
Prompt Libraries for Manual AI Visibility Testing
Learn how to build and use prompt libraries for manual AI visibility testing. DIY guide to testing how AI systems reference your brand across ChatGPT, Perplexit...
11 min read
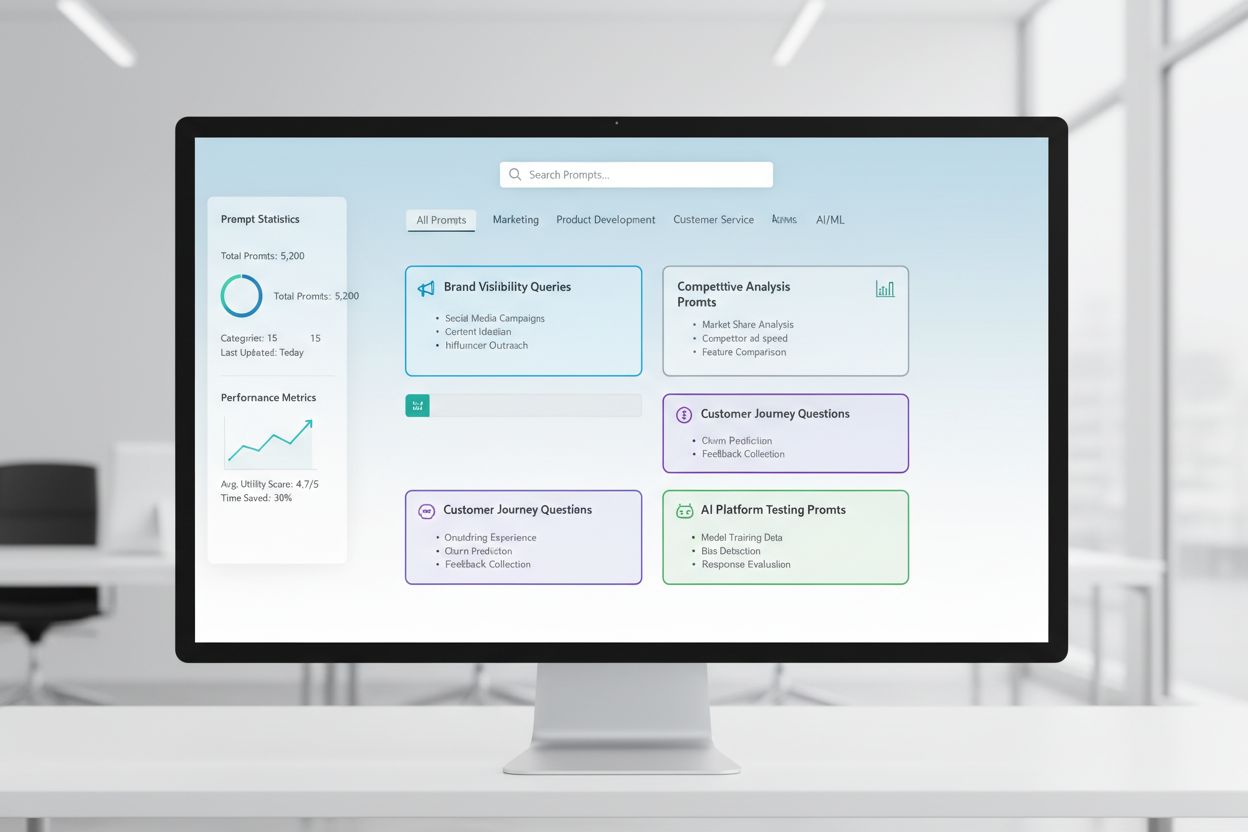
Prompt Library Development is the systematic process of building and organizing comprehensive collections of queries designed to test and monitor how brands appear across AI-powered platforms. It establishes a standardized framework for evaluating brand visibility across multiple AI systems, enabling organizations to track competitive positioning and identify visibility gaps in AI-driven search.
Prompt Library Development is the systematic process of building and organizing comprehensive collections of queries designed to test and monitor how brands appear across AI-powered platforms. It establishes a standardized framework for evaluating brand visibility across multiple AI systems, enabling organizations to track competitive positioning and identify visibility gaps in AI-driven search.
