caracteristică | Crawlere AI | Boturi tradiționale |
|---|---|---|
| Randare JavaScript | Nu (doar HTML static) | Da (randare completă) |
| Frecvență crawl | Foarte mare (100x+ mai frecvent) | Moderată (săptămânal/lunar) |
| Re-indexare | Nu (doar la cerere) | Da (actualizări continue) |
| Cerințe de conținut | HTML simplu, schema markup | Flexibil (acceptă conținut dinamic) |
| Blocare User-Agent | Specific pe bot (GPTBot, ClaudeBot etc.) | Generic (Googlebot, Bingbot) |
| Strategie caching | Snapshots pe termen scurt | Menținere index pe termen lung |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Conținutul tău poate fi invizibil pentru crawlerele AI din motive la care poate nu te-ai gândit până acum. Iată principalele obstacole care împiedică boturile AI să acceseze și să înțeleagă conținutul tău:
Fișierul tău robots.txt este principalul mecanism prin care controlezi ce boturi AI pot accesa conținutul tău, funcționând prin reguli User-Agent specifice pentru fiecare crawler. Fiecare platformă AI folosește șiruri User-Agent distincte—GPTBot de la OpenAI, ClaudeBot de la Anthropic, PerplexityBot de la Perplexity—și poți permite sau bloca fiecare bot independent. Acest control granular îți permite să decizi ce sisteme AI pot folosi sau cita conținutul tău, ceea ce este crucial pentru protejarea informațiilor proprietare sau gestionarea aspectelor competitive. Totuși, multe site-uri blochează accidental crawlerele AI prin reguli prea largi concepute pentru boturi mai vechi sau nu implementează deloc reguli potrivite.
Iată un exemplu de configurare a robots.txt pentru diferiți boti AI:
# Permite GPTBot de la OpenAI
User-agent: GPTBot
Allow: /
# Blochează ClaudeBot de la Anthropic
User-agent: ClaudeBot
Disallow: /
# Permite Perplexity dar restricționează anumite directoare
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Regulă implicită pentru toți ceilalți boti
User-agent: *
Allow: /
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Spre deosebire de Google, care accesează și re-indexează continuu site-ul tău, crawlerele AI funcționează pe principiul „o singură șansă”—vin atunci când un utilizator interoghează sistemul, iar dacă în acel moment conținutul nu e accesibil, ai pierdut oportunitatea. Această diferență fundamentală impune ca site-ul tău să fie pregătit tehnic de la bun început; nu există perioadă de grație, nu există a doua șansă să rezolvi problemele înainte să-ți afecteze vizibilitatea. O experiență slabă la prima accesare—fie din cauza problemelor de randare JavaScript, a lipsei markup-ului schema sau a erorilor de server—poate duce la excluderea conținutului tău din răspunsurile AI pentru săptămâni sau luni. Nu există opțiune de re-indexare manuală, nu există buton „Request Indexing” într-o consolă, ceea ce face ca monitorizarea și optimizarea proactivă să fie obligatorii. Presiunea de a face totul corect din prima nu a fost niciodată mai mare.
A te baza pe crawluri programate pentru a monitoriza accesul crawlerelor AI e ca și cum ai verifica dacă a luat foc casa o dată pe lună—ratezi momentele critice când apar probleme. Monitorizarea în timp real detectează problemele exact în momentul apariției, permițându-ți să reacționezi înainte ca site-ul să devină invizibil pentru sistemele AI. Auditările programate, făcute săptămânal sau lunar, creează zone moarte periculoase în care site-ul tău poate eșua pentru crawlerele AI zile în șir fără să știi. Soluțiile de monitorizare în timp real urmăresc comportamentul crawlerelor continuu, alertându-te la probleme de randare JavaScript, erori de markup schema, blocaje de firewall sau probleme server pe măsură ce apar. Această abordare proactivă transformă auditul dintr-o simplă verificare de conformitate într-o strategie activă de management al vizibilității. Cu trafic AI de până la 100 de ori mai mare decât cel de la motoarele de căutare tradiționale, costul ratării chiar și a câtorva ore de accesibilitate poate fi semnificativ.
