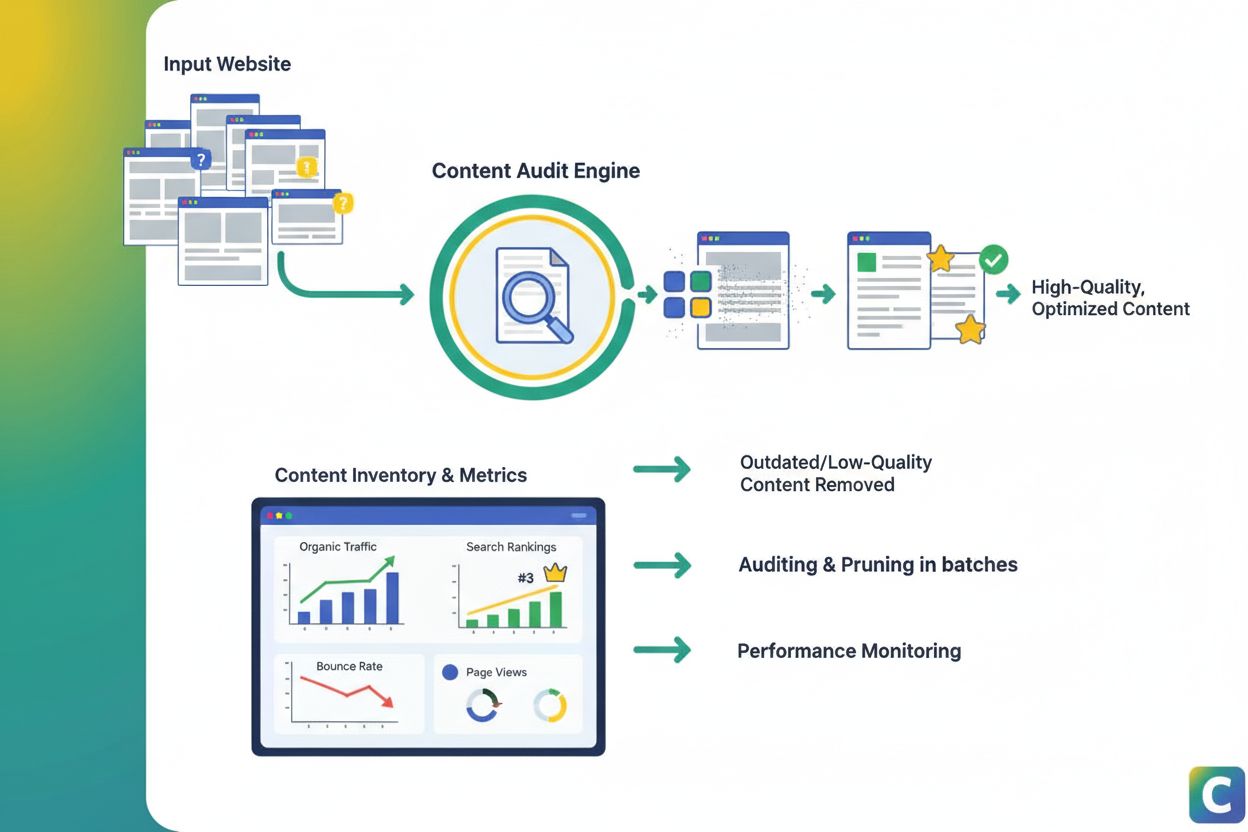
Poda de Contenido
La poda de contenido es la eliminación estratégica o actualización de contenido con bajo rendimiento para mejorar el SEO, la experiencia del usuario y la visibi...
18 min de lectura

Un sitio scraper es un sitio web que copia automáticamente contenido de otras fuentes sin permiso y lo vuelve a publicar, a menudo con modificaciones mínimas. Estos sitios utilizan bots automatizados para recolectar datos, textos, imágenes y otros contenidos de sitios web legítimos para poblar sus propias páginas, generalmente con fines fraudulentos, plagio o para generar ingresos por publicidad.
