
Gestión de rastreadores de IA
Aprende cómo gestionar el acceso de rastreadores de IA al contenido de tu sitio web. Comprende la diferencia entre rastreadores de entrenamiento y de búsqueda, ...
8 min de lectura
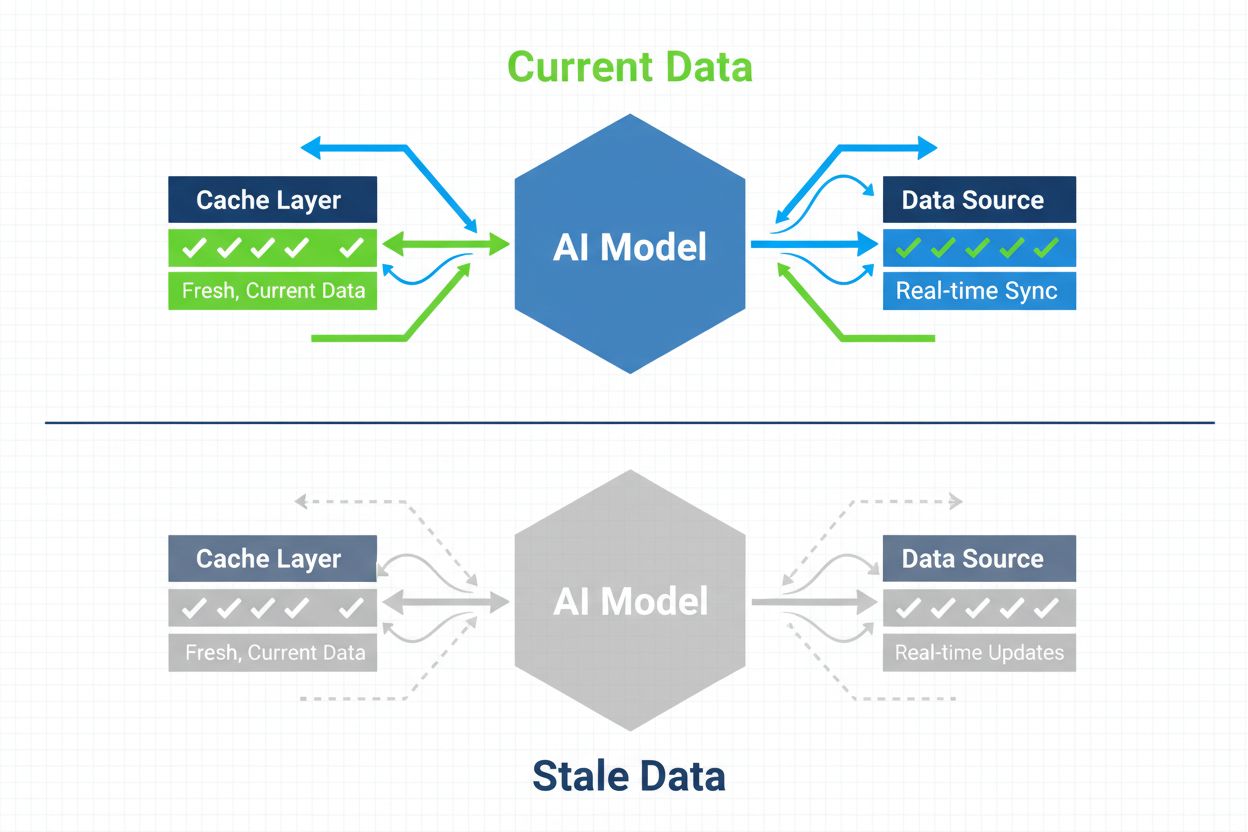
Estrategias para garantizar que los sistemas de IA tengan acceso a contenido actualizado en lugar de versiones obsoletas almacenadas en caché. La gestión de caché equilibra los beneficios de rendimiento del almacenamiento en caché frente al riesgo de servir información desactualizada, utilizando estrategias de invalidación y monitoreo para mantener la frescura de los datos mientras se reducen la latencia y los costos.
Estrategias para garantizar que los sistemas de IA tengan acceso a contenido actualizado en lugar de versiones obsoletas almacenadas en caché. La gestión de caché equilibra los beneficios de rendimiento del almacenamiento en caché frente al riesgo de servir información desactualizada, utilizando estrategias de invalidación y monitoreo para mantener la frescura de los datos mientras se reducen la latencia y los costos.
