Republicación de contenido para IA: Consideraciones sobre contenido duplicado
Aprenda cómo la republicación de contenido genera problemas de contenido duplicado que dañan la visibilidad en búsquedas de IA de manera más grave que en búsquedas tradicionales. Descubra salvaguardas técnicas y mejores prácticas.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Republicar contenido en múltiples canales, plataformas y formatos es una estrategia legítima y, a menudo, necesaria para maximizar el alcance y la participación. Sin embargo, esta práctica genera una tensión fundamental con la forma en que los sistemas de búsqueda—especialmente los impulsados por IA—procesan y clasifican el contenido. El desafío no es si puedes republicar, sino si lo haces de manera que no sabotee tu visibilidad en los resultados de búsqueda de IA. A diferencia de los motores de búsqueda tradicionales, que han desarrollado sofisticados mecanismos de detección de duplicados durante décadas, los sistemas de IA abordan el contenido duplicado de manera diferente, creando nuevos riesgos que muchos editores aún no han aprendido a abordar.
Cómo gestionan los sistemas de IA el contenido republicado
Según la documentación técnica de Microsoft sobre Copilot y búsqueda por IA, “los LLM agrupan URLs casi duplicadas en un solo clúster y luego eligen una página para representar el conjunto.” Este comportamiento de agrupamiento es fundamentalmente diferente de cómo el algoritmo PageRank de Google distribuye autoridad entre las páginas duplicadas. En lugar de consolidar señales, los sistemas de IA toman una decisión binaria: seleccionan una página representativa de un clúster de contenido similar e ignoran en gran parte las demás. Este proceso de selección no siempre es predecible ni se basa en la versión que preferirías posicionar. El algoritmo considera factores como novedad, calidad del contenido, señales técnicas y autoridad de dominio, pero la ponderación de estos factores sigue siendo opaca. Lo que hace esto especialmente problemático es que los sistemas de IA pueden seleccionar una versión desactualizada si las diferencias entre las páginas son lo suficientemente mínimas como para que el algoritmo de agrupamiento no detecte variaciones significativas.
Republicar sin las salvaguardas adecuadas introduce tres riesgos interconectados que afectan directamente la visibilidad en IA:
Dilución de señales de intención: Cuando el mismo contenido aparece en varias URLs, el sistema de IA recibe señales contradictorias sobre qué versión responde mejor a la consulta del usuario. En vez de concentrar la autoridad en una sola URL, tus señales se dispersan a través del clúster. Esta dilución reduce la puntuación de confianza que los sistemas de IA asignan a tu contenido al decidir incluirlo en las respuestas. Un contenido que podría haber sido fuente primaria se vuelve una consideración secundaria porque el sistema no puede determinar con confianza cuál versión es autoritativa.
Riesgo de representación: La selección que hace el sistema de IA sobre qué página representa tu clúster de contenido puede no alinearse con tus objetivos de negocio. Puedes republicar una entrada de blog en una red de sindicación esperando que esa versión genere tráfico, solo para que el sistema de IA seleccione la versión de tu dominio original—o peor, seleccione la versión sindicada que no enlaza de regreso a tu sitio. Esta desalineación significa que tu estrategia de republicación trabaja activamente en contra de tus metas de visibilidad en lugar de amplificarlas.
Latencia en actualizaciones y obsolescencia: Cuando actualizas tu contenido original pero las versiones republicadas permanecen sin cambios, los sistemas de IA pueden seleccionar una versión desactualizada como la página representativa. El algoritmo de agrupamiento no siempre reconoce que una versión es más nueva o precisa que otras, especialmente si los cambios son incrementales en vez de estructurales. Esto crea un escenario en el que tu contenido más actual y preciso es invisible mientras una versión antigua representa tu experiencia ante los sistemas de IA.
