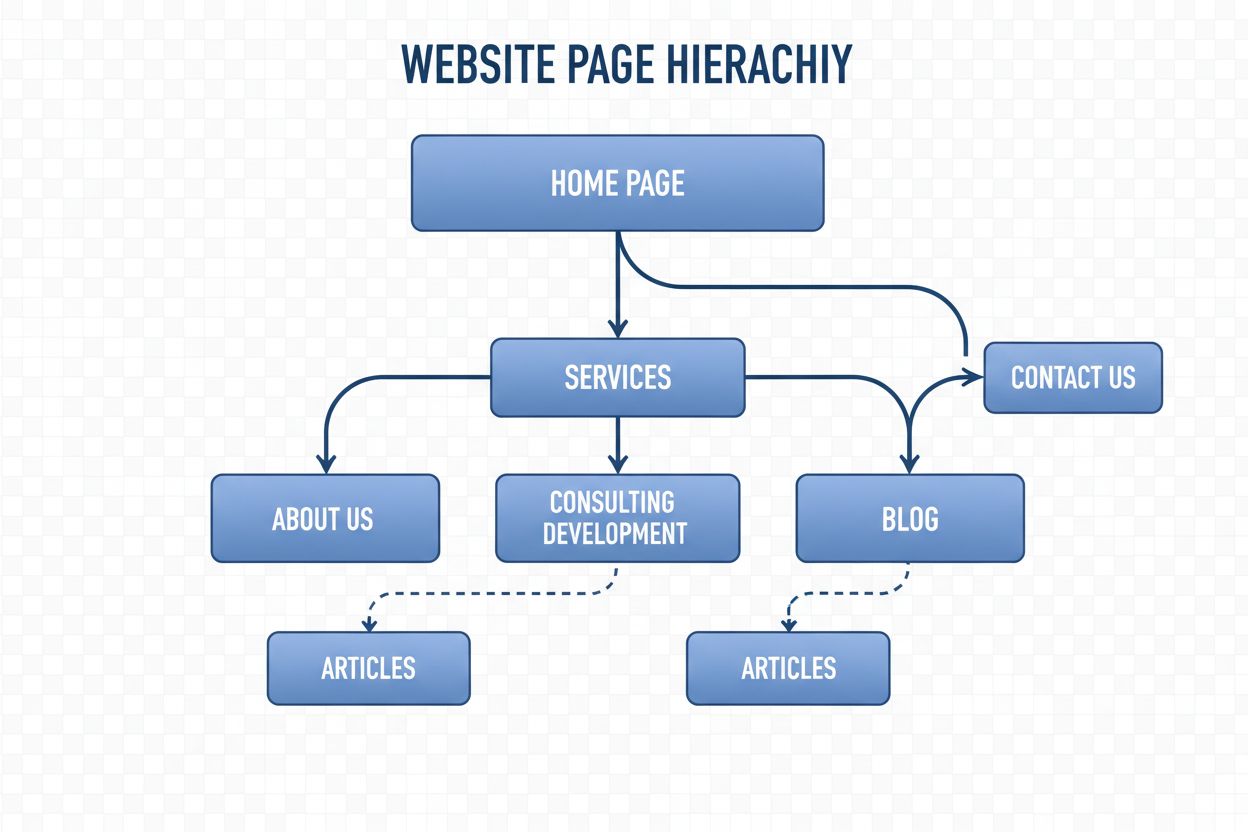
Štruktúra navigácie
Štruktúra navigácie je systém organizujúci stránky a odkazy webu s cieľom viesť používateľov a AI robotov. Zistite, ako ovplyvňuje SEO, používateľský zážitok a ...