La gestión de caché en IA se refiere al enfoque sistemático de almacenar y recuperar resultados previamente calculados, salidas de modelos o respuestas de API para evitar reprocesamiento redundante y reducir la latencia en sistemas de inteligencia artificial. El principal desafío radica en equilibrar los beneficios de rendimiento de los datos en caché frente al riesgo de servir información obsoleta o desactualizada que ya no refleja el estado actual del sistema ni los requerimientos del usuario. Esto se vuelve especialmente crítico en grandes modelos de lenguaje (LLMs) y aplicaciones de IA donde los costos de inferencia son elevados y el tiempo de respuesta impacta directamente en la experiencia del usuario. Los sistemas de gestión de caché deben determinar de manera inteligente cuándo los resultados almacenados siguen siendo válidos y cuándo es necesario un nuevo cálculo, convirtiéndose en una consideración arquitectónica fundamental para implementaciones de IA en producción.
El impacto de una gestión de caché efectiva en el rendimiento de los sistemas de IA es sustancial y medible en múltiples dimensiones. Implementar estrategias de almacenamiento en caché puede reducir la latencia de respuesta entre un 80% y un 90% para consultas repetidas, al tiempo que reduce los costos de API entre un 50% y un 90%, dependiendo de las tasas de aciertos de la caché y de la arquitectura del sistema. Más allá de los indicadores de rendimiento, la gestión de caché influye directamente en la consistencia de la precisión y la fiabilidad del sistema, ya que las invalidaciones adecuadas aseguran que los usuarios reciban información actualizada mientras que una mala gestión puede introducir problemas de obsolescencia de datos. Estas mejoras se vuelven cada vez más importantes a medida que los sistemas de IA escalan para manejar millones de solicitudes, donde el efecto acumulativo de la eficiencia de la caché determina directamente los costos de infraestructura y la satisfacción de los usuarios.
| Aspecto | Sistemas con caché | Sistemas sin caché |
|---|---|---|
| Tiempo de respuesta | 80-90% más rápido | Línea base |
| Costos de API | Reducción del 50-90% | Costo total |
| Precisión | Consistente | Variable |
| Escalabilidad | Alta | Limitada |
Las estrategias de invalidación de caché determinan cómo y cuándo los datos almacenados se actualizan o eliminan del almacenamiento, representando una de las decisiones más críticas en el diseño de la arquitectura de caché. Los distintos enfoques de invalidación ofrecen diferentes compensaciones entre la frescura de los datos y el rendimiento del sistema:
La selección de la estrategia de invalidación depende fundamentalmente de los requisitos de la aplicación: sistemas que priorizan la precisión de los datos pueden aceptar mayores costos de latencia mediante invalidaciones agresivas, mientras que aplicaciones críticas para el rendimiento pueden tolerar datos ligeramente obsoletos para mantener tiempos de respuesta por debajo del milisegundo.
El almacenamiento en caché de prompts en grandes modelos de lenguaje representa una aplicación especializada de la gestión de caché que almacena estados intermedios del modelo y secuencias de tokens para evitar el reprocesamiento de entradas idénticas o similares. Los LLMs soportan dos enfoques principales: la caché exacta coincide con prompts idénticos carácter por carácter, mientras que la caché semántica identifica prompts funcionalmente equivalentes a pesar de una redacción diferente. OpenAI implementa el almacenamiento en caché de prompts de forma automática con una reducción del 50% en el costo de los tokens almacenados, requiriendo segmentos mínimos de prompts de 1024 tokens para activar los beneficios de caché. Anthropic ofrece un almacenamiento en caché de prompts manual con reducciones de costos más agresivas de hasta el 90%, pero requiere que los desarrolladores gestionen explícitamente las claves y duraciones de la caché, con requisitos mínimos de caché de 1024 a 2048 tokens según la configuración del modelo. La duración de la caché en sistemas LLM suele variar de minutos a horas, equilibrando el ahorro computacional de reutilizar estados almacenados frente al riesgo de servir salidas de modelo desactualizadas en aplicaciones sensibles al tiempo.
