Etiquetas Meta NoAI: Controlando el Acceso de la IA a Través de Encabezados
Aprende cómo implementar las etiquetas meta noai y noimageai para controlar el acceso de rastreadores de IA al contenido de tu sitio web. Guía completa sobre encabezados de control de acceso de IA y métodos de implementación.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Entendiendo los Rastreadoreos Web y las Etiquetas Meta
Los rastreadores web son programas automatizados que navegan sistemáticamente por Internet, recolectando información de sitios web. Históricamente, estos bots eran operados principalmente por motores de búsqueda como Google, cuyo Googlebot rastreaba páginas, indexaba contenido y enviaba usuarios de vuelta a los sitios web a través de resultados de búsqueda—creando una relación mutuamente beneficiosa. Sin embargo, la aparición de rastreadores de IA ha cambiado fundamentalmente esta dinámica. A diferencia de los bots tradicionales de motores de búsqueda que proporcionan tráfico de referencia a cambio de acceso al contenido, los rastreadores de entrenamiento de IA consumen grandes cantidades de contenido web para construir conjuntos de datos para modelos de lenguaje grande, devolviendo a menudo un tráfico mínimo o nulo a los editores. Este cambio ha hecho que las etiquetas meta—pequeñas directivas HTML que comunican instrucciones a los rastreadores—sean cada vez más importantes para los creadores de contenido que desean mantener el control sobre cómo su trabajo es utilizado por sistemas de inteligencia artificial.
¿Qué Son las Etiquetas Meta NoAI y NoImageAI?
Las etiquetas meta noai y noimageai son directivas creadas por DeviantArt en 2022 para ayudar a los creadores de contenido a evitar que su trabajo sea usado para entrenar generadores de imágenes por IA. Estas etiquetas funcionan de manera similar a la conocida directiva noindex que indica a los motores de búsqueda que no indexen una página. La directiva noai señala que ningún contenido de la página debe ser usado para entrenar IA, mientras que noimageai previene específicamente que las imágenes sean utilizadas para entrenamiento de modelos de IA. Puedes implementar estas etiquetas en la sección head de tu HTML usando la siguiente sintaxis:
<!-- Bloquear todo el contenido para entrenamiento de IA --><metaname="robots"content="noai">
<!-- Bloquear solo imágenes para entrenamiento de IA --><metaname="robots"content="noimageai">
<!-- Bloquear tanto contenido como imágenes --><metaname="robots"content="noai, noimageai">
Aquí tienes una tabla comparativa de diferentes directivas de etiquetas meta y sus propósitos:
Directiva
Propósito
Sintaxis
Alcance
noai
Previene todo el contenido para IA
content="noai"
Todo el contenido de la página
noimageai
Previene imágenes para IA
content="noimageai"
Solo imágenes
noindex
Evita la indexación en motores de búsqueda
content="noindex"
Resultados de búsqueda
nofollow
Evita que sigan los enlaces
content="nofollow"