8 min čítania
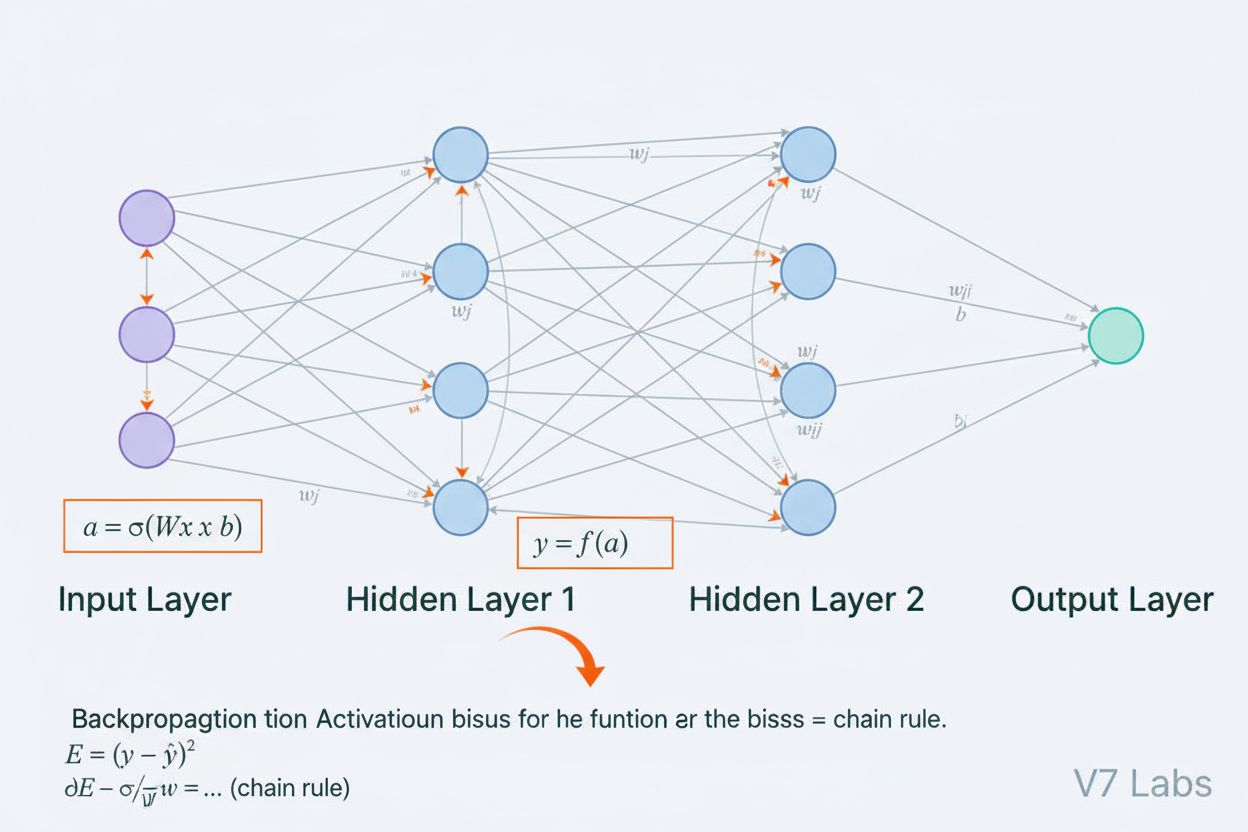
Neuronová sieť je výpočtový systém inšpirovaný biologickými neurónovými sieťami, ktorý pozostáva z navzájom prepojených umelých neurónov usporiadaných vo vrstvách a je schopný učiť sa vzory z dát prostredníctvom procesu zvaného spätná propagácia. Tieto systémy tvoria základ moderného umelého intelektu a hlbokého učenia, poháňajú aplikácie od spracovania prirodzeného jazyka až po počítačové videnie.
Neuronová sieť je výpočtový systém inšpirovaný biologickými neurónovými sieťami, ktorý pozostáva z navzájom prepojených umelých neurónov usporiadaných vo vrstvách a je schopný učiť sa vzory z dát prostredníctvom procesu zvaného spätná propagácia. Tieto systémy tvoria základ moderného umelého intelektu a hlbokého učenia, poháňajú aplikácie od spracovania prirodzeného jazyka až po počítačové videnie.
Neuronová sieť je výpočtový systém, ktorý je zásadne inšpirovaný štruktúrou a funkciou biologických neurónových sietí nachádzajúcich sa v mozgoch živočíchov. Pozostáva z navzájom prepojených umelých neurónov usporiadaných do vrstiev—typicky vstupnej vrstvy, jednej alebo viacerých skrytých vrstiev a výstupnej vrstvy—ktoré spoločne spracúvajú dáta, rozpoznávajú vzory a robia predikcie. Každý neurón prijíma vstupy, aplikuje na ne matematické transformácie prostredníctvom váh a biasov a výsledok prechádza aktivačnou funkciou, ktorá generuje výstup. Definujúcou vlastnosťou neuronových sietí je ich schopnosť učiť sa z dát prostredníctvom iteratívneho procesu zvaného spätná propagácia, pri ktorom sieť upravuje svoje vnútorné parametre s cieľom minimalizovať chyby predikcie. Táto schopnosť učenia, kombinovaná s kapacitou modelovať zložité nelineárne vzťahy, spôsobila, že neuronové siete sú základnou technológiou, ktorá poháňa moderné systémy umelej inteligencie, od veľkých jazykových modelov až po aplikácie počítačového videnia.
