
Archivo LLMs.txt
Descubre qué son los archivos LLMs.txt, en qué se diferencian de robots.txt y por qué son esenciales para la visibilidad y citaciones en ChatGPT, Perplexity y G...
12 min de lectura

Análisis crítico de la efectividad de LLMs.txt. Descubre si este estándar de contenido para IA es esencial para tu sitio o solo es una moda. Datos reales sobre adopción, soporte de plataformas y lo que realmente funciona para la visibilidad en IA.
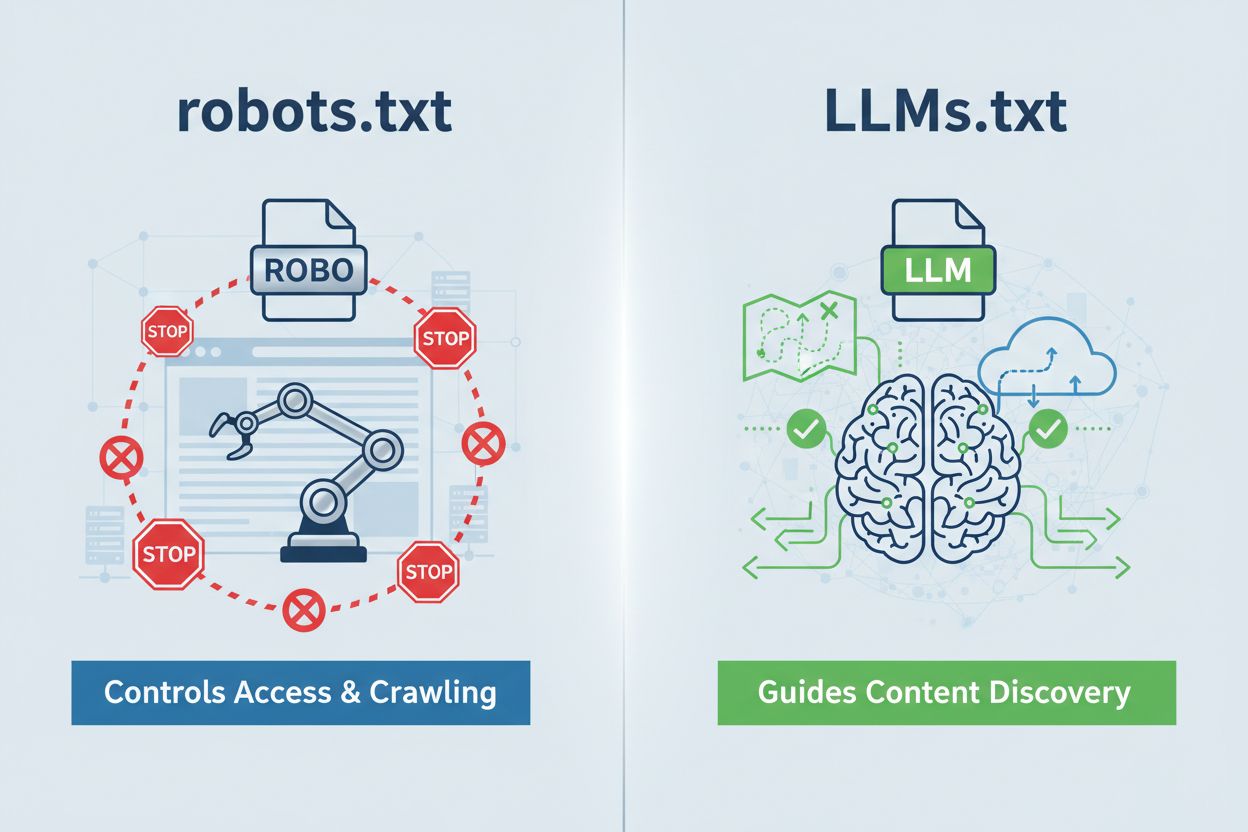
LLMs.txt es un archivo de texto plano ubicado en dominio.com/llms.txt que sirve como guía seleccionada para que los sistemas de IA descubran tu contenido de mayor calidad. Es fundamentalmente diferente de robots.txt: mientras robots.txt controla si los rastreadores de IA pueden acceder a tu sitio, LLMs.txt opera en acceso en tiempo de inferencia, ayudando a los sistemas de IA a entender qué páginas merecen prioridad al generar respuestas. Piénsalo menos como un agente de tránsito y más como un mapa del tesoro: no impide la exploración, simplemente resalta dónde está el verdadero valor. El formato es refrescantemente simple: markdown plano sin sintaxis compleja, lo que lo hace accesible para cualquier organización sin importar su sofisticación técnica. Esta distinción importa porque replantea toda la conversación: LLMs.txt no trata de controlar el rastreo, sino de optimizar cómo los sistemas de IA interpretan y priorizan tu contenido legible por IA una vez que ya te han encontrado.
