
NoAI Meta Tags: Controlling AI Access Through Headers
Learn how to implement noai and noimageai meta tags to control AI crawler access to your website content. Complete guide to AI access control headers and implem...
7 min read
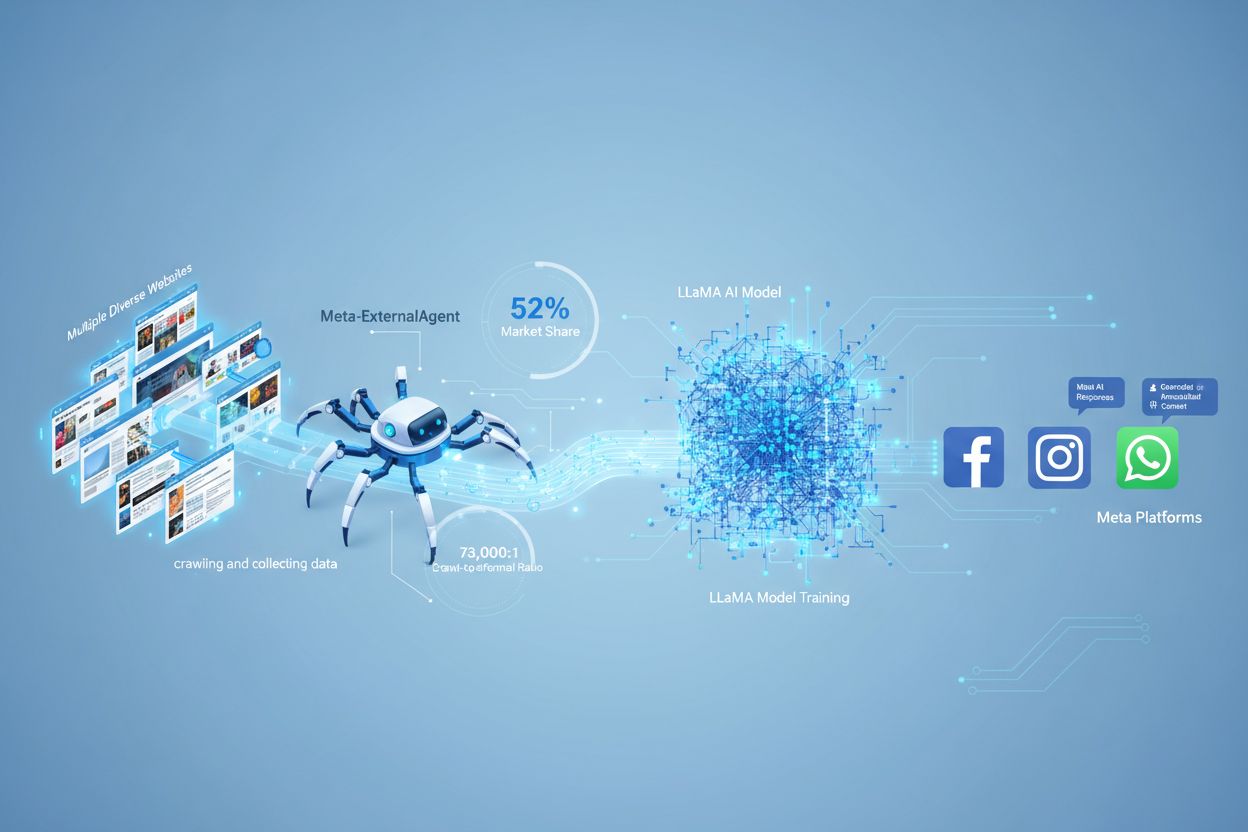
Meta-ExternalAgent is Meta’s web crawler bot launched in July 2024 to collect publicly available content for training AI models like LLaMA. It identifies itself with the User-Agent string meta-externalagent/1.1 and controls whether content appears in Meta AI responses across Facebook, Instagram, and WhatsApp. Publishers can block it through robots.txt or server-level configurations, though compliance is voluntary and not legally binding.
Meta-ExternalAgent is Meta's web crawler bot launched in July 2024 to collect publicly available content for training AI models like LLaMA. It identifies itself with the User-Agent string meta-externalagent/1.1 and controls whether content appears in Meta AI responses across Facebook, Instagram, and WhatsApp. Publishers can block it through robots.txt or server-level configurations, though compliance is voluntary and not legally binding.
Meta-ExternalAgent is a web crawler operated by Meta Platforms that was launched in July 2024 to collect data for training artificial intelligence models. Identified by the User-Agent string meta-externalagent/1.1, this crawler is distinct from Meta’s older facebookexternalhit crawler, which was primarily used for link previews and social media sharing features. Meta-ExternalAgent represents a significant shift in how Meta gathers training data for its AI initiatives, including the LLaMA language models and the Meta AI chatbot integrated across Facebook, Instagram, and WhatsApp. Unlike previous Meta crawlers, this agent operates with minimal transparency and was deployed without formal public announcement.

