
KI-Crawler-Management
Erfahren Sie, wie Sie den Zugriff von KI-Crawlern auf die Inhalte Ihrer Website steuern. Verstehen Sie den Unterschied zwischen Trainings- und Suchcrawlern, imp...
6 Min. Lesezeit
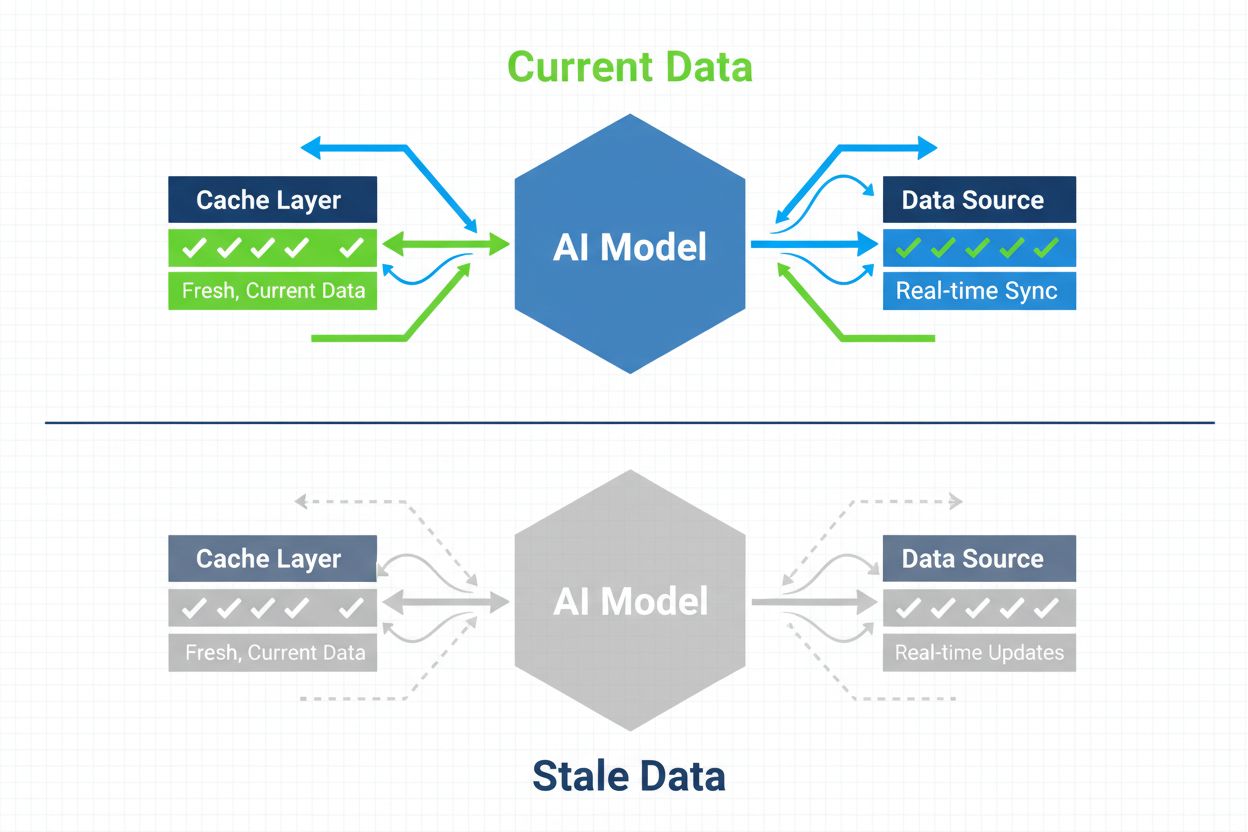
Strategien, um sicherzustellen, dass KI-Systeme auf aktuelle Inhalte statt auf veraltete, zwischengespeicherte Versionen zugreifen. Cache-Management balanciert die Leistungsvorteile des Cachings mit dem Risiko, veraltete Informationen bereitzustellen, und nutzt Invalidierungsstrategien sowie Überwachung, um die Datenaktualität zu gewährleisten und gleichzeitig Latenz und Kosten zu senken.
