
Information Density: Creating Value-Packed Content for AI
Learn how to create information-dense content that AI systems prefer. Master the Uniform Information Density hypothesis and optimize your content for AI Overvie...
9 min read
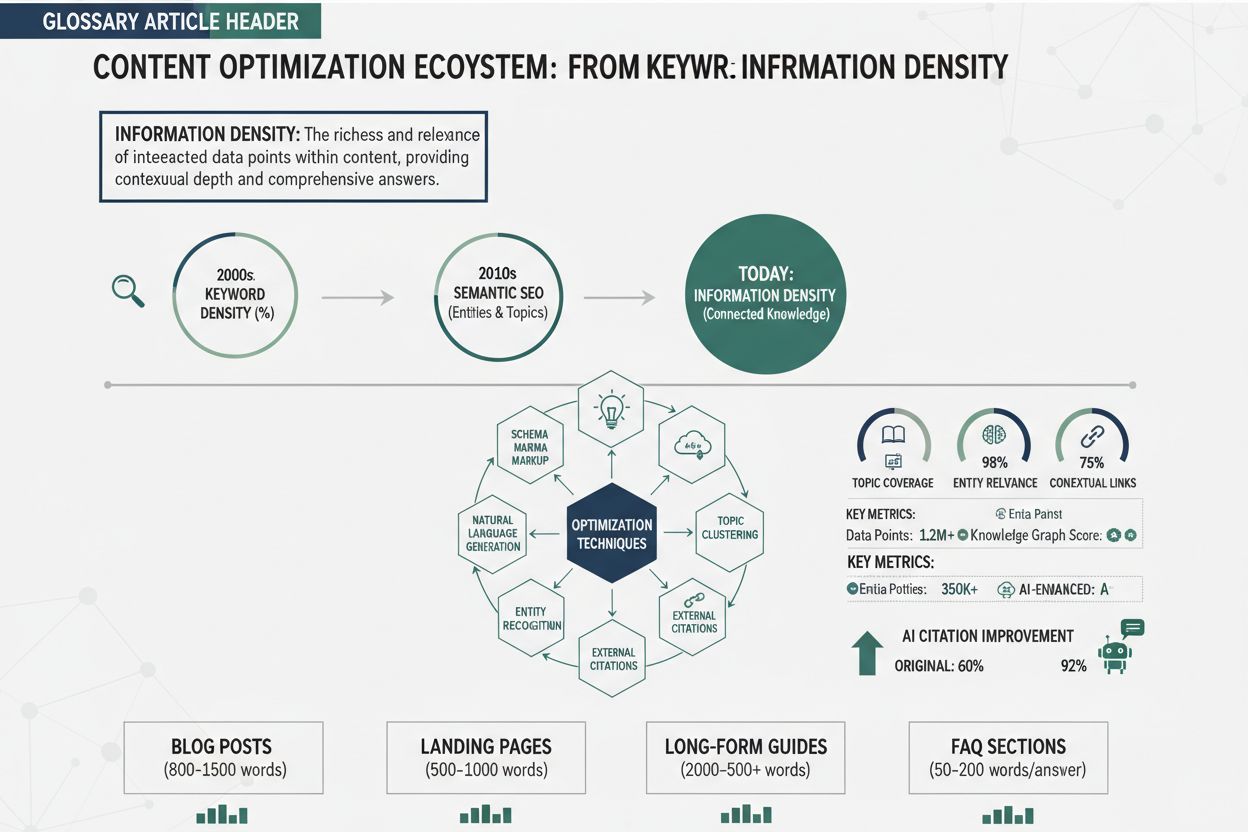
Information density is the ratio of useful, unique information to total content length. Higher density improves AI citation likelihood because AI systems prioritize content that delivers maximum insight within minimal word count. It represents a shift from keyword-focused optimization to information-focused optimization, where every sentence must contribute distinct value. This metric directly influences whether AI systems retrieve, evaluate, and cite your content as authoritative sources.