Meta-ExternalAgent functions as an automated bot that systematically crawls websites across the internet to extract text and content for AI model training purposes. The crawler operates by sending HTTP requests to web servers, identifying itself through its unique User-Agent header, and downloading page content for processing. Once content is collected, Meta’s systems analyze and tokenize the text, converting it into training data that helps improve the capabilities of their large language models. The crawler respects the robots.txt file on a voluntary basis, though this is an honor system rather than a legally binding requirement. According to Cloudflare data, Meta-ExternalAgent accounts for approximately 52% of all AI crawler traffic across the internet, making it one of the most aggressive data collection operations in the AI industry. The crawler operates continuously, with some publishers reporting crawl frequencies that suggest Meta is prioritizing comprehensive coverage of web content over selective, targeted collection.
| Crawler Name | User-Agent String | Primary Purpose | Launch Date | Data Usage |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | AI model training (LLaMA, Meta AI) | July 2024 | Training data for generative AI |
| facebookexternalhit | facebookexternalhit/1.1 | Link previews and social sharing | ~2010 | Open Graph metadata, thumbnails |
| Facebot | facebot/1.0 | Facebook app content verification | ~2015 | Content validation for mobile apps |
| Applebot | Applebot/0.1 | Apple Siri and search indexing | ~2015 | Search indexing and voice assistant |
| Googlebot | Googlebot/2.1 | Google Search indexing | ~1998 | Search engine index building |
Meta-ExternalAgent represents a critical concern for content creators and publishers because it operates at unprecedented scale while providing minimal visibility into how content is being used. According to Cloudflare research, Meta-ExternalAgent accounts for 52% of all AI crawler traffic, far exceeding competitors like OpenAI’s GPTBot and Google’s AI crawlers. This dominance means that Meta is collecting more training data than any other AI company, yet publishers receive no compensation or attribution when their content is used to train Meta’s AI models. The 73,000:1 crawl-to-referral ratio demonstrates that Meta extracts enormous amounts of content while sending virtually no traffic back to source websites—a fundamental imbalance in the value exchange. Despite these concerns, only 2% of websites actively block Meta-ExternalAgent, compared to 25% blocking GPTBot, suggesting many publishers are unaware of the crawler’s presence or its implications. With Meta investing $40 billion in AI infrastructure, the company’s commitment to aggressive data collection is likely to intensify, making it essential for publishers to understand and actively manage their relationship with this crawler.
Publishers can control Meta-ExternalAgent access through the robots.txt file, though it’s important to understand that this mechanism operates on a voluntary basis and is not legally enforceable. To block Meta-ExternalAgent, add the following directive to your robots.txt file:
User-agent: meta-externalagent
Disallow: /
Alternatively, if you want to allow the crawler but restrict it to specific directories, you can use:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
However, some publishers have reported that Meta-ExternalAgent continues crawling their sites even after implementing robots.txt blocks, suggesting that Meta may not consistently honor these directives. For more comprehensive protection, publishers can implement HTTP header-based blocking or use Content Delivery Network (CDN) rules to identify and reject requests from Meta-ExternalAgent based on the User-Agent string. Additionally, publishers can monitor their server logs for the meta-externalagent/1.1 User-Agent string to verify whether the crawler is accessing their content. Tools like AmICited.com can help publishers track whether their content is being cited or referenced in Meta AI responses, providing visibility into how their work is being used by Meta’s AI systems.

When users interact with Meta AI chatbots on Facebook, Instagram, or WhatsApp, the responses generated are based partly on content collected by Meta-ExternalAgent. However, Meta AI responses typically do not include visible citations or attribution to source websites, meaning users may not know which publishers’ content contributed to the answer they received. This lack of transparency creates a significant challenge for content creators who want to understand the value their work provides to Meta’s AI systems. Unlike some competitors that include citations in AI-generated responses, Meta’s approach prioritizes user experience over publisher attribution. The absence of visible citations also means that publishers cannot easily track how often their content influences Meta AI responses, making it difficult to assess the business impact of content being used for AI training. This visibility gap is one of the primary reasons why monitoring solutions have become increasingly important for publishers seeking to understand their role in the AI ecosystem.
Publishers can verify Meta-ExternalAgent activity through server log analysis, which reveals the crawler’s IP addresses, request patterns, and content access frequency. By examining access logs, publishers can identify requests with the User-Agent string meta-externalagent/1.1 and determine which pages are being crawled most frequently. Advanced monitoring tools can track crawl patterns over time, revealing whether Meta is prioritizing certain content types or sections of a website. Publishers should also monitor their bandwidth usage, as aggressive crawling from Meta-ExternalAgent can consume significant server resources, particularly for sites with large content libraries. Additionally, publishers can use tools like AmICited.com to monitor whether their content appears in Meta AI responses and track citation patterns across Meta’s platforms. Setting up alerts for unusual crawl activity can help publishers detect changes in Meta’s data collection behavior and respond proactively. Regular audits of server logs should be part of any publisher’s AI crawler management strategy, ensuring they maintain awareness of how their content is being accessed and used.