Un sitio scraper es un sitio web que copia automáticamente contenido de otras fuentes sin permiso y lo vuelve a publicar, a menudo con modificaciones mínimas. Estos sitios utilizan bots automatizados para recolectar datos, textos, imágenes y otros contenidos de sitios web legítimos para poblar sus propias páginas, generalmente con fines fraudulentos, plagio o para generar ingresos por publicidad.
Un sitio scraper es un sitio web que copia automáticamente contenido de otras fuentes sin permiso y lo vuelve a publicar, a menudo con modificaciones mínimas o parafraseo. Estos sitios utilizan bots automatizados para recolectar datos, textos, imágenes, descripciones de productos y otros contenidos de sitios legítimos para poblar sus propias páginas. Esta práctica es técnicamente ilegal según la ley de derechos de autor y viola los términos de servicio de la mayoría de los sitios web. El raspado de contenido es fundamentalmente diferente del raspado web legítimo, ya que implica la copia no autorizada de contenido publicado con fines maliciosos, como fraude, plagio, generación de ingresos por publicidad y robo de propiedad intelectual. La naturaleza automatizada del scraping permite a los actores maliciosos copiar miles de páginas en minutos, creando problemas masivos de contenido duplicado en todo internet.
El raspado de contenido existe desde los primeros días de internet, pero el problema se ha incrementado dramáticamente con los avances en la automatización y la inteligencia artificial. A principios de los 2000, los scrapers eran relativamente simples y fáciles de detectar. Sin embargo, los bots scraper modernos se han vuelto cada vez más sofisticados, utilizando técnicas como algoritmos de parafraseo, rotación de direcciones IP y automatización de navegadores para evadir la detección. El auge de la generación de contenido impulsada por IA ha empeorado el problema, ya que los scrapers ahora emplean aprendizaje automático para reescribir contenido robado de formas más difíciles de identificar como duplicados. Según informes de la industria, los sitios scraper representan una parte significativa del tráfico malicioso de bots, con algunas estimaciones que sugieren que los bots automatizados representan más del 40% de todo el tráfico en internet. La aparición de motores de búsqueda de IA como ChatGPT, Perplexity y Google AI Overviews ha creado nuevos desafíos, ya que estos sistemas pueden citar inadvertidamente sitios scraper en lugar de a los creadores originales, amplificando aún más el problema.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Los bots scraper funcionan mediante un proceso automatizado de varios pasos que requiere mínima intervención humana. Primero, el bot rastrea los sitios objetivo siguiendo enlaces y accediendo a páginas, descargando el código HTML y todo el contenido asociado. Luego, el bot analiza el HTML para extraer datos relevantes como texto de artículos, imágenes, metadatos e información de productos. Este contenido extraído se almacena en una base de datos, donde puede ser procesado usando herramientas de parafraseo o software de reescritura impulsado por IA para crear variaciones que parezcan diferentes del original. Finalmente, el contenido copiado se vuelve a publicar en el sitio scraper, a menudo con atribución mínima o con afirmaciones de autoría falsas. Algunos scrapers sofisticados utilizan proxies rotativos y falsificación de agente de usuario para disfrazar sus solicitudes como si fueran tráfico humano legítimo, haciendo más difícil su detección y bloqueo. Todo el proceso puede estar totalmente automatizado, permitiendo que una sola operación de scraper copie miles de páginas diarias de múltiples sitios a la vez.
