
Hacked Content - Compromised Website Content
Hacked content is unauthorized website material altered by cybercriminals. Learn how compromised websites affect SEO, AI search results, and brand reputation wi...
12 min read

A scraper site is a website that automatically copies content from other sources without permission and republishes it, often with minimal modifications. These sites use automated bots to harvest data, text, images, and other content from legitimate websites to populate their own pages, typically for fraudulent purposes, plagiarism, or to generate ad revenue.
A scraper site is a website that automatically copies content from other sources without permission and republishes it, often with minimal modifications. These sites use automated bots to harvest data, text, images, and other content from legitimate websites to populate their own pages, typically for fraudulent purposes, plagiarism, or to generate ad revenue.
A scraper site is a website that automatically copies content from other sources without permission and republishes it, often with minimal modifications or paraphrasing. These sites use automated bots to harvest data, text, images, product descriptions, and other content from legitimate websites to populate their own pages. The practice is technically illegal under copyright law and violates the terms of service of most websites. Content scraping is fundamentally different from legitimate web scraping because it involves unauthorized copying of published content for malicious purposes, including fraud, plagiarism, ad revenue generation, and intellectual property theft. The automated nature of scraping allows bad actors to copy thousands of pages in minutes, creating massive duplicate content problems across the internet.
Content scraping has existed since the early days of the internet, but the problem has escalated dramatically with advances in automation technology and artificial intelligence. In the early 2000s, scrapers were relatively simple and easy to detect. However, modern scraper bots have become increasingly sophisticated, using techniques like paraphrasing algorithms, rotating IP addresses, and browser automation to evade detection. The rise of AI-powered content generation has made the problem worse, as scrapers now use machine learning to rewrite stolen content in ways that are harder to identify as duplicates. According to industry reports, scraper sites account for a significant portion of malicious bot traffic, with some estimates suggesting that automated bots represent over 40% of all internet traffic. The emergence of AI search engines like ChatGPT, Perplexity, and Google AI Overviews has created new challenges, as these systems may inadvertently cite scraper sites instead of original content creators, further amplifying the problem.
Scraper bots function through a multi-step automated process that requires minimal human intervention. First, the bot crawls target websites by following links and accessing pages, downloading the HTML code and all associated content. The bot then parses the HTML to extract relevant data such as article text, images, metadata, and product information. This extracted content is stored in a database, where it may be processed further using paraphrasing tools or AI-powered rewriting software to create variations that appear different from the original. Finally, the scraped content is republished on the scraper site, often with minimal attribution or with false authorship claims. Some sophisticated scrapers use rotating proxies and user-agent spoofing to disguise their requests as legitimate human traffic, making them harder to detect and block. The entire process can be fully automated, allowing a single scraper operation to copy thousands of pages daily from multiple websites simultaneously.
| Aspect | Scraper Site | Original Content Site | Legitimate Data Aggregator |
|---|---|---|---|
| Content Origin | Copied without permission | Created originally | Curated with attribution and links |
| Legal Status | Illegal (copyright violation) | Protected by copyright | Legal (with proper licensing) |
| Attribution | Minimal or false | Original author credited | Sources cited and linked |
| Purpose | Fraud, plagiarism, ad revenue | Provide value to audience | Aggregate and organize information |
| SEO Impact | Negative (duplicate content) | Positive (original content) | Neutral to positive (with proper canonicalization) |
| User Experience | Poor (low-quality content) | High (unique, valuable content) | Good (organized, sourced content) |
| Terms of Service | Violates ToS | Complies with own ToS | Respects website ToS and robots.txt |
| Detection Methods | IP tracking, bot signatures | N/A | Transparent crawling patterns |
Scraper sites operate on several distinct business models, all designed to generate revenue from stolen content. The most common model is ad-based monetization, where scrapers fill their pages with advertisements from networks like Google AdSense or other ad exchanges. By republishing popular content, scrapers attract organic search traffic and generate ad impressions and clicks without creating any original value. Another prevalent model is ecommerce fraud, where scrapers create fake online stores that mimic legitimate retailers, copying product descriptions, images, and pricing information. Unsuspecting customers purchase from these fraudulent sites, either receiving counterfeit products or having their payment information stolen. Email harvesting is another significant scraper business model, where contact information is extracted from websites and sold to spammers or used for targeted phishing campaigns. Some scrapers also engage in affiliate marketing fraud, copying product reviews and content while inserting their own affiliate links to earn commissions. The low operational costs of scraping—requiring only server space and automated software—make these business models highly profitable despite their illegal nature.