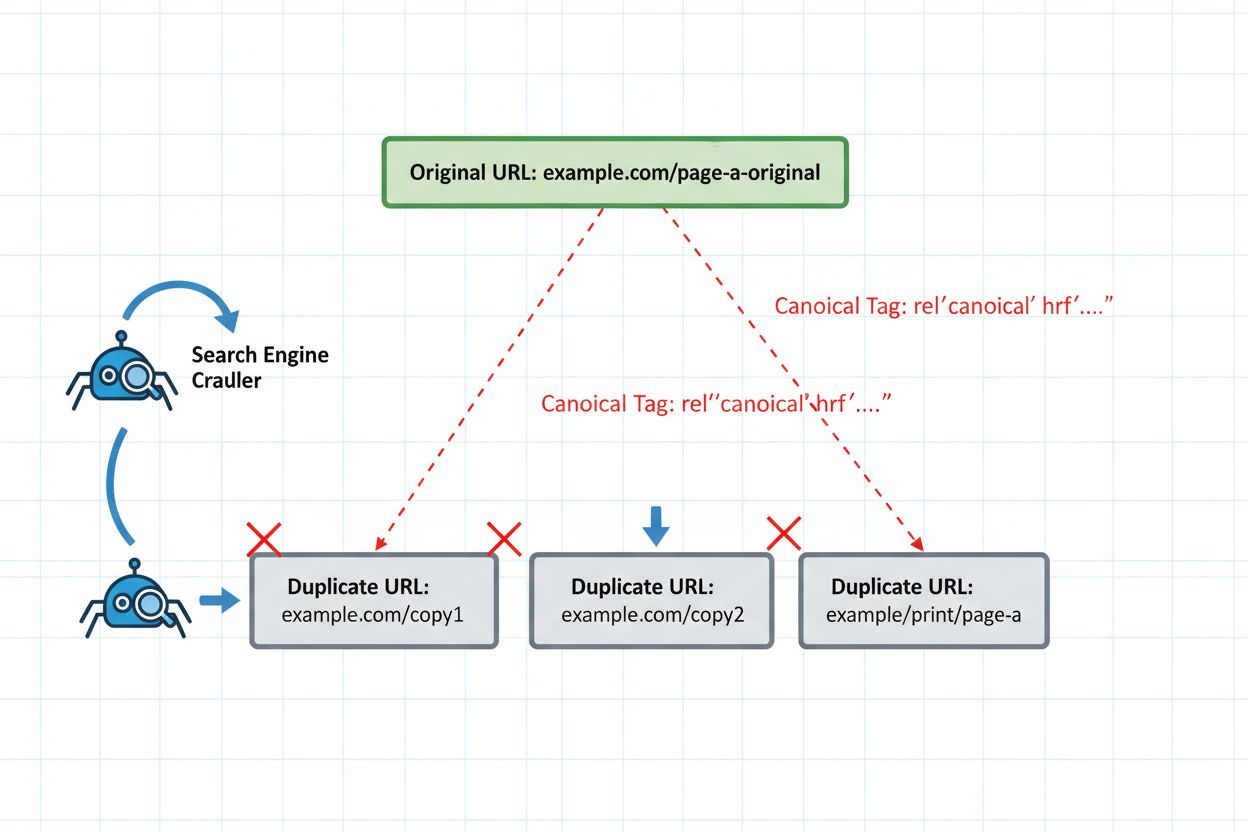
Sindicación sin etiquetas canónicas
El error más común al republicar se da cuando el contenido se sindica a plataformas de terceros sin implementar etiquetas canónicas. Considera el caso típico: una empresa de software B2B publica una guía completa en su blog, luego la sindica a publicaciones del sector como Medium, LinkedIn y agregadores de noticias especializados. Cada plataforma aloja el contenido idéntico bajo diferentes URLs. Sin etiquetas canónicas apuntando al original, el algoritmo de agrupamiento del sistema de IA trata todas las versiones como igual de autoritativas. La plataforma de sindicación podría tener mayor autoridad de dominio, haciendo que el sistema de IA seleccione esa versión como la página representativa. Ahora tu contenido original—la versión que optimizaste, actualizaste y a la que generaste backlinks—se vuelve invisible en los resultados de búsqueda de IA. El tráfico y la autoridad fluyen hacia la plataforma de sindicación en vez de a tu propiedad. Este escenario se repite miles de veces al día en la industria editorial, con editores saboteando inadvertidamente su propia visibilidad por no implementar una simple etiqueta HTML.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Páginas de campaña y variaciones en república
El contenido específico de campañas crea un problema particularmente insidioso de contenido duplicado al republicarse en varios canales. Un equipo de marketing lanza una página de destino optimizada para una promoción específica, luego republica variaciones de ese contenido en boletines por correo, redes sociales, anuncios pagados y sitios de socios. Cada versión contiene ligeras diferencias en el texto, llamados a la acción o formato, pero el contenido y la intención principales permanecen idénticos. Los sistemas de IA detectan estos como casi duplicados y los agrupan juntos. El problema se intensifica cuando las páginas de campaña se republican sin una implementación canónica adecuada. El sistema de IA podría seleccionar la versión del boletín (que no tiene seguimiento de conversiones) como la página representativa, o la versión del sitio socio que no beneficia tus métricas. Además, cuando las campañas finalizan y las páginas se archivan o eliminan, el sistema de IA puede haber seleccionado una versión ya inactiva como representativa, creando una situación en la que tu contenido se vuelve invisible o dirige a los usuarios a experiencias rotas.
