
Reconocimiento de Entidades
El Reconocimiento de Entidades es una capacidad de IA y PLN que identifica y categoriza entidades nombradas en texto. Descubre cómo funciona, sus aplicaciones e...
12 min de lectura

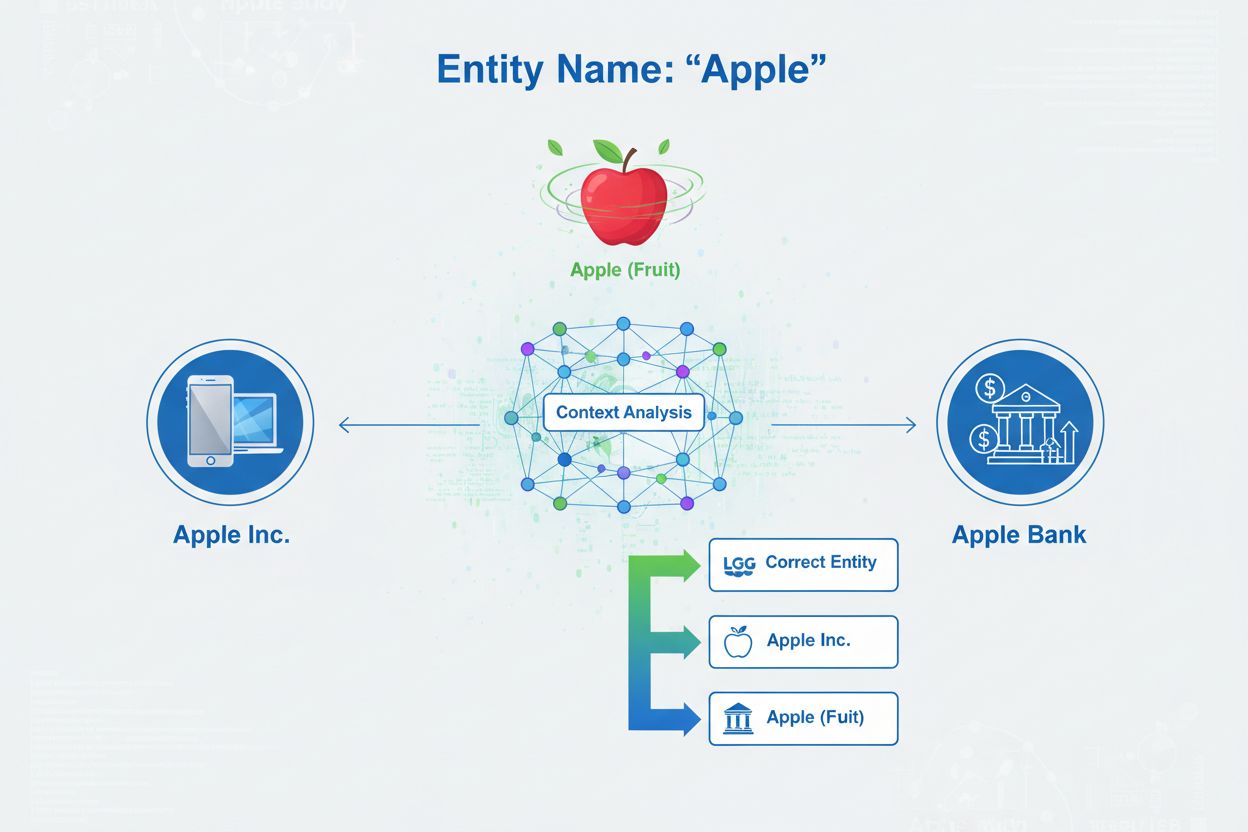
La desambiguación de entidades es el proceso de determinar a qué entidad específica se refiere una mención concreta cuando varias entidades comparten el mismo nombre. Ayuda a los sistemas de IA a comprender y citar el contenido con precisión resolviendo la ambigüedad en las referencias de entidades nombradas, garantizando que las menciones de ‘Apple’ identifiquen correctamente si la referencia es a Apple Inc., la fruta u otra entidad con el mismo nombre.
La desambiguación de entidades es el proceso de determinar a qué entidad específica se refiere una mención concreta cuando varias entidades comparten el mismo nombre. Ayuda a los sistemas de IA a comprender y citar el contenido con precisión resolviendo la ambigüedad en las referencias de entidades nombradas, garantizando que las menciones de 'Apple' identifiquen correctamente si la referencia es a Apple Inc., la fruta u otra entidad con el mismo nombre.