| Aspecto | Sitio Scraper | Sitio de Contenido Original | Agregador de Datos Legítimo |
|---|---|---|---|
| Origen del Contenido | Copiado sin permiso | Creado originalmente | Curado con atribución y enlaces |
| Estatus Legal | Ilegal (violación de derechos de autor) | Protegido por derechos de autor | Legal (con licencia adecuada) |
| Atribución | Mínima o falsa | Se acredita al autor original | Fuentes citadas y enlazadas |
| Propósito | Fraude, plagio, ingresos por publicidad | Aportar valor a la audiencia | Agregar y organizar información |
| Impacto SEO | Negativo (contenido duplicado) | Positivo (contenido original) | Neutral a positivo (con canonización adecuada) |
| Experiencia del Usuario | Pobre (contenido de baja calidad) | Alta (contenido único y valioso) | Buena (contenido organizado y con fuentes) |
| Términos de Servicio | Viola los ToS | Cumple con sus propios ToS | Respeta los ToS del sitio web y robots.txt |
| Métodos de Detección | Rastreo de IP, firmas de bots | N/A | Patrones de rastreo transparentes |
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Los sitios scraper operan bajo varios modelos de negocio, todos diseñados para generar ingresos a partir de contenido robado. El modelo más común es la monetización publicitaria, donde los scrapers llenan sus páginas de anuncios de redes como Google AdSense u otros intercambios publicitarios. Al volver a publicar contenido popular, los scrapers atraen tráfico orgánico y generan impresiones y clics sin aportar ningún valor original. Otro modelo prevalente es el fraude en comercio electrónico, donde los scrapers crean tiendas falsas que imitan a minoristas legítimos, copiando descripciones, imágenes e información de precios de productos. Los clientes desprevenidos compran en estos sitios fraudulentos, recibiendo productos falsificados o viendo cómo se roba su información de pago. La recolección de correos electrónicos es otro modelo significativo, donde se extrae información de contacto de sitios web para venderla a spammers o usarla en campañas de phishing. Algunos scrapers también participan en fraudes de marketing de afiliados, copiando reseñas y contenido mientras insertan sus propios enlaces de afiliado para ganar comisiones. Los bajos costos operativos del scraping—requiriendo solo espacio en servidores y software automatizado—hacen que estos modelos sean altamente rentables a pesar de su ilegalidad.
Las consecuencias del raspado de contenido para los creadores originales son severas y multifacéticas. Cuando los scrapers republican su contenido en sus propios dominios, crean contenido duplicado que confunde a los motores de búsqueda sobre cuál versión es la original. El algoritmo de Google puede tener dificultades para identificar la fuente autorizada, lo que puede provocar que tanto la versión original como la copiada bajen en los resultados de búsqueda. Esto impacta directamente el tráfico orgánico, ya que el contenido cuidadosamente optimizado pierde visibilidad frente a sitios scraper que no contribuyeron a su creación. Más allá del posicionamiento, los scrapers distorsionan sus analíticas generando tráfico falso de bots, dificultando la comprensión del comportamiento real de los usuarios y las métricas de engagement. Sus recursos de servidor también se desperdician procesando solicitudes de bots scraper, incrementando los costos de ancho de banda y potencialmente ralentizando su sitio para los visitantes legítimos. El impacto negativo en SEO se extiende a la autoridad de dominio y el perfil de enlaces, ya que los scrapers pueden crear enlaces de baja calidad hacia su sitio o usar su contenido en contextos de spam. Además, cuando los scrapers se posicionan por encima de su contenido original en los resultados de búsqueda, pierde la oportunidad de establecer liderazgo de pensamiento y autoridad en su industria, dañando la reputación y credibilidad de su marca.
Identificar sitios scraper requiere una combinación de enfoques manuales y automatizados. Google Alerts es una de las herramientas gratuitas más efectivas, permitiéndole monitorear títulos de artículos, frases únicas y su marca para detectar publicaciones no autorizadas. Cuando Google Alerts le notifique una coincidencia, podrá investigar si se trata de una cita legítima o de un sitio scraper. El monitoreo de pingbacks es especialmente útil en sitios WordPress, ya que se generan pingbacks cada vez que otro sitio enlaza su contenido. Si recibe pingbacks de dominios desconocidos o sospechosos, pueden ser sitios scraper que han copiado sus enlaces internos. Las herramientas SEO como Ahrefs, SEM Rush y Grammarly ofrecen funciones de detección de contenido duplicado que exploran la web en busca de páginas coincidentes. Estas herramientas pueden identificar tanto duplicados exactos como versiones parafraseadas de sus artículos. El análisis de registros del servidor brinda información técnica sobre patrones de tráfico de bots, revelando direcciones IP sospechosas, tasas inusuales de solicitudes y cadenas de agentes de usuario de bots. La búsqueda inversa de imágenes con Google Imágenes o TinEye puede ayudarle a identificar dónde se han republicado sus imágenes sin permiso. El monitoreo regular de su Google Search Console puede revelar anomalías de indexación y problemas de contenido duplicado que indican actividad de scraping.