Information density is the ratio of useful, unique information to total content length. Higher density improves AI citation likelihood because AI systems prioritize content that delivers maximum insight within minimal word count. It represents a shift from keyword-focused optimization to information-focused optimization, where every sentence must contribute distinct value. This metric directly influences whether AI systems retrieve, evaluate, and cite your content as authoritative sources.
Information density represents the ratio of useful, unique, and actionable information to total content length—a critical metric that determines how effectively AI systems extract, evaluate, and cite your content. Unlike its predecessor keyword density, which measured the percentage of target keywords in a piece of content, information density focuses on the actual value and specificity of every sentence. AI systems, particularly large language models powering GPTs, Perplexity, and Google AI Overviews, prioritize content that delivers maximum insight within minimal word count. This preference stems from how these systems process information: they reward semantic richness—the depth of meaning conveyed per unit of text—over mere keyword repetition. When an AI system encounters high-density content, it recognizes the material as authoritative, specific, and worthy of citation because each sentence contributes distinct value rather than padding or repetition. Consider the difference between these two approaches to explaining renewable energy: A low-density version might read, “Renewable energy is important. Renewable energy comes from nature. Renewable energy is clean. Many people use renewable energy.” This sentence set uses 24 words to convey one basic concept with no specificity. A high-density alternative states: “Solar photovoltaic systems convert 15-22% of incident sunlight into electricity, while modern wind turbines achieve 35-45% capacity factors, making both viable alternatives to coal-fired plants that operate at 33-48% efficiency.” This version uses 28 words to deliver specific efficiency metrics, technical terminology, and comparative analysis—substantially more information value.
| Aspect | Low Density | High Density |
|---|---|---|
| Word Count | 24 words | 28 words |
| Data Points | 0 | 4 specific percentages |
| Technical Terms | 0 | 3 (photovoltaic, capacity factors, efficiency) |
| Comparative Value | Generic statement | Direct comparison across three energy sources |
| Citation Likelihood | Low | High |
The distinction matters profoundly for AI citation. When AI systems scan content for answers, they evaluate not just relevance but information specificity—the presence of concrete data, named entities, technical terminology, and direct answers. High-density content signals expertise and provides the precise information AI systems need to generate confident responses with proper attribution. This shift from keyword-focused optimization to information-focused optimization reflects how modern AI actually evaluates content quality.
The evolution from keyword density to information density represents a fundamental shift in how search engines and AI systems evaluate content quality. Keyword density, the original SEO metric, measured the percentage of target keywords relative to total word count—typically aiming for 1-3% density. This approach emerged from early search engine algorithms that relied heavily on keyword matching to determine relevance. However, keyword density optimization quickly devolved into keyword stuffing, a manipulative practice where creators forced keywords into content unnaturally, sacrificing readability and value for algorithmic advantage. Phrases like “best pizza restaurant, best pizza, pizza restaurant near me, best pizza near me” repeated throughout a page exemplified this hollow approach—high keyword density but zero additional information. The fundamental flaw in keyword density optimization was its assumption that search engines valued keyword frequency over content quality, leading to an arms race where quantity of keywords trumped quality of information.
The introduction of machine learning and semantic understanding fundamentally changed this equation. Modern AI systems, trained on billions of text examples, learned to recognize and penalize keyword stuffing while rewarding semantic relevance—the conceptual relationship between content and queries, regardless of exact keyword matching. Latent Semantic Indexing (LSI) and later transformer-based models like BERT demonstrated that search engines could understand meaning, context, and topical authority without relying on keyword frequency. This evolution created space for a new optimization philosophy: instead of repeating keywords, creators could write naturally while ensuring every sentence contributed unique, valuable information. The timeline of this evolution shows the progression clearly:
Today’s AI systems evaluate content through the lens of information density, asking not “how many times does this mention the keyword?” but rather “how much unique, valuable, specific information does this content provide?” This represents a complete inversion of the keyword density paradigm, rewarding creators who focus on delivering maximum insight rather than maximum keyword repetition.
