
Arquitectura Transformer
La Arquitectura Transformer es un diseño de red neuronal que utiliza mecanismos de autoatención para procesar datos secuenciales en paralelo. Impulsa ChatGPT, C...
20 min de lectura
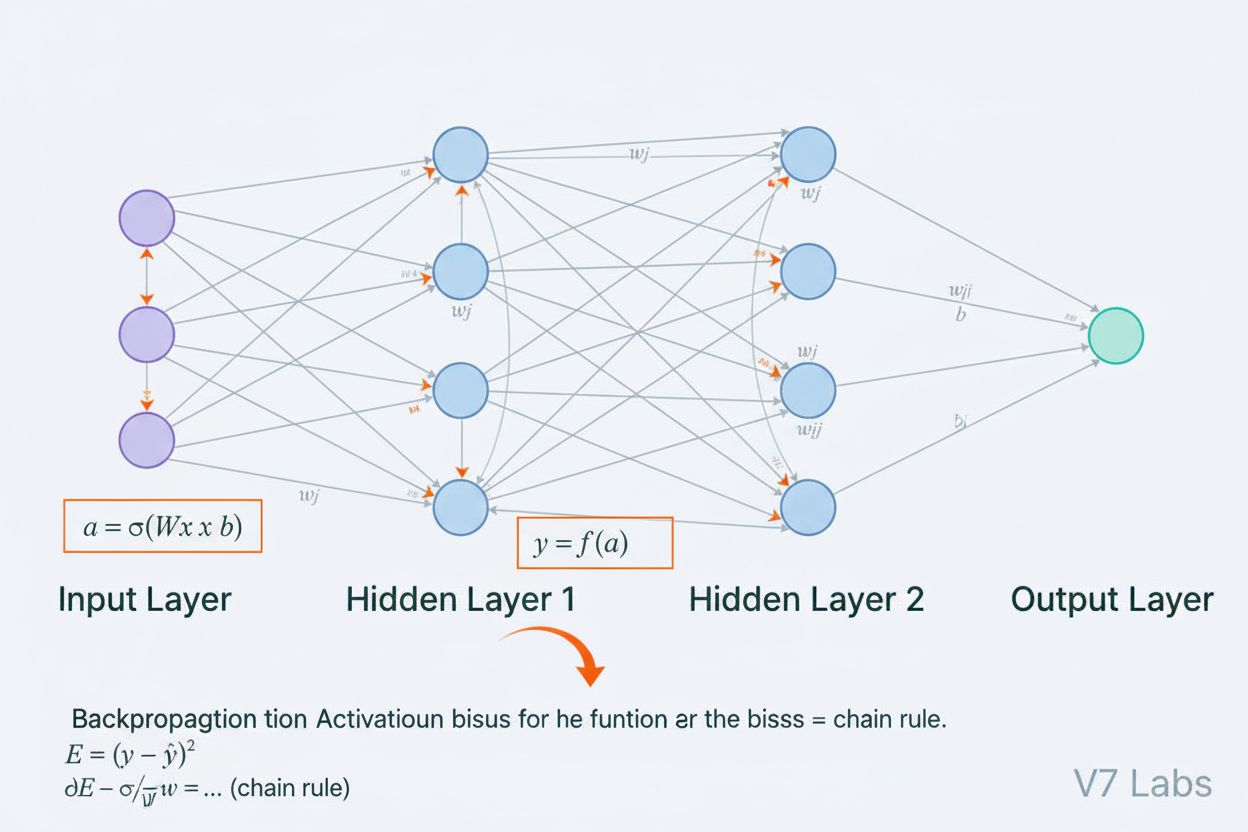
Una red neuronal es un sistema informático inspirado en las redes neuronales biológicas que consiste en neuronas artificiales interconectadas organizadas en capas, capaces de aprender patrones a partir de datos mediante un proceso llamado retropropagación. Estos sistemas forman la base de la inteligencia artificial moderna y el aprendizaje profundo, impulsando aplicaciones desde el procesamiento del lenguaje natural hasta la visión por computadora.