Enlaces salientes
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Diferencia Entre Etiquetas Meta y Encabezados HTTP
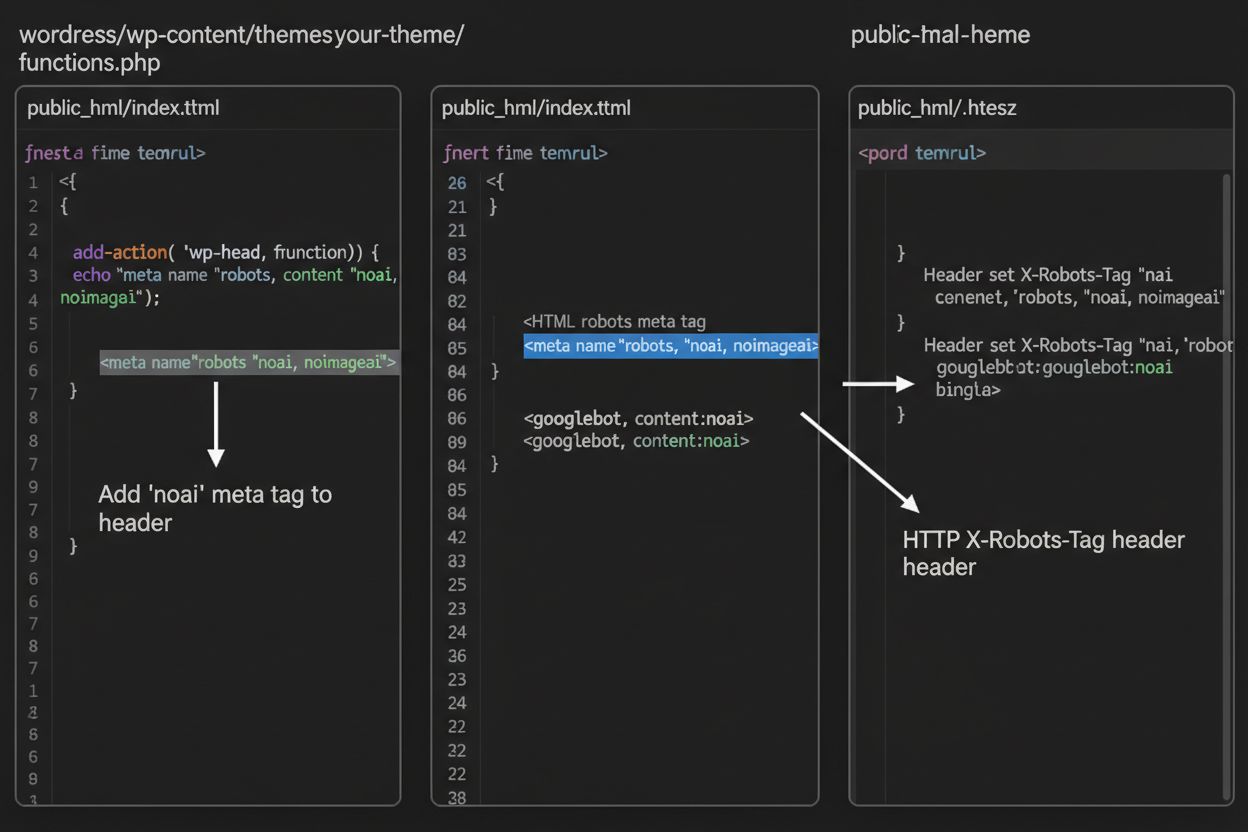
Mientras que las etiquetas meta se colocan directamente en tu HTML, los encabezados HTTP ofrecen un método alternativo para comunicar directivas a rastreadores a nivel de servidor. El encabezado X-Robots-Tag puede incluir las mismas directivas que las etiquetas meta, pero funciona de manera diferente: se envía en la respuesta HTTP antes de que se entregue el contenido de la página. Este enfoque es especialmente valioso para controlar el acceso a archivos que no son HTML, como PDFs, imágenes y videos, donde no puedes insertar etiquetas meta HTML.
Para servidores Apache, puedes establecer encabezados X-Robots-Tag en tu archivo .htaccess:
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
Para servidores NGINX, añade el encabezado en la configuración de tu servidor:
Los encabezados proporcionan protección global en todo tu sitio o directorios específicos, lo que los hace ideales para estrategias integrales de control de acceso de IA.
Cómo los Rastreadoreos de IA Respetan (o Ignoran) Estas Directivas
La efectividad de las etiquetas noai y noimageai depende completamente de si los rastreadores deciden respetarlas. Los rastreadores bien comportados de grandes empresas de IA generalmente respetan estas directivas:
GPTBot (OpenAI) - Respeta las directivas noai
ClaudeBot (Anthropic) - Respeta las directivas noai
PerplexityBot (Perplexity) - Respeta las directivas noai
Amazonbot (Amazon) - Respeta las directivas noai
CCBot (Common Crawl) - Respeta las directivas noai
Rastreadores pequeños/desconocidos - Pueden no respetar las directivas
Sin embargo, bots mal comportados y rastreadores maliciosos pueden ignorar deliberadamente estas directivas porque no existe un mecanismo de aplicación. A diferencia de robots.txt, que los motores de búsqueda han aceptado respetar como estándar de la industria, noai no es un estándar web oficial, lo que significa que los rastreadores no tienen obligación de cumplirlo. Por eso los expertos en seguridad recomiendan un enfoque por capas que combine varios métodos de protección en lugar de depender exclusivamente de las etiquetas meta.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Métodos de Implementación en Diferentes Plataformas
La implementación de las etiquetas noai y noimageai varía según la plataforma de tu sitio web. Aquí tienes instrucciones paso a paso para las plataformas más comunes:
1. WordPress (vía functions.php)
Agrega este código al archivo functions.php de tu tema hijo:
3. Squarespace
Navega a Configuración > Avanzado > Inyección de código y añade en la sección Header:
<metaname="robots"content="noai, noimageai">
4. Wix
Ve a Configuración > Código personalizado, haz clic en “Agregar código personalizado”, pega la etiqueta meta, selecciona “Head” y aplícalo a todas las páginas.
