Un flujo de trabajo de Generación Aumentada por Recuperación (RAG) es un proceso que permite a los sistemas de IA encontrar, clasificar y citar fuentes externas al generar respuestas. Combina la recuperación de documentos, la clasificación semántica y la generación con LLM para proporcionar respuestas precisas y contextualmente relevantes, fundamentadas en datos reales. Los sistemas RAG reducen las alucinaciones consultando bases de conocimiento externas antes de producir respuestas, lo que los hace esenciales para aplicaciones que requieren precisión factual y atribución de fuentes.
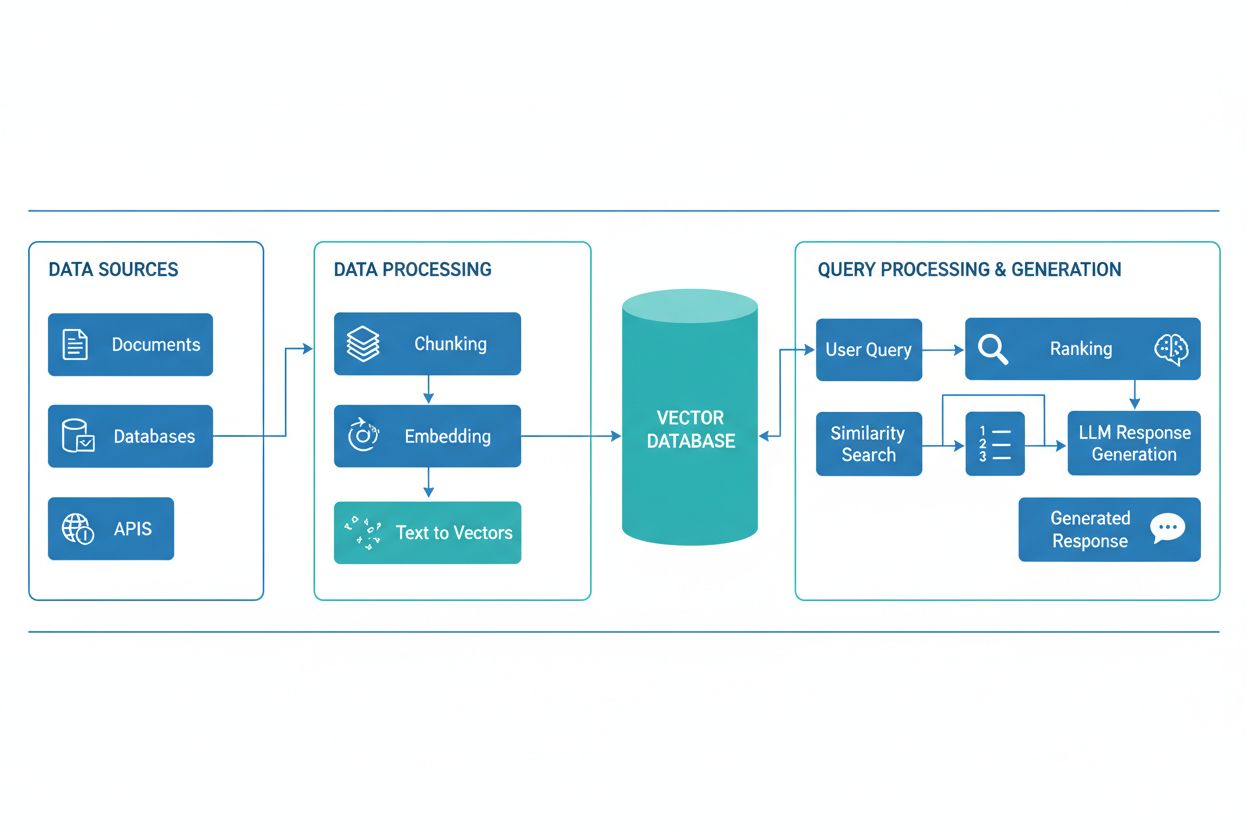
Flujo de trabajo RAG Pipeline
Un flujo de trabajo de Generación Aumentada por Recuperación (RAG) es un proceso que permite a los sistemas de IA encontrar, clasificar y citar fuentes externas al generar respuestas. Combina la recuperación de documentos, la clasificación semántica y la generación con LLM para proporcionar respuestas precisas y contextualmente relevantes, fundamentadas en datos reales. Los sistemas RAG reducen las alucinaciones consultando bases de conocimiento externas antes de producir respuestas, lo que los hace esenciales para aplicaciones que requieren precisión factual y atribución de fuentes.
