Descubre cómo la Generación Aumentada por Recuperación transforma las citaciones de la IA, permitiendo una atribución precisa de fuentes y respuestas fundamentadas en ChatGPT, Perplexity y Google AI Overviews.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Los grandes modelos de lenguaje han revolucionado la IA, pero presentan una falla crítica: límites de conocimiento. Estos modelos se entrenan con datos hasta un punto específico en el tiempo, lo que significa que no pueden acceder a información posterior a esa fecha. Más allá de quedar obsoletos, los LLMs tradicionales sufren alucinaciones: generan con confianza información falsa que suena plausible y no proveen atribución de fuentes para sus afirmaciones. Cuando una empresa necesita datos de mercado actuales, investigaciones propias o hechos verificables, los LLMs tradicionales no cumplen, dejando a los usuarios con respuestas que no pueden confiar ni verificar.
¿Qué es RAG? - Definición y Componentes Clave
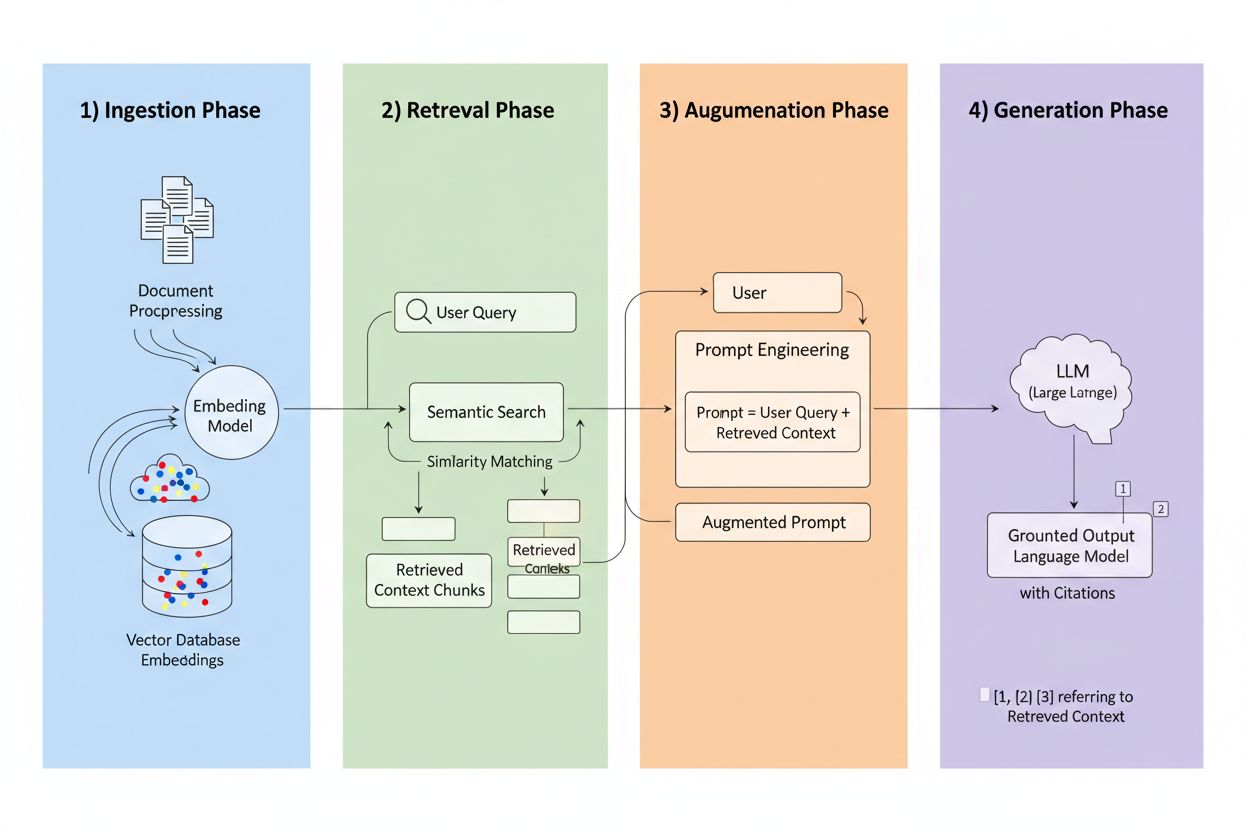
La Generación Aumentada por Recuperación (RAG) es un marco que combina el poder generativo de los LLMs con la precisión de los sistemas de recuperación de información. En lugar de depender solo de datos de entrenamiento, los sistemas RAG extraen información relevante de fuentes externas antes de generar respuestas, creando una cadena que fundamenta las respuestas en datos reales. Los cuatro componentes principales trabajan en conjunto: Ingesta (convertir documentos en formatos buscables), Recuperación (encontrar las fuentes más relevantes), Aumentación (enriquecer el prompt con contexto recuperado) y Generación (crear la respuesta final con citaciones). Así se compara RAG con los enfoques tradicionales:
Aspecto
LLM Tradicional
Sistema RAG
Fuente de Conocimiento
Datos de entrenamiento estáticos
Fuentes externas indexadas
Capacidad de Citación
Ninguna/alucinada
Rastreable a fuentes
Precisión
Propenso a errores
Fundamentado en hechos
Datos en Tiempo Real
No
Sí
Riesgo de Alucinación
Alto
Bajo
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Cómo Funciona la Recuperación en RAG - Profundidad Técnica
El motor de recuperación es el corazón de RAG, y es mucho más sofisticado que una simple coincidencia de palabras clave. Los documentos se convierten en embeddings vectoriales—representaciones matemáticas que capturan el significado semántico—permitiendo al sistema encontrar contenido conceptualmente similar aunque no coincidan las palabras exactas. El sistema fragmenta los documentos en partes manejables, normalmente de 256-1024 tokens, equilibrando la preservación del contexto con la precisión de la recuperación. Los sistemas RAG más avanzados emplean búsqueda híbrida, combinando similitud semántica con coincidencia tradicional de palabras clave para captar coincidencias tanto conceptuales como exactas. Un mecanismo de reranking puntúa luego estos candidatos, a menudo usando modelos cross-encoder que evalúan la relevancia de manera más precisa que la recuperación inicial. La relevancia se calcula a través de múltiples señales: puntuaciones de similitud semántica, coincidencia de palabras clave, coincidencia de metadatos y autoridad de dominio. Todo el proceso ocurre en milisegundos, asegurando respuestas rápidas y precisas sin latencia perceptible.