Cada plataforma ofrece diferentes niveles de control—WordPress permite implementación por página mediante plugins, mientras que Squarespace y Wix brindan opciones globales para todo el sitio. Elige el método que mejor se adapte a tu nivel técnico y necesidades específicas.
Limitaciones y Efectividad de las Etiquetas NoAI
Si bien las etiquetas noai y noimageai representan un paso importante hacia la protección del creador de contenido, tienen limitaciones significativas. Primero, no son estándares web oficiales—DeviantArt las creó como una iniciativa comunitaria, lo que significa que no existe una especificación formal ni un mecanismo de aplicación. Segundo, el cumplimiento es completamente voluntario. Los rastreadores bien comportados de grandes compañías las respetan, pero los bots maliciosos y los scrapers pueden ignorarlas sin consecuencia. Tercero, la falta de estandarización implica una adopción variable. Algunas empresas de IA más pequeñas y organizaciones de investigación pueden ni siquiera estar al tanto de estas directivas, mucho menos implementarlas. Finalmente, las etiquetas meta solas no pueden prevenir que actores maliciosos decididos raspen tu contenido. Un rastreador malicioso puede ignorar completamente tus directivas, por lo que son esenciales capas adicionales de protección para una seguridad integral del contenido.
Combinando Etiquetas Meta con robots.txt y Otros Métodos
La estrategia de control de acceso de IA más efectiva utiliza múltiples capas de protección en lugar de depender de un solo método. Aquí tienes una comparación de diferentes enfoques de protección:
Método
Alcance
Efectividad
Dificultad
Etiquetas Meta (noai)
Por página
Media (cumplimiento voluntario)
Fácil
robots.txt
Todo el sitio
Media (solo asesoramiento)
Fácil
Encabezados X-Robots-Tag
A nivel servidor
Media-Alta (todos los tipos de archivo)
Media
Reglas de Firewall
A nivel red
Alta (bloquea en la infraestructura)
Difícil
Lista Blanca de IPs
A nivel red
Muy Alta (solo fuentes verificadas)
Difícil
Una estrategia integral podría incluir: (1) implementar etiquetas meta noai en todas las páginas, (2) añadir reglas robots.txt bloqueando rastreadores de entrenamiento de IA conocidos, (3) configurar encabezados X-Robots-Tag a nivel de servidor para archivos que no son HTML y (4) monitorear los registros del servidor para identificar rastreadores que ignoran tus directivas. Este enfoque por capas aumenta significativamente la dificultad para los actores maliciosos y mantiene la compatibilidad con rastreadores bien comportados que respetan tus preferencias.
Monitoreo y Verificación del Cumplimiento de Rastreadores
Tras implementar las etiquetas noai y otras directivas, deberías verificar que los rastreadores realmente estén respetando tus reglas. El método más directo es revisar los registros de acceso del servidor para detectar actividad de rastreadores. En servidores Apache, puedes buscar rastreadores específicos:
Si ves solicitudes de rastreadores que has bloqueado, están ignorando tus directivas. Para servidores NGINX, revisa /var/log/nginx/access.log usando el mismo comando grep. Además, herramientas como Cloudflare Radar te ofrecen visibilidad sobre los patrones de tráfico de rastreadores de IA en tu sitio, mostrando qué bots son más activos y cómo cambian sus comportamientos con el tiempo. Monitorear regularmente los registros—al menos mensualmente—te ayuda a identificar nuevos rastreadores y verificar que tus medidas de protección funcionen según lo previsto.
El Futuro de los Estándares de Control de Acceso de IA
Actualmente, noai y noimageai existen en una zona gris: son ampliamente reconocidas y respetadas por las principales empresas de IA, pero siguen siendo no oficiales y no estandarizadas. Sin embargo, hay un impulso creciente hacia la estandarización formal. El W3C (World Wide Web Consortium) y varios grupos de la industria están discutiendo cómo crear estándares oficiales para el control de acceso de IA, que darían a estas directivas el mismo peso que los estándares establecidos como robots.txt. Si noai se convierte en un estándar web oficial, el cumplimiento pasaría a ser una práctica esperada de la industria en lugar de voluntaria, aumentando significativamente su efectividad. Este esfuerzo de estandarización refleja un cambio más amplio en cómo la industria tecnológica ve los derechos de los creadores de contenido y el equilibrio entre el desarrollo de IA y la protección de los editores. A medida que más editores adopten estas etiquetas y demanden protecciones más sólidas, aumenta la probabilidad de estandarización oficial, lo que podría hacer que el control de acceso de IA sea tan fundamental para la gobernanza web como las reglas de indexación de motores de búsqueda.