Koncept umelých neuronových sietí vznikol z raných pokusov matematicky modelovať, ako biologické neuróny komunikujú a spracúvajú informácie. V roku 1943 navrhli Warren McCulloch a Walter Pitts prvý matematický model neurónu, ktorý ukázal, že jednoduché výpočtové jednotky môžu vykonávať logické operácie. Na tento teoretický základ nadviazal Frank Rosenblatt v roku 1958 predstavením perceptronu, algoritmu určeného na rozpoznávanie vzorov, ktorý sa stal historickým predchodcom dnešných sofistikovaných architektúr neuronových sietí. Perceptron bol v podstate lineárny model s obmedzeným výstupom, schopný naučiť sa jednoduché rozhodovacie hranice. V 70. rokoch však došlo v tomto odbore k výrazným neúspechom, keď vedci zistili, že jednovrstvové perceptrony nedokážu riešiť nelineárne problémy, ako je funkcia XOR, čo viedlo k obdobiu známeho ako „AI zima“. Prielom nastal v 80. rokoch s opätovným objavením a zdokonalením spätnej propagácie, algoritmu, ktorý umožnil trénovanie viacvrstvových sietí. Táto obnova nabrala dramatické tempo v 2010-tych rokoch vďaka dostupnosti obrovských dátových súborov, výkonných GPU a vylepšených trénovacích techník, čo viedlo k revolúcii hlbokého učenia, ktorá transformovala umelú inteligenciu.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Architektúra neuronovej siete pozostáva z viacerých kľúčových komponentov, ktoré pracujú v súčinnosti. Vstupná vrstva prijíma surové vlastnosti dát z externých zdrojov, pričom každý neurón vo vrstve zodpovedá jednej vlastnosti. Skryté vrstvy vykonávajú najnáročnejšie výpočty, transformujú vstupy do čoraz abstraktnejších reprezentácií prostredníctvom vážených kombinácií a nelineárnych aktivačných funkcií. Počet a veľkosť skrytých vrstiev určujú schopnosť siete učiť sa zložité vzory—hlbšie siete môžu zachytiť sofistikovanejšie vzťahy, no vyžadujú viac dát a výpočtového výkonu. Výstupná vrstva generuje konečné predikcie a jej štruktúra závisí od úlohy: jeden neurón pri regresii, viacero neurónov pri viactriednej klasifikácii alebo špecializované architektúry pre iné aplikácie. Každé spojenie medzi neurónmi nesie váhu, ktorá určuje silu vplyvu, zatiaľ čo každý neurón má bias, ktorý posúva jeho aktivačný prah. Tieto váhy a biasy sú učené parametre, ktoré sieť upravuje počas trénovania. Aktivačná funkcia aplikovaná v každom neuróne vnáša zásadnú nelinearitu, vďaka ktorej sa sieť dokáže učiť zložité rozhodovacie hranice a vzory, ktoré by lineárne modely nezachytili.