Strategien, um sicherzustellen, dass KI-Systeme auf aktuelle Inhalte statt auf veraltete, zwischengespeicherte Versionen zugreifen. Cache-Management balanciert die Leistungsvorteile des Cachings mit dem Risiko, veraltete Informationen bereitzustellen, und nutzt Invalidierungsstrategien sowie Überwachung, um die Datenaktualität zu gewährleisten und gleichzeitig Latenz und Kosten zu senken.
KI-Cache-Management bezeichnet den systematischen Ansatz zum Speichern und Abrufen zuvor berechneter Ergebnisse, Modellausgaben oder API-Antworten, um redundante Verarbeitung zu vermeiden und die Latenz in Systemen der künstlichen Intelligenz zu reduzieren. Die zentrale Herausforderung besteht darin, die Leistungsvorteile zwischengespeicherter Daten gegen das Risiko abzuwägen, veraltete oder nicht mehr aktuelle Informationen bereitzustellen, die den aktuellen Systemzustand oder Benutzeranforderungen nicht mehr widerspiegeln. Dies wird besonders kritisch bei großen Sprachmodellen (LLMs) und KI-Anwendungen, bei denen die Inferenzkosten erheblich sind und die Antwortzeit die Nutzererfahrung direkt beeinflusst. Cache-Management-Systeme müssen intelligent bestimmen, wann zwischengespeicherte Ergebnisse weiterhin gültig sind und wann eine Neuberechnung erforderlich ist, was das Cache-Management zu einem grundlegenden architektonischen Aspekt für produktive KI-Einsätze macht.
Die Auswirkungen eines effektiven Cache-Managements auf die Leistung von KI-Systemen sind erheblich und in mehreren Dimensionen messbar. Die Implementierung von Caching-Strategien kann die Antwortlatenz bei wiederholten Anfragen um 80-90 % senken und gleichzeitig die API-Kosten je nach Cache-Trefferquote und Systemarchitektur um 50-90 % reduzieren. Über Leistungskennzahlen hinaus beeinflusst das Cache-Management direkt die Genauigkeitskonsistenz und Systemzuverlässigkeit, da korrekt invalidierte Caches sicherstellen, dass Nutzer aktuelle Informationen erhalten, während schlecht verwaltete Caches zu Problemen mit Datenveraltung führen. Diese Verbesserungen gewinnen an Bedeutung, wenn KI-Systeme auf Millionen von Anfragen skalieren, da die kumulative Wirkung der Cache-Effizienz die Infrastrukturkosten und die Nutzerzufriedenheit direkt bestimmt.
| Aspekt | Gecachte Systeme | Nicht gecachte Systeme |
|---|---|---|
| Antwortzeit | 80-90 % schneller | Basiswert |
| API-Kosten | 50-90 % Reduktion | Volle Kosten |
| Genauigkeit | Konsistent | Variabel |
| Skalierbarkeit | Hoch | Eingeschränkt |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Cache-Invalidierungsstrategien bestimmen, wie und wann zwischengespeicherte Daten aktualisiert oder aus dem Speicher entfernt werden und stellen eine der wichtigsten Entscheidungen beim Entwurf der Cache-Architektur dar. Verschiedene Invalidierungsansätze bieten unterschiedliche Kompromisse zwischen Datenaktualität und Systemleistung:
Die Auswahl der Invalidierungsstrategie hängt grundlegend von den Anforderungen der Anwendung ab: Systeme, die Datengenauigkeit priorisieren, akzeptieren möglicherweise höhere Latenzkosten durch aggressive Invalidierung, während leistungskritische Anwendungen leicht veraltete Daten in Kauf nehmen, um Antwortzeiten im Sub-Millisekundenbereich zu erreichen.