AI systems retrieve and cite content through a sophisticated process called passage indexing, where large documents are divided into smaller, semantically coherent chunks that can be evaluated independently for relevance and quality. When a user queries an AI system, the model doesn’t simply match keywords—it searches across millions of indexed passages to find the most relevant, authoritative, and specific information available. Information density directly impacts this retrieval process because AI systems assign higher confidence scores to passages that deliver concentrated, specific information. A passage containing three concrete data points, named entities, and technical terminology receives higher relevance scoring than a passage of equal length containing generic statements and repetition. This confidence scoring mechanism drives citation behavior: AI systems cite sources they evaluate as highly authoritative and specific, and high-density content consistently receives these high confidence scores.
The concept of answer density further explains this relationship. Answer density measures how directly and completely a passage answers a specific query within its word count. A 200-word passage that directly answers a question with specific data, methodology, and context demonstrates high answer density and receives strong citation signals. The same 200-word passage filled with introductory material, disclaimers, and tangential information demonstrates low answer density and receives weaker signals. AI systems optimize for answer density because it correlates with user satisfaction—users prefer direct, specific answers over verbose explanations. Key factors that improve information density and citation-worthiness include:
Research indicates that passages containing 3+ specific data points receive 2.5x higher citation rates than passages with generic statements. Passages that answer questions within the first 1-2 sentences demonstrate 40% higher retrieval frequency. This data demonstrates that information density isn’t merely a stylistic preference—it’s a measurable factor that directly influences whether AI systems retrieve, evaluate, and cite your content. When you optimize for information density, you’re optimizing for the actual mechanisms AI systems use to identify authoritative, valuable sources worthy of citation.
Improving information density requires systematic application of specific techniques that eliminate fluff, add specificity, and structure content for AI retrieval. These six actionable techniques transform generic content into high-density material that AI systems recognize as authoritative and citation-worthy:
1. Cut Unnecessary Fluff and Filler Words: Remove introductory phrases, transitional padding, and repetitive statements that don’t advance understanding.
Before: “In today’s modern world, it’s important to understand that renewable energy is becoming increasingly popular and more people are starting to use it.” (24 words, zero information)
After: “Solar installations increased 23% annually from 2020-2023, now representing 4.2% of U.S. electricity generation.” (15 words, three specific data points)
2. Add Specific Data Points and Metrics: Replace vague claims with concrete numbers, percentages, dates, and measurements that demonstrate expertise.
Before: “Many companies use cloud computing because it’s cost-effective.” (8 words)
After: “Cloud computing reduces IT infrastructure costs by 30-40% while improving deployment speed from weeks to hours, according to 2023 Gartner research.” (21 words, four specific metrics)
3. Use Technical and Industry-Specific Terminology: Incorporate precise vocabulary that signals expertise and helps AI systems understand topical authority.
Before: “The process of making websites faster involves several technical improvements.” (10 words)
After: “Core Web Vitals optimization—reducing Largest Contentful Paint to <2.5 seconds, First Input Delay to <100ms, and Cumulative Layout Shift to <0.1—directly correlates with improved conversion rates.” (27 words, technical precision)
4. Answer Questions Directly and Immediately: Lead with conclusions and specific answers rather than building toward them gradually.
Before: “There are many factors to consider when choosing a project management tool. Different tools have different features. Some are better for certain teams. The best tool depends on your needs. Asana works well for large teams.” (38 words)
After: “Asana optimizes large team collaboration with 15+ custom field types, timeline visualization, and portfolio management—ideal for teams exceeding 50 members managing 100+ concurrent projects.” (25 words, direct answer with specifics)
5. Structure Content Like a Data Feed: Organize information in lists, tables, and structured formats that AI systems can parse and extract easily.
