Jak działa Retrieval-Augmented Generation: architektura i proces
Dowiedz się, jak RAG łączy LLM z zewnętrznymi źródłami danych, aby generować precyzyjne odpowiedzi AI. Poznaj pięcioetapowy proces, komponenty oraz znaczenie te...
9 min czytania

Dowiedz się, jak Retrieval-Augmented Generation zmienia cytowania AI, umożliwiając precyzyjne przypisywanie źródeł i ugruntowane odpowiedzi w ChatGPT, Perplexity i Google AI Overviews.
Duże modele językowe zrewolucjonizowały AI, ale mają poważną wadę: ograniczenie wiedzy. Modele te są trenowane na danych do określonego momentu, co oznacza, że nie mają dostępu do informacji nowszych niż data odcięcia. Oprócz dezaktualizacji, tradycyjne LLM cierpią na halucynacje — pewne siebie generowanie fałszywych informacji brzmiących wiarygodnie — i nie podają źródeł swoich twierdzeń. Gdy firma potrzebuje aktualnych danych rynkowych, badań własnych czy weryfikowalnych faktów, tradycyjne LLM zawodzą, pozostawiając użytkowników z odpowiedziami, którym nie mogą ufać ani ich zweryfikować.
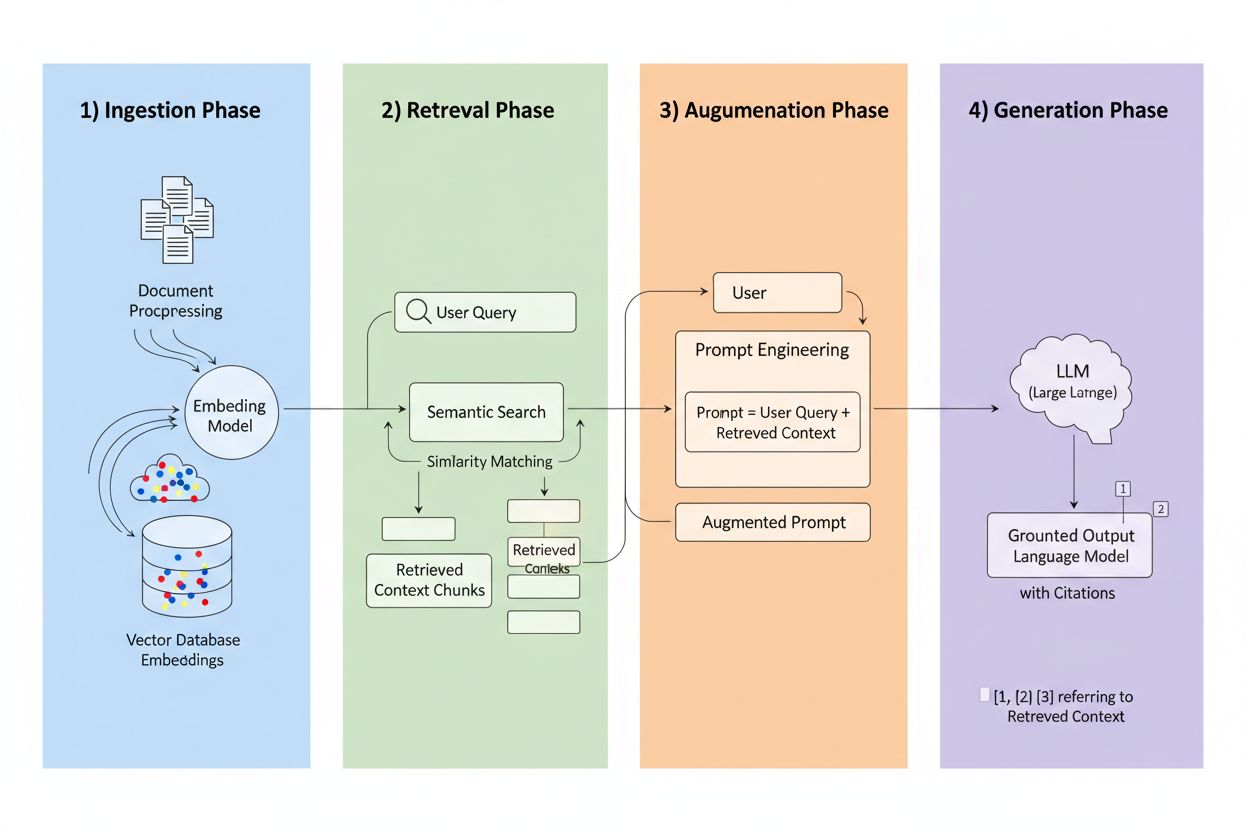
Retrieval-Augmented Generation (RAG) to ramy łączące generatywną moc LLM z precyzją systemów wyszukiwania informacji. Zamiast polegać wyłącznie na danych treningowych, systemy RAG pobierają odpowiednie informacje z zewnętrznych źródeł przed wygenerowaniem odpowiedzi, tworząc ciąg, który ugruntowuje odpowiedzi w rzeczywistych danych. Cztery główne składniki współpracują ze sobą: Ingestia (zamiana dokumentów w przeszukiwalne formaty), Wyszukiwanie (odnajdywanie najbardziej odpowiednich źródeł), Augmentacja (wzbogacenie promptu pobranym kontekstem) oraz Generacja (tworzenie finalnej odpowiedzi z cytowaniami). Oto jak RAG wypada w porównaniu do tradycyjnych podejść:
| Aspekt | Tradycyjny LLM | System RAG |
|---|---|---|
| Źródło wiedzy | Statyczne dane treningowe | Zewnętrzne zaindeksowane źródła |
| Cytowanie | Brak/halucynowane | Śledzone do źródeł |
| Dokładność | Podatność na błędy | Ugruntowane w faktach |
| Dane w czasie rzeczywistym | Nie | Tak |