Las cifras sugieren una verdadera tracción: más de 844,000 sitios web han implementado LLMs.txt a octubre de 2025, con la adopción concentrada en empresas que comprenden el papel de la IA en su futuro. Grandes actores como Anthropic, Cloudflare, Stripe, Vercel y Supabase han implementado el estándar, señalando que las empresas de infraestructura más serias ven valor en el experimento. La decisión de Mintlify de habilitar la generación automática para miles de sitios de documentación en noviembre de 2024 provocó un fuerte repunte en la adopción, demostrando que el soporte de herramientas puede acelerar la implementación. Tres directorios comunitarios rastrean ahora implementaciones, con más de 788 sitios verificados documentados entre ellos. Sin embargo, el patrón de adopción revela algo importante: la implementación se concentra fuertemente en herramientas para desarrolladores y plataformas de documentación, los sectores que más probablemente se beneficien de la visibilidad en IA. Así luce realmente el panorama de adopción:
| Empresa/Plataforma | Implementación | Conteo de tokens | Estado |
|---|---|---|---|
| Anthropic | Sí | ~2,000 | Activo |
| Cloudflare | Sí | ~5,000 | Activo |
| Stripe | Sí | ~8,000 | Activo |
| Vercel | Sí | ~3,500 | Activo |
| Supabase | Sí | ~4,200 | Activo |
| Mintlify (auto-generado) | Sí | Variable | Activo |
Aquí es donde el escepticismo se justifica: NINGUNA gran plataforma de IA ha confirmado oficialmente el uso de LLMs.txt en sus sistemas de recuperación. John Mueller de Google lo dijo claramente: “Ningún sistema de IA usa actualmente llms.txt”, un comentario que debió cerrar el tema, pero de algún modo no lo hizo. OpenAI, Anthropic, Google, Microsoft y Perplexity han mantenido un silencio estratégico al respecto: sin documentación oficial, sin confirmación de uso, sin hojas de ruta públicas. Hay evidencia de que algunas plataformas rastrean los archivos (se ha observado a bots de Microsoft y OpenAI obteniendo archivos LLMs.txt), pero rastrear y realmente usar son cosas totalmente diferentes. La interpretación optimista sugiere que las plataformas están probando silenciosamente antes de comprometerse públicamente; la interpretación escéptica sugiere que nunca lo adoptarán porque no resuelve un problema real. Ese silencio es el núcleo del argumento de que está “sobrevalorado”: 18 meses después de la propuesta, tenemos una adopción generalizada pero cero adopción oficial por parte de plataformas. Eso no es un estándar: es una esperanza.
La posición escéptica se basa en una idea simple: no hay pruebas de que LLMs.txt mejore la recuperación de IA, aumente el tráfico o mejore la visibilidad del contenido. El problema de la confianza es más profundo: al crear un archivo separado que puede contener contenido diferente al de tu HTML, básicamente facilitas la manipulación. Investigaciones sobre el comportamiento de los LLM muestran que son 2.5 veces más propensos a recomendar contenido específicamente resaltado o dirigido, lo que crea incentivos evidentes para el juego sucio. Una organización podría poblar LLMs.txt solo con su mejor contenido y ocultar las páginas más débiles, o peor, incluir contenido en LLMs.txt que ni siquiera existe en su sitio. Los proveedores de herramientas SEO han amplificado la presión marcando la ausencia de LLMs.txt como oportunidad de optimización: Rank Math, SEMrush y otros han creado un ciclo donde los sitios implementan el estándar no porque funcione, sino porque las herramientas lo indican como algo faltante. Este es el verdadero problema: 18 meses de presión para implementar y ni un solo caso documentado de valor medible. Es el equivalente digital de que todos compren un billete de lotería porque la compañía de lotería sigue anunciando.
El campo pro-LLMs.txt hace un argumento diferente, basado en el cambio inevitable más que en pruebas actuales. Carolyn Shelby de Yoast lo expresó perfectamente: “El ranking ya no es el premio: la inclusión lo es.” Windsurf, un editor de código con IA, reportó que LLMs.txt ahorra tiempo y tokens al analizar documentación, sugiriendo ganancias reales de eficiencia para sistemas de IA que sí lo usan. Anthropic solicitó específicamente que Mintlify implementara LLMs.txt para su documentación, lo que implica valor interno aunque no lo confirmen públicamente. Google incluyó LLMs.txt en su protocolo A2A (Agentes a Agentes), lo que sugiere que la empresa lo ve como parte de la infraestructura futura para la comunicación IA-IA. Implementarlo toma de 1 a 4 horas y no tiene desventajas demostradas: no rompes nada, no perjudicas el SEO, solo creas un archivo. Jeremy Howard lo resume así: “El 99.9% de la atención será atención de LLM, no humana,” lo que significa que optimizar para sistemas de IA no es opcional, es inevitable. Springs Apps reportó un aumento del 20% en visibilidad de búsqueda tras implementarlo, aunque esto no está verificado y podría ser simple correlación.