Mai multe platforme oferă acum instrumente specializate pentru monitorizarea și optimizarea accesului crawlerelor AI. Cloudflare AI Crawl Control oferă management la nivel de infrastructură al traficului boturilor AI, permițând setarea de limite de acces și politici personalizate. Conductor pune la dispoziție dashboard-uri de monitorizare ce urmăresc interacțiunile diferitelor crawlere AI cu conținutul tău. Elementive se concentrează pe audituri SEO tehnice cu accent pe cerințele crawlerelor AI. AdAmigo și MRS Digital furnizează consultanță și monitorizare specializată pentru vizibilitatea AI. Însă, pentru monitorizare continuă, în timp real, concepută special pentru a urmări tiparele de acces ale crawlerelor AI și a alerta la probleme înainte să afecteze vizibilitatea, AmICited se remarcă drept o soluție dedicată. AmICited este specializat în monitorizarea accesului sistemelor AI la conținutul tău, cât de des accesează și dacă întâmpină bariere tehnice. Această focalizare pe comportamentul crawlerelor AI—nu pe metrice SEO tradiționale—îl face un instrument esențial pentru organizațiile care mizează pe vizibilitatea AI.
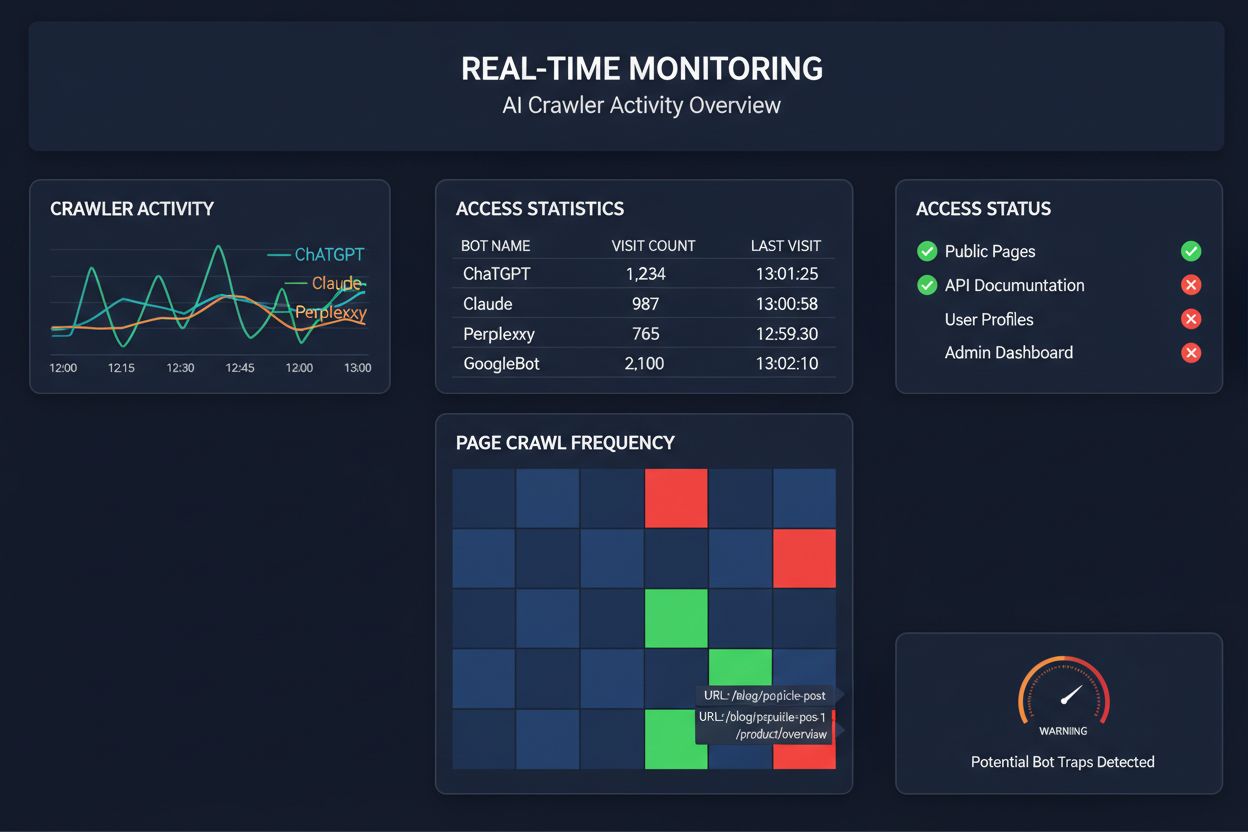
Realizarea unui audit complet pentru crawlerele AI necesită o abordare sistematică. Pasul 1: Stabilește un punct de pornire verificând fișierul robots.txt actual și identificând ce boturi AI permiți sau blochezi în prezent. Pasul 2: Auditează infrastructura tehnică testând accesibilitatea site-ului la crawlere non-JavaScript, verificând timpii de răspuns ai serverului și asigurându-te că informațiile critice sunt servite în HTML static. Pasul 3: Implementează și validează markup schema pe tot conținutul, asigurând structura corectă pentru autor, dată publicare, tip conținut și alte metadate în format JSON-LD. Pasul 4: Monitorizează comportamentul crawlerelor folosind instrumente ca AmICited pentru a urmări ce boti AI accesează site-ul, cât de des și dacă întâmpină erori. Pasul 5: Analizează rezultatele revizuind logurile de crawl, identificând tipare de eșecuri și prioritizând rezolvarea celor cu impact major. Pasul 6: Implementează remediile începând cu problemele critice precum randarea JavaScript sau lipsa schema, apoi treci la optimizări secundare. Pasul 7: Stabilește monitorizare continuă pentru a detecta din timp noile probleme, setând alerte pentru erori de crawl sau blocaje de acces.