La desambiguación de entidades es el proceso de determinar a qué entidad específica se refiere una mención concreta cuando varias entidades comparten el mismo nombre o referencias similares. En el contexto de la inteligencia artificial y el procesamiento de lenguaje natural (PLN), la desambiguación de entidades asegura que, cuando un sistema de IA encuentra una entidad nombrada en un texto, identifique correctamente a qué objeto, persona, organización o lugar del mundo real se está haciendo referencia. Esto es fundamentalmente diferente al reconocimiento de entidades nombradas (NER), que simplemente identifica que existe una entidad y la clasifica en una categoría como “persona”, “organización” o “lugar”. Mientras que el NER responde a la pregunta “¿Hay una entidad aquí?”, la desambiguación de entidades responde “¿De qué entidad específica se trata?”. Por ejemplo, al procesar la frase “Apple fue la creación de Steve Jobs”, el NER identifica “Apple” como una organización, pero la desambiguación de entidades determina si esto se refiere a Apple Inc., la empresa tecnológica, o potencialmente a otra entidad con el mismo nombre. Esta distinción es fundamental para los sistemas de IA que necesitan comprender y citar el contenido con precisión, por lo que AmICited.com monitorea cómo sistemas de IA como ChatGPT, Perplexity y Google AI Overviews gestionan la desambiguación de entidades al generar respuestas sobre marcas y organizaciones.
El problema fundamental que resuelve la desambiguación de entidades es la ambigüedad: la realidad de que muchos nombres de entidades pueden referirse a diferentes objetos del mundo real. Esta ambigüedad genera importantes desafíos para los sistemas de IA que intentan comprender y generar contenido preciso. Según el Stanford AI Index 2024, más del 18% de las salidas de LLM que involucran entidades de marca contienen alucinaciones o atribuciones incorrectas, lo que significa que los sistemas de IA suelen confundir una entidad con otra o generan información falsa sobre las entidades. Este índice de error tiene graves implicaciones para la representación de marca y la precisión del contenido. Cuando un sistema de IA identifica incorrectamente una entidad, puede proporcionar información incorrecta, atribuir declaraciones a la organización equivocada o no citar la fuente correcta de la información.
| Nombre de la Entidad | Posibles Significados | Tasa de Confusión de IA |
|---|---|---|
| Apple | Empresa tecnológica / Fruta / Banco | Alta |
| Delta | Aerolínea / Fábrica de grifos / Letra griega | Alta |
| Jaguar | Fabricante de autos / Especie animal | Media |
| Amazon | Empresa de comercio electrónico / Selva / Río | Alta |
| Orange | Color / Fruta / Empresa de telecomunicaciones | Media |
Las consecuencias de una mala desambiguación de entidades van más allá de simples errores fácticos. Para creadores de contenido y marcas, la identificación errónea en respuestas generadas por IA puede conducir a pérdida de visibilidad, atribución incorrecta y daño a la reputación de la marca. Cuando un usuario pregunta a un sistema de IA sobre “Delta”, puede estar buscando información sobre Delta Air Lines, pero si el sistema la confunde con Delta Faucet Company, el usuario recibe información irrelevante. Por ello AmICited.com monitorea cómo los sistemas de IA desambiguar entidades, para ayudar a las marcas a entender si están siendo correctamente identificadas y citadas en el contenido generado por IA en múltiples plataformas.
La desambiguación de entidades opera a través de un proceso sistemático que combina múltiples técnicas de PLN para resolver la ambigüedad e identificar correctamente las entidades. Comprender este proceso revela por qué algunos sistemas de IA tienen mejor rendimiento que otros a la hora de mantener la precisión en las citaciones.