¿Qué es un RAG Pipeline?
Un flujo de trabajo de Generación Aumentada por Recuperación (RAG) es una arquitectura de IA que combina la recuperación de información con la generación mediante grandes modelos de lenguaje (LLM) para producir respuestas más precisas, relevantes contextualmente y verificables. En lugar de depender únicamente de los datos de entrenamiento de un LLM, los sistemas RAG buscan dinámicamente documentos o datos relevantes en bases de conocimiento externas antes de generar respuestas, reduciendo significativamente las alucinaciones y mejorando la precisión factual. El pipeline actúa como un puente entre los datos de entrenamiento estáticos y la información en tiempo real, permitiendo que los sistemas de IA hagan referencia a contenido actual, específico de dominio o propietario. Este enfoque se ha vuelto esencial para organizaciones que requieren respuestas con citas, cumplimiento de estándares de precisión y transparencia en el contenido generado por IA. Los pipelines RAG son especialmente valiosos en el monitoreo de sistemas de IA donde la trazabilidad y la atribución de fuentes son requisitos críticos.
Componentes principales
Un pipeline RAG consta de varios componentes interconectados que trabajan juntos para recuperar información relevante y generar respuestas fundamentadas. La arquitectura típicamente incluye una capa de ingestión de documentos que procesa y prepara datos en bruto, una base de datos vectorial o base de conocimiento que almacena embeddings y contenido indexado, un mecanismo de recuperación que identifica documentos relevantes según las consultas del usuario, un sistema de clasificación que prioriza los resultados más pertinentes y un módulo de generación impulsado por un LLM que sintetiza la información recuperada en respuestas coherentes. Los componentes adicionales incluyen módulos de procesamiento y preprocesamiento de consultas que normalizan la entrada del usuario, modelos de embeddings que convierten texto en representaciones numéricas y un bucle de retroalimentación que mejora continuamente la precisión de la recuperación. La orquestación de estos componentes determina la efectividad y eficiencia global del sistema RAG.
Componente
Función
Tecnologías clave
Ingesta de documentos
Procesamiento y preparación de datos en bruto
Apache Kafka, LangChain, Unstructured
Base de datos vectorial
Almacenamiento de embeddings y contenido indexado
Pinecone, Weaviate, Milvus, Qdrant
Motor de recuperación
Identificación de documentos relevantes
BM25, Dense Passage Retrieval (DPR)
Sistema de clasificación
Priorización de resultados de búsqueda
Cross-encoders, reranking basado en LLM
Módulo de generación
Síntesis de respuestas a partir del contexto
GPT-4, Claude, Llama, Mistral
Procesador de consultas
Normalización y comprensión de la entrada del usuario
BERT, T5, pipelines NLP personalizados
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
El pipeline RAG opera a través de dos fases distintas: la fase de recuperación y la fase de generación. Durante la fase de recuperación, el sistema convierte la consulta del usuario en un embedding utilizando el mismo modelo de embeddings que procesó los documentos de la base de conocimiento y luego busca en la base de datos vectorial para identificar los documentos o pasajes más semánticamente similares. Esta fase típicamente devuelve una lista clasificada de documentos candidatos, que puede ser refinada aún más mediante algoritmos de reordenamiento que utilizan cross-encoders o puntuaciones basadas en LLM para asegurar la relevancia. En la fase de generación, los documentos recuperados mejor clasificados se formatean en una ventana de contexto y se pasan al LLM junto con la consulta original, permitiendo que el modelo genere respuestas fundamentadas en material fuente real. Este enfoque en dos fases asegura que las respuestas sean apropiadas contextualmente y trazables a fuentes específicas, lo que lo hace ideal para aplicaciones que requieren citas y responsabilidad. La calidad del resultado final depende críticamente tanto de la relevancia de los documentos recuperados como de la capacidad del LLM para sintetizar la información de manera coherente.
