
Crawler AI spiegati: GPTBot, ClaudeBot e altri
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...
15 min di lettura

Scopri come i crawler AI influenzano le risorse del server, la banda e le prestazioni. Approfondisci statistiche reali, strategie di mitigazione e soluzioni infrastrutturali per gestire efficacemente il carico dei bot.
I crawler AI sono diventati una forza significativa nel traffico web, con le principali aziende AI che distribuiscono bot sofisticati per indicizzare i contenuti a fini di addestramento e recupero. Questi crawler operano su larga scala, generando circa 569 milioni di richieste al mese nel web e consumando oltre 30TB di banda a livello globale. I principali crawler AI includono GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) e Amazonbot (Amazon), ognuno con modelli di crawling e richieste di risorse distinti. Comprendere il comportamento e le caratteristiche di questi crawler è essenziale per gli amministratori di siti web per gestire correttamente le risorse del server e prendere decisioni informate sulle politiche di accesso.
| Nome Crawler | Azienda | Scopo | Modello di richiesta |
|---|---|---|---|
| GPTBot | OpenAI | Dati di addestramento per ChatGPT e modelli GPT | Aggressivo, richieste ad alta frequenza |
| ClaudeBot | Anthropic | Dati di addestramento per modelli Claude AI | Frequenza moderata, crawling rispettoso |
| PerplexityBot | Perplexity AI | Ricerca in tempo reale e generazione di risposte | Frequenza da moderata ad alta |
| Google-Extended | Indicizzazione estesa per funzionalità AI | Controllato, segue robots.txt | |
| Amazonbot | Amazon | Indicizzazione prodotti e contenuti | Variabile, focalizzato sul commercio |
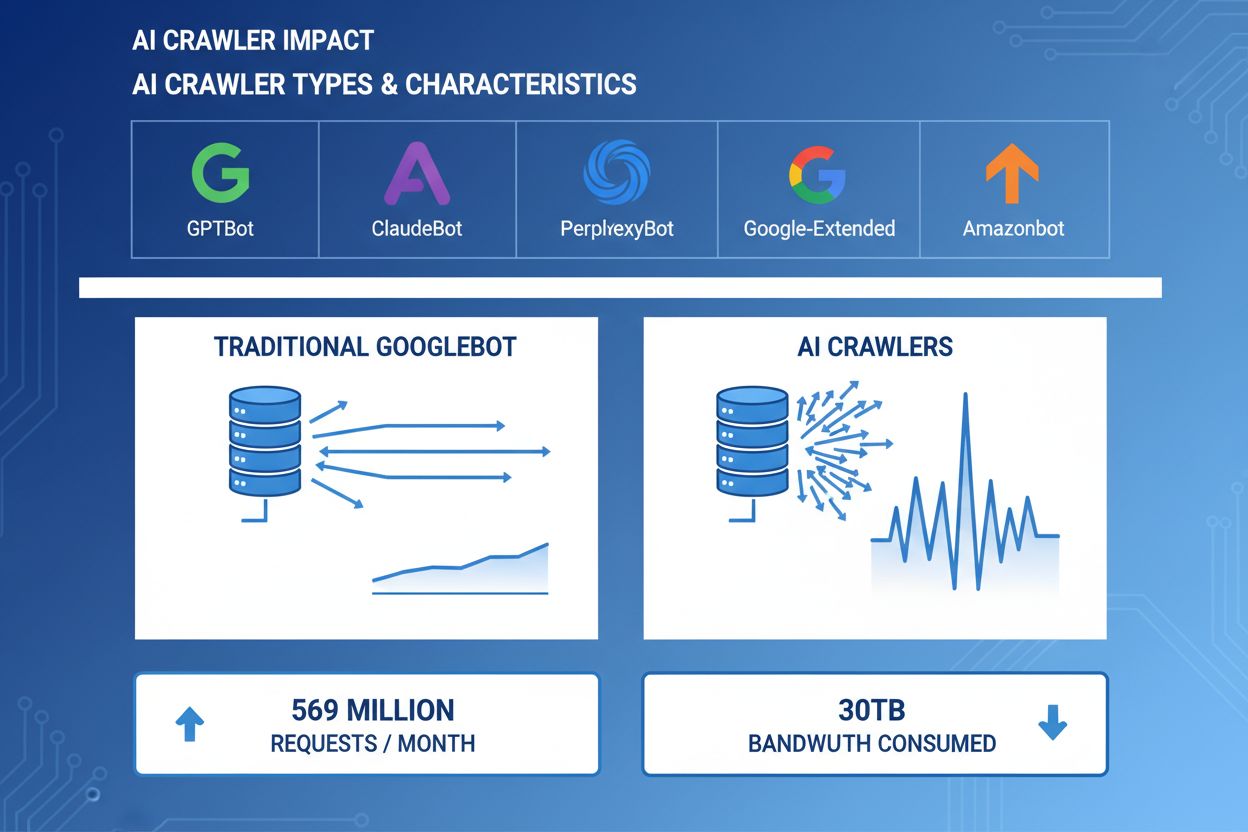
I crawler AI consumano risorse del server su più fronti, creando impatti misurabili sulle prestazioni dell’infrastruttura. L’utilizzo della CPU può aumentare del 300% o più durante il picco di attività dei crawler, poiché i server elaborano migliaia di richieste