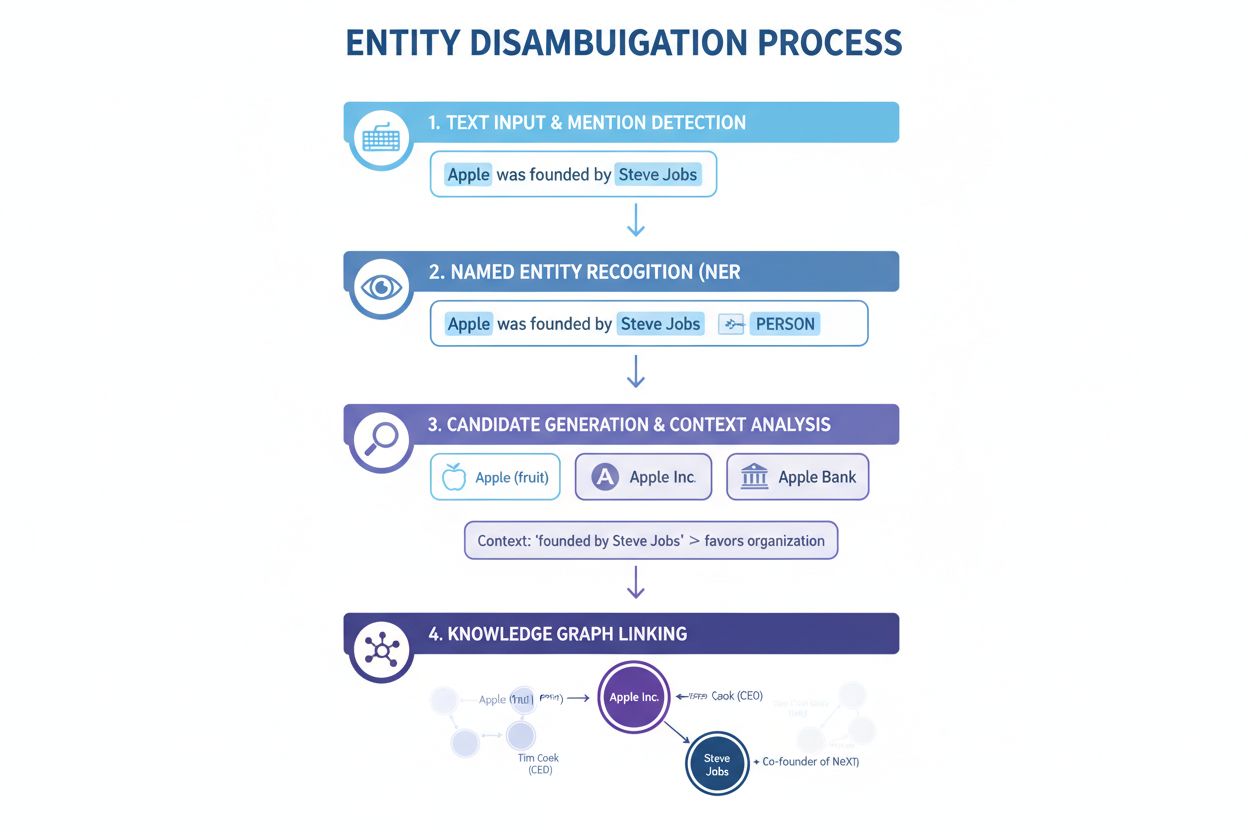
Reconocimiento de Entidades Nombradas (NER): El primer paso consiste en identificar y clasificar las entidades nombradas dentro del texto. Los sistemas NER analizan los datos textuales y localizan menciones de entidades, asignándolas a categorías predefinidas como persona, organización, lugar, producto o fecha. Por ejemplo, en la frase “Apple fue la creación de Steve Jobs”, el NER identifica tanto a “Apple” como a “Steve Jobs” como entidades y las clasifica como organización y persona, respectivamente. Este paso es esencial porque la desambiguación no puede ocurrir sin primero identificar qué entidades están presentes en el texto.
Categorización de Entidades: Una vez identificadas las entidades, deben ser categorizadas con mayor precisión. Esto implica no solo una clasificación amplia sino comprender el tipo específico y el contexto de cada entidad. El sistema analiza el texto circundante para entender si “Apple” aparece en un contexto tecnológico (sugiriendo Apple Inc.), alimenticio (la fruta) o financiero (Apple Bank). Este análisis contextual ayuda a reducir las posibilidades antes del paso de desambiguación propiamente dicho.
Desambiguación: Este es el paso central donde el sistema determina a qué entidad específica se está haciendo referencia. El sistema evalúa varias entidades candidatas que coinciden con el nombre identificado y utiliza distintas señales —incluyendo contexto, descripciones de entidades, relaciones semánticas e información de grafos de conocimiento— para seleccionar la entidad correcta más probable. Para “Apple fue la creación de Steve Jobs”, el sistema reconoce que Steve Jobs está fuertemente asociado a Apple Inc., haciendo de esa la elección correcta.