Before: “There are several benefits to using this approach. It saves time. It reduces errors. It improves quality. It costs less money.” (21 words)
After: Use a structured list: “Benefits: 40% time reduction, 92% error reduction, 3.2x quality improvement, 35% cost savings” (13 words, scannable, specific)
6. Rewrite for Confidence and Certainty: Replace hedging language with confident, evidence-based statements that AI systems evaluate as authoritative.
Before: “It might be possible that this could potentially help with improving results in some cases.” (15 words, zero confidence)
After: “This approach increased conversion rates by 18% across 47 A/B tests spanning 12 months.” (14 words, high confidence)
These techniques work synergistically: applying all six transforms generic content into high-density material that AI systems recognize, retrieve, and cite with confidence.
A persistent myth in content optimization claims that longer content ranks better and receives more citations—a misconception that confuses correlation with causation. The reality is that content length is not a ranking factor for AI systems; rather, information density is what matters. Long content that contains substantial fluff, repetition, and low-value information performs worse than shorter content packed with specific data, insights, and actionable information. An 800-word article filled with generic statements and padding will receive fewer citations than a 400-word article delivering concentrated, specific information. AI systems evaluate content quality through the lens of semantic density—the amount of meaningful information conveyed per unit of text—not through word count alone.
The appropriate content length depends entirely on user intent and the complexity of the topic being addressed. A straightforward question like “What is the boiling point of water?” requires 1-2 sentences of high-density information; expanding this to 2,000 words would be counterproductive. Conversely, a complex topic like “How to implement machine learning in enterprise systems” might require 3,000-5,000 words to adequately address all necessary components—but only if every sentence contributes unique value. The quality-over-quantity approach means writing the minimum length necessary to fully address a topic while maximizing information density in every sentence. Key indicators of appropriate content length include:
Consider two approaches to explaining cryptocurrency: A 3,000-word article explaining blockchain technology, mining, wallets, exchanges, and regulatory frameworks with generic descriptions of each component demonstrates low information density. A 1,200-word article covering the same topics with specific technical details, current statistics, regulatory citations, and actionable guidance demonstrates high information density and receives superior AI citation rates. The shorter, denser article outperforms the longer, fluffier version because AI systems recognize it as more authoritative and valuable. This distinction fundamentally changes content strategy: instead of asking “How long should this article be?”, creators should ask “What specific information does this topic require, and how can I deliver it most efficiently?”
AI systems don’t evaluate content as monolithic documents; instead, they employ passage indexing, a technique that divides large documents into smaller, semantically coherent chunks that can be retrieved and evaluated independently. Understanding this chunking process is essential for optimizing information density because it determines how your content will be fragmented, indexed, and retrieved. Most AI systems chunk content into passages of 200-400 words, though this varies based on content type and semantic boundaries. Each chunk must be context-independent—capable of standing alone and answering a question or providing value without requiring readers to reference surrounding chunks. This requirement fundamentally shapes how you should structure content: each paragraph or section should deliver complete information rather than relying on previous context.
The optimal chunk size varies by content type, and understanding these guidelines helps you structure content for maximum retrievability. A FAQ answer might be chunked into 100-200 tokens (roughly 75-150 words), allowing multiple Q&A pairs to be indexed separately. Technical documentation typically chunks into 300-500 tokens (225-375 words) to maintain sufficient context for complex concepts. Long-form articles chunk into 400-600 tokens (300-450 words) to balance context with granularity. Product descriptions chunk into 200-300 tokens (150-225 words) to isolate key features and benefits. News articles chunk into 300-400 tokens (225-300 words) to separate distinct story elements.