La Ventaja de la Citación
Aquí es donde RAG transforma el panorama de las citaciones: cuando un sistema recupera información de una fuente indexada específica, esa fuente se vuelve rastreable y verificable. Cada fragmento de texto puede trazarse hasta su documento, URL o publicación original, haciendo que la citación sea automática en vez de alucinada. Este cambio fundamental crea una transparencia sin precedentes en la toma de decisiones de la IA: los usuarios pueden ver exactamente qué fuentes informaron la respuesta, verificar afirmaciones de forma independiente y evaluar la credibilidad de la fuente por sí mismos. A diferencia de los LLMs tradicionales donde las citaciones suelen ser inventadas o genéricas, las citaciones RAG están basadas en eventos reales de recuperación. Esta trazabilidad aumenta dramáticamente la confianza del usuario, ya que pueden validar la información en vez de tomarla por fe. Para creadores de contenido y editores, esto significa que su trabajo puede ser descubierto y acreditado por sistemas de IA, abriendo nuevos canales de visibilidad.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Factores de Calidad de Citación en Sistemas RAG
No todas las fuentes son iguales en los sistemas RAG, y varios factores determinan qué contenido es citado con mayor frecuencia:
Autoridad: La reputación del dominio, los perfiles de backlinks y la presencia en grafos de conocimiento indican confiabilidad a los algoritmos de recuperación
Actualidad: El contenido actualizado en ciclos de 48-72 horas se posiciona mejor, pues la frescura indica mantenimiento activo y fiabilidad
Relevancia: La alineación semántica con las consultas de los usuarios determina si el contenido aparece en los resultados de recuperación
Estructura: Jerarquía clara, encabezados descriptivos y marcado semántico ayudan a los sistemas a comprender y extraer información con precisión
Densidad Factual: El contenido cargado de datos específicos, estadísticas y citaciones ofrece más fragmentos recuperables que los resúmenes genéricos
Grafo de Conocimiento: La presencia en Wikipedia, Wikidata o bases de conocimiento de la industria aumenta dramáticamente la probabilidad de citación
Cada factor potencia a los otros: un artículo bien estructurado, actualizado frecuentemente, de un dominio autoritativo con fuertes backlinks y presencia en grafo de conocimiento se convierte en un imán de citaciones en sistemas RAG. Esto crea un nuevo paradigma de optimización donde la visibilidad depende menos del SEO tradicional y más de convertirse en una fuente confiable y estructurada de información.