The consequences of content scraping for original creators are severe and multifaceted. When scrapers republish your content on their domains, they create duplicate content that confuses search engines about which version is the original. Google’s algorithm may struggle to identify the authoritative source, potentially causing both the original and scraped versions to rank lower in search results. This directly impacts organic traffic, as your carefully optimized content loses visibility to scraper sites that contributed nothing to its creation. Beyond search rankings, scrapers distort your website analytics by generating fake traffic from bots, making it difficult to understand genuine user behavior and engagement metrics. Your server resources are also wasted processing requests from scraper bots, increasing bandwidth costs and potentially slowing your site for legitimate visitors. The negative SEO impact extends to your domain authority and backlink profile, as scrapers may create low-quality links pointing to your site or use your content in spam contexts. Additionally, when scrapers rank higher than your original content in search results, you lose the opportunity to establish thought leadership and authority in your industry, damaging your brand reputation and credibility.
Identifying scraper sites requires a combination of manual and automated approaches. Google Alerts is one of the most effective free tools, allowing you to monitor your article titles, unique phrases, and brand name for unauthorized republication. When Google Alerts notifies you of a match, you can investigate whether it’s a legitimate citation or a scraper site. Pingback monitoring is particularly useful for WordPress sites, as pingbacks are generated whenever another site links to your content. If you receive pingbacks from unfamiliar or suspicious domains, they may be scraper sites that have copied your internal links. SEO tools like Ahrefs, SEM Rush, and Grammarly offer duplicate content detection features that scan the web for pages matching your content. These tools can identify both exact duplicates and paraphrased versions of your articles. Server log analysis provides technical insights into bot traffic patterns, revealing suspicious IP addresses, unusual request rates, and bot user-agent strings. Reverse image search using Google Images or TinEye can help identify where your images have been republished without permission. Regular monitoring of your Google Search Console can reveal indexing anomalies and duplicate content issues that may indicate scraping activity.
Content scraping violates multiple layers of legal protection, making it one of the most prosecutable forms of online fraud. Copyright law automatically protects all original content, whether published online or in print, giving creators exclusive rights to reproduce, distribute, and display their work. Scraping content without permission is direct copyright infringement, exposing scrapers to civil liability including damages and injunctions. The Digital Millennium Copyright Act (DMCA) provides additional protection by prohibiting circumvention of technological measures that control access to copyrighted works. If you implement access controls or anti-scraping measures, the DMCA makes it illegal to bypass them. The Computer Fraud and Abuse Act (CFAA) can also apply to scraping, particularly when bots access systems without authorization or exceed authorized access. Website terms of service explicitly prohibit scraping, and violating these terms can result in legal action for breach of contract. Many content creators have successfully pursued legal action against scrapers, obtaining court orders to remove content and cease scraping activities. Some jurisdictions have also recognized scraping as a form of unfair competition, allowing businesses to sue for damages based on lost revenue and market harm.
The emergence of AI search engines and large language models (LLMs) has created a new dimension to the scraper site problem. When AI systems like ChatGPT, Perplexity, Google AI Overviews, and Claude crawl the web to gather training data or generate responses, they may encounter scraper sites alongside original content. If the scraper site appears more frequently or has better technical SEO, the AI system may cite the scraper instead of the original source. This is particularly problematic because AI citations carry significant weight in determining brand visibility and authority. When a scraper site is cited in an AI response instead of your original content, you lose the opportunity to establish your brand as an authoritative source in AI-driven search results. Additionally, scrapers may introduce inaccuracies or outdated information into AI training data, potentially causing AI systems to generate incorrect or misleading responses. The problem is compounded by the fact that many AI systems don’t provide transparent source attribution, making it difficult for users to verify whether they’re reading original content or scraped material. Monitoring tools like AmICited help content creators track where their brand and content appear across AI platforms, identifying when scrapers are competing for visibility in AI responses.
Protecting your content from scraping requires a multi-layered technical and operational approach. Bot detection and blocking tools like ClickCease’s Bot Zapping can identify and block malicious bots before they access your content, directing them to error pages instead of your actual pages. Robots.txt configuration allows you to restrict bot access to specific directories or pages, though determined scrapers may ignore these directives. Noindex tags can be applied to sensitive pages or automatically generated content (like WordPress tag and category pages) to prevent them from being indexed and scraped. Content gating requires users to fill out forms or log in to access premium content, making it harder for bots to harvest information at scale. Rate limiting on your server restricts the number of requests from a single IP address within a time period, slowing down scraper bots and making their operations less efficient. CAPTCHA challenges can verify that requests come from humans rather than bots, though sophisticated bots can sometimes bypass these. Server-side monitoring of request patterns helps identify suspicious activity, allowing you to block problematic IP addresses proactively. Regular backups of your content ensure you have evidence of original creation dates, which is valuable if you need to pursue legal action against scrapers.