Neuronové siete sa učia prostredníctvom dvojfázového iteratívneho procesu. Počas prednej propagácie prechádzajú vstupné dáta sieťou od vstupnej vrstvy po výstupnú. V každom neuróne sa vypočíta vážený súčet vstupov plus bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), ktorý sa následne preženie aktivačnou funkciou a vytvorí výstup neurónu. Tento proces sa opakuje v každej skrytej vrstve až po výstupnú vrstvu, kde sieť vyprodukuje svoju predikciu. Sieť potom vypočíta chybu medzi svojou predikciou a skutočnou hodnotou pomocou stratovej funkcie, ktorá kvantifikuje, ako ďaleko je predikcia od správnej odpovede. Pri spätnej propagácii sa táto chyba šíri naspäť sieťou pomocou reťazového pravidla diferenciálneho počtu. V každom neuróne algoritmus vypočíta gradient straty vzhľadom na každú váhu a bias, čím určí, nakoľko každý parameter prispel k celkovej chybe. Tieto gradienty určujú aktualizácie parametrov: váhy a biasy sa upravujú v smere opačnom ku gradientu, pričom veľkosť kroku určuje rýchlosť učenia. Tento proces sa opakuje počas mnohých iterácií nad trénovacím dátovým súborom, pričom sa postupne znižuje strata a zlepšuje presnosť siete. Kombinácia prednej propagácie, výpočtu straty, spätnej propagácie a aktualizácie parametrov tvorí kompletný trénovací cyklus, ktorý umožňuje neuronovým sieťam učiť sa z dát.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
| Typ architektúry | Hlavné využitie | Kľúčová vlastnosť | Silné stránky | Obmedzenia |
|---|---|---|---|---|
| Siete s priamym šírením | Klasifikácia, regresia na štruktúrovaných dátach | Informácie prúdia iba jedným smerom | Jednoduché, rýchly tréning, interpretovateľné | Nedokážu dobre spracovať sekvenčné ani priestorové dáta |
| Konvolučné neuronové siete (CNNs) | Rozpoznávanie obrazov, počítačové videnie | Konvolučné vrstvy detegujú priestorové vlastnosti | Výborné zachytávanie lokálnych vzorov, efektívnosť parametrov | Vyžaduje rozsiahle označené obrazové datasety |
| Rekurentné neuronové siete (RNNs) | Sekvenčné dáta, časové rady, NLP | Skrytý stav udržiava pamäť naprieč krokmi | Dokáže spracovať sekvencie rôznej dĺžky | Trpí problémom miznúcich/prekvitajúcich gradientov |
| Long Short-Term Memory (LSTM) | Dlhodobé závislosti v sekvenciách | Pamäťové bunky s bránami vstupu/zabudnutia/výstupu | Efektívne zvládanie dlhodobých závislostí | Zložitejšie, pomalší tréning než RNN |
| Transformerové siete | Spracovanie prirodzeného jazyka, veľké jazykové modely | Mechanizmus viacnásobnej pozornosti, paralelné spracovanie | Vysoká paralelizácia, zachytenie dlhodobých závislostí | Vyžaduje masívne výpočtové prostriedky |
| Generatívne adversariálne siete (GANs) | Generovanie obrazov, tvorba syntetických dát | Sieť generátora a diskriminátora súťažia | Dokáže generovať realistické syntetické dáta | Ťažký tréning, problém kolapsu módov |
Zavedenie aktivačných funkcií predstavuje jednu z najdôležitejších inovácií v návrhu neuronových sietí. Bez aktivačných funkcií by bola neuronová sieť matematicky ekvivalentná jednej lineárnej transformácii, bez ohľadu na počet vrstiev. Je to preto, že zloženie lineárnych funkcií je opäť lineárne, čo výrazne obmedzuje schopnosť siete učiť sa zložité vzory. Aktivačné funkcie tento problém riešia tým, že do každého neurónu vnášajú nelinearitu. Funkcia ReLU (Rectified Linear Unit), definovaná ako f(x) = max(0, x), sa stala najpopulárnejšou vo svete hlbokého učenia vďaka svojej výpočtovej efektívnosti a účinnosti pri trénovaní hlbokých sietí. Sigmoidálna funkcia, f(x) = 1/(1 + e^(-x)), stláča výstupy do rozsahu medzi 0 a 1, čím je užitočná pre binárnu klasifikáciu. Tanh funkcia, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), generuje výstupy medzi -1 a 1 a často v skrytých vrstvách funguje lepšie než sigmoid. Výber aktivačnej funkcie výrazne ovplyvňuje dynamiku učenia siete, rýchlosť konvergencie aj konečný výkon modelu. Moderné architektúry často používajú ReLU v skrytých vrstvách pre výpočtovú efektívnosť a sigmoid alebo softmax vo výstupných vrstvách na odhad pravdepodobnosti. Nelinearita zavedená aktivačnými funkciami umožňuje neuronovým sieťam aproximovať akúkoľvek spojitú funkciu, čo je vlastnosť známa ako teória univerzálnej aproximácie, ktorá vysvetľuje ich výnimočnú univerzálnosť naprieč rôznymi aplikáciami.