Cómo Diferentes Plataformas de IA Usan RAG para Citaciones
Distintas plataformas de IA implementan RAG con estrategias únicas, generando patrones de citación variados. ChatGPT pondera fuertemente las fuentes de Wikipedia, con estudios que muestran que aproximadamente el 26-35% de sus citaciones provienen solo de Wikipedia, reflejando su autoridad y formato estructurado. Google AI Overviews emplea una selección de fuentes más diversa, extrayendo de sitios de noticias, artículos académicos y foros, con Reddit apareciendo en alrededor del 5% de las citaciones a pesar de su menor autoridad tradicional. Perplexity AI suele citar de 3 a 5 fuentes por respuesta y muestra preferencia por publicaciones especializadas de la industria y noticias recientes, optimizando por exhaustividad y actualidad. Estas plataformas ponderan la autoridad de dominio de manera diferente: algunas priorizan marcadores tradicionales como backlinks y antigüedad del dominio, mientras otras enfatizan la frescura del contenido y la relevancia semántica. Comprender estas estrategias de recuperación específicas de cada plataforma es crucial para los creadores de contenido, ya que la optimización para el RAG de una plataforma puede diferir significativamente de la de otra.
RAG vs Búsqueda Tradicional - Implicaciones en Citaciones
El auge de RAG altera fundamentalmente la sabiduría tradicional del SEO. En la optimización para motores de búsqueda, citaciones y visibilidad se correlacionan directamente con el tráfico: necesitas clics para que importe. RAG invierte esta ecuación: el contenido puede ser citado e influir en respuestas de IA sin generar tráfico alguno. Un artículo bien estructurado y autoritativo puede aparecer en docenas de respuestas de IA a diario y recibir cero clics, ya que los usuarios reciben la respuesta directamente del resumen de la IA. Esto significa que las señales de autoridad son más importantes que nunca, ya que son el principal mecanismo que los sistemas RAG emplean para evaluar la calidad de la fuente. La consistencia entre plataformas se vuelve crítica: si tu contenido aparece en tu web, LinkedIn, bases de datos de la industria y grafos de conocimiento, los sistemas RAG ven señales de autoridad reforzadas. La presencia en grafo de conocimiento pasa de ser “deseable” a infraestructura esencial, ya que estas bases estructuradas son fuentes primarias de recuperación para muchas implementaciones RAG. El juego de la citación ha cambiado fundamentalmente de “generar tráfico” a “convertirse en una fuente confiable de información”.