Una red neuronal es un sistema informático inspirado en las redes neuronales biológicas que consiste en neuronas artificiales interconectadas organizadas en capas, capaces de aprender patrones a partir de datos mediante un proceso llamado retropropagación. Estos sistemas forman la base de la inteligencia artificial moderna y el aprendizaje profundo, impulsando aplicaciones desde el procesamiento del lenguaje natural hasta la visión por computadora.
Una red neuronal es un sistema informático fundamentalmente inspirado en la estructura y función de las redes neuronales biológicas presentes en los cerebros de los animales. Consiste en neuronas artificiales interconectadas, organizadas en capas—típicamente una capa de entrada, una o más capas ocultas y una capa de salida—que trabajan juntas para procesar datos, reconocer patrones y hacer predicciones. Cada neurona recibe entradas, aplica transformaciones matemáticas mediante pesos y sesgos, y pasa el resultado a través de una función de activación para producir una salida. La característica definitoria de las redes neuronales es su capacidad para aprender de los datos a través de un proceso iterativo llamado retropropagación, donde la red ajusta sus parámetros internos para minimizar los errores de predicción. Esta capacidad de aprendizaje, combinada con su habilidad para modelar relaciones no lineales complejas, ha hecho de las redes neuronales la tecnología fundamental que impulsa los sistemas modernos de inteligencia artificial, desde grandes modelos de lenguaje hasta aplicaciones de visión por computadora.
El concepto de redes neuronales artificiales surgió de los primeros intentos de modelar matemáticamente cómo las neuronas biológicas se comunican y procesan información. En 1943, Warren McCulloch y Walter Pitts propusieron el primer modelo matemático de una neurona, demostrando que unidades computacionales simples podían realizar operaciones lógicas. Esta base teórica fue seguida por la introducción del perceptrón por Frank Rosenblatt en 1958, un algoritmo diseñado para el reconocimiento de patrones que se convirtió en el antecesor histórico de las actuales arquitecturas sofisticadas de redes neuronales. El perceptrón era esencialmente un modelo lineal con salida restringida, capaz de aprender límites de decisión simples. Sin embargo, el campo experimentó importantes retrocesos en la década de 1970 cuando los investigadores descubrieron que los perceptrones de una sola capa no podían resolver problemas no lineales como la función XOR, lo que llevó a lo que se conoció como el “invierno de la IA”. El avance llegó en los años 80 con el redescubrimiento y perfeccionamiento de la retropropagación, un algoritmo que permitió el entrenamiento de redes multicapa. Este resurgimiento se aceleró dramáticamente en la década de 2010 con la disponibilidad de conjuntos de datos masivos, potentes GPUs y técnicas de entrenamiento refinadas, dando lugar a la revolución del aprendizaje profundo que transformó la inteligencia artificial.
La arquitectura de una red neuronal comprende varios componentes esenciales que trabajan en conjunto. La capa de entrada recibe las características de datos crudos desde fuentes externas, correspondiendo cada neurona de esta capa a una característica. Las capas ocultas realizan el trabajo computacional principal, transformando las entradas en representaciones cada vez más abstractas mediante combinaciones ponderadas y funciones de activación no lineales. El número y tamaño de las capas ocultas determinan la capacidad de la red para aprender patrones complejos—las redes más profundas pueden captar relaciones más sofisticadas pero requieren más datos y recursos computacionales. La capa de salida produce las predicciones finales, y su estructura depende de la tarea: una sola neurona para regresión, múltiples neuronas para clasificación multiclase, o arquitecturas especializadas para otras aplicaciones. Cada conexión entre neuronas lleva un peso que determina la fuerza de influencia, mientras que cada neurona tiene un sesgo que desplaza su umbral de activación. Estos pesos y sesgos son los parámetros ajustables que la red modifica durante el entrenamiento. La función de activación aplicada en cada neurona introduce una no linealidad crucial, permitiendo que la red aprenda límites de decisión y patrones complejos que los modelos lineales no pueden captar.