Nu ai nevoie de o restructurare completă pentru a îmbunătăți accesul crawlerelor AI—există câteva schimbări cu impact mare care pot fi implementate rapid. Servește conținutul critic în HTML simplu, fără a te baza pe randarea JavaScript; dacă totuși folosești JavaScript, asigură-te că textul și metadatele importante sunt prezente și în payload-ul HTML inițial. Adaugă markup schema complet folosind formatul JSON-LD: schema articol, autor, dată publicare, relații între conținuturi—acest lucru ajută crawlerele AI să înțeleagă contextul și să atribuie corect conținutul. Asigură informații clare despre autor prin schema și byline, deoarece sistemele AI prioritizează din ce în ce mai mult citarea surselor autoritare. Monitorizează și optimizează Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), deoarece paginile cu încărcare lentă pot fi abandonate de crawlere înainte de finalizare. Revizuiește și actualizează robots.txt pentru a nu bloca accidental boturile AI pe care vrei să le acceseze. Rezolvă problemele tehnice precum lanțuri de redirecționări, linkuri stricate și erori server care pot determina crawlerele să abandoneze accesarea site-ului.
Nu toate crawlerele AI au același scop, iar înțelegerea acestor diferențe te ajută să iei decizii informate despre controlul accesului. GPTBot (OpenAI) este folosit mai ales pentru colectarea de date pentru antrenarea modelelor și îmbunătățirea capabilităților, fiind relevant dacă vrei ca informațiile tale să influențeze răspunsurile ChatGPT. OAI-SearchBot (OpenAI) accesează special pentru citări în căutare, adică este botul responsabil cu includerea conținutului tău în răspunsurile ChatGPT cu integrare de căutare. ClaudeBot (Anthropic) are funcții similare pentru Claude, asistentul AI de la Anthropic. PerplexityBot (Perplexity) accesează pentru citare în motorul de căutare AI Perplexity, care a devenit o sursă importantă de trafic pentru mulți publisheri. Fiecare bot are tipare, frecvențe și scopuri diferite—unii colectează date pentru antrenare, alții doar pentru citări în căutare în timp real. Decizia privind ce boti să permiți sau să blochezi trebuie să fie aliniată cu strategia ta de conținut: dacă vrei citări în rezultatele AI, permite boturile dedicate căutării; dacă ai rezerve legate de utilizarea datelor la antrenare, poți bloca boturile de colectare și permite doar cele de căutare. Această abordare nuanțată de management al boturilor este mult mai sofisticată decât vechiul „permit tot” sau „blochez tot”.
Obține informații în timp real despre ce boturi AI accesează conținutul tău și cum îți văd site-ul. Începe un audit gratuit astăzi și asigură-te că brandul tău este vizibil pe toate platformele AI de căutare.
Află cum să faci conținutul tău vizibil pentru crawlerii AI precum ChatGPT, Perplexity și AI-ul Google. Descoperă cerințe tehnice, bune practici și strategii de...
Depanează problemele de crawling AI cu jurnalele de server, identificarea agenților utilizatori și soluții tehnice. Monitorizează crawlerele ChatGPT, Perplexity...
Află cum să testezi dacă crawler-ele AI precum ChatGPT, Claude și Perplexity pot accesa conținutul site-ului tău web. Descoperă metode de testare, instrumente ș...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.