Entender por qué LLMs.txt podría fracasar requiere examinar por qué otros estándares sí tuvieron éxito. Robots.txt funcionó porque generó beneficio mutuo con costo mínimo y recibió soporte oficial de RFC (RFC 9309): los motores de búsqueda querían rastrear eficientemente, los sitios controlar el rastreo y la solución era tan simple que la adopción fue sin fricción. Schema.org triunfó gracias al desarrollo multilateral con Google, Microsoft, Yahoo y Yandex desde el principio: ninguna empresa tenía la propiedad, lo que generó confianza. Sitemap.xml logró soporte amplio de plataformas antes de la adopción masiva, no después. LLMs.txt carece de esos tres factores clave: no hay participación del W3C, ni respaldo de consorcio, ni soporte oficial de plataformas, ni valor demostrado en tráfico, rankings o precisión. Lo que hace que un estándar funcione es la aceptación de múltiples partes interesadas, beneficios claros y medibles y bajo potencial de manipulación. LLMs.txt tiene esperanza, adopción entre los primeros creyentes y soporte de herramientas, pero no cuenta con los elementos que transformaron experimentos previos en infraestructura real.
Si LLMs.txt sigue sin probarse, ¿qué realmente marca la diferencia en visibilidad y citas por IA? La respuesta es menos exótica que un nuevo formato de archivo:
Estas tácticas funcionan porque se alinean con la forma en que los sistemas de IA procesan la información, no porque estén optimizadas para un archivo específico.

La conversación sobre LLMs.txt refleja un cambio más profundo en cómo el contenido tiene éxito en línea: la convergencia entre experiencia de usuario humana y optimización para IA. Las investigaciones sobre Generative Engine Optimization (GEO) muestran que el contenido que gana en respuestas generadas por IA comparte características específicas: claridad, estructura, autoridad y especificidad. Vercel reportó que el 10% de sus registros ahora provienen directamente de menciones en ChatGPT y no de búsqueda orgánica tradicional, una métrica impensable hace cinco años. El éxito cada vez más significa aparecer en respuestas generadas por IA, no solo rankear en resultados orgánicos: son objetivos y requisitos distintos de optimización. El universo de herramientas ha evolucionado para rastrear este cambio: SEMrush AIO, el tracking GEO de Profound y Ahrefs Brand Radar ahora monitorean visibilidad en IA junto con rankings tradicionales. El cambio fundamental es: ser citado importa más que estar rankeado y ser referenciado importa más que ser indexado. Este cambio explica por qué LLMs.txt ganó tracción pese a no tener soporte oficial: representa un intento de optimizar para una nueva economía de atención donde la IA es el canal principal de distribución.
Si decides implementarlo, hazlo bien. El archivo debe estar en dominio.com/llms.txt (ojo: plural, no singular), en formato markdown de texto plano y no XML o JSON. Comienza con un encabezado H1 con el nombre de tu sitio, seguido opcionalmente de un bloque de cita con el resumen del propósito del sitio. Organiza el contenido en secciones H2 si tu sitio tiene áreas distintas (Documentación, Blog, API, etc.), con descripciones que expliquen qué contiene cada sección. Usa el formato [Título](URL): Descripción para cada página, manteniendo las descripciones concisas pero informativas. Qué incluir: contenido atemporal, páginas bien estructuradas y piezas que demuestren experiencia genuina. Qué evitar: la página de inicio (normalmente no tiene valor en aislamiento), todas las URLs del sitio (calidad sobre cantidad) y páginas que no tienen sentido fuera de contexto. Ejemplo básico de estructura:
# Nombre de la empresa
> Breve descripción de lo que hace tu empresa y por qué los sistemas de IA deberían interesarse por tu contenido
## Documentación
[Comenzando](https://example.com/docs/getting-started): Guía paso a paso para nuevos usuarios
[Referencia de API](https://example.com/docs/api): Documentación completa de API con ejemplos
[Mejores prácticas](https://example.com/docs/best-practices): Patrones probados para usar nuestra plataforma
## Blog
[Por qué construimos esto](https://example.com/blog/why-we-built-this): El problema que resolvimos y cómo lo hicimos
Opcionalmente puedes incluir una sección de URLs a omitir si se necesita un contexto más corto, aunque la mayoría de implementaciones no requiere tanta granularidad.