Trh s neuronovými sieťami zaznamenal prudký rast, čo odráža ústrednú úlohu tejto technológie v modernom umelej inteligencii. Podľa najnovších prieskumov bola globálna hodnota trhu so softvérom pre neuronové siete v roku 2025 približne 34,76 miliardy dolárov a predpokladá sa, že do roku 2030 dosiahne 139,86 miliardy dolárov, čo predstavuje zloženú ročnú mieru rastu (CAGR) 32,10%. Širší trh s neuronovými sieťami vykazuje ešte výraznejšiu expanziu, pričom odhady hovoria o raste z 34,05 miliardy dolárov v roku 2024 na 385,29 miliardy dolárov do roku 2033 pri CAGR 31,4%. Tento rýchly rast poháňa viacero faktorov: rastúca dostupnosť veľkých dát, vývoj efektívnejších trénovacích algoritmov, rozmach GPU a špecializovaného AI hardvéru a rozšírené nasadzovanie neuronových sietí v priemysle. Podľa AI Index Reportu Stanfordu z roku 2025 78 % organizácií používalo AI v roku 2024, čo je nárast z 55 % v predchádzajúcom roku, pričom neuronové siete tvoria základ väčšiny podnikových AI implementácií. Adopcia siaha od zdravotníctva, financií, výroby, maloobchodu až po prakticky každý ďalší sektor, keďže organizácie si uvedomujú konkurenčnú výhodu, ktorú poskytujú systémy na báze neuronových sietí pre rozpoznávanie vzorov, predikciu a rozhodovanie.
Neuronové siete poháňajú najpokročilejšie AI systémy súčasnosti, vrátane ChatGPT, Perplexity, Google AI Overviews a Claude. Tieto veľké jazykové modely sú postavené na transformerových architektúrach neuronových sietí, ktoré používajú mechanizmy pozornosti na spracovanie a generovanie ľudského jazyka s pozoruhodnou sofistikovanosťou. Transformerová architektúra, predstavená v roku 2017, spôsobila revolúciu v spracovaní prirodzeného jazyka tým, že umožnila paralelné spracovanie celých sekvencií namiesto sekvenčného spracovania, čím dramaticky zvýšila efektívnosť tréningu aj výkon modelu. V kontexte sledovania značky a monitorovania citácií AI je pochopenie neuronových sietí kľúčové, pretože tieto systémy používajú neuronové siete na pochopenie kontextu, vyhľadávanie relevantných informácií a generovanie odpovedí, ktoré môžu odkazovať alebo citovať vašu značku, doménu či obsah. AmICited využíva znalosti o tom, ako neuronové siete spracúvajú a vyhľadávajú informácie, na monitorovanie výskytu vašej značky v AI-generovaných odpovediach na viacerých platformách. Ako sa neuronové siete stále zlepšujú v chápaní sémantiky a vyhľadávaní relevantných informácií, význam monitorovania prítomnosti vašej značky v AI odpovediach bude čoraz kľúčovejší pre udržanie viditeľnosti a správu online reputácie v ére AI-vyhľadávania a generovania obsahu.
Efektívne trénovanie neuronových sietí predstavuje viacero významných výziev, ktorým musia výskumníci a praktici čeliť. Preučenie (overfitting) nastáva, keď sa sieť naučí trénovacie dáta až príliš dobre, vrátane ich šumu a špecifík, čo vedie k slabej výkonnosti na nových, nevidených dátach. Tento problém je obzvlášť výrazný pri hlbokých sieťach s veľkým počtom parametrov vzhľadom na veľkosť trénovacích dát. Nedoučenie (underfitting) predstavuje opačný problém, kedy sieť nemá dostatočnú kapacitu alebo trénovanie na zachytenie podstatných vzorov v dátach. Problém miznúcich gradientov sa vyskytuje vo veľmi hlbokých sieťach, kde gradienty pri spätnom šírení exponenciálne klesajú, čo spôsobuje, že váhy v skorých vrstvách sa aktualizujú veľmi pomaly alebo vôbec. Problém explodujúcich gradientov je opačný, keď gradienty exponenciálne rastú, čo spôsobuje nestabilitu tréningu. Moderné riešenia zahŕňajú batch normalization, ktorá normalizuje vstupy vrstiev pre udržanie stabilného gradientového toku; reziduálne spojenia (skip connections), ktoré umožňujú gradientom prúdiť priamo cez vrstvy; a klipovanie gradientov, ktoré obmedzuje veľkosť gradientov. Regularizačné techniky ako L1 a L2 regularizácia pridávajú penalizácie za veľké váhy a podporujú jednoduchšie modely s lepšou generalizáciou. Dropout náhodne vypína neuróny počas tréningu, čím zabraňuje ich spoluzávislosti a zlepšuje generalizáciu. Výber optimalizátora (napr. Adam, SGD, RMSprop) a rýchlosť učenia výrazne ovplyvňujú efektivitu tréningu a konečný výkon modelu. Praktici musia starostlivo vyvažovať komplexnosť modelu, veľkosť dát, silu regularizácie a optimalizačné parametre, aby dosiahli siete, ktoré sa efektívne učia bez preučenia.