Optimización de Contenidos para Citaciones RAG
Para maximizar las citaciones RAG, la estrategia de contenido debe pasar de optimización por tráfico a optimización por fuente. Implementa ciclos de actualización de 48-72 horas para contenido evergreen, señalando a los sistemas de recuperación que tu información está al día. Usa marcado de datos estructurados (Schema.org, JSON-LD) para ayudar a los sistemas a analizar y comprender el significado y las relaciones de tu contenido. Alinea tu contenido semánticamente con patrones comunes de consulta: utiliza lenguaje natural que coincida con cómo la gente formula preguntas, no solo cómo busca. Da formato a tu contenido consecciones de preguntas frecuentes y Q&A, ya que estas coinciden directamente con el patrón pregunta-respuesta que usan los sistemas RAG. Desarrolla o contribuye a entradas en Wikipedia y grafos de conocimiento, ya que son fuentes primarias para la mayoría de las plataformas. Construye autoridad de backlinks mediante alianzas estratégicas y citaciones desde otras fuentes autoritativas, ya que los perfiles de enlaces siguen siendo fuertes señales de autoridad. Finalmente, mantén la consistencia entre plataformas: asegúrate de que tus afirmaciones clave, datos y mensajes estén alineados en tu web, perfiles sociales, bases de datos de la industria y grafos de conocimiento, creando señales reforzadas de fiabilidad.
El Futuro del RAG y las Citaciones
La tecnología RAG sigue evolucionando rápidamente, con varias tendencias que redefinen cómo funcionan las citaciones. Algoritmos de recuperación más sofisticados irán más allá de la similitud semántica hacia una comprensión más profunda de la intención y el contexto de la consulta, mejorando la relevancia de las citaciones. Bases de conocimiento especializadas emergerán para dominios concretos—sistemas médicos RAG usando literatura médica curada, sistemas legales utilizando jurisprudencia y legislación—creando nuevas oportunidades de citación para fuentes autoritativas del sector. La integración con sistemas multiagente permitirá que RAG orqueste múltiples recuperadores especializados, combinando ideas de diferentes bases de conocimiento para respuestas más completas. El acceso a datos en tiempo real mejorará drásticamente, permitiendo que los sistemas RAG incorporen información en vivo de APIs, bases de datos y fuentes en streaming. El RAG agentivo—donde agentes de IA deciden autónomamente qué recuperar, cómo procesarlo y cuándo iterar—generará patrones de citación más dinámicos, citando potencialmente fuentes varias veces a medida que los agentes refinan su razonamiento.
El Rol de AmICited en el Monitoreo de Citaciones RAG
A medida que RAG redefine cómo lossistemas de IA descubren y citan fuentes, entender tu desempeño en citaciones se vuelve esencial. AmICited monitorea citaciones de IA en todas las plataformas, rastreando qué fuentes tuyas aparecen en ChatGPT, Google AI Overviews, Perplexity y sistemas de IA emergentes. Verás qué fuentes específicas son citadas, con qué frecuencia aparecen y en qué contexto, revelando qué contenido resuena con los algoritmos de recuperación RAG. Nuestra plataforma te ayuda a entender los patrones de citación en tu portafolio de contenidos, identificando qué hace que ciertas piezas sean citables y otras pasen desapercibidas. Mide la visibilidad de tu marca en respuestas IA con métricas relevantes en la era RAG, yendo más allá de la analítica de tráfico tradicional. Realiza análisis competitivo del desempeño en citaciones, viendo cómo tus fuentes se comparan frente a la competencia en respuestas generadas por IA. En un mundo donde las citaciones de IA impulsan la visibilidad y la autoridad, tener una visión clara de tu desempeño en citaciones no es opcional: es cómo te mantienes competitivo.
Preguntas frecuentes
¿Cuál es la diferencia entre RAG y los LLMs tradicionales?
Los LLMs tradicionales dependen de datos de entrenamiento estáticos con límites de conocimiento y no pueden acceder a información en tiempo real, lo que a menudo resulta en alucinaciones y afirmaciones no verificables. Los sistemas RAG recuperan información de fuentes externas indexadas antes de generar respuestas, permitiendo citaciones precisas y respuestas fundamentadas en datos actuales y verificables.