Sí, deberías implementar LLMs.txt. No porque esté probado que funcione, sino porque el riesgo es nulo y el potencial es real. Si las plataformas de IA nunca lo adoptan oficialmente, el archivo simplemente quedará en tu servidor sin impacto: sin penalización SEO, sin pérdida de tráfico, sin funciones rotas. Implementarlo toma unos 10 minutos para un sitio pequeño y quizás una hora para propiedades grandes. Mientras tanto, el tráfico se fragmenta entre varios sistemas de IA: ChatGPT, Perplexity, Claude y otros competidores manejan colectivamente cientos de millones de consultas mensuales. Ya eres visible para los sistemas de IA: LLMs.txt solo les ayuda a encontrar tu mejor contenido en vez de páginas aleatorias. Incluso si nunca se convierte en estándar, estarás entrenando a la IA para entender mejor la estructura y prioridades de tu sitio, lo que tiene valor por sí mismo. El verdadero aprendizaje es: cubre tus apuestas gratis. Implementa el estándar, optimiza tu contenido para visibilidad en IA con tácticas comprobadas y monitorea qué realmente trae tráfico de sistemas de IA. En 12 meses tendrás datos reales sobre si LLMs.txt importa para tu negocio, y eso es infinitamente más valioso que especular.
LLMs.txt es un archivo de texto plano que guía a los sistemas de IA hacia tu mejor contenido para acceso en tiempo de inferencia, mientras que robots.txt controla el acceso y la indexación de los rastreadores. LLMs.txt no restringe nada: selecciona y resalta tus páginas más valiosas para la comprensión de la IA. Piensa en robots.txt como un agente de tránsito y en LLMs.txt como un mapa del tesoro.
No oficialmente. A pesar de que más de 844,000 sitios web lo han implementado, ninguna gran plataforma de IA ha confirmado que use LLMs.txt para generar respuestas. Hay algunas pruebas de actividad de rastreo por parte de bots de OpenAI y Microsoft, pero no hay un uso confirmado para inferencia o citas. Este es el núcleo del argumento de que está 'sobrevalorado'.
Sí. Implementarlo toma de 10 a 30 minutos y no tiene desventajas. Si las plataformas lo adoptan, ya estarás preparado. Si no lo hacen, el archivo no causa ningún daño. Es una apuesta de bajo riesgo y posible recompensa para la visibilidad en IA. Básicamente, estás apostando por el futuro del descubrimiento de contenido mediado por IA.
Incluye contenido atemporal y bien estructurado que responda preguntas específicas: guías, preguntas frecuentes, documentación de API, contenido pilar y piezas de autoridad. Evita tu página de inicio, todas las URL de tu sitio y páginas que no tengan sentido citadas fuera de contexto. La clave es la calidad por encima de la cantidad.
Sí, esta es una preocupación legítima. Podrías colocar contenido diferente en LLMs.txt de lo que aparece en tus páginas reales, lo que rompe la confianza. Por eso algunos expertos siguen siendo escépticos sobre la viabilidad a largo plazo del estándar y la adopción por parte de las plataformas es cautelosa.
llms.txt contiene enlaces seleccionados a tus mejores páginas con descripciones. llms-full.txt es una versión completa con toda tu documentación en un solo archivo masivo (a veces más de 400,000 palabras). Usa llms-full.txt si quieres dar a los sistemas de IA todo de entrada sin requerir que sigan enlaces.
LLMs.txt es una herramienta dentro de la estrategia general de GEO. GEO se centra en hacer que tu contenido sea descubrible y citable por sistemas de IA mediante estructura clara, citas, datos y experiencia de autoridad. LLMs.txt ayuda a guiar a los sistemas de IA hacia tu mejor contenido optimizado para GEO.
Sí. Cualquier sitio web se beneficia ayudando a que los sistemas de IA entiendan y citen tu contenido. Blogs, negocios locales, tiendas en línea y comunidades de nicho reciben tráfico de la búsqueda potenciada por IA. LLMs.txt es una forma simple de mejorar tu visibilidad en ChatGPT, Claude, Perplexity y otras plataformas de IA.
Haz seguimiento de cómo sistemas de IA como ChatGPT, Claude y Perplexity referencian tu contenido. Obtén información en tiempo real sobre tus citas y visibilidad entre plataformas de IA.
Descubre qué son los archivos LLMs.txt, en qué se diferencian de robots.txt y por qué son esenciales para la visibilidad y citaciones en ChatGPT, Perplexity y G...

Descubre qué es LLMs.txt, si realmente funciona y si deberías implementarlo en tu sitio web. Análisis honesto de este emergente estándar de SEO para IA.

Aprende cómo implementar LLMs.txt en tu sitio web para ayudar a los sistemas de IA a comprender mejor tu contenido. Guía completa paso a paso para todas las pla...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.