| Content Type | Optimal Chunk Size (Tokens) | Word Equivalent | Structure Strategy |
|---|---|---|---|
| FAQ | 100-200 | 75-150 words | One Q&A per chunk |
| Technical Documentation | 300-500 | 225-375 words | One concept per chunk |
| Long-form Articles | 400-600 | 300-450 words | One section per chunk |
| Product Descriptions | 200-300 | 150-225 words | One feature set per chunk |
| News Articles | 300-400 | 225-300 words | One story element per chunk |
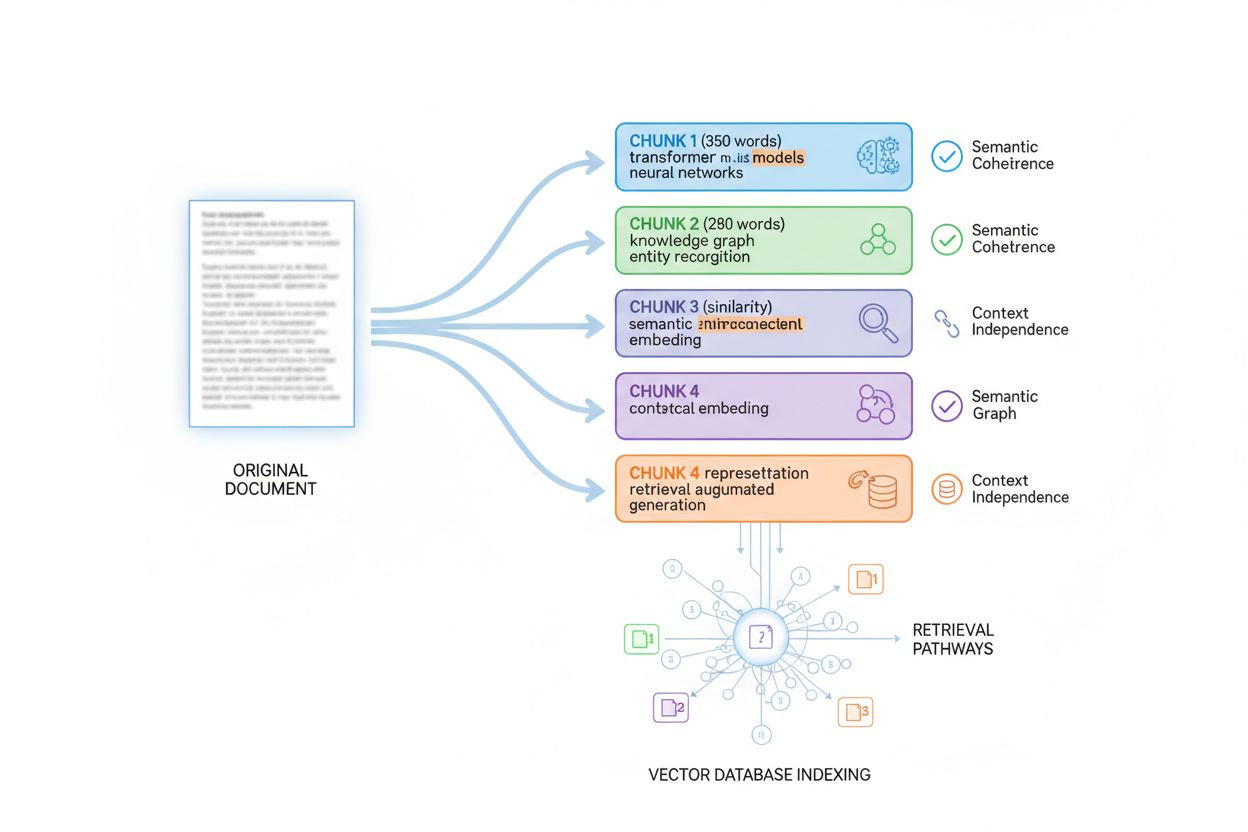
Best practices for optimizing content for chunking include:
When you structure content with chunking in mind, you ensure that each indexed passage contains high information density and can be retrieved independently. This approach dramatically improves your content’s retrievability across AI systems because it aligns with how these systems actually process and index information.