Vinculación a la Base de Conocimiento: El paso final consiste en vincular la entidad desambiguada a un identificador único en una base de conocimiento o grafo de conocimiento externo, como Wikidata, Wikipedia o una base de datos propietaria. Esta vinculación confirma la identidad de la entidad y enriquece el texto con información semántica para su posterior procesamiento y análisis. La entidad recibe un URI (Identificador Uniforme de Recursos) único que sirve como punto de referencia definitivo.
Distintos enfoques para la desambiguación de entidades han evolucionado con el tiempo, cada uno con ventajas y limitaciones específicas. Comprender estos enfoques ayuda a explicar por qué los sistemas de IA modernos varían en su precisión de desambiguación.
Enfoques Basados en Reglas: Estos sistemas utilizan reglas lingüísticas predefinidas y patrones heurísticos para desambiguar entidades. Pueden aplicar reglas como “si ‘Apple’ aparece cerca de ‘iPhone’ o ‘MacBook’, se refiere a Apple Inc.” o “si ‘Delta’ aparece cerca de ‘aerolínea’ o ‘vuelo’, se refiere a Delta Air Lines”. Si bien son interpretables y no requieren grandes conjuntos de datos de entrenamiento, tienen dificultades en contextos novedosos y no pueden adaptarse a nuevos significados sin actualizaciones manuales de reglas.
Enfoques de Aprendizaje Automático: Los modelos supervisados aprenden a partir de datos de entrenamiento anotados para predecir la entidad correcta según características contextuales. Estos sistemas extraen atributos del texto circundante y emplean algoritmos como Máquinas de Vectores de Soporte o Random Forests para clasificar la entidad más probable. Son más flexibles que los sistemas basados en reglas, pero requieren una gran cantidad de datos etiquetados y pueden no generalizar bien a entidades no vistas durante el entrenamiento.
Modelos de Deep Learning y Basados en Transformadores: La desambiguación moderna se apoya cada vez más en arquitecturas como BERT, RoBERTa y modelos especializados como GENRE y BLINK. Estos modelos utilizan redes neuronales para comprender el contexto a un nivel profundo, capturando relaciones semánticas y patrones lingüísticos sutiles. Los transformadores logran un rendimiento superior en benchmarks y pueden manejar escenarios complejos de desambiguación. Por ejemplo, el sistema CEEL (Common English Entity Linking) de Ontotext utiliza una arquitectura basada en transformadores optimizada para eficiencia en CPU, logrando un 96% de precisión en reconocimiento de entidades y 76% en vinculación en benchmarks estándar.
Integración de Grafos de Conocimiento: Los sistemas modernos combinan cada vez más el aprendizaje automático con grafos de conocimiento, bases de datos estructuradas que representan entidades y sus relaciones. Los grafos de conocimiento brindan información contextual sobre entidades, sus propiedades y relaciones. Al consultarlos durante la desambiguación, los sistemas acceden a metadatos, descripciones y relaciones que ayudan a resolver la ambigüedad con mayor precisión.
La desambiguación de entidades es esencial en numerosas industrias y aplicaciones, cada una beneficiándose de la identificación precisa de entidades y citaciones correctas.
Motores de Búsqueda: Google, Bing y otros dependen fuertemente de la desambiguación para mostrar resultados relevantes. Cuando un usuario busca “Apple”, el motor debe determinar si se refiere a Apple Inc., la fruta u otra entidad. Utilizan el contexto de la consulta, el historial del usuario y grafos de conocimiento para desambiguar y devolver los resultados más pertinentes. Por eso, los resultados de búsqueda para “Apple” suelen mostrar primero la empresa tecnológica: el sistema ha aprendido que es la entidad más comúnmente buscada.
Medios y Publicaciones: Organizaciones de noticias y plataformas de contenido usan la desambiguación para mejorar la descubribilidad de contenidos y enlazar artículos relacionados. Cuando un artículo menciona “Apple”, el sistema puede enlazar automáticamente con la entrada de Apple Inc. en la base de conocimientos, brindando al lector contexto adicional y artículos relacionados. Esto mejora la experiencia y ayuda a comprender el contexto.