Localización y republicación regional
La republicación regional introduce complejidad porque la detección de contenido duplicado debe tener en cuenta necesidades legítimas de localización. Una empresa con operaciones en varios países podría publicar el mismo contenido principal en diferentes idiomas o con variaciones específicas de la región. Sin la implementación adecuada, estas versiones regionales compiten entre sí en la agrupación de IA. Considera una empresa SaaS que publica una guía de funciones en inglés en su dominio de EE.UU., luego la republica en su dominio del Reino Unido con ortografía británica y precios regionales. El sistema de IA agrupa estos como duplicados, posiblemente seleccionando la versión de EE.UU. incluso para usuarios del Reino Unido. La solución requiere implementar etiquetas hreflang que indiquen relaciones regionales a los sistemas de IA, aunque la efectividad de hreflang en la búsqueda por IA sigue siendo menos establecida que en la búsqueda tradicional.
<!-- En la versión de EE.UU. (example.com/feature-guide) --><linkrel="alternate"hreflang="en-US"href="https://example.com/feature-guide" />
<linkrel="alternate"hreflang="en-GB"href="https://example.co.uk/feature-guide" />
<linkrel="alternate"hreflang="x-default"href="https://example.com/feature-guide" />
<!-- En la versión del Reino Unido (example.co.uk/feature-guide) --><linkrel="alternate"hreflang="en-GB"href="https://example.co.uk/feature-guide" />
<linkrel="alternate"hreflang="en-US"href="https://example.com/feature-guide" />
<linkrel="alternate"hreflang="x-default"href="https://example.com/feature-guide" />
Salvaguardas técnicas para contenido republicado
Implementar las salvaguardas técnicas adecuadas es innegociable para una republicación segura. La etiqueta canónica sigue siendo tu defensa principal, indicando explícitamente a los sistemas de IA qué versión debe representar tu clúster de contenido. Coloca la etiqueta canónica en la sección <head> de cada versión republicada, apuntando a tu versión autorizada preferida. Para contenido sindicado, esto normalmente significa apuntar al dominio original.
<!-- En la versión sindicada (medium.com/your-publication/article) --><linkrel="canonical"href="https://yoursite.com/blog/article" />
Para contenido que nunca debe competir con otras versiones, implementa noindex en las versiones secundarias. Esto las elimina completamente del índice de IA, asegurando que no puedan ser seleccionadas como páginas representativas. Usa este enfoque para páginas duplicadas internas, versiones de prueba o contenido sindicado donde no quieras visibilidad en búsquedas de IA.
<!-- En la versión secundaria que no debe indexarse --><metaname="robots"content="noindex, follow" />
Las redirecciones 301 proporcionan la señal más fuerte para consolidar autoridad, pero úsalas solo cuando la versión secundaria nunca se actualizará de forma independiente. Las redirecciones indican a los sistemas de IA que la URL antigua se ha movido permanentemente, consolidando todas las señales en la nueva ubicación. Sin embargo, si necesitas que ambas versiones permanezcan activas (como en la sindicación), las redirecciones generan problemas porque rompen la estructura de URL de la plataforma de sindicación.
# En .htaccess o configuración de servidor
Redirect 301 /old-article https://yoursite.com/new-article
Para sistemas de gestión de contenido, implementa rel=“canonical” de forma dinámica para gestionar paginación, variaciones de parámetros y URLs basadas en sesión que generan duplicados no intencionados. Muchas plataformas CMS generan múltiples URLs para el mismo contenido a través de diferentes rutas de navegación—las etiquetas canónicas las consolidan automáticamente.