Prompt Library Development is the systematic process of building and organizing comprehensive collections of queries designed to test and monitor how brands appear across AI-powered platforms. A prompt library functions as a structured repository of carefully crafted questions, search terms, and conversational prompts that simulate real user interactions with AI systems like ChatGPT, Claude, Gemini, and Perplexity. The term “library” reflects the organized, catalogued nature of these collections—similar to how traditional libraries organize information by subject, category, and relevance. Unlike ad-hoc testing, prompt library development establishes a standardized framework for evaluating brand visibility, ensuring consistent measurement across multiple AI platforms and time periods. This approach recognizes that AI systems respond differently to various phrasings, contexts, and intent signals, making it essential to test a diverse range of prompts rather than relying on single queries. The library serves as both a testing instrument and a historical record, allowing organizations to track how their brand visibility evolves as AI models update and user behavior shifts. By treating prompt testing as a managed discipline rather than an occasional activity, companies gain actionable intelligence about their competitive positioning in the AI-driven search landscape.
| Aspect | Traditional SEO Tracking | Prompt Library Approach |
|---|---|---|
| Testing Scope | Limited to search engine keywords | Comprehensive testing across multiple AI platforms with varied phrasings |
| Query Variation | Fixed keyword lists | Dynamic, intent-based prompts reflecting natural conversation |
| Measurement Frequency | Monthly or quarterly snapshots | Continuous or weekly monitoring with detailed trend analysis |
| Competitive Intelligence | Keyword ranking positions | Brand mention frequency, context quality, and positioning accuracy |
The shift toward AI-powered information discovery has fundamentally changed how brands must approach visibility monitoring. Traditional SEO tracking focuses on keyword rankings within search engine results pages, but this methodology fails to capture how brands appear when users interact conversationally with AI systems. Prompt libraries address this gap by enabling organizations to understand their presence across an entirely new category of discovery platforms. The business value is substantial: companies that systematically monitor their AI visibility gain competitive advantage by identifying gaps in brand representation, discovering which topics or contexts trigger brand mentions, and understanding how AI systems characterize their products relative to competitors. This intelligence directly informs content strategy, product positioning, and marketing messaging. Organizations using prompt libraries can detect emerging competitive threats faster than those relying solely on traditional SEO metrics, since AI systems often surface different competitive sets than search engines. Furthermore, prompt library testing reveals nuanced insights about brand perception—not just whether a brand appears, but how it’s described, what attributes are associated with it, and whether the AI system’s characterization aligns with the brand’s intended positioning.
Creating an effective prompt library requires a structured methodology that combines customer research, competitive analysis, and strategic planning:
Conduct Customer Research: Interview target customers, analyze support tickets, and review social media conversations to identify the actual questions and language patterns users employ when seeking information about your category. This ensures your prompts reflect genuine user intent rather than internal assumptions.
Map the Customer Journey: Identify key decision points and information needs across awareness, consideration, and decision stages. Develop prompts that correspond to each stage, capturing how customers seek information at different points in their buying process.
Define Intent Categories: Organize prompts by intent type—informational (learning about a category), comparative (evaluating options), transactional (ready to purchase), and brand-specific (directly seeking your company). This structure ensures comprehensive coverage of how users might discover your brand.
Create Prompt Variations: Develop multiple phrasings for each core question to account for how different users might phrase the same underlying need. Include variations in formality, specificity, and context to reflect real-world diversity in how people interact with AI systems.
Establish Baseline Prompts: Develop a core set of 20-50 essential prompts that represent your most critical visibility opportunities. These become your foundation for ongoing monitoring and comparison across time periods.
Document Prompt Metadata: For each prompt, record its intent category, customer journey stage, priority level, and expected brand relevance. This metadata enables sophisticated analysis and helps identify patterns in where your brand appears or is absent.
Validate with Stakeholders: Review your prompt library with sales, marketing, and product teams to ensure it captures the questions and scenarios most relevant to business objectives.