Las redes neuronales aprenden a través de un proceso iterativo de dos fases. Durante la propagación hacia adelante, los datos de entrada fluyen a través de la red desde la capa de entrada hasta la capa de salida. En cada neurona, se calcula la suma ponderada de las entradas más el sesgo (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), que luego se pasa por una función de activación para producir la salida de la neurona. Este proceso se repite a través de cada capa oculta hasta llegar a la capa de salida, que produce la predicción de la red. La red calcula entonces el error entre su predicción y la etiqueta real utilizando una función de pérdida, que cuantifica cuán lejos está la predicción de la respuesta correcta. En la retropropagación, este error se propaga hacia atrás a través de la red usando la regla de la cadena del cálculo. En cada neurona, el algoritmo calcula el gradiente de la pérdida con respecto a cada peso y sesgo, determinando cuánto contribuyó cada parámetro al error total. Estos gradientes guían la actualización de los parámetros: los pesos y sesgos se ajustan en la dirección opuesta al gradiente, escalados por una tasa de aprendizaje que controla el tamaño del paso. Este proceso se repite durante muchas iteraciones a través del conjunto de datos de entrenamiento, reduciendo gradualmente la pérdida y mejorando las predicciones de la red. La combinación de propagación hacia adelante, cálculo de la pérdida, retropropagación y actualización de parámetros forma el ciclo completo de entrenamiento que permite a las redes neuronales aprender de los datos.
| Tipo de Arquitectura | Caso de Uso Principal | Característica Clave | Fortalezas | Limitaciones |
|---|---|---|---|---|
| Redes Feedforward | Clasificación, regresión en datos estructurados | La información fluye solo en una dirección | Simples, entrenamiento rápido, interpretables | No manejan bien datos secuenciales o espaciales |
| Redes Neuronales Convolucionales (CNN) | Reconocimiento de imágenes, visión por computadora | Las capas convolucionales detectan características espaciales | Excelentes captando patrones locales, eficientes en parámetros | Requieren grandes conjuntos de imágenes etiquetadas |
| Redes Neuronales Recurrentes (RNN) | Datos secuenciales, series temporales, PLN | El estado oculto mantiene memoria a través de pasos de tiempo | Pueden procesar secuencias de longitud variable | Sufren problemas de gradientes desvanecidos/explosivos |
| Memoria a Largo y Corto Plazo (LSTM) | Dependencias a largo plazo en secuencias | Celdas de memoria con compuertas de entrada/olvido/salida | Manejan eficazmente dependencias a largo plazo | Más complejas, entrenamiento más lento que las RNN |
| Redes Transformer | Procesamiento de lenguaje natural, grandes modelos de lenguaje | Mecanismo de atención multi-cabeza, procesamiento en paralelo | Altamente paralelizables, captan dependencias de largo alcance | Requieren enormes recursos computacionales |
| Redes Generativas Antagónicas (GANs) | Generación de imágenes, creación de datos sintéticos | Generador y discriminador compiten | Pueden generar datos sintéticos realistas | Difíciles de entrenar, problemas de colapso de modos |
La introducción de funciones de activación representa una de las innovaciones más críticas en el diseño de redes neuronales. Sin funciones de activación, una red neuronal sería matemáticamente equivalente a una sola transformación lineal, sin importar cuántas capas contenga. Esto se debe a que la composición de funciones lineales es también lineal, lo que limita severamente la capacidad de la red para aprender patrones complejos. Las funciones de activación resuelven este problema al introducir no linealidad en cada neurona. La función ReLU (Unidad Lineal Rectificada), definida como f(x) = max(0, x), se ha convertido en la opción más popular en el aprendizaje profundo moderno debido a su eficiencia computacional y efectividad para entrenar redes profundas. La función sigmoide, f(x) = 1/(1 + e^(-x)), reduce las salidas a un rango entre 0 y 1, por lo que es útil para tareas de clasificación binaria. La función tanh, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), produce salidas entre -1 y 1 y suele funcionar mejor que la sigmoide en capas ocultas. La elección de la función de activación impacta significativamente la dinámica de aprendizaje de la red, la velocidad de convergencia y el rendimiento final. Las arquitecturas modernas suelen utilizar ReLU en capas ocultas por su eficiencia computacional y sigmoide o softmax en las capas de salida para estimación de probabilidades. La no linealidad introducida por las funciones de activación permite a las redes neuronales aproximar cualquier función continua, una propiedad conocida como el teorema de aproximación universal, lo que explica su notable versatilidad en aplicaciones diversas.