Tecnologías y herramientas clave
El ecosistema RAG abarca una amplia gama de herramientas y marcos especializados diseñados para simplificar la construcción y el despliegue de pipelines. Las implementaciones modernas de RAG aprovechan varias categorías de tecnología:
Marcos de orquestación: LangChain, LlamaIndex (antes GPT Index) y Haystack proporcionan capas de abstracción para construir flujos de trabajo RAG sin gestionar componentes individuales
Bases de datos vectoriales: Pinecone, Weaviate, Milvus, Qdrant y Chroma ofrecen almacenamiento y recuperación escalables de embeddings de alta dimensión con latencias de consulta en sub-milisegundos
Modelos de embeddings: text-embedding-3 de OpenAI, Embed API de Cohere y modelos open-source como all-MiniLM-L6-v2 convierten texto en representaciones semánticas
Proveedores de LLM: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) y Mistral ofrecen diversos tamaños de modelo y capacidades para tareas de generación
Soluciones de reordenamiento: Rerank API de Cohere, modelos cross-encoder de Hugging Face y rerankers propietarios basados en LLM mejoran la precisión de la recuperación
Herramientas de preparación de datos: Unstructured, Apache Kafka y pipelines ETL personalizados manejan la ingestión de documentos, fragmentación y preprocesamiento
Monitoreo y evaluación: Herramientas como Ragas, TruLens y marcos de evaluación personalizados evalúan el rendimiento del sistema RAG e identifican modos de fallo
Estas herramientas se pueden combinar de manera modular, permitiendo a las organizaciones construir sistemas RAG adaptados a sus requisitos y limitaciones de infraestructura específicos.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Mecanismos de recuperación
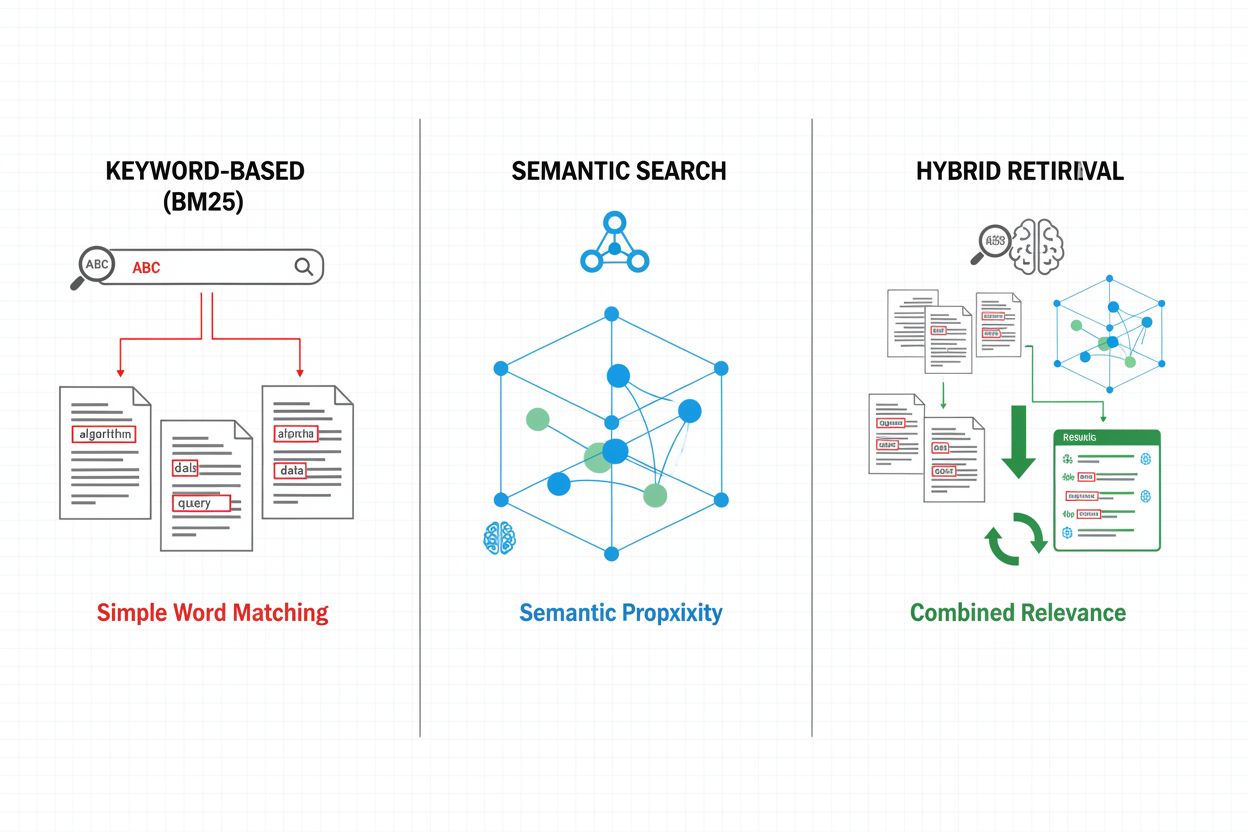
Los mecanismos de recuperación forman la base de la efectividad del pipeline RAG, evolucionando desde enfoques simples basados en palabras clave hasta métodos sofisticados de búsqueda semántica. La recuperación tradicional basada en palabras clave mediante algoritmos BM25 sigue siendo eficiente computacionalmente y eficaz para escenarios de coincidencia exacta, pero tiene dificultades con la comprensión semántica y la sinonimia. Dense Passage Retrieval (DPR) y otros métodos de recuperación neuronal abordan estas limitaciones codificando tanto las consultas como los documentos en embeddings vectoriales densos, permitiendo la coincidencia de similitud semántica que captura significado más allá de palabras clave superficiales. Los