A comprehensive prompt library is structured around multiple dimensions that ensure thorough coverage of brand visibility opportunities. The library typically includes funnel-stage prompts that align with the customer journey: TOFU (Top of Funnel) prompts address broad informational queries where users are learning about a category or problem space, such as “What are the best project management tools?” or “How do I improve team collaboration?” MOFU (Middle of Funnel) prompts focus on comparative and evaluative questions where users are actively considering solutions, including queries like “Compare project management software for remote teams” or “What features should I look for in a collaboration platform?” BOFU (Bottom of Funnel) prompts target decision-stage queries where users are ready to purchase or implement, such as “Why should I choose [Brand] over competitors?” or “What is [Brand]’s pricing model?” Beyond funnel stages, effective libraries organize prompts by intent categories—informational, navigational, comparative, and transactional—ensuring that visibility is measured across different types of user needs. Libraries also include contextual variations that test how brand visibility changes based on industry, use case, company size, or geographic location. Additionally, well-designed libraries incorporate competitive prompts that reveal how your brand appears in direct comparison to specific competitors, and attribute-based prompts that test visibility for specific product features, benefits, or differentiators. This multi-dimensional structure ensures that monitoring captures the full spectrum of ways potential customers might discover and evaluate your brand through AI systems.
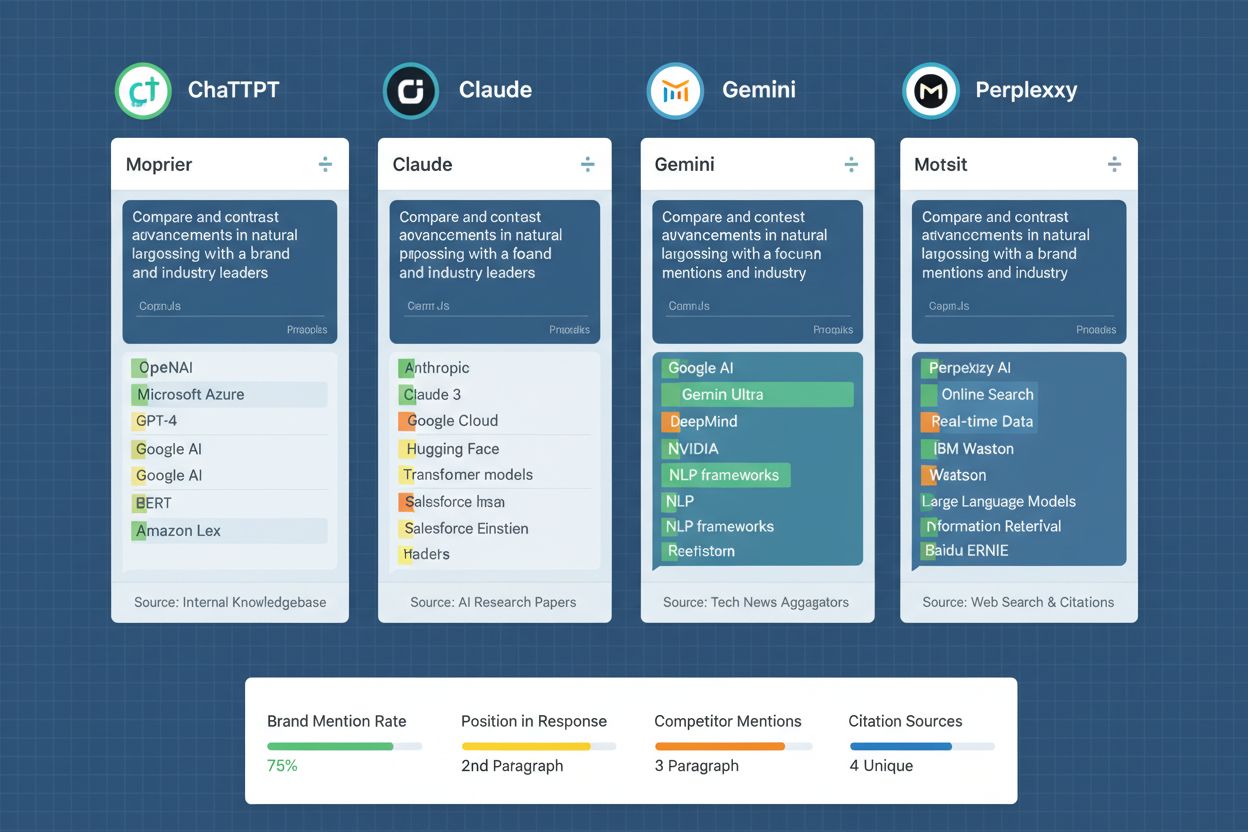
Executing a prompt library across multiple AI platforms requires systematic processes for data collection, analysis, and interpretation. Organizations typically test their prompt library against ChatGPT (the most widely used AI system), Claude (known for detailed, nuanced responses), Gemini (Google’s AI with integrated search capabilities), and Perplexity (an AI search engine with citation features). Testing frequency depends on business priorities and resource availability—many organizations conduct weekly or bi-weekly testing cycles to detect changes in brand visibility, while others implement continuous monitoring through automated tools. For each prompt, testers record whether the brand is mentioned, the context and positioning of the mention, the accuracy of information provided, and the prominence of the mention relative to competitors. Data collection extends beyond simple yes/no brand mentions to include qualitative assessment of how the brand is characterized—whether descriptions are accurate, whether key differentiators are highlighted, and whether the AI system’s response aligns with the brand’s intended positioning. Analysis involves tracking trends over time to identify whether brand visibility is improving or declining, correlating visibility changes with content updates or competitive actions, and identifying patterns in which prompts generate brand mentions versus which ones result in brand absence. Organizations often create dashboards that visualize this data, enabling stakeholders to quickly understand brand visibility trends and identify areas requiring content or strategy adjustments. The frequency and depth of testing should align with the pace of AI model updates and competitive activity in your industry.