| Ryzyko halucynacji | Wysokie | Niskie |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Silnik wyszukiwania jest sercem RAG i jest znacznie bardziej zaawansowany niż proste dopasowanie słów kluczowych. Dokumenty są przekształcane w wektory embedujące — matematyczne reprezentacje oddające znaczenie semantyczne — co pozwala systemowi znajdować podobne treści nawet wtedy, gdy słowa się nie pokrywają. System dzieli dokumenty na fragmenty, zazwyczaj 256–1024 tokenów, by zachować balans między kontekstem a precyzją wyszukiwania. Najbardziej zaawansowane systemy RAG stosują hybrydowe wyszukiwanie, łącząc podobieństwo semantyczne z klasycznym dopasowaniem słów kluczowych, by wychwycić zarówno powiązania pojęciowe, jak i dosłowne. Mechanizm rerankingu następnie ocenia kandydatów, często z użyciem modeli cross-encoder, które dokładniej określają trafność niż początkowe wyszukiwanie. Trafność wyliczana jest na podstawie wielu sygnałów: wyniki podobieństwa semantycznego, pokrycie słów kluczowych, zgodność metadanych i autorytet domeny. Cały proces trwa milisekundy, zapewniając szybkie, precyzyjne odpowiedzi bez zauważalnych opóźnień.
To tutaj RAG odmienia krajobraz cytowań: gdy system pobiera informację z konkretnego źródła, to źródło staje się identyfikowalne i weryfikowalne. Każdy fragment tekstu można powiązać z oryginalnym dokumentem, adresem URL czy publikacją, czyniąc cytowanie automatycznym zamiast halucynowanego. Ta fundamentalna zmiana tworzy niespotykaną przejrzystość decyzji AI — użytkownicy widzą, które źródła wpłynęły na odpowiedź, mogą samodzielnie zweryfikować twierdzenia i ocenić wiarygodność źródła. W przeciwieństwie do tradycyjnych LLM, gdzie cytowania są często wymyślone lub ogólne, cytowania RAG są ugruntowane w rzeczywistych zdarzeniach pobierania. Ta śledzalność radykalnie buduje zaufanie użytkowników, bo mogą oni zweryfikować informacje zamiast przyjmować je na wiarę. Dla twórców treści i wydawców oznacza to możliwość odkrycia i docenienia ich pracy przez systemy AI, otwierając zupełnie nowe kanały widoczności.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Nie wszystkie źródła są równe w systemach RAG, a kilka czynników decyduje, które treści są cytowane najczęściej:
Każdy czynnik potęguje pozostałe — dobrze zbudowany, często aktualizowany artykuł z autorytatywnej domeny, z silnymi linkami zwrotnymi i obecnością w grafie wiedzy, staje się magnesem na cytowania w systemach RAG. Powstaje nowy paradygmat optymalizacji, gdzie widoczność zależy mniej od SEO nastawionego na ruch, a bardziej od bycia zaufanym, uporządkowanym źródłem wiedzy.