enfoques de recuperación híbrida combinan búsqueda basada en palabras clave y búsqueda semántica, aprovechando las fortalezas de ambos métodos para mejorar la recuperación y precisión en diversos tipos de consultas. Mecanismos de recuperación avanzados incorporan expansión de consulta, donde la consulta original se amplía con términos relacionados o reformulaciones para captar más documentos relevantes. Las capas de reordenamiento refinan aún más los resultados aplicando modelos más costosos computacionalmente que puntúan los documentos candidatos según comprensión semántica profunda o criterios de relevancia específicos de la tarea. La elección del mecanismo de recuperación impacta significativamente tanto en la precisión del contexto recuperado como en el costo computacional del pipeline RAG, requiriendo una consideración cuidadosa de los compromisos entre velocidad y calidad.
Beneficios de los pipelines RAG
Los pipelines RAG ofrecen ventajas sustanciales sobre los enfoques tradicionales solo con LLM, especialmente para aplicaciones que requieren precisión, actualidad y trazabilidad. Al fundamentar las respuestas en documentos recuperados, los sistemas RAG reducen drásticamente las alucinaciones—instancias donde los LLM generan información plausible pero incorrecta—lo que los hace adecuados para dominios de alto riesgo como salud, legal y servicios financieros. La capacidad de referenciar bases de conocimiento externas permite a los sistemas RAG proporcionar información actual sin reentrenar modelos, permitiendo a las organizaciones mantener respuestas al día a medida que hay nueva información. Los pipelines RAG admiten personalización específica de dominio al incorporar documentos propietarios, bases de conocimiento internas y terminología especializada, permitiendo respuestas más relevantes y apropiadas contextualmente. El componente de recuperación aporta transparencia y auditabilidad al mostrar explícitamente qué fuentes informaron cada respuesta, lo cual es crítico para requisitos de cumplimiento y confianza del usuario. La eficiencia de costos mejora mediante el uso de LLM más pequeños y eficientes que pueden generar respuestas de alta calidad cuando se les proporciona contexto relevante, reduciendo la carga computacional en comparación con modelos más grandes. Estos beneficios hacen que RAG sea especialmente valioso para organizaciones que implementan sistemas de monitoreo de IA donde la precisión de las citas y la visibilidad del contenido son primordiales.