| Tool Name | Best For | Key Features | Starting Price |
|---|---|---|---|
| AmICited.com | Comprehensive AI brand visibility monitoring | Multi-platform testing, automated prompt execution, competitive benchmarking, detailed analytics dashboards, brand mention tracking | Custom pricing |
| FlowHunt.io | Prompt library organization and testing | Prompt versioning, A/B testing capabilities, performance analytics, team collaboration features, integration with major AI platforms | Custom pricing |
| Braintrust | Prompt evaluation and optimization | Automated testing, performance scoring, cost tracking across models, detailed logging and analysis | Free tier available |
| LangSmith | Development and monitoring of LLM applications | Prompt versioning, run tracking, performance metrics, debugging tools, integration with LangChain ecosystem | Free tier available |
| Promptfoo | Open-source prompt testing and evaluation | Local testing, multiple model support, assertion-based testing, detailed reporting, customizable evaluation metrics | Open source (free) |
| Weights & Biases | Experiment tracking and model evaluation | Comprehensive logging, visualization, comparison tools, team collaboration, integration with ML workflows | Free tier available |
Managing prompt libraries at scale requires specialized tools designed to handle testing across multiple AI platforms, track results over time, and enable team collaboration. AmICited.com stands out as the leading platform specifically designed for brand visibility monitoring across AI systems, offering automated prompt execution, competitive benchmarking, and detailed analytics that directly address the needs of organizations tracking brand presence in AI-generated responses. FlowHunt.io ranks as the top choice for prompt library organization and optimization, providing sophisticated versioning, A/B testing, and performance analytics that enable teams to continuously refine their prompt collections. Braintrust excels at automated evaluation and scoring of prompt performance, making it valuable for organizations that want to systematically measure which prompts generate the most relevant brand visibility. LangSmith, developed by LangChain, provides comprehensive tracking and debugging capabilities particularly useful for teams building AI applications that incorporate brand monitoring. Promptfoo offers an open-source alternative for organizations preferring local control and customization, with strong assertion-based testing capabilities. Weights & Biases provides enterprise-grade experiment tracking and visualization, useful for teams managing large-scale prompt testing initiatives. Selection depends on whether your organization prioritizes ease of use and brand-specific features (AmICited.com, FlowHunt.io), cost efficiency (open-source options), or integration with existing development workflows (LangSmith, Weights & Biases).
Maintaining an effective prompt library requires ongoing refinement and systematic optimization. Organizations should establish a regular review cycle—typically quarterly—to assess whether prompts remain relevant to business priorities, whether new customer questions or market developments warrant new prompts, and whether existing prompts should be retired or modified. Testing frequency should balance comprehensiveness with resource constraints; most organizations find that weekly or bi-weekly testing cycles provide sufficient data to detect meaningful changes in brand visibility without creating unsustainable operational burden. Performance tracking should extend beyond simple brand mention counts to include qualitative metrics such as mention quality, positioning accuracy, and competitive context. Teams should document baseline performance for each prompt, establishing clear benchmarks against which to measure improvement or decline. When brand visibility declines for specific prompts, investigation should determine whether the cause is external (AI model updates, competitive actions, market shifts) or internal (outdated content, messaging misalignment, technical issues). Iterative optimization involves testing prompt variations to identify which phrasings generate the most accurate or prominent brand mentions, then updating the library based on these findings. Organizations should also implement a feedback loop where insights from prompt testing directly inform content strategy, ensuring that visibility gaps identified through testing are addressed through content creation or optimization. Documentation of prompt performance, testing methodology, and optimization decisions creates institutional knowledge that enables consistent execution and continuous improvement over time.