¿Cómo mejora RAG la precisión de las citaciones?
RAG rastrea cada fragmento de información recuperada hasta su fuente original, haciendo que las citaciones sean automáticas y verificables en lugar de alucinadas. Esto crea un vínculo directo entre la respuesta y el material fuente, permitiendo a los usuarios verificar las afirmaciones de forma independiente y evaluar la credibilidad de la fuente.
¿Qué factores determinan qué fuentes son citadas en los sistemas RAG?
Los sistemas RAG evalúan las fuentes según la autoridad (reputación del dominio y backlinks), actualidad (contenido actualizado en 48-72 horas), relevancia semántica con la consulta, estructura y claridad del contenido, densidad factual con datos específicos y presencia en grafos de conocimiento como Wikipedia. Estos factores se combinan para determinar la probabilidad de citación.
¿Cómo puedo optimizar mi contenido para citaciones RAG?
Actualiza el contenido cada 48-72 horas para mantener señales de frescura, implementa marcado de datos estructurados (Schema.org), alinea el contenido semánticamente con consultas comunes, utiliza formato de preguntas frecuentes y Q&A, desarrolla presencia en Wikipedia y grafos de conocimiento, construye autoridad de backlinks y mantén la consistencia en todas las plataformas.
¿Por qué es importante la presencia en grafos de conocimiento para citaciones de IA?
Grafos de conocimiento como Wikipedia y Wikidata son fuentes primarias de recuperación para la mayoría de los sistemas RAG. La presencia en estas bases de datos estructuradas aumenta drásticamente la probabilidad de citación y crea señales de confianza fundamentales que los sistemas de IA consultan repetidamente en consultas diversas.
¿Con qué frecuencia debo actualizar el contenido para visibilidad en RAG?
El contenido debe actualizarse cada 48-72 horas para mantener señales sólidas de actualidad en los sistemas RAG. No es necesario reescribir todo: agregar nuevos datos, actualizar estadísticas o ampliar secciones con desarrollos recientes es suficiente para mantener la elegibilidad para ser citado.
¿Qué papel juega la autoridad del dominio en las citaciones RAG?
La autoridad de dominio funciona como un indicador de fiabilidad en los algoritmos RAG, representando aproximadamente el 5% de la probabilidad de citación. Se evalúa por la antigüedad del dominio, certificados SSL, perfiles de backlinks, atribución de expertos y presencia en grafos de conocimiento, todo lo cual influye en la selección de fuentes.
¿Cómo ayuda AmICited a monitorear las citaciones RAG?
AmICited rastrea qué fuentes tuyas aparecen en respuestas generadas por IA en ChatGPT, Google AI Overviews, Perplexity y otras plataformas. Verás la frecuencia de citación, el contexto y el rendimiento frente a la competencia, ayudándote a entender qué hace a un contenido digno de ser citado en la era RAG.
Monitorea las citaciones de IA de tu marca
Comprende cómo aparece tu marca en respuestas generadas por IA en ChatGPT, Perplexity, Google AI Overviews y más. Rastrear patrones de citación, medir visibilidad y optimizar tu presencia en la búsqueda impulsada por IA.
¿Qué es RAG en la Búsqueda de IA?: Guía Completa sobre Generación Aumentada por Recuperación
Descubre qué es RAG (Generación Aumentada por Recuperación) en la búsqueda de IA. Aprende cómo RAG mejora la precisión, reduce las alucinaciones y alimenta a Ch...
Cómo Funciona la Generación Aumentada por Recuperación: Arquitectura y Proceso
Descubre cómo RAG combina LLMs con fuentes de datos externas para generar respuestas de IA precisas. Comprende el proceso de cinco etapas, los componentes y por...
¿Cómo manejan los sistemas RAG la información desactualizada?
Descubra cómo los sistemas de Generación Aumentada por Recuperación gestionan la frescura de la base de conocimientos, previenen datos obsoletos y mantienen inf...
12 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.