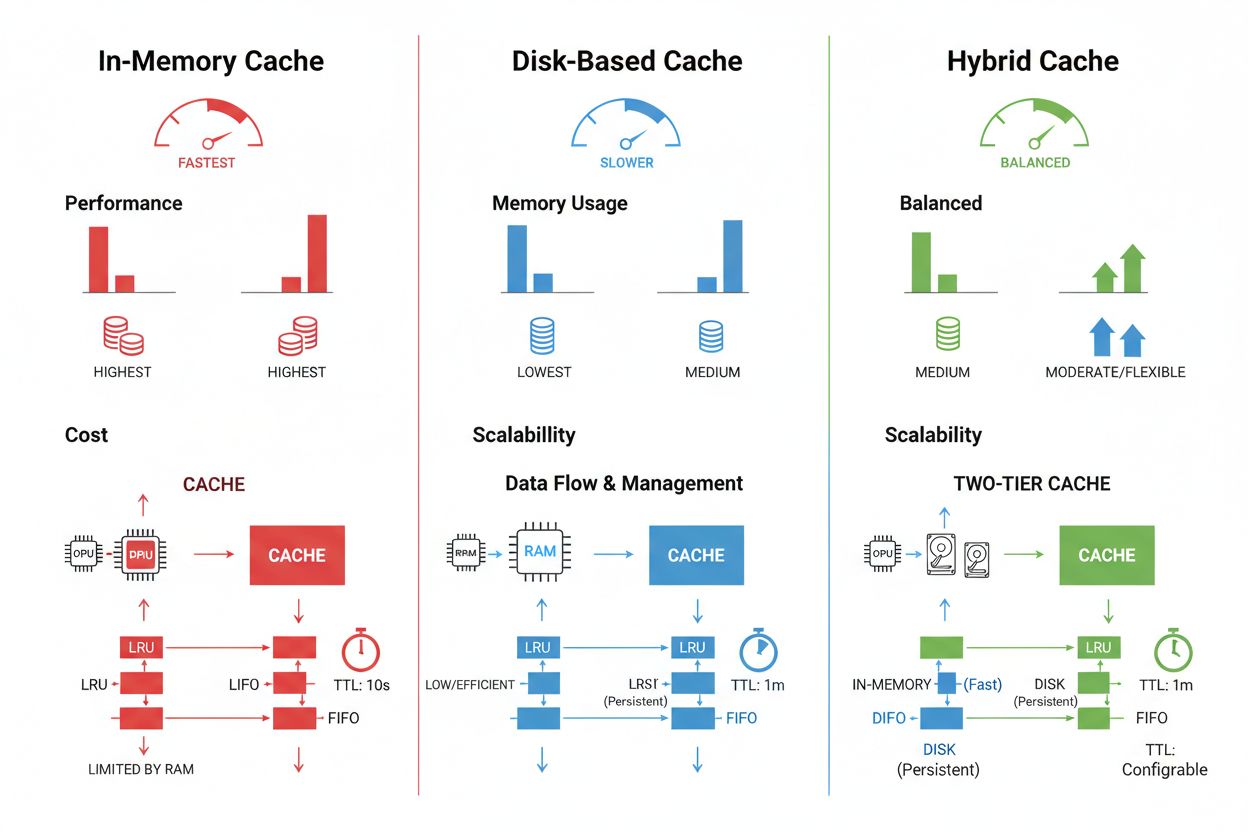
Las técnicas de almacenamiento y gestión de caché varían significativamente según los requisitos de rendimiento, el volumen de datos y las restricciones de infraestructura, ofreciendo cada enfoque ventajas y limitaciones distintas. Las soluciones de almacenamiento en memoria como Redis proporcionan velocidades de acceso a nivel de microsegundos ideales para consultas de alta frecuencia, pero consumen una cantidad significativa de RAM y requieren una gestión cuidadosa de la memoria. El almacenamiento en caché basado en disco permite manejar conjuntos de datos más grandes y persiste entre reinicios del sistema, pero introduce una latencia medida en milisegundos en comparación con las alternativas en memoria. Los enfoques híbridos combinan ambos tipos de almacenamiento, enviando los datos más accedidos a la memoria mientras mantienen conjuntos de datos grandes en disco:
| Tipo de almacenamiento | Mejor para | Rendimiento | Uso de memoria |
|---|---|---|---|
| En memoria (Redis) | Consultas frecuentes | Más rápido | Mayor |
| En disco | Grandes conjuntos de datos | Moderado | Menor |
| Híbrido | Cargas mixtas | Equilibrado | Equilibrado |
Una gestión de caché efectiva requiere configurar valores TTL apropiados que reflejen la volatilidad de los datos—TTLs cortos (minutos) para datos que cambian rápidamente frente a TTLs largos (horas/días) para contenido estable—combinado con un monitoreo continuo de las tasas de aciertos, patrones de expulsión y utilización de memoria para identificar oportunidades de optimización.
Las aplicaciones reales de IA demuestran tanto el potencial transformador como la complejidad operativa de la gestión de caché en diversos casos de uso. Los chatbots de atención al cliente aprovechan la caché para ofrecer respuestas consistentes a preguntas frecuentes mientras reducen los costos de inferencia entre un 60% y un 70%, permitiendo escalar de manera rentable a miles de usuarios concurrentes. Los asistentes de codificación almacenan en caché patrones de código comunes y fragmentos de documentación, permitiendo a los desarrolladores recibir sugerencias de autocompletado con latencias inferiores a 100 ms incluso en periodos de máxima demanda. Los sistemas de procesamiento de documentos almacenan en caché embeddings y representaciones semánticas de documentos frecuentemente analizados, acelerando drásticamente búsquedas de similitud y tareas de clasificación. Sin embargo, la gestión de caché en producción introduce desafíos significativos: la complejidad de invalidación aumenta exponencialmente en sistemas distribuidos donde la consistencia debe mantenerse entre múltiples servidores, las limitaciones de recursos obligan a tomar decisiones difíciles entre el tamaño y la cobertura de la caché, surgen riesgos de seguridad cuando los datos almacenados incluyen información sensible que requiere cifrado y controles de acceso, y la coordinación de actualizaciones de caché entre microservicios introduce posibles condiciones de carrera e inconsistencias de datos. Las soluciones de monitoreo integral que rastrean la frescura de la caché, tasas de aciertos y eventos de invalidación se vuelven esenciales para mantener la fiabilidad del sistema e identificar cuándo es necesario ajustar las estrategias de caché según los patrones de datos y comportamiento de los usuarios.