Prompt-Caching in großen Sprachmodellen ist eine spezialisierte Form des Cache-Managements, bei der Zwischenzustände des Modells und Token-Sequenzen gespeichert werden, um die erneute Verarbeitung identischer oder ähnlicher Eingaben zu vermeiden. LLMs unterstützen zwei Hauptansätze für das Caching: Exaktes Caching gleicht Prompts zeichengetreu ab, während semantisches Caching funktional äquivalente Prompts trotz unterschiedlicher Formulierungen erkennt. OpenAI implementiert automatisches Prompt-Caching mit einer Kostenreduktion von 50 % bei gecachten Tokens und setzt voraus, dass mindestens 1024 Token pro Promptsegment verarbeitet werden, um Caching-Vorteile zu aktivieren. Anthropic bietet manuelles Prompt-Caching mit noch aggressiveren Kostenreduktionen von 90 %, verlangt jedoch, dass Entwickler Cache-Keys und -Dauern explizit verwalten; die Mindestanforderungen für das Caching liegen modellabhängig bei 1024-2048 Token. Die Cache-Dauer in LLM-Systemen liegt typischerweise zwischen Minuten und Stunden und balanciert die Recheneinsparungen durch die Wiederverwendung zwischengespeicherter Zustände gegen das Risiko, veraltete Modellausgaben für zeitkritische Anwendungen zu liefern.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
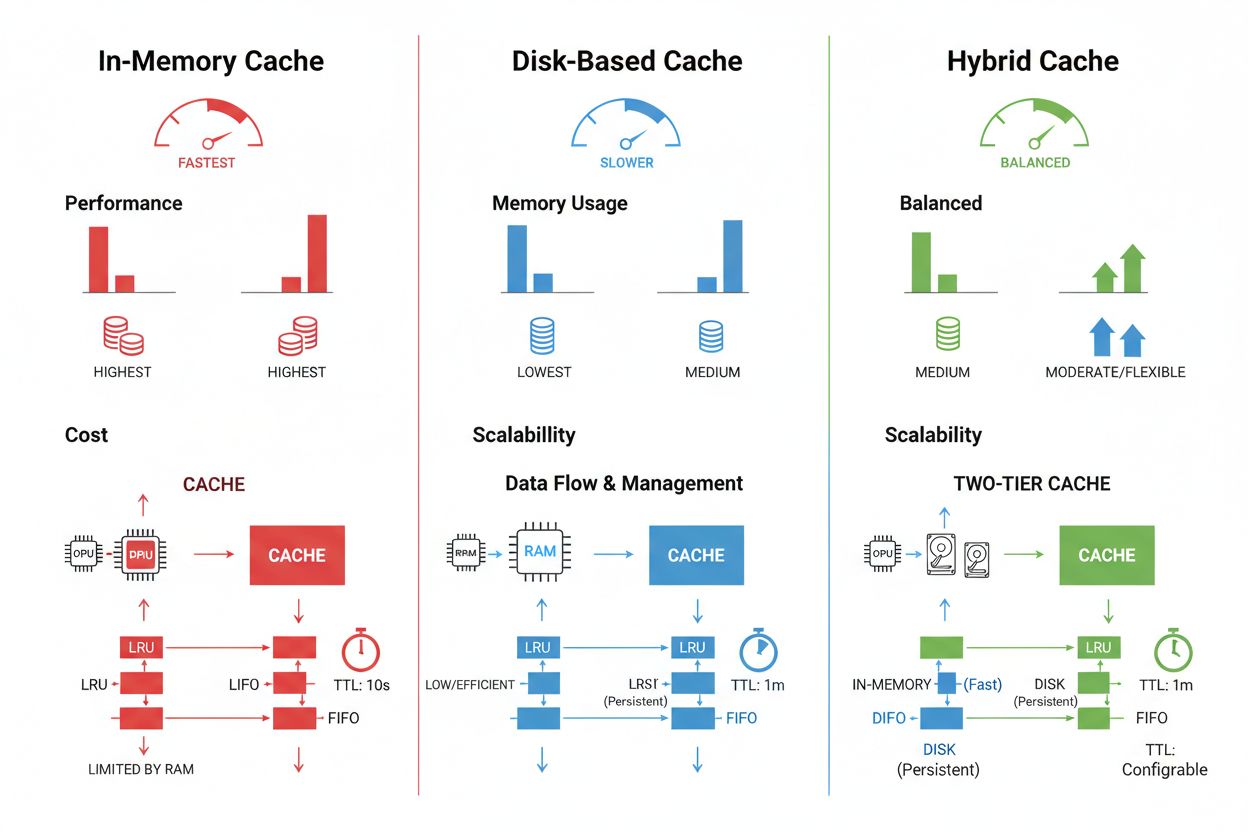
Cache-Speicher- und Management-Techniken variieren je nach Leistungsanforderungen, Datenvolumen und Infrastrukturbeschränkungen erheblich, wobei jeder Ansatz spezifische Vor- und Nachteile bietet. In-Memory-Caching-Lösungen wie Redis ermöglichen Zugriffszeiten im Mikrosekundenbereich und eignen sich ideal für hochfrequente Anfragen, verbrauchen jedoch signifikant Arbeitsspeicher und erfordern ein sorgfältiges Speichermanagement. Festplattenbasiertes Caching kann größere Datenmengen verarbeiten und bleibt über Systemneustarts hinweg erhalten, bringt jedoch gegenüber In-Memory-Alternativen Latenzen im Millisekundenbereich mit sich. Hybride Ansätze kombinieren beide Speicherarten, indem häufig genutzte Daten im Speicher gehalten und größere Datenmengen auf der Festplatte vorgehalten werden:
| Speichertyp | Am besten geeignet für | Leistung | Speicherverbrauch |
|---|---|---|---|
| In-Memory (Redis) | Häufige Anfragen | Am schnellsten | Höher |
| Festplattenbasiert | Große Datenmengen | Mittel | Geringer |
| Hybrid | Gemischte Workloads | Ausgewogen | Ausgewogen |
Effektives Cache-Management erfordert die Konfiguration geeigneter TTL-Einstellungen, die die Datenvolatilität berücksichtigen – kurze TTLs (Minuten) für sich schnell ändernde Daten versus längere TTLs (Stunden/Tage) für stabile Inhalte – in Kombination mit kontinuierlicher Überwachung der Cache-Trefferquoten, Ausmusterungsmuster und Speichernutzung, um Optimierungspotenziale zu erkennen.