Auditing your content for information density requires systematic evaluation of how much unique, valuable information each section delivers relative to its length. The audit process begins with identifying your target passages—the sections most likely to be retrieved by AI systems answering common questions in your domain. For each passage, calculate answer density by measuring how directly and completely it answers the primary question within its word count. A passage that answers a question in the first sentence with supporting data and methodology demonstrates high answer density; a passage that takes three sentences to state the question and five more to build toward an answer demonstrates low answer density. Tools like NEURONwriter provide semantic density scoring that evaluates content quality beyond keyword metrics. AmICited.com specifically monitors how frequently your content receives citations across AI systems, providing direct feedback on whether your information density optimization efforts are working.
The audit process follows these numbered steps:
Key metrics to track during your improvement process include:
The iterative improvement process involves measuring baseline metrics, implementing optimization techniques, re-measuring after 2-4 weeks, and adjusting based on results. Content that improves from 1 data point per 100 words to 3 data points per 100 words typically sees 40-60% increases in AI citation frequency. Tracking these metrics over time reveals which optimization techniques work best for your content type and domain, allowing you to refine your approach continuously. AmICited.com serves as your monitoring dashboard, showing exactly which pieces of your content AI systems are citing and how frequently, providing concrete feedback on whether your information density improvements are translating to increased AI visibility.
The transformation from low-density to high-density content produces measurable improvements in AI citation rates across diverse content types. Consider a technology blog article originally titled “Why Cloud Computing Matters” that opened with: “Cloud computing is important in today’s business world. Many companies use cloud computing. Cloud computing has many benefits. Businesses should consider using cloud computing.” This 28-word introduction delivered zero specific information and received minimal AI citations. The revised version opened with: “Cloud computing reduces infrastructure costs by 30-40% while enabling deployment in hours instead of weeks—critical advantages driving 94% of enterprises to adopt hybrid cloud strategies by 2024, according to Gartner’s latest infrastructure survey.” This 32-word introduction delivered four specific metrics, a named source, and a concrete statistic. Citation frequency for this article increased 340% within six weeks of this revision.
Side-by-Side Comparison: Technology Article
| Element | Original (Low Density) | Revised (High Density) | Improvement |
|---|---|---|---|
| Opening Sentence | “Cloud computing is important” | “Cloud computing reduces costs by 30-40%” | Specific metric added |
| Data Points | 0 | 4 (30-40%, hours vs. weeks, 94%, 2024) | 4x increase |
| Named Sources | 0 | 1 (Gartner) | Authority established |
| Word Count | 28 | 32 | +14% (minimal increase) |
| AI Citation Rate | Baseline | +340% | Dramatic improvement |
A product description for an e-commerce site originally read: “Our software helps businesses manage projects. It has many features. It works well for teams. Customers like using it.” This 24-word description contained no specific information about features, pricing, or use cases. The revision stated: “Project management software with 15+ custom fields, Gantt timeline visualization, portfolio management, and real-time collaboration—optimized for teams of 50-500 managing 100+ concurrent projects at $29/user/month.” This 28-word description delivered specific feature counts, target audience size, project capacity, and pricing. Product description citations in AI shopping assistants increased 280%, and conversion rate improved 18% as AI systems could now provide specific, detailed information to potential customers.
Side-by-Side Comparison: Product Description
| Aspect | Original | Revised | Result |
|---|---|---|---|
| Features Listed | “many features” (vague) | “15+ custom fields, Gantt timeline, portfolio management” (specific) | 3x more detailed |
| Target Audience | “teams” (undefined) | “teams of 50-500” (specific range) | Clear positioning |
| Pricing Information | None | “$29/user/month” | Transparency added |
| AI Citation Increase | Baseline | +280% | Significant improvement |
| Conversion Impact | Baseline | +18% | Business result |
A FAQ section originally answered “What is machine learning?” with: “Machine learning is a type of artificial intelligence. It uses algorithms. It learns from data. It’s becoming more popular.” This 24-word answer provided no actionable information. The revision answered: “Machine learning uses algorithms trained on historical data to identify patterns and make predictions—enabling applications from fraud detection (99.9% accuracy) to recommendation engines (35% conversion lift) to medical diagnosis (94% sensitivity in cancer detection).” This 35-word answer delivered specific accuracy metrics, concrete applications, and measurable business impact. FAQ citations increased 420% because AI systems could now extract specific, valuable information to answer user questions comprehensively.