El mercado de redes neuronales ha experimentado un crecimiento explosivo, reflejando el papel central de la tecnología en la inteligencia artificial moderna. Según investigaciones de mercado recientes, el mercado global de software de redes neuronales fue valorado en aproximadamente $34.76 mil millones en 2025 y se proyecta que alcance los $139.86 mil millones para 2030, representando una tasa de crecimiento anual compuesta (CAGR) de 32.10%. El mercado general de redes neuronales muestra una expansión aún más dramática, con estimaciones que sugieren un crecimiento de $34.05 mil millones en 2024 a $385.29 mil millones para 2033, con una CAGR de 31.4%. Este crecimiento explosivo es impulsado por múltiples factores: la disponibilidad creciente de grandes conjuntos de datos, el desarrollo de algoritmos de entrenamiento más eficientes, la proliferación de hardware especializado en IA y GPU, y la adopción generalizada de redes neuronales en diversas industrias. Según el AI Index Report de Stanford de 2025, el 78% de las organizaciones reportaron usar IA en 2024, frente al 55% del año anterior, siendo las redes neuronales la columna vertebral de la mayoría de implementaciones empresariales de IA. La adopción abarca salud, finanzas, manufactura, retail y prácticamente todos los sectores, ya que las organizaciones reconocen la ventaja competitiva que proporcionan los sistemas basados en redes neuronales para reconocimiento de patrones, predicción y toma de decisiones.
Las redes neuronales impulsan los sistemas de IA más avanzados actualmente desplegados, incluyendo ChatGPT, Perplexity, Google AI Overviews y Claude. Estos grandes modelos de lenguaje se construyen sobre arquitecturas de redes neuronales tipo transformer que utilizan mecanismos de atención para procesar y generar lenguaje humano con notable sofisticación. La arquitectura transformer, introducida en 2017, revolucionó el procesamiento del lenguaje natural al permitir el procesamiento en paralelo de secuencias completas en lugar de procesamiento secuencial, mejorando drásticamente la eficiencia de entrenamiento y el rendimiento de los modelos. En el contexto de monitoreo de marcas y seguimiento de citas de IA, comprender las redes neuronales es crucial porque estos sistemas las utilizan para entender el contexto, recuperar información relevante y generar respuestas que pueden hacer referencia o citar tu marca, dominio o contenido. AmICited aprovecha el conocimiento de cómo las redes neuronales procesan y recuperan información para monitorear dónde aparece tu marca en respuestas generadas por IA en múltiples plataformas. A medida que las redes neuronales continúan mejorando su capacidad de entender el significado semántico y recuperar información relevante, la importancia de monitorear la presencia de tu marca en respuestas de IA se vuelve cada vez más crítica para mantener la visibilidad de marca y gestionar la reputación en línea en la era de la búsqueda y la generación de contenido impulsadas por IA.
Entrenar redes neuronales de manera efectiva presenta varios desafíos significativos que investigadores y profesionales deben abordar. El sobreajuste ocurre cuando una red aprende demasiado bien los datos de entrenamiento, incluyendo su ruido y peculiaridades, lo que resulta en un desempeño deficiente con datos nuevos no vistos. Esto es especialmente problemático en redes profundas con muchos parámetros en relación al tamaño del conjunto de entrenamiento. El subajuste representa el problema opuesto, donde la red carece de suficiente capacidad o entrenamiento para captar los patrones subyacentes en los datos. El problema del gradiente desvanecido ocurre en redes muy profundas donde los gradientes se vuelven exponencialmente pequeños a medida que se propagan hacia atrás, provocando que los pesos de las capas iniciales se actualicen muy lentamente o no lo hagan. El problema del gradiente explosivo es lo opuesto, donde los gradientes se vuelven exponencialmente grandes, causando un entrenamiento inestable. Las soluciones modernas incluyen la normalización por lotes (batch normalization), que normaliza las entradas de las capas para mantener un flujo de gradientes estable; conexiones residuales (skip connections), que permiten que los gradientes fluyan directamente a través de las capas; y clipping de gradientes, que limita la magnitud de los gradientes. Las técnicas de regularización como la regularización L1 y L2 añaden penalizaciones para pesos grandes, fomentando modelos más simples que generalizan mejor. Dropout desactiva aleatoriamente neuronas durante el entrenamiento, previniendo la coadaptación y mejorando la generalización. La elección del optimizador (como Adam, SGD o RMSprop) y la tasa de aprendizaje impactan significativamente la eficiencia del entrenamiento y el rendimiento final del modelo. Los profesionales deben equilibrar cuidadosamente la complejidad del modelo, el tamaño del conjunto de entrenamiento, la fuerza de regularización y los parámetros de optimización para lograr redes que aprendan efectivamente sin sobreajustar.