Różne platformy AI wdrażają RAG w odmienny sposób, tworząc różnorodne wzorce cytowań. ChatGPT mocno preferuje źródła z Wikipedii; badania wskazują, że ok. 26–35% cytowań pochodzi wyłącznie z Wikipedii, co odzwierciedla jej autorytet i ustrukturyzowaną formę. Google AI Overviews stosuje bardziej zróżnicowany dobór źródeł, sięgając po serwisy newsowe, publikacje naukowe i fora, przy czym Reddit pojawia się w ok. 5% cytowań mimo niższego tradycyjnego autorytetu. Perplexity AI zazwyczaj cytuje 3–5 źródeł na odpowiedź i wyraźnie preferuje branżowe publikacje oraz najnowsze wiadomości, optymalizując pod kątem kompletności i aktualności. Platformy te różnie ważą autorytet domeny — jedne preferują tradycyjne wskaźniki, jak linki zwrotne i wiek domeny, inne kładą nacisk na świeżość i semantyczną zgodność treści. Zrozumienie tych platformowych strategii pobierania jest kluczowe dla twórców treści, bo optymalizacja pod jeden system RAG może się znacząco różnić od drugiego.
Wzrost znaczenia RAG fundamentalnie zmienia dotychczasową wiedzę SEO. W optymalizacji pod wyszukiwarki cytowania i widoczność są bezpośrednio powiązane z ruchem — musisz zdobyć kliknięcie, by mieć znaczenie. RAG odwraca to równanie: treść może być cytowana i wpływać na odpowiedzi AI bez generowania jakiegokolwiek ruchu. Dobrze zbudowany, autorytatywny artykuł może pojawiać się w dziesiątkach odpowiedzi AI dziennie, nie generując żadnych kliknięć, bo użytkownicy otrzymują odpowiedź bezpośrednio z podsumowania AI. Oznacza to, że sygnały autorytetu są ważniejsze niż kiedykolwiek, bo są głównym mechanizmem oceny jakości źródła przez systemy RAG. Kluczowa staje się spójność na różnych platformach — jeśli Twoje treści pojawiają się na stronie, LinkedIn, w branżowych bazach i grafach wiedzy, systemy RAG widzą wzmocnione sygnały autorytetu. Obecność w grafach wiedzy staje się nie tylko pożądana, ale wręcz niezbędna, bo te uporządkowane bazy są głównym źródłem dla wielu wdrożeń RAG. Gra o cytowania zmieniła się z „generuj ruch” na „stań się zaufanym źródłem wiedzy”.
Aby zmaksymalizować cytowania przez RAG, strategia treści musi przesunąć się z optymalizacji pod ruch na optymalizację pod źródło. Wdrażaj cykle aktualizacji co 48–72 godziny dla treści evergreen, sygnalizując systemom pobierającym, że Twoje informacje są aktualne. Stosuj uporządkowane dane (Schema.org, JSON-LD), by pomóc systemom zrozumieć znaczenie i zależności w treści. Dopasuj treści semantycznie do typowych wzorców zapytań — używaj naturalnego języka, takiego w jaki sposób ludzie formułują pytania, a nie tylko jak je wyszukują. Formatuj treści z sekcjami FAQ i Q&A, bo odpowiadają one bezpośrednio wzorcowi pytanie–odpowiedź używanemu przez RAG. Twórz lub współtwórz wpisy w Wikipedii i grafach wiedzy, bo to główne źródła pobierania dla większości platform. Buduj autorytet poprzez linki zwrotne z innych zaufanych źródeł, bo profil linków nadal jest silnym sygnałem autorytetu. Wreszcie, dbaj o spójność między platformami — upewnij się, że Twoje kluczowe tezy, dane i przekaz są zgodne na stronie, w profilach społecznościowych, branżowych bazach i grafach wiedzy, budując wzmocnione sygnały wiarygodności.