Vývoj architektúr neuronových sietí sleduje jasnú trajektóriu smerom k stále sofistikovanejším mechanizmom spracovania informácií. Skoré siete s priamym šírením boli obmedzené na vstupy pevnej veľkosti a nedokázali zachytiť časové ani sekvenčné závislosti. Rekurentné neuronové siete (RNNs) zaviedli spätné slučky, ktoré umožnili informáciám pretrvávať naprieč časovými krokmi a spracúvať sekvencie rôznej dĺžky. RNN však trpeli problémami s gradientmi a boli inherentne sekvenčné, čo bránilo ich paralelizácii na modernom hardvéri. LSTM siete riešili niektoré z týchto problémov pamäťovými bunkami a bránami, no zostávali v podstate sekvenčné. Prielom prišiel s transformerovými sieťami, ktoré úplne nahradili rekurenciu mechanizmami pozornosti. Mechanizmus pozornosti umožňuje sieti dynamicky sa zamerať na rôzne časti vstupu a počítať vážené kombinácie všetkých vstupných prvkov paralelne. To umožňuje transformerom efektívne zachytávať dlhodobé závislosti a zároveň ich plne paralelizovať na GPU klastri. Transformerová architektúra v kombinácii s masívnym rozsahom (moderné veľké jazykové modely obsahujú miliardy až bilióny parametrov) sa ukázala ako mimoriadne účinná pre spracovanie prirodzeného jazyka, počítačové videnie a multimodálne úlohy. Úspech transformerov viedol k ich prijatiu ako štandardu pre najmodernejšie AI systémy vrátane všetkých hlavných veľkých jazykových modelov. Tento vývoj ukazuje, ako architektonické inovácie, v kombinácii s narastajúcimi výpočtovými zdrojmi a väčšími dátovými súbormi, naďalej posúvajú hranice možností neuronových sietí.
Oblasť neuronových sietí sa neustále rýchlo vyvíja a objavujú sa viaceré sľubné smery. Neuromorfné výpočty sa snažia vytvárať hardvér, ktorý ešte viac napodobňuje biologické neuronové siete, čím by sa dosiahla vyššia energetická efektivita a výpočtový výkon. Výskum v oblasti učenia z mála príkladov (few-shot/zero-shot learning) sa zameriava na to, aby sa neuronové siete dokázali naučiť nové úlohy z minima príkladov, čím by sa priblížili ľudskému učeniu. Vysvetliteľnosť a interpretovateľnosť sú čoraz dôležitejšie, pričom vedci vyvíjajú techniky na pochopenie a vizualizáciu toho, čo sa siete učia, čo je kľúčové pre aplikácie v zdravotníctve, financiách či justícii. Federované učenie umožňuje trénovanie neuronových sietí na distribuovaných dátach bez potreby centrálneho ukladania citlivých informácií, čím sa riešia otázky ochrany súkromia. Kvantové neuronové siete sú na hranici výskumu, kde sa princípy kvantového počítania spájajú s architektúrami neuronových sietí, čo by mohlo priniesť exponenciálne zrýchlenie riešenia niektorých problémov. Multimodálne neuronové siete, ktoré integrujú text, obraz, zvuk a video, sú čoraz sofistikovanejšie a umožňujú komplexnejšie AI systémy. Vyvíjajú sa aj energeticky efektívne neuronové siete na zníženie výpočtovej a environmentálnej záťaže trénovania a nasadzovania veľkých modelov. Ako sa neuronové siete posúvajú vpred, ich integrácia do AI monitorovacích nástrojov ako AmICited je čoraz dôležitejšia pre organizácie, ktoré chcú pochopiť a riadiť prítomnosť svojej značky v AI-generovanom obsahu a odpovediach na platformách ako ChatGPT, Perplexity, Google AI Overviews a Claude.