IndexNow para limpieza de republicación
IndexNow acelera el descubrimiento de señales canónicas y la consolidación de duplicados, reduciendo lo que tradicionalmente tomaría semanas a solo días. Cuando implementas etiquetas canónicas en contenido republicado, IndexNow notifica inmediatamente a los sistemas de búsqueda que estas URLs deben agruparse. En vez de esperar a que los rastreadores descubran la relación canónica mediante patrones de rastreo normales, IndexNow envía esta información directamente al índice de Microsoft y otros sistemas de búsqueda participantes. Esto es especialmente útil al corregir errores de republicación de manera retroactiva: puedes implementar etiquetas canónicas y usar IndexNow para señalar el cambio de inmediato, en vez de esperar a que los rastreadores visiten las páginas nuevamente. Para editores que gestionan contenido en múltiples plataformas, IndexNow se convierte en una herramienta crítica para mantener el control sobre qué versión representa tu clúster de contenido. La integración con la API te permite enviar URLs en lote, haciendo práctico gestionar cientos o miles de páginas republicadas.
Monitoreo del rendimiento del contenido republicado
Rastrear qué versión de tu contenido republicado es seleccionada por los sistemas de IA requiere un monitoreo más allá de la analítica tradicional. Configura seguimiento para identificar cuándo los sistemas de IA citan o referencian tu contenido, observando qué URL aparece en los resultados de búsqueda por IA. Herramientas como Semrush, Ahrefs y Moz comienzan a añadir métricas de visibilidad en IA, aunque siguen siendo menos maduras que el seguimiento tradicional. Implementa parámetros UTM en versiones sindicadas para rastrear la atribución de tráfico, pero reconoce que los sistemas de IA pueden no transmitir estos parámetros, dificultando la atribución directa. Monitorea tu Search Console (o herramientas equivalentes para otros sistemas de búsqueda) para ver patrones de rastreo: si las versiones secundarias se rastrean más que tu versión canónica, indica que el sistema de IA podría haber seleccionado la página representativa equivocada. Configura alertas para menciones de tu contenido en plataformas de sindicación y cruza esta información con tu visibilidad en IA para detectar desalineaciones entre dónde aparece tu contenido y de dónde lo seleccionan los sistemas de IA.
Mejores prácticas para una republicación segura
Implementa esta lista de verificación antes de republicar cualquier contenido para asegurar que mantienes el control sobre la visibilidad en IA:
Antes de republicar, identifica tu versión canónica—la URL que deseas que represente ese contenido en los resultados de búsqueda por IA. Usualmente debe ser tu dominio propio, no una plataforma de sindicación. Implementa etiquetas canónicas en cada versión republicada apuntando a tu URL canónica, incluso si republicas en tus propias propiedades (diferentes dominios, subdominios o variaciones de parámetros). Usa IndexNow para notificar de inmediato a los sistemas de búsqueda sobre la relación canónica, en vez de esperar al rastreo. Evita republicar en plataformas de alta autoridad sin soporte canónico—algunas eliminan las etiquetas canónicas o no las permiten, haciéndolas inadecuadas para republicar sin aceptar pérdida de visibilidad. Monitorea las primeras 48 horas tras la republicación para verificar que los sistemas de IA seleccionen tu versión canónica, no una alternativa. Actualiza todas las versiones simultáneamente cuando hagas cambios de contenido—si solo actualizas la versión canónica, el algoritmo de agrupamiento puede no reconocer la actualización en todas las versiones, causando que el sistema de IA seleccione una versión obsoleta. Establece un calendario de republicación que evite que el contenido quede obsoleto en plataformas secundarias; el contenido sindicado desactualizado eleva el riesgo de que los sistemas de IA lo seleccionen como versión representativa si tu versión canónica no se ha actualizado recientemente.
Preguntas frecuentes
¿El uso de etiquetas canónicas al republicar contenido previene penalizaciones por contenido duplicado?