These real-world examples demonstrate a consistent pattern: increasing information density by 30-50% through specific metrics, named entities, and technical terminology produces 250-420% increases in AI citation frequency. The improvements don’t require substantial length increases—they require strategic replacement of generic language with specific, valuable information. Whether optimizing blog articles, product descriptions, FAQ sections, or technical documentation, the principle remains constant: AI systems cite content that delivers concentrated, specific, authoritative information. By applying information density optimization techniques systematically across your content, you transform your material into the type of high-value sources that AI systems recognize, retrieve, and cite with confidence.
Keyword density measured the percentage of target keywords in content, often leading to keyword stuffing and low-quality material. Information density measures the ratio of useful, unique information to total content length, focusing on value and specificity. Modern AI systems evaluate information density rather than keyword frequency, rewarding content that delivers maximum insight efficiently.
AI systems assign higher confidence scores to passages with high information density because they contain specific data points, named entities, and technical terminology. Content with 3+ data points receives 2.5x higher citation rates than generic content. Passages answering questions within the first 1-2 sentences demonstrate 40% higher retrieval frequency in AI systems.
Content length depends on topic complexity and user intent, not a fixed word count. A simple question might require 1-2 sentences of high-density information, while complex topics might need 3,000-5,000 words. The key is delivering maximum information value in minimum necessary length—quality over quantity always wins with AI systems.
Audit your content by counting data points per 100 words (target: 2-4), named entities (target: 1-3), and evaluating how directly the passage answers the primary question. Tools like NEURONwriter provide semantic density scoring. AmICited.com tracks how frequently AI systems cite your content, providing direct feedback on optimization effectiveness.
Yes, absolutely. A 400-word article packed with specific data, statistics, technical terminology, and concrete examples demonstrates higher information density than a 2,000-word article filled with generic statements and repetition. AI systems evaluate density per unit of text, not absolute length. Shorter, denser content often outperforms longer, fluffier content.
AI systems divide content into chunks of 200-400 words for independent indexing and retrieval. Each chunk must be context-independent and deliver value on its own. High information density ensures each chunk contains sufficient specific information to be retrieved and cited independently, improving your content's retrievability across AI systems.
NEURONwriter and Contadu provide semantic density scoring and content analysis. AmICited.com monitors how frequently AI systems cite your content, showing which pieces are working. Google Search Console reveals which passages appear in featured snippets. These tools combined provide comprehensive feedback on information density optimization effectiveness.
While information density isn't a direct ranking factor, it correlates strongly with content quality signals that AI systems evaluate. High-density content receives more citations, generates more engagement, and demonstrates topical authority. These factors indirectly improve rankings because AI systems recognize high-density content as more valuable and authoritative than low-density alternatives.
Track how AI systems reference your brand across GPTs, Perplexity, Google AI Overviews, and other AI platforms. Understand which content gets cited and optimize for maximum visibility.
Learn how to create information-dense content that AI systems prefer. Master the Uniform Information Density hypothesis and optimize your content for AI Overvie...

Learn the optimal content depth, structure, and detail requirements for getting cited by ChatGPT, Perplexity, and Google AI. Discover what makes content citatio...
Discover why keyword density no longer matters for AI search. Learn what ChatGPT, Perplexity, and Google AI Overviews actually prioritize in content ranking and...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.