Salud: Instituciones médicas emplean la desambiguación para identificar con precisión medicamentos, enfermedades y procedimientos en expedientes clínicos y literatura científica. Desambiguar nombres de medicamentos es fundamental: “aspirina” puede referirse al genérico, una marca específica o una variante de dosis. Una desambiguación precisa asegura que los profesionales accedan a la información correcta y los registros se organicen apropiadamente.
Servicios Financieros: Firmas de inversión y analistas utilizan la desambiguación para rastrear menciones de empresas en noticias, informes de resultados y datos de mercado. Al analizar la exposición al mercado, una firma debe identificar correctamente todas las menciones de una empresa específica en diversas fuentes. La desambiguación asegura que las referencias a “Apple” se atribuyan correctamente a Apple Inc., permitiendo una evaluación precisa de riesgos y carteras.
Comercio Electrónico: Minoristas en línea utilizan la desambiguación para relacionar menciones de productos con artículos reales en sus catálogos. Cuando un cliente busca “portátil Apple”, el sistema debe desambiguar “Apple” como la empresa y asociarlo con los productos correctos. Esto mejora la precisión en la búsqueda y ayuda al cliente a encontrar lo que busca.
AmICited.com aplica los principios de desambiguación para monitorear cómo sistemas como ChatGPT, Perplexity y Google AI Overviews gestionan menciones de marcas. Al rastrear si estos sistemas desambiguan y citan correctamente las marcas, AmICited ayuda a las empresas a comprender su visibilidad y representación en el contenido generado por IA.
Los grafos de conocimiento son fundamentales en los sistemas modernos de desambiguación, proporcionando representaciones estructuradas de entidades y sus relaciones. Un grafo de conocimiento es esencialmente una base de datos de entidades (nodos) y las relaciones entre ellas (aristas). Cada nodo contiene metadatos como nombre, descripción, tipo y propiedades. Por ejemplo, en un grafo, “Apple Inc.” podría tener propiedades como “fundada en 1976”, “sede en Cupertino”, “industria: tecnología”, y relaciones como “fundada por Steve Jobs” y “produce iPhone”.
Cuando un sistema de desambiguación encuentra una mención ambigua, puede consultar el grafo para acceder a información contextual sobre las entidades candidatas. Esto ayuda al sistema a tomar decisiones más informadas. Por ejemplo, si el sistema trata de desambiguar “Apple” y el texto menciona “Steve Jobs”, puede consultar el grafo y descubrir que Steve Jobs está estrechamente asociado a Apple Inc., haciendo de esa la entidad más probable. Grafos como Wikidata y Wikipedia ofrecen información pública que muchos sistemas de IA utilizan durante la inferencia. Grafos propietarios de empresas como Google o Microsoft proporcionan información adicional de dominio específico. La integración de grafos con modelos de aprendizaje ha mejorado notablemente la precisión de la desambiguación, ya que los sistemas pueden combinar patrones aprendidos con información factual estructurada.
A pesar de los avances, los sistemas enfrentan desafíos persistentes que limitan su precisión y aplicabilidad.
Polisemia y Ambigüedad: Muchos nombres tienen múltiples significados legítimos, y el contexto puede no ser suficiente para desambiguar. “Banco” puede referirse a una institución financiera o la orilla de un río. “Grúa” puede ser un ave o una máquina de construcción. Algunos nombres son tan ambiguos que incluso para humanos es difícil sin contexto adicional. Los sistemas deben aprender a reconocer cuándo el contexto es insuficiente y manejarlo apropiadamente.
Nuevas Entidades Emergentes: Las bases de conocimiento y los datos de entrenamiento se quedan obsoletos a medida que surgen nuevas entidades. Cuando se funda una empresa o lanza un producto, los sistemas pueden no tener información en sus bases. El enlace de entidades zero-shot —desambiguar entidades no vistas en entrenamiento— sigue siendo un reto. Los sistemas deben reconocer nuevas entidades y no emparejarlas erróneamente con existentes de nombre similar.
Variaciones y Errores Ortográficos: Las entidades suelen tener varios nombres, abreviaturas y variantes. “Estados Unidos”, “EE.UU.”, “U.S.A.”, “América” refieren a lo mismo. Los errores ortográficos complican aún más. Los sistemas deben reconocer estas variantes y mapearlas correctamente a la entidad canónica, especialmente en contenido generado por usuarios.
Datos Incompletos o Desactualizados: Las bases pueden tener información incompleta o desactualizada, ya que las entidades evolucionan. La sede de una empresa puede cambiar, la dirección cambiar o ser adquirida. Si la base no se actualiza, los sistemas pueden tomar decisiones basadas en información obsoleta.