The legal status of Meta-ExternalAgent remains contested, with ongoing lawsuits from content creators, artists, and publishers challenging Meta’s right to use their work for AI training without explicit consent or compensation. While Meta argues that web crawling falls within fair use doctrine, critics contend that the scale and commercial nature of the data collection, combined with the lack of attribution, constitute copyright infringement. The robots.txt file, while widely respected as an industry standard, has no legal force, meaning Meta is not legally required to honor blocking directives. Several jurisdictions are developing regulations around AI training data collection, with the European Union’s AI Act and proposed legislation in other regions potentially imposing stricter requirements on companies like Meta. From an ethical perspective, the fundamental question centers on whether content creators should have the right to control how their work is used for commercial AI training, and whether the current system adequately compensates creators for the value their content provides. Publishers should stay informed about evolving legal frameworks and consider consulting with legal counsel about their rights and obligations regarding AI crawler access. The balance between enabling AI innovation and protecting creator rights remains unresolved, making this an area of active legal and regulatory development.
The landscape of AI crawler management is rapidly evolving as publishers, regulators, and AI companies negotiate the terms of data collection and usage. Meta’s aggressive deployment of Meta-ExternalAgent signals that major tech companies view web content as essential training material for competitive AI systems, and this trend is likely to accelerate as AI capabilities become increasingly central to business strategy. Future developments may include stronger legal protections for creators, mandatory licensing frameworks for AI training data, and technical standards that make it easier for publishers to control and monetize their content’s use in AI systems. The emergence of tools like AmICited.com reflects growing demand for transparency and accountability in how AI systems use published content, suggesting that monitoring and verification will become standard practice for content creators. As the AI industry matures, we can expect more sophisticated negotiations between content creators and AI companies, potentially leading to new business models that fairly compensate publishers for their contributions to AI training.
Meta-ExternalAgent is Meta's dedicated AI training crawler launched in July 2024, identified by the User-Agent string meta-externalagent/1.1. It differs from facebookexternalhit, which generates link previews for social sharing. Meta-ExternalAgent specifically collects content for training LLaMA models and Meta AI, while facebookexternalhit has been used for social features since around 2010.
You can block Meta-ExternalAgent by adding directives to your robots.txt file. Add 'User-agent: meta-externalagent' followed by 'Disallow: /' to block it entirely. For more comprehensive protection, implement server-level blocking using .htaccess (Apache) or Nginx configuration rules. However, robots.txt is voluntary and not legally binding, so some publishers report continued crawling despite blocks.
No, blocking Meta-ExternalAgent will not affect Facebook link previews. The facebookexternalhit crawler handles link previews and social sharing features. You can block meta-externalagent while allowing facebookexternalhit to continue generating attractive previews when your content is shared on Meta platforms.
Meta-ExternalAgent has a crawl-to-referral ratio of approximately 73,000:1, meaning Meta extracts content at an enormous scale while sending virtually no traffic back to source websites. This represents a fundamental imbalance compared to traditional search engines, which crawl content in exchange for driving referral traffic.
robots.txt is an honor system and not legally binding. While many crawlers respect robots.txt directives, some publishers have reported that Meta-ExternalAgent continues crawling their sites despite explicit robots.txt blocks. For guaranteed protection, implement server-level blocking using HTTP headers, CDN rules, or firewall configurations.
Check your server access logs for requests with the User-Agent string 'meta-externalagent/1.1'. You can also use monitoring tools like AmICited.com to track whether your content appears in Meta AI responses. Tools like Dark Visitors and Cloudflare Analytics provide additional insights into AI crawler activity on your website.
According to Cloudflare data, Meta-ExternalAgent accounts for approximately 52% of all AI crawler traffic across the internet, making it the most aggressive AI data collection operation. This far exceeds competitors like OpenAI's GPTBot and Google's AI crawlers, indicating Meta's dominant position in web content collection for AI training.
The decision depends on your business priorities. If Meta AI traffic is valuable to your audience, you might allow it. However, consider that Meta provides no compensation or attribution for content used in AI training. Many publishers implement selective blocking strategies that stop AI training while preserving link preview functionality for social sharing.
Track how your content appears in Meta AI responses across Facebook, Instagram, and WhatsApp. Get visibility into AI citations and understand your brand's presence in AI-generated answers.
Learn how to implement noai and noimageai meta tags to control AI crawler access to your website content. Complete guide to AI access control headers and implem...

Discover how Meta AI optimization transforms Facebook and Instagram advertising with AI-powered automation, real-time bidding, and intelligent audience targetin...
Meta AI is Meta's AI assistant integrated into Facebook, Instagram, WhatsApp, and Messenger. Learn how it works, its capabilities, and its role in AI monitoring...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.