La evolución de las arquitecturas de redes neuronales ha seguido una trayectoria clara hacia mecanismos cada vez más sofisticados para procesar información. Las primeras redes feedforward estaban limitadas a entradas de tamaño fijo y no podían captar dependencias temporales o secuenciales. Las redes neuronales recurrentes (RNN) introdujeron bucles de retroalimentación que permiten que la información persista a través de pasos de tiempo, permitiendo procesar secuencias de longitud variable. Sin embargo, las RNN sufrían problemas de flujo de gradientes y eran inherentemente secuenciales, lo que impedía su paralelización en hardware moderno. Las redes de memoria a largo y corto plazo (LSTM) abordaron algunos de estos problemas mediante celdas de memoria y mecanismos de compuertas, pero seguían siendo fundamentalmente secuenciales. El avance llegó con las redes transformer, que reemplazaron la recurrencia completamente con mecanismos de atención. El mecanismo de atención permite que la red se enfoque dinámicamente en diferentes partes de la entrada, calculando combinaciones ponderadas de todos los elementos de entrada en paralelo. Esto permite que los transformers capten dependencias de largo alcance de manera eficiente mientras mantienen total paralelismo en clústeres de GPU. La arquitectura transformer, combinada con una escala masiva (los grandes modelos de lenguaje modernos contienen miles de millones a billones de parámetros), ha demostrado ser extremadamente efectiva en procesamiento de lenguaje natural, visión por computadora y tareas multimodales. El éxito de los transformers ha llevado a su adopción como la arquitectura estándar para sistemas de IA de última generación, incluyendo todos los principales grandes modelos de lenguaje. Esta evolución demuestra cómo las innovaciones arquitectónicas, combinadas con mayores recursos computacionales y conjuntos de datos más grandes, continúan expandiendo los límites de lo que las redes neuronales pueden lograr.
El campo de las redes neuronales sigue evolucionando rápidamente con varias direcciones prometedoras emergiendo. La computación neuromórfica busca crear hardware que imite más de cerca las redes neuronales biológicas, logrando potencialmente mayor eficiencia energética y poder de cómputo. La investigación en few-shot y zero-shot learning se centra en permitir que las redes neuronales aprendan a partir de muy pocos ejemplos, asemejándose más al aprendizaje humano. La explicabilidad e interpretabilidad se han vuelto cada vez más importantes, y los investigadores desarrollan técnicas para entender y visualizar lo que aprenden las redes neuronales, crucial para aplicaciones críticas como salud, finanzas y justicia. El aprendizaje federado permite entrenar redes neuronales en datos distribuidos sin centralizar información sensible, abordando preocupaciones de privacidad. Las redes neuronales cuánticas representan una frontera donde los principios de la computación cuántica se combinan con arquitecturas de redes neuronales, ofreciendo potencialmente aceleraciones exponenciales para ciertos problemas. Las redes neuronales multimodales que integran texto, imágenes, audio y video se vuelven cada vez más sofisticadas, permitiendo sistemas de IA más completos. Las redes neuronales eficientes energéticamente se desarrollan para reducir los costos computacionales y medioambientales de entrenar y desplegar modelos grandes. A medida que las redes neuronales continúan avanzando, su integración en sistemas de monitoreo de IA como AmICited se vuelve cada vez más importante para organizaciones que buscan comprender y gestionar la presencia de su marca en contenido y respuestas generadas por IA en plataformas como ChatGPT, Perplexity, Google AI Overviews y Claude.