El raspado de contenido viola múltiples capas de protección legal, siendo una de las formas de fraude en línea más perseguibles. La ley de derechos de autor protege automáticamente todo contenido original, ya sea publicado en línea o impreso, otorgando a los creadores derechos exclusivos de reproducción, distribución y exhibición. Copiar contenido sin permiso es una infracción directa, exponiendo a los scrapers a responsabilidad civil, incluyendo daños e indemnizaciones. La Ley de Derechos de Autor Digital Millennium (DMCA) brinda protección adicional al prohibir la elusión de medidas tecnológicas que controlan el acceso a obras protegidas. Si implementa controles de acceso o medidas anti-scraping, la DMCA hace ilegal eludirlos. La Ley de Fraude y Abuso Informático (CFAA) también puede aplicarse, especialmente cuando los bots acceden a sistemas sin autorización o exceden el acceso permitido. Los términos de servicio de los sitios web prohíben explícitamente el scraping, y violarlos puede resultar en acciones legales por incumplimiento de contrato. Muchos creadores han logrado acciones legales exitosas contra scrapers, obteniendo órdenes judiciales para eliminar contenido y cesar actividades. Algunas jurisdicciones incluso han reconocido el scraping como competencia desleal, permitiendo reclamar daños por pérdida de ingresos y perjuicio de mercado.
La aparición de motores de búsqueda de IA y modelos de lenguaje de gran escala (LLMs) ha añadido una nueva dimensión al problema de los sitios scraper. Cuando sistemas de IA como ChatGPT, Perplexity, Google AI Overviews y Claude rastrean la web para recolectar datos de entrenamiento o generar respuestas, pueden encontrar sitios scraper junto a contenido original. Si el sitio scraper aparece con más frecuencia o tiene mejor SEO técnico, el sistema de IA puede citar al scraper en lugar de la fuente original. Esto es especialmente problemático porque las citas de IA tienen gran peso en la visibilidad y autoridad de marca. Cuando un sitio scraper es citado en una respuesta de IA en lugar de su contenido original, pierde la oportunidad de establecer su marca como fuente autorizada en búsquedas impulsadas por IA. Además, los scrapers pueden introducir inexactitudes o información desactualizada en los datos de entrenamiento de IA, provocando respuestas incorrectas o engañosas. El problema se agrava porque muchos sistemas de IA no proporcionan atribución transparente, dificultando verificar si se está leyendo contenido original o copiado. Herramientas de monitoreo como AmICited ayudan a los creadores a rastrear dónde aparece su marca y contenido en plataformas de IA, identificando cuándo los scrapers compiten por visibilidad en respuestas de IA.