Las etiquetas canónicas no previenen penalizaciones porque el contenido duplicado no genera penalizaciones en primer lugar. Sin embargo, las etiquetas canónicas son críticas para la búsqueda en IA porque indican a los sistemas de IA qué versión debe representar tu clúster de contenido. Sin etiquetas canónicas, los sistemas de IA pueden seleccionar una versión no deseada como fuente autorizada, reduciendo tu visibilidad.
¿Cómo sé si mi contenido republicado está siendo seleccionado por los sistemas de IA?
Monitorea qué URLs aparecen en los resultados de búsqueda de IA y en las citas de tu contenido. Herramientas como Semrush y Ahrefs están incorporando métricas de visibilidad en búsquedas de IA. Consulta tu Search Console para ver los patrones de rastreo: si las versiones secundarias se rastrean con más frecuencia que tu versión canónica, el sistema de IA puede haber seleccionado la página equivocada.
¿Puedo republicar el mismo contenido en varios dominios sin etiquetas canónicas?
Técnicamente sí, pero no es recomendable. Sin etiquetas canónicas, los sistemas de IA agruparán tu contenido y seleccionarán una versión como representativa, pero no controlarás cuál. La plataforma de sindicación podría tener mayor autoridad, haciendo que la IA seleccione esa versión en lugar de tu dominio original.
¿Cuál es la diferencia entre republicación y sindicación de contenido?
Republicación generalmente se refiere a distribuir tu contenido en múltiples canales que controlas o con los que tienes alianzas. La sindicación de contenido es una forma específica de republicación donde plataformas de terceros republican tu contenido con tu permiso. Ambas crean problemas de contenido duplicado si no se gestionan adecuadamente con etiquetas canónicas.
¿Cuánto tiempo tarda en hacer efecto una etiqueta canónica en la búsqueda por IA?
Las etiquetas canónicas suelen ser reconocidas en 24-48 horas si usas IndexNow para notificar a los sistemas de búsqueda de inmediato. Sin IndexNow, puede tomar semanas para que los rastreadores descubran la relación canónica. Por esto, IndexNow es fundamental para gestionar contenido republicado: acelera significativamente el proceso.
¿Debo usar redirecciones 301 o etiquetas canónicas para contenido republicado?
Utiliza redirecciones 301 solo cuando desees consolidar URLs permanentemente y la versión secundaria nunca se actualizará de forma independiente. Usa etiquetas canónicas cuando ambas versiones deban permanecer activas (como en la sindicación). Las redirecciones son señales más fuertes, pero rompen la funcionalidad de la URL secundaria.
¿La republicación de contenido perjudica la visibilidad de mi dominio original en IA?
Sí, si no se gestiona correctamente. Republicar sin etiquetas canónicas diluye tus señales de autoridad en varias URLs. Los sistemas de IA pueden seleccionar la versión sindicada en vez de la original, reduciendo la visibilidad en tu propio dominio. Una implementación canónica adecuada lo previene.
¿Cuál es la mejor manera de republicar contenido para lograr el mayor alcance sin problemas de duplicidad?
Implementa etiquetas canónicas en cada versión republicada apuntando a tu dominio original. Usa IndexNow para notificar a los sistemas de búsqueda sobre la relación canónica de inmediato. Evita republicar en plataformas que no soportan etiquetas canónicas. Monitorea qué versión selecciona la IA en las primeras 48 horas y ajusta si es necesario.
Monitorea la visibilidad de tu contenido en IA
Rastrea cómo los sistemas de IA citan y referencian tu contenido republicado en todas las plataformas. Obtén información en tiempo real sobre qué versión selecciona la IA como tu fuente autorizada.
URLs canónicos y la IA: Previniendo problemas de contenido duplicado
Aprende cómo los URLs canónicos previenen problemas de contenido duplicado en sistemas de búsqueda con IA. Descubre las mejores prácticas para implementar canón...
¿Cómo manejan los motores de búsqueda de IA el contenido duplicado? ¿Es diferente de Google?
Discusión comunitaria sobre cómo los sistemas de IA manejan el contenido duplicado de manera diferente a los motores de búsqueda tradicionales. Profesionales SE...
Cómo Manejar el Contenido Duplicado para Motores de Búsqueda de IA
Aprende a gestionar y prevenir el contenido duplicado al usar herramientas de IA. Descubre etiquetas canónicas, redirecciones, herramientas de detección y mejor...
14 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.