Desafíos y limitaciones
A pesar de sus ventajas, los pipelines RAG enfrentan varios desafíos técnicos y operativos que requieren una gestión cuidadosa. La calidad de los documentos recuperados determina directamente la calidad de las respuestas, haciendo que los errores de recuperación sean difíciles de corregir—un fenómeno conocido como “basura entra, basura sale”, donde documentos irrelevantes o desactualizados en la base de conocimiento se propagan a las respuestas finales. Los modelos de embeddings pueden tener dificultades con terminología específica de dominio, lenguas raras o contenido altamente técnico, lo que lleva a coincidencias semánticas pobres y documentos relevantes omitidos. El costo computacional de la recuperación, la generación de embeddings y el reordenamiento puede ser considerable a gran escala, especialmente al procesar grandes bases de conocimiento o manejar volúmenes altos de consultas. Las limitaciones de ventana de contexto en los LLM restringen la cantidad de información recuperada que se puede incorporar en los prompts, requiriendo una selección y resumen cuidadosos de pasajes relevantes. Mantener la frescura y consistencia de la base de conocimiento presenta desafíos operativos, especialmente en entornos dinámicos donde la información cambia frecuentemente o proviene de múltiples fuentes. Evaluar el rendimiento del sistema RAG requiere métricas integrales más allá de medidas tradicionales de precisión, incluyendo precisión de recuperación, relevancia de la respuesta y corrección de citas, que pueden ser difíciles de evaluar automáticamente.
RAG frente a otros enfoques
RAG representa un enfoque entre varias estrategias para mejorar la precisión y relevancia de los LLM, cada una con diferentes compromisos. El fine-tuning implica reentrenar los LLM con datos específicos de dominio, proporcionando una personalización profunda del modelo pero requiriendo recursos computacionales sustanciales, datos de entrenamiento etiquetados y mantenimiento continuo a medida que la información cambia. La ingeniería de prompts optimiza las instrucciones y el contexto proporcionado a los LLM sin modificar los pesos del modelo, ofreciendo flexibilidad y bajo costo pero limitada por los datos de entrenamiento del modelo y el tamaño de la ventana de contexto. El aprendizaje en contexto utiliza ejemplos few-shot dentro de los prompts para guiar el comportamiento del modelo, proporcionando adaptación rápida pero consumiendo valiosos tokens de contexto y requiriendo una selección cuidadosa de ejemplos. Comparado con estos enfoques, RAG ofrece un punto intermedio: proporciona acceso dinámico a información actual sin reentrenamiento, mantiene transparencia mediante la atribución explícita de fuentes y escala eficientemente a través de diversos dominios de conocimiento. Sin embargo, RAG introduce complejidad adicional a través de la infraestructura de recuperación y posibles errores de recuperación, mientras que el fine-tuning proporciona una integración más estrecha del conocimiento de dominio en el comportamiento del modelo. El enfoque óptimo a menudo implica combinar múltiples estrategias—por ejemplo, usar RAG con modelos fine-tuned y prompts cuidadosamente diseñados—para maximizar precisión y relevancia en casos de uso específicos.
Construcción y despliegue de RAG
Implementar un pipeline RAG de producción requiere una planificación sistemática en la preparación de datos, diseño de arquitectura y consideraciones operativas. El proceso comienza con la preparación de la base de conocimiento: recopilación de documentos relevantes, limpieza y estandarización de formatos y segmentación del contenido en fragmentos de tamaño apropiado que equilibren la preservación del contexto con la precisión de recuperación. A continuación, las organizaciones seleccionan modelos de embeddings y bases de datos vectoriales según los requisitos de rendimiento, restricciones de latencia y necesidades de escalabilidad, considerando factores como dimensionalidad de embeddings, rendimiento de consultas y capacidad de almacenamiento. Luego se configura el sistema de recuperación, incluyendo decisiones sobre algoritmos de recuperación (por palabras clave, semánticos o híbridos), estrategias de reordenamiento y criterios de filtrado de resultados. La integración con proveedores de LLM sigue, estableciendo conexiones con modelos de generación y definiendo plantillas de prompts que incorporen el contexto recuperado de manera efectiva. Las pruebas y evaluación son críticas, requiriendo métricas para la calidad de recuperación (precisión, recall, MRR), calidad de generación (relevancia, coherencia, factualidad) y el rendimiento de extremo a extremo del sistema. Las consideraciones de despliegue incluyen configurar el monitoreo para la precisión de recuperación y calidad de generación, implementar bucles de retroalimentación para identificar y abordar modos de fallo y establecer procesos para actualizaciones y mantenimiento de la base de conocimiento. Finalmente, la optimización continua implica analizar las interacciones de los usuarios, identificar patrones comunes de fallo y mejorar iterativamente los mecanismos de recuperación, estrategias de reordenamiento y la ingeniería de prompts para aumentar el rendimiento global del sistema.