Las redes neuronales están inspiradas en la estructura y función de las neuronas biológicas en el cerebro humano. En el cerebro, las neuronas se comunican a través de señales eléctricas mediante sinapsis, que pueden fortalecerse o debilitarse en función de la experiencia. Las redes neuronales artificiales imitan este comportamiento utilizando modelos matemáticos de neuronas conectadas a través de enlaces ponderados, lo que permite al sistema aprender y adaptarse a partir de datos de manera análoga a cómo los cerebros biológicos procesan la información y forman recuerdos.
La retropropagación es el algoritmo principal que permite a las redes neuronales aprender. Durante la propagación hacia adelante, los datos fluyen a través de las capas de la red produciendo predicciones. La red calcula entonces el error entre las salidas predichas y las reales utilizando una función de pérdida. En la pasada hacia atrás, este error se propaga hacia atrás a través de la red utilizando la regla de la cadena del cálculo, calculando cuánto contribuyó cada peso y sesgo al error. Luego, los pesos se ajustan en la dirección que minimiza el error, normalmente utilizando la optimización por descenso de gradiente.
Las principales arquitecturas de redes neuronales incluyen redes feedforward (los datos fluyen en una sola dirección), redes neuronales convolucionales o CNN (optimizadas para procesamiento de imágenes), redes neuronales recurrentes o RNN (diseñadas para datos secuenciales), redes de memoria a largo y corto plazo o LSTM (RNN mejoradas con celdas de memoria), y redes transformer (que utilizan mecanismos de atención para procesamiento en paralelo). Cada arquitectura está especializada para diferentes tipos de datos y tareas, desde el reconocimiento de imágenes hasta el procesamiento de lenguaje natural.
Los sistemas de IA modernos como ChatGPT, Perplexity y Claude están construidos sobre redes neuronales basadas en transformadores, que utilizan mecanismos de atención para procesar el lenguaje de manera eficiente. Estas redes neuronales permiten a estos sistemas comprender el contexto, generar textos coherentes y realizar tareas de razonamiento complejas. La capacidad de las redes neuronales para aprender de conjuntos de datos masivos y captar patrones complejos en el lenguaje las hace esenciales para construir IA conversacional capaz de entender y responder a consultas humanas con notable precisión.
Los pesos en las redes neuronales controlan la fuerza de las conexiones entre neuronas, determinando cuánta influencia tiene cada entrada sobre la salida. Los sesgos son parámetros adicionales que desplazan el umbral de activación de las neuronas, permitiendo que se activen incluso cuando las entradas son débiles. Juntos, pesos y sesgos forman los parámetros ajustables de la red que se modifican durante el entrenamiento para minimizar errores de predicción y permitir que la red aprenda patrones complejos a partir de los datos.
Las funciones de activación introducen no linealidad en las redes neuronales, permitiendo que aprendan relaciones complejas y no lineales en los datos. Sin funciones de activación, apilar múltiples capas seguiría resultando en transformaciones lineales, limitando severamente la capacidad de aprendizaje de la red. Las funciones de activación comunes incluyen ReLU (Unidad Lineal Rectificada), sigmoide y tanh, cada una introduciendo diferentes tipos de no linealidad que ayudan a la red a captar patrones intrincados y realizar predicciones más sofisticadas.
Las capas ocultas son capas intermedias entre las capas de entrada y salida donde la red realiza la mayor parte de su trabajo computacional. Estas capas extraen y transforman características de los datos de entrada en representaciones cada vez más abstractas. La profundidad y el ancho de las capas ocultas determinan la capacidad de la red para aprender patrones complejos. Redes más profundas con más capas ocultas pueden captar relaciones más sofisticadas en los datos, aunque requieren más recursos computacionales y un entrenamiento cuidadoso para evitar el sobreajuste.
Comienza a rastrear cómo los chatbots de IA mencionan tu marca en ChatGPT, Perplexity y otras plataformas. Obtén información procesable para mejorar tu presencia en IA.
La Arquitectura Transformer es un diseño de red neuronal que utiliza mecanismos de autoatención para procesar datos secuenciales en paralelo. Impulsa ChatGPT, C...
Descubre qué es una Red Privada de Blogs (PBN), cómo funciona, por qué infringe las directrices de Google y los riesgos de utilizar PBNs para la construcción de...
Aprende qué es un gráfico en la visualización de datos. Descubre cómo los gráficos muestran relaciones entre datos utilizando nodos y aristas, y por qué son ese...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.