Reale KI-Anwendungen zeigen sowohl das transformative Potenzial als auch die betriebliche Komplexität des Cache-Managements in verschiedensten Anwendungsfällen. Kundenservice-Chatbots nutzen Caching, um auf häufig gestellte Fragen konsistente Antworten zu liefern und die Inferenzkosten um 60-70 % zu senken, was eine kosteneffiziente Skalierung auf Tausende gleichzeitige Nutzer ermöglicht. Coding-Assistenten cachen gängige Codemuster und Dokumentationsschnipsel, sodass Entwickler selbst zu Spitzenzeiten Autovervollständigung mit Latenzen unter 100 ms erhalten. Dokumentenverarbeitungssysteme speichern Einbettungen und semantische Repräsentationen häufig analysierter Dokumente, was die Ähnlichkeitssuche und Klassifizierungsaufgaben erheblich beschleunigt. Im Produktivbetrieb bringt Cache-Management jedoch erhebliche Herausforderungen mit sich: Die Komplexität der Invalidierung steigt exponentiell in verteilten Systemen, wenn die Cache-Konsistenz über mehrere Server hinweg aufrechterhalten werden muss; Ressourcenbeschränkungen erzwingen schwierige Kompromisse zwischen Cache-Größe und -Abdeckung; Sicherheitsrisiken entstehen, wenn zwischengespeicherte Daten sensible Informationen enthalten, die verschlüsselt und zugriffsbeschränkt werden müssen; und die Koordination von Cache-Updates über Microservices hinweg führt zu möglichen Race Conditions und Dateninkonsistenzen. Umfassende Monitoring-Lösungen, die Cache-Aktualität, Trefferquoten und Invalidierungsereignisse nachverfolgen, werden unerlässlich, um die Systemzuverlässigkeit zu gewährleisten und rechtzeitig zu erkennen, wann Cache-Strategien an veränderte Datenmuster und Benutzerverhalten angepasst werden müssen.
AmICited verfolgt, wie KI-Systeme auf Ihre Marke Bezug nehmen, und sorgt dafür, dass Ihre Inhalte in KI-Caches aktuell bleiben. Erhalten Sie Einblick in das KI-Cache-Management und die Inhaltsfrische über GPTs, Perplexity und Google AI Overviews hinweg.
Erfahren Sie, wie Sie den Zugriff von KI-Crawlern auf die Inhalte Ihrer Website steuern. Verstehen Sie den Unterschied zwischen Trainings- und Suchcrawlern, imp...

Erfahren Sie, wie Sie KI-generierte Krisen erkennen, darauf reagieren und sie verhindern, die den Ruf Ihrer Marke bedrohen. Entdecken Sie Echtzeit-Monitoring-St...
Erfahren Sie, wie KI-Gedächtnis-Personalisierungssysteme detaillierte Nutzerprofile erstellen, um personalisierte Markenempfehlungen zu liefern. Verstehen Sie d...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.