RAG en monitoreo de IA y citación
Los pipelines RAG son fundamentales para plataformas modernas de monitoreo de IA como AmICited.com, donde rastrear las fuentes y la precisión del contenido generado por IA es esencial. Al recuperar y citar explícitamente documentos fuente, los sistemas RAG crean una huella auditable que permite a las plataformas de monitoreo verificar afirmaciones, evaluar precisión factual e identificar posibles alucinaciones o atribuciones erróneas. Esta capacidad de citación aborda una brecha crítica en la transparencia de la IA: los usuarios y auditores pueden rastrear las respuestas hasta las fuentes originales, permitiendo la verificación independiente y fomentando la confianza en el contenido generado por IA. Para creadores de contenido y organizaciones que usan herramientas de IA, el monitoreo habilitado por RAG proporciona visibilidad sobre qué fuentes informaron respuestas específicas, apoyando el cumplimiento de requisitos de atribución y políticas de gobernanza de contenido. El componente de recuperación de los pipelines RAG genera metadatos ricos—including puntuaciones de relevancia, clasificaciones de documentos y métricas de confianza en la recuperación—que los sistemas de monitoreo pueden analizar para evaluar la fiabilidad de las respuestas e identificar cuándo los sistemas de IA operan fuera de sus dominios de conocimiento. La integración de RAG con plataformas de monitoreo permite la detección de deriva de citas, donde los sistemas de IA se alejan gradualmente de fuentes autorizadas hacia otras menos confiables, y respalda la aplicación de políticas de contenido en torno a la calidad y diversidad de las fuentes. A medida que los sistemas de IA se integran cada vez más en flujos de trabajo críticos, la combinación de pipelines RAG con monitoreo integral crea mecanismos de responsabilidad que protegen a usuarios, organizaciones y al ecosistema informativo más amplio frente a la desinformación generada por IA.
Preguntas frecuentes
¿Cuál es la diferencia entre RAG y el fine-tuning?
RAG y el fine-tuning son enfoques complementarios para mejorar el rendimiento de los LLM. RAG recupera documentos externos en tiempo real sin modificar el modelo, permitiendo acceso a datos actualizados y actualizaciones sencillas. El fine-tuning reentrena el modelo con datos específicos de dominio, proporcionando personalización profunda pero requiriendo recursos computacionales significativos y actualizaciones manuales cuando la información cambia. Muchas organizaciones usan ambas técnicas juntas para obtener resultados óptimos.
¿Cómo reduce RAG las alucinaciones en respuestas de IA?
RAG reduce las alucinaciones fundamentando las respuestas de los LLM en documentos factuales recuperados. En lugar de depender solo de los datos de entrenamiento, el sistema recupera fuentes relevantes antes de la generación, proporcionando al modelo evidencia concreta para citar. Este enfoque asegura que las respuestas se basen en información real en lugar de patrones aprendidos por el modelo, mejorando significativamente la precisión factual y reduciendo afirmaciones falsas o engañosas.
¿Qué son los embeddings vectoriales y por qué son importantes en RAG?