Escalabilidad y Rendimiento: Procesar grandes volúmenes de texto con alta precisión requiere muchos recursos computacionales. La desambiguación en tiempo real para aplicaciones web es costosa. Los sistemas deben equilibrar precisión, velocidad y coste, lo que a menudo implica sacrificar calidad.
Para marcas y creadores de contenido, comprender la desambiguación es esencial para asegurar una representación precisa en contenidos generados por IA. A medida que estas tecnologías influyen en cómo se descubre y consume información, las marcas deben tomar medidas proactivas para garantizar que sean desambiguadas y citadas correctamente.
Estrategias de Pre-desambiguación: Las marcas pueden crear señales digitales claras y distintivas para facilitar la desambiguación. Una estrategia clave es implementar datos estructurados con marcado Schema.org y formato JSON-LD en sus sitios. Estos datos informan explícitamente a la IA sobre la identidad de la marca: nombre oficial, descripción, logo, ubicación y otros rasgos distintivos. Así, la IA puede referenciar estos datos para confirmar la entidad correcta.
Optimización en Grafos de Conocimiento: Las marcas deben asegurar su presencia en grafos como Wikidata y Wikipedia, creando o manteniendo artículos precisos y relaciones con entidades relacionadas. Cuanto más completa y actualizada sea esta presencia, más información tendrá la IA para desambiguar.
Estrategia de Contenido Contextual: Crear contenido que brinde contexto claro sobre su identidad y diferencia frente a entidades similares. Contenido que mencione explícitamente industria, productos, fundadores y propuesta de valor ayuda a los sistemas a comprender los rasgos distintivos de la marca, convirtiéndose en parte del contexto y datos de entrenamiento.
Monitoreo de Citaciones: Herramientas como AmICited.com permiten monitorear cómo los sistemas desambiguar y citan la marca en distintas plataformas. Al rastrear si ChatGPT, Perplexity, Google AI Overviews, etc., identifican y citan correctamente, las marcas pueden detectar fallos y tomar acciones correctivas. Este monitoreo es vital para entender la visibilidad en la era de la IA generativa.
Optimización para Motores Generativos (GEO): A medida que la desambiguación gana importancia para la visibilidad en IA, las marcas deben integrar la optimización de entidades en su estrategia de Generative Engine Optimization. Esto implica definir, documentar y diferenciar claramente la entidad frente a competidores. GEO abarca tanto SEO tradicional como la optimización de cómo los sistemas de IA comprenden y representan las marcas.
La desambiguación evoluciona a medida que la tecnología de IA avanza y surgen nuevos desafíos. Varias tendencias están modelando el futuro de esta capacidad crítica.
Desambiguación Multilingüe: A medida que los sistemas son más globales, la capacidad de desambiguar en varios idiomas es clave. Un nombre puede escribirse diferente o referirse de distintas formas según el idioma. Se desarrollan modelos multilingües avanzados para gestionar la desambiguación más allá de las fronteras lingüísticas, permitiendo sistemas realmente globales.
Desambiguación en Tiempo Real en LLMs: Los modelos modernos como GPT-4 y Claude incorporan desambiguación en tiempo real durante la generación de texto. En vez de depender solo de datos de entrenamiento, pueden consultar grafos y bases externas durante la inferencia para verificar información y asegurar precisión, mejorando la citación y reduciendo alucinaciones.
Mejoras en Zero-Shot Learning: Los sistemas futuros lograrán mejor desempeño en entidades no vistas en entrenamiento. Los avances en aprendizaje few-shot y zero-shot permitirán desambiguar nuevas entidades sin reentrenamiento frecuente, haciendo los sistemas más adaptables.
Integración con RAG (Generación Aumentada por Recuperación): Los sistemas de generación aumentada por recuperación, que combinan modelos de lenguaje con recuperación de información, ganan popularidad. Pueden recuperar información relevante de bases durante la generación, mejorando desambiguación y calidad de citaciones.
Estandarización e Interoperabilidad: A medida que la desambiguación es más crítica, surgirán estándares para la representación y desambiguación de entidades, permitiendo mejor interoperabilidad entre sistemas y bases y facilitando el acceso y uso consistente de la información.