Technologia RAG szybko się rozwija, a kilka trendów zmienia sposób działania cytowań. Bardziej zaawansowane algorytmy wyszukiwania wyjdą poza podobieństwo semantyczne w kierunku głębszego rozumienia intencji i kontekstu zapytania, poprawiając trafność cytowań. Specjalistyczne bazy wiedzy pojawią się dla konkretnych branż — medyczne RAG korzystające z literatury naukowej, systemy prawne z orzecznictwa i ustaw — tworząc nowe możliwości cytowań dla autorytatywnych źródeł branżowych. Integracja z systemami multi-agentowymi pozwoli RAG orkiestrację wielu wyspecjalizowanych retrieverów, łącząc wiedzę z różnych baz dla pełniejszych odpowiedzi. Dostęp do danych w czasie rzeczywistym znacznie się poprawi, umożliwiając RAG korzystanie z danych live z API, baz i źródeł strumieniowych. Agentowy RAG — gdzie agenci AI autonomicznie decydują, co pobrać, jak to przetworzyć i kiedy iterować — stworzy dynamiczne wzorce cytowań, potencjalnie cytując te same źródła wielokrotnie podczas doskonalenia rozumowania.
W miarę jak RAG zmienia sposób, w jaki systemy AI odkrywają i cytują źródła, zrozumienie Twojej skuteczności w cytowaniach staje się kluczowe. AmICited monitoruje cytowania AI na różnych platformach, śledząc, które z Twoich źródeł pojawiają się w ChatGPT, Google AI Overviews, Perplexity i nadchodzących systemach AI. Zobaczysz które konkretne źródła są cytowane, jak często się pojawiają i w jakim kontekście — odkrywając, które treści rezonują z algorytmami pobierania RAG. Nasza platforma pomaga zrozumieć wzorce cytowań w całym portfolio treści, wskazując, co sprawia, że jedne materiały są cytowane, inne pozostają niewidoczne. Mierz widoczność marki w odpowiedziach AI za pomocą wskaźników istotnych w erze RAG, wykraczając poza tradycyjną analitykę ruchu. Przeprowadzaj analizy porównawcze skuteczności cytowań, sprawdzając jak Twoje źródła wypadają na tle konkurencji w odpowiedziach generowanych przez AI. W świecie, w którym cytowania AI napędzają widoczność i autorytet, jasny wgląd w swoje cytowania nie jest opcją — to warunek, by pozostać konkurencyjnym.
Dowiedz się, jak Twoja marka pojawia się w odpowiedziach generowanych przez AI w ChatGPT, Perplexity, Google AI Overviews i innych. Śledź wzorce cytowań, mierz widoczność i optymalizuj obecność w krajobrazie wyszukiwania napędzanym przez AI.
Dowiedz się, jak RAG łączy LLM z zewnętrznymi źródłami danych, aby generować precyzyjne odpowiedzi AI. Poznaj pięcioetapowy proces, komponenty oraz znaczenie te...
Dowiedz się, czym jest RAG (Retrieval-Augmented Generation) w wyszukiwaniu AI. Odkryj, jak RAG zwiększa dokładność, ogranicza halucynacje i napędza ChatGPT, Per...
Dowiedz się, jak bazy wiedzy poprawiają cytowanie przez AI dzięki technologii RAG, umożliwiając dokładne przypisywanie źródeł na platformach takich jak ChatGPT,...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.