Los embeddings vectoriales son representaciones numéricas de texto que capturan el significado semántico en un espacio multidimensional. Permiten a los sistemas RAG realizar búsquedas semánticas, encontrando documentos con significado similar incluso si usan palabras diferentes. Los embeddings son cruciales porque permiten que RAG vaya más allá de la coincidencia de palabras clave para comprender relaciones conceptuales, mejorando la relevancia de la recuperación y permitiendo una generación de respuestas más precisa.
¿Pueden los pipelines RAG funcionar con datos en tiempo real?
Sí, los pipelines RAG pueden incorporar datos en tiempo real mediante procesos continuos de ingestión e indexación. Las organizaciones pueden configurar pipelines automatizados que actualizan regularmente la base de datos vectorial con nuevos documentos, asegurando que la base de conocimiento se mantenga actualizada. Esta capacidad hace que RAG sea ideal para aplicaciones que requieren información al día, como análisis de noticias, inteligencia de precios y monitoreo de mercado, sin necesidad de reentrenar el LLM subyacente.
¿Cuál es la diferencia entre búsqueda semántica y RAG?
La búsqueda semántica es una técnica de recuperación que encuentra documentos en función de la similitud de significado utilizando embeddings vectoriales. RAG es un pipeline completo que combina la búsqueda semántica con la generación de LLM para producir respuestas fundamentadas en los documentos recuperados. Mientras que la búsqueda semántica se centra en encontrar información relevante, RAG añade el componente de generación que sintetiza el contenido recuperado en respuestas coherentes con citas.
¿Cómo deciden los sistemas RAG qué fuentes citar?
Los sistemas RAG utilizan múltiples mecanismos para seleccionar las fuentes a citar. Emplean algoritmos de recuperación para encontrar documentos relevantes, modelos de reordenamiento para priorizar los resultados más pertinentes y procesos de verificación para asegurar que las citas respalden realmente las afirmaciones realizadas. Algunos sistemas utilizan enfoques de 'citar mientras escriben', donde solo se hacen afirmaciones si están respaldadas por fuentes recuperadas, mientras que otros verifican las citas después de la generación y eliminan afirmaciones no respaldadas.
¿Cuáles son los principales desafíos al construir pipelines RAG?
Los principales desafíos incluyen mantener la frescura y calidad de la base de conocimiento, optimizar la precisión de recuperación en distintos tipos de contenido, gestionar los costos computacionales a escala, manejar terminología específica de dominio que los modelos de embeddings pueden no comprender bien y evaluar el rendimiento del sistema con métricas integrales. Las organizaciones también deben abordar las limitaciones de ventana de contexto en los LLM y asegurar que los documentos recuperados sigan siendo relevantes a medida que la información evoluciona.
¿Cómo monitorea AmICited las citas RAG en sistemas de IA?
AmICited rastrea cómo sistemas de IA como ChatGPT, Perplexity y Google AI Overviews recuperan y citan contenido a través de pipelines RAG. La plataforma monitorea qué fuentes se seleccionan para citas, con qué frecuencia aparece tu marca en las respuestas de IA y si las citas son precisas. Esta visibilidad ayuda a las organizaciones a entender su presencia en la búsqueda mediada por IA y asegurar la atribución adecuada de su contenido.
Monitorea tu marca en respuestas de IA
Rastrea cómo sistemas de IA como ChatGPT, Perplexity y Google AI Overviews hacen referencia a tu contenido. Obtén visibilidad sobre citas RAG y monitoreo de respuestas de IA.
¿Qué es RAG en la Búsqueda de IA?: Guía Completa sobre Generación Aumentada por Recuperación
Descubre qué es RAG (Generación Aumentada por Recuperación) en la búsqueda de IA. Aprende cómo RAG mejora la precisión, reduce las alucinaciones y alimenta a Ch...
Cómo Funciona la Generación Aumentada por Recuperación: Arquitectura y Proceso
Descubre cómo RAG combina LLMs con fuentes de datos externas para generar respuestas de IA precisas. Comprende el proceso de cinco etapas, los componentes y por...
Descubre qué es la Generación Aumentada por Recuperación (RAG), cómo funciona y por qué es esencial para respuestas precisas de IA. Explora la arquitectura, ben...
14 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.