La desambiguación de entidades ha pasado de ser una tarea de nicho en PLN a una capacidad crítica para asegurar que los sistemas de IA comprendan y representen la información con precisión. A medida que la IA influye cada vez más en cómo se descubre y consume información, la importancia de la desambiguación precisa solo aumentará. Para marcas, creadores y organizaciones, comprender y optimizar la desambiguación es esencial para mantener la visibilidad y asegurar una representación certera en la era de la IA generativa.
El reconocimiento de entidades nombradas identifica que existe una entidad en el texto y la clasifica en categorías como persona, organización o lugar. La desambiguación de entidades va más allá, determinando a qué entidad específica se está haciendo referencia cuando varias entidades comparten el mismo nombre. Por ejemplo, el NER identifica 'Apple' como una organización, mientras que la desambiguación de entidades determina si se refiere a Apple Inc., Apple Bank u otra entidad.
La desambiguación de entidades garantiza que los sistemas de IA comprendan con precisión qué entidad se está discutiendo y la citen correctamente. Según el Stanford AI Index 2024, más del 18% de las salidas de LLM que involucran entidades de marca contienen alucinaciones o atribuciones incorrectas. Una desambiguación precisa previene que los sistemas de IA confundan una entidad con otra, lo cual es crucial para mantener la reputación de la marca y la precisión en las citaciones.
Los grafos de conocimiento proporcionan información estructurada sobre las entidades y sus relaciones. Cuando un sistema de IA encuentra una mención de entidad ambigua, puede consultar el grafo de conocimiento para acceder a metadatos, descripciones e información de relaciones sobre las entidades candidatas. Esta información contextual ayuda al sistema a tomar decisiones de desambiguación más informadas y seleccionar la entidad correcta.
Sí, mediante enfoques de vinculación de entidades zero-shot. Los sistemas modernos pueden reconocer cuándo una entidad es nueva y gestionarla adecuadamente en lugar de emparejarla incorrectamente con una entidad existente. Sin embargo, sigue siendo un problema desafiante, y los sistemas tienen mejor rendimiento cuando las nuevas entidades cuentan con señales contextuales claras que las distinguen de las existentes.
Una desambiguación precisa garantiza que tu marca sea identificada y citada correctamente en las respuestas generadas por IA. Cuando los sistemas de IA desambiguan correctamente tu marca, los usuarios reciben información precisa sobre tu organización, mejorando la visibilidad y la reputación de la marca. Una mala desambiguación puede llevar a que tu marca se confunda con competidores u otras entidades, reduciendo la visibilidad y dañando potencialmente la reputación.
Los desafíos clave incluyen polisemia (múltiples significados para el mismo nombre), nuevas entidades no presentes en los datos de entrenamiento, variantes de nombre y errores ortográficos, bases de conocimiento incompletas o desactualizadas, y problemas de escalabilidad. Además, algunos nombres de entidades son intrínsecamente ambiguos y el contexto por sí solo puede no ser suficiente para determinar la entidad correcta.
Las marcas pueden implementar datos estructurados mediante marcado Schema.org, mantener entradas precisas en Wikipedia y Wikidata, crear contenido contextual que distinga claramente su marca, y monitorear cómo los sistemas de IA desambiguan su marca usando herramientas como AmICited. Estas estrategias ayudan a que los sistemas de IA identifiquen y citen correctamente tu marca.
El contexto es crucial para la desambiguación de entidades. El texto circundante, entidades relacionadas y las relaciones semánticas proporcionan señales que ayudan a los sistemas de IA a determinar a qué entidad se hace referencia. Por ejemplo, si 'Apple' aparece cerca de 'Steve Jobs' y 'tecnología', el sistema puede usar este contexto para desambiguar correctamente como Apple Inc. en lugar de la fruta.
Haz seguimiento a la precisión de la desambiguación de entidades en plataformas de IA y asegúrate de que tu marca sea identificada y citada correctamente en las respuestas generadas por IA.
El Reconocimiento de Entidades es una capacidad de IA y PLN que identifica y categoriza entidades nombradas en texto. Descubre cómo funciona, sus aplicaciones e...

Explora cómo los sistemas de IA reconocen y procesan entidades en el texto. Aprende sobre modelos NER, arquitecturas de transformers y aplicaciones reales de la...

Aprende cómo la vinculación de entidades conecta tu marca en los sistemas de IA. Descubre estrategias para mejorar el reconocimiento de marca en ChatGPT, Perple...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.