Začnite sledovať, ako AI chatboty spomínajú vašu značku na ChatGPT, Perplexity a ďalších platformách. Získajte použiteľné poznatky na zlepšenie vašej prítomnosti v AI.
Štruktúra navigácie je systém organizujúci stránky a odkazy webu s cieľom viesť používateľov a AI robotov. Zistite, ako ovplyvňuje SEO, používateľský zážitok a ...
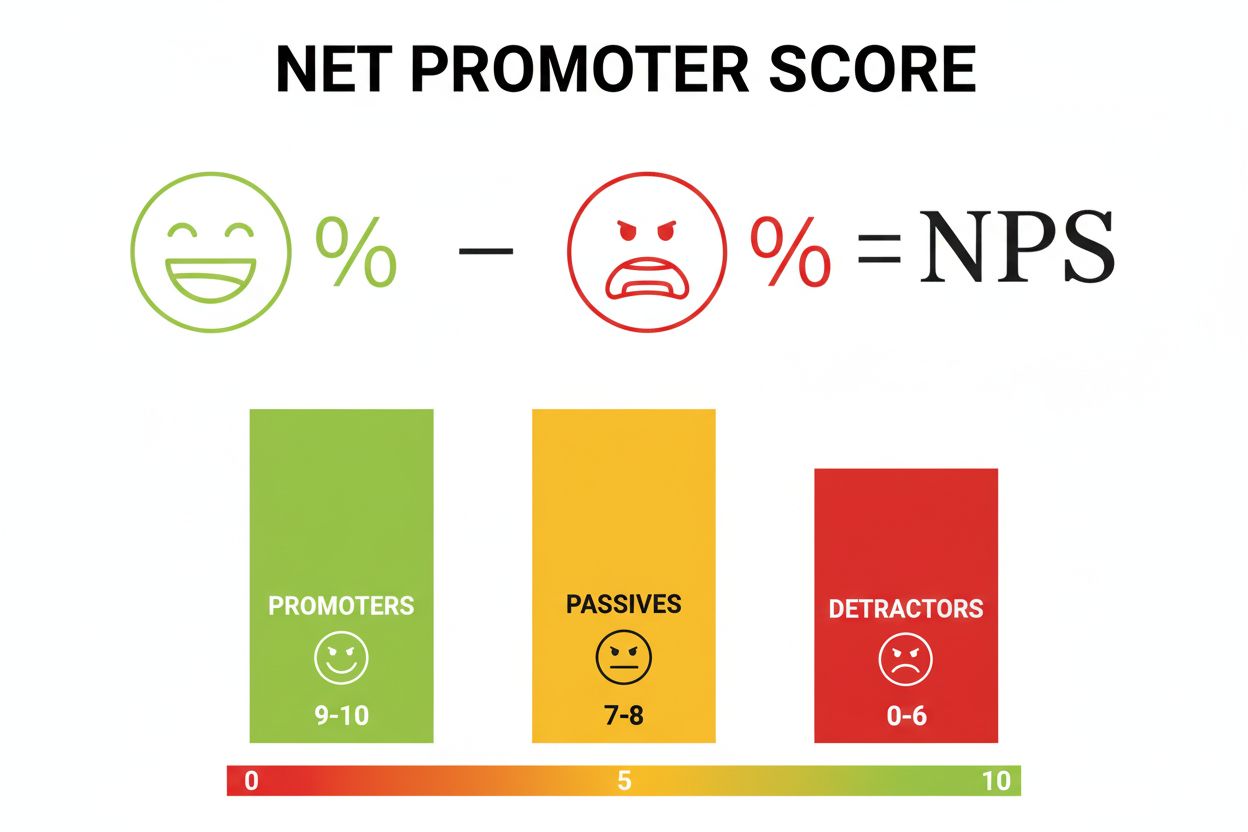
Net Promoter Score (NPS) je metrika lojality zákazníkov merajúca pravdepodobnosť odporúčania. Naučte sa, ako vypočítať NPS, interpretovať skóre a porovnávať sa ...

Parametre modelu sú naučiteľné premenné v AI modeloch, ktoré určujú správanie. Pochopte váhy, biasy a ako parametre ovplyvňujú výkon a trénovanie AI modelu....
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.