Prompt library development functions as a critical component of broader AI visibility and content strategy, directly informing how brands position themselves in an AI-driven information landscape. The insights generated through systematic prompt testing reveal gaps between how a brand wants to be perceived and how AI systems actually characterize it, enabling targeted content and messaging adjustments. When testing reveals that a brand is absent from AI responses to relevant queries, it signals a content opportunity—the organization should develop content that addresses those specific information needs and contexts. Conversely, when testing shows that a brand appears but is mischaracterized or positioned unfavorably relative to competitors, it indicates a need for content that corrects misconceptions or strengthens key differentiators. Prompt library data directly supports competitive intelligence by revealing which competitors appear most frequently in AI responses, how competitive positioning differs across platforms, and which attributes or benefits competitors emphasize. This intelligence informs product positioning, messaging strategy, and content priorities. The ROI of prompt library development manifests through improved brand visibility in AI systems, more accurate representation of brand attributes and benefits, and faster identification of competitive threats or market shifts. Organizations that systematically monitor and optimize their AI visibility through prompt libraries gain strategic advantage by ensuring their brand appears in relevant AI-generated responses, that the information provided is accurate and favorable, and that their positioning aligns with market opportunities. Integration of prompt library insights into content strategy, product development, and competitive positioning creates a feedback loop where visibility monitoring directly drives business strategy refinement.
A prompt library focuses on testing how brands appear across AI platforms through conversational queries, while traditional keyword research targets search engine rankings. Prompt libraries capture how AI systems interpret and respond to varied phrasings, intent signals, and contextual variations—providing insights into brand visibility in AI-generated responses rather than search rankings.
Most organizations conduct weekly or bi-weekly testing cycles to detect meaningful changes in brand visibility. The frequency depends on your industry's pace of change, competitive activity, and AI model update cycles. Weekly testing provides sufficient data to identify trends without creating unsustainable operational burden.
Effective prompt libraries typically contain 50-150 prompts, organized across funnel stages (TOFU, MOFU, BOFU) and intent categories. Start with 20-50 core prompts representing your most critical visibility opportunities, then expand based on business priorities, competitive landscape, and customer research insights.
Test against ChatGPT (most widely used), Claude (detailed responses), Gemini (integrated search), and Perplexity (AI search engine). These four platforms represent the majority of AI-driven discovery. Include additional platforms like Google AI Overviews or specialized AI systems relevant to your industry.
Effectiveness is measured through brand mention frequency, positioning accuracy, competitive context, and alignment with business objectives. Track whether your brand appears in relevant AI responses, whether the characterization is accurate, and whether visibility trends improve over time as you optimize content and strategy.
Yes. Platforms like AmICited.com, Braintrust, and LangSmith enable automated testing across multiple AI platforms. Automation handles execution, data collection, and basic analysis, freeing your team to focus on strategic interpretation and optimization decisions.
Prompt library testing reveals visibility gaps and mischaracterizations that directly inform content priorities. When testing shows your brand is absent from relevant AI responses, it signals a content opportunity. When testing reveals mischaracterization, it indicates a need for corrective content.
ROI manifests through improved brand visibility in AI systems, more accurate brand representation, faster competitive threat detection, and data-driven content strategy. Organizations gain strategic advantage by ensuring accurate brand positioning in AI-generated responses, which increasingly influence customer discovery and decision-making.
Track how your brand appears in ChatGPT, Claude, Gemini, Perplexity, and Google AI Overviews with AmICited's comprehensive AI brand visibility monitoring platform.
Learn how to build and use prompt libraries for manual AI visibility testing. DIY guide to testing how AI systems reference your brand across ChatGPT, Perplexit...

Learn how to create and organize an effective prompt library to track your brand across ChatGPT, Perplexity, and Google AI. Step-by-step guide with best practic...

Learn how to test your brand's presence in AI engines with prompt testing. Discover manual and automated methods to monitor AI visibility across ChatGPT, Perple...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.