Proteger su contenido del scraping requiere un enfoque técnico y operativo de múltiples capas. Herramientas de detección y bloqueo de bots como Bot Zapping de ClickCease pueden identificar y bloquear bots maliciosos antes de que accedan a su contenido, redirigiéndolos a páginas de error en vez de las reales. La configuración de robots.txt le permite restringir el acceso de bots a directorios o páginas específicas, aunque los scrapers determinados pueden ignorar estas directivas. Las etiquetas noindex pueden aplicarse a páginas sensibles o contenido generado automáticamente (como páginas de etiquetas y categorías en WordPress) para evitar que sean indexadas y copiadas. El contenido protegido requiere que los usuarios llenen formularios o inicien sesión para acceder a contenido premium, dificultando la recolección masiva de información por parte de bots. El limitador de velocidad en su servidor restringe el número de solicitudes desde una IP en un periodo, ralentizando los bots scraper y haciendo menos eficientes sus operaciones. Los desafíos CAPTCHA pueden verificar que las solicitudes provengan de humanos y no de bots, aunque los más sofisticados pueden a veces eludirlos. El monitoreo del lado del servidor de los patrones de solicitudes ayuda a identificar actividad sospechosa, permitiéndole bloquear IPs problemáticas proactivamente. Las copias de seguridad regulares de su contenido le garantizan evidencia de fechas de creación original, útil si necesita emprender acciones legales contra scrapers.
El panorama de los scrapers sigue evolucionando a medida que la tecnología avanza y surgen nuevas oportunidades. El parafraseo impulsado por IA es cada vez más sofisticado, haciendo que el contenido copiado sea más difícil de detectar como duplicado mediante herramientas tradicionales de plagio. Los scrapers están invirtiendo en rotación avanzada de proxies y automatización de navegadores para evadir los sistemas de detección de bots. El auge del raspado de datos para entrenamiento de IA representa una nueva frontera, en la que los scrapers buscan contenido específicamente para entrenar modelos de aprendizaje automático, a menudo sin compensar al creador original. Algunos scrapers emplean navegadores sin cabeza y renderizado de JavaScript para acceder a contenido dinámico que los scrapers tradicionales no podían alcanzar. La integración del scraping con redes de marketing de afiliados y esquemas de fraude publicitario está creando operaciones scraper más complejas y difíciles de detectar. Sin embargo, también hay avances positivos: los sistemas de detección IA mejoran en la identificación de contenido copiado y los motores de búsqueda penalizan cada vez más a los sitios scraper en sus algoritmos. La actualización central de Google de noviembre de 2024 apuntó específicamente a los sitios scraper, provocando importantes pérdidas de visibilidad para muchos dominios de este tipo. Los creadores de contenido también están adoptando tecnologías de marca de agua y verificación basada en blockchain para probar la autoría y creación original. A medida que los motores de búsqueda IA maduran, están implementando mejor atribución y mecanismos de transparencia para garantizar que los creadores reciban el crédito y la visibilidad adecuados.
Para creadores de contenido y gestores de marca, el desafío de los sitios scraper va más allá de los motores de búsqueda tradicionales y se extiende al emergente panorama de búsqueda y sistemas de respuestas impulsados por IA. AmICited ofrece monitoreo especializado para rastrear dónde aparece su marca, contenido y dominio en plataformas de IA como Perplexity, ChatGPT, Google AI Overviews y Claude. Monitoreando su visibilidad en IA, puede identificar cuándo los sitios scraper compiten por citas en respuestas de IA, cuándo su contenido original está siendo correctamente atribuido y cuándo las copias no autorizadas ganan tracción. Esta inteligencia le permite tomar medidas proactivas para proteger su propiedad intelectual y mantener la autoridad de su marca en los resultados de búsqueda impulsados por IA. Entender la distinción entre la agregación legítima de contenido y el scraping malicioso es crucial en la era de la IA, ya que la visibilidad y la autoridad de marca nunca han sido tan importantes.
Comienza a rastrear cómo los chatbots de IA mencionan tu marca en ChatGPT, Perplexity y otras plataformas. Obtén información procesable para mejorar tu presencia en IA.
La poda de contenido es la eliminación estratégica o actualización de contenido con bajo rendimiento para mejorar el SEO, la experiencia del usuario y la visibi...

Aprende cómo implementar las etiquetas meta noai y noimageai para controlar el acceso de rastreadores de IA al contenido de tu sitio web. Guía completa sobre en...

El contenido hackeado es material web no autorizado alterado por ciberdelincuentes. Descubre cómo los sitios comprometidos afectan el SEO, los resultados de bús...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.