The scraper landscape continues to evolve as technology advances and new opportunities emerge. AI-powered paraphrasing is becoming increasingly sophisticated, making scraped content harder to detect as duplicates through traditional plagiarism detection tools. Scrapers are investing in more advanced proxy rotation and browser automation techniques to evade bot detection systems. The rise of AI training data scraping represents a new frontier, where scrapers target content specifically for use in training machine learning models, often without any compensation to original creators. Some scrapers are now using headless browsers and JavaScript rendering to access dynamic content that traditional scrapers couldn’t reach. The integration of scraping with affiliate marketing networks and ad fraud schemes is creating more complex and harder-to-detect scraper operations. However, there are also positive developments: AI detection systems are becoming better at identifying scraped content, and search engines are increasingly penalizing scraper sites in their algorithms. The November 2024 Google core update specifically targeted scraper sites, resulting in significant visibility losses for many scraper domains. Content creators are also adopting watermarking technologies and blockchain-based verification to prove original creation and ownership. As AI search engines mature, they are implementing better source attribution and transparency mechanisms to ensure original creators receive proper credit and visibility.
For content creators and brand managers, the challenge of scraper sites extends beyond traditional search engines to the emerging landscape of AI-powered search and response systems. AmICited provides specialized monitoring for tracking where your brand, content, and domain appear across AI platforms including Perplexity, ChatGPT, Google AI Overviews, and Claude. By monitoring your AI visibility, you can identify when scraper sites are competing for citations in AI responses, when your original content is being properly attributed, and when unauthorized copies are gaining traction. This intelligence allows you to take proactive steps to protect your intellectual property and maintain your brand authority in AI-driven search results. Understanding the distinction between legitimate content aggregation and malicious scraping is crucial in the AI era, as the stakes for brand visibility and authority have never been higher.
Yes, content scraping is technically illegal in most jurisdictions. It violates copyright laws that protect digital content the same way they protect physical publications. Additionally, scraping often violates the terms of service of websites and can trigger legal action under the Digital Millennium Copyright Act (DMCA) and the Computer Fraud and Abuse Act (CFAA). Website owners can pursue civil and criminal liability against scrapers.
Scraper sites negatively impact SEO in multiple ways. When duplicate content from scrapers ranks higher than the original, it dilutes the original site's search visibility and organic traffic. Google's algorithm struggles to identify which version is the original, potentially causing all versions to rank lower. Additionally, scrapers waste your site's crawl budget and can distort your analytics, making it difficult to understand genuine user behavior and performance metrics.
Scraper sites serve several malicious purposes: creating fake ecommerce stores to commit fraud, hosting spoofed websites that mimic legitimate brands, generating ad revenue through fraudulent traffic, plagiarizing content to fill pages without effort, and harvesting email lists and contact information for spam campaigns. Some scrapers also target pricing information, product details, and social media content for competitive intelligence or resale.
You can detect scraped content using several methods: set up Google Alerts for your article titles or unique phrases, search your content titles in Google to see if duplicates appear, check for pingbacks on internal links (especially in WordPress), use SEO tools like Ahrefs or SEM Rush to find duplicate content, and monitor your website's traffic patterns for unusual bot activity. Regular monitoring helps you identify scrapers quickly.
Web scraping is a broader technical term for extracting data from websites, which can be legitimate when done with permission for research or data analysis. Content scraping specifically refers to the unauthorized copying of published content like articles, product descriptions, and images for republication. While web scraping can be legal, content scraping is inherently malicious and illegal because it violates copyright and terms of service.
Scraper bots use automated software to crawl websites, download HTML content, extract text and images, and store them in databases. These bots simulate human browsing behavior to bypass basic detection methods. They can access both publicly visible content and sometimes hidden databases if security is weak. The harvested data is then processed, sometimes paraphrased using AI tools, and republished on scraper sites with minimal modifications to avoid exact duplicate detection.