Preguntas frecuentes
¿Qué es la etiqueta meta noai y cómo funciona?
La etiqueta meta noai es una directiva que se coloca en la sección head del HTML de tu sitio web y que indica a los rastreadores de IA que tu contenido no debe ser utilizado para entrenar modelos de inteligencia artificial. Funciona comunicando tu preferencia a los bots de IA bien comportados, aunque no es un estándar web oficial y algunos rastreadores pueden ignorarla.
¿Noai es un estándar web oficial?
No, noai y noimageai no son estándares web oficiales. Fueron creados por DeviantArt como una iniciativa comunitaria para ayudar a los creadores de contenido a proteger su trabajo del entrenamiento de IA. Sin embargo, grandes empresas de IA como OpenAI, Anthropic y otras han comenzado a respetar estas directivas en sus rastreadores.
¿Qué rastreadores de IA respetan la etiqueta meta noai?
Los principales rastreadores de IA, incluyendo GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) y otros, respetan la directiva noai. Sin embargo, algunos rastreadores más pequeños o mal implementados pueden ignorarla, por lo que se recomienda un enfoque de protección por capas.
¿Cuál es la diferencia entre etiquetas meta y encabezados HTTP para el control de IA?
Las etiquetas meta se colocan en la sección head de tu HTML y se aplican a páginas individuales, mientras que los encabezados HTTP (X-Robots-Tag) se configuran a nivel de servidor y pueden aplicarse globalmente o a tipos de archivos específicos. Los encabezados funcionan para archivos que no son HTML, como PDFs e imágenes, lo que los hace más versátiles para una protección integral.
¿Puedo implementar etiquetas noai en WordPress?
Sí, puedes implementar etiquetas noai en WordPress mediante varios métodos: agregando código al archivo functions.php de tu tema, usando un plugin como WPCode o a través de herramientas de creación de páginas como Divi y Elementor. El método de functions.php es el más común e implica añadir un sencillo hook para inyectar la etiqueta meta en el encabezado de tu sitio.
¿Debo bloquear todos los rastreadores de IA o solo los de entrenamiento?
Esto depende de los objetivos de tu negocio. Bloquear los rastreadores de entrenamiento protege tu contenido de ser usado en el desarrollo de modelos de IA. Sin embargo, bloquear rastreadores de búsqueda como OAI-SearchBot puede reducir tu visibilidad en resultados de búsqueda potenciados por IA y plataformas de descubrimiento. Muchos editores usan un enfoque selectivo que bloquea los rastreadores de entrenamiento y permite los de búsqueda.
¿Cómo puedo verificar que los rastreadores de IA respetan mis directivas noai?
Puedes revisar los registros de tu servidor buscando actividad de rastreadores con comandos como grep para buscar agentes de usuario de bots específicos. Herramientas como Cloudflare Radar ofrecen visibilidad sobre los patrones de tráfico de rastreadores de IA. Monitorea tus registros regularmente para ver si los rastreadores bloqueados siguen accediendo a tu contenido, lo que indicaría que están ignorando tus directivas.
¿Qué debo hacer si los rastreadores ignoran mis etiquetas meta noai?
Si los rastreadores ignoran tus etiquetas meta, implementa capas de protección adicionales incluyendo reglas robots.txt, encabezados HTTP X-Robots-Tag y bloqueos a nivel de servidor mediante .htaccess o reglas de firewall. Para una verificación más fuerte, utiliza listas blancas de IP para permitir solo solicitudes de direcciones IP verificadas publicadas por grandes empresas de IA.
¿A qué rastreadores de IA debo permitir el acceso? Guía completa para 2025
Descubre qué rastreadores de IA permitir o bloquear en tu robots.txt. Guía completa que cubre GPTBot, ClaudeBot, PerplexityBot y más de 25 rastreadores de IA co...
Cómo Permitir que los Bots de IA Rastreen tu Sitio Web: Guía Completa de robots.txt y llms.txt
Aprende cómo permitir que bots de IA como GPTBot, PerplexityBot y ClaudeBot rastreen tu sitio. Configura robots.txt, crea llms.txt y optimiza para la visibilida...
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
10 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.