La invalidación de caché elimina o actualiza datos obsoletos cuando ocurren cambios, proporcionando frescura inmediata pero requiriendo disparadores basados en eventos. La expiración de caché establece un límite de tiempo (TTL) para cuánto tiempo permanece la información en caché, ofreciendo una implementación más simple pero pudiendo servir datos obsoletos si el TTL es demasiado largo. Muchos sistemas combinan ambos enfoques para un rendimiento óptimo.
Una gestión de caché efectiva puede reducir los costos de API entre un 50% y un 90% dependiendo de las tasas de aciertos de caché y la arquitectura del sistema. El almacenamiento en caché de prompts de OpenAI ofrece una reducción del 50% en el costo de los tokens almacenados, mientras que Anthropic proporciona hasta un 90% de reducción. El ahorro real depende de los patrones de consulta y de cuánto dato pueda almacenarse eficazmente en caché.
El almacenamiento en caché de prompts guarda estados intermedios del modelo y secuencias de tokens para evitar reprocesar entradas idénticas o similares en modelos de lenguaje grande. Soporta caché exacta (coincidencias carácter por carácter) y caché semántica (prompts funcionalmente equivalentes con distinta redacción). Esto reduce la latencia en un 80% y los costos entre un 50% y un 90% para consultas repetidas.
Las estrategias principales son: Expiración basada en tiempo (TTL) para eliminación automática tras un periodo determinado, Invalidación basada en eventos para actualizaciones inmediatas cuando los datos cambian, Invalidación semántica para consultas similares basadas en significado, y Enfoques híbridos que combinan varias estrategias. La elección depende de la volatilidad de los datos y los requisitos de frescura.
El almacenamiento en caché en memoria (como Redis) ofrece velocidades de acceso a nivel de microsegundos, ideal para consultas frecuentes pero consume una cantidad significativa de RAM. El almacenamiento en caché en disco permite manejar conjuntos de datos más grandes y persiste entre reinicios, pero introduce una latencia a nivel de milisegundos. Los enfoques híbridos combinan ambos, enviando los datos más accedidos a la memoria mientras mantienen conjuntos de datos grandes en disco.
TTL es un temporizador regresivo que determina cuánto tiempo permanecen válidos los datos en caché antes de expirar. TTLs cortos (minutos) son apropiados para datos que cambian rápidamente, mientras que TTLs largos (horas/días) funcionan para contenido estable. Una configuración adecuada de TTL equilibra la frescura de los datos con la sobrecarga innecesaria de actualizaciones de caché y la carga del servidor.
Una gestión de caché efectiva permite que los sistemas de IA manejen muchas más solicitudes sin una expansión proporcional de la infraestructura. Al reducir la carga computacional por solicitud mediante el almacenamiento en caché, los sistemas pueden servir a millones de usuarios con mayor eficiencia de costos. Las tasas de aciertos de caché determinan directamente los costos de infraestructura y la satisfacción del usuario en entornos productivos.
Almacenar datos sensibles en caché introduce vulnerabilidades si no se encriptan y controlan los accesos adecuadamente. Los riesgos incluyen acceso no autorizado a la información en caché, exposición de datos durante la invalidación y almacenamiento involuntario de contenido confidencial. La encriptación integral, los controles de acceso y el monitoreo son esenciales para proteger los datos sensibles almacenados en caché.
AmICited rastrea cómo los sistemas de IA referencian tu marca y asegura que tu contenido se mantenga actualizado en las cachés de IA. Obtén visibilidad sobre la gestión de caché de IA y la frescura de tu contenido en GPTs, Perplexity y Google AI Overviews.
Aprende cómo gestionar el acceso de rastreadores de IA al contenido de tu sitio web. Comprende la diferencia entre rastreadores de entrenamiento y de búsqueda, ...

Descubre qué significa la gestión de la reputación en búsquedas con IA, por qué es importante para tu marca y cómo monitorear tu presencia en ChatGPT, Perplexit...
Aprende a automatizar la monitorización de las menciones de tu marca y las citas de tu sitio web en ChatGPT, Perplexity, Google AI Overviews y otros motores de ...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.