Effective prevention strategies include implementing bot detection and blocking tools, using robots.txt to restrict bot access, adding noindex tags to sensitive pages, gating premium content behind login forms, monitoring your site regularly with Google Alerts and SEO tools, using CAPTCHA challenges, implementing rate limiting on your server, and monitoring your server logs for suspicious IP addresses and traffic patterns. A multi-layered approach is most effective.
Scraper sites pose a significant challenge for AI search engines like ChatGPT, Perplexity, and Google AI Overviews. When AI systems crawl the web for training data or to generate responses, they may encounter scraped content and cite scraper sites instead of original sources. This dilutes the visibility of legitimate content creators in AI responses and can cause AI systems to propagate misinformation. Monitoring tools like AmICited help track where your brand and content appear across AI platforms.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Hacked content is unauthorized website material altered by cybercriminals. Learn how compromised websites affect SEO, AI search results, and brand reputation wi...

Duplicate content is identical or similar content on multiple URLs that confuses search engines and dilutes ranking authority. Learn how it affects SEO, AI visi...
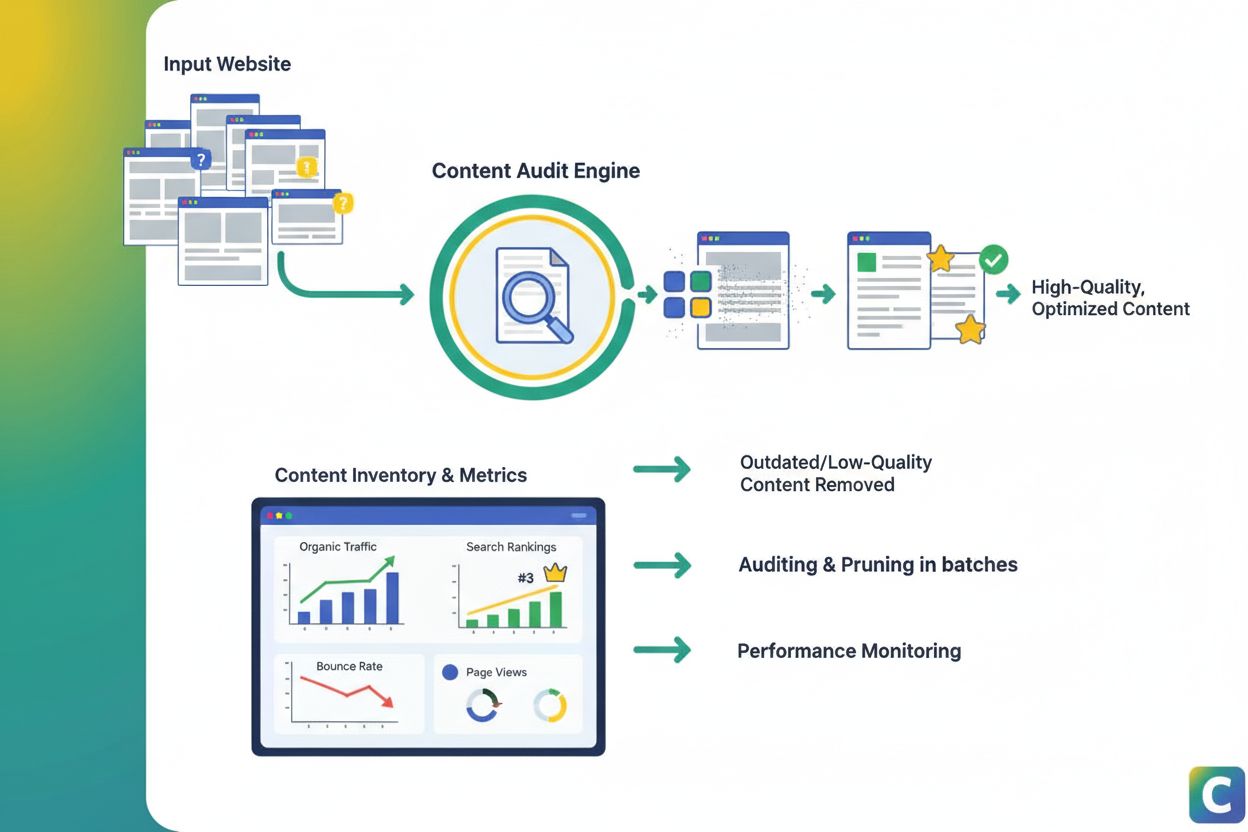
Content pruning is the strategic removal or updating of underperforming content to improve SEO, user experience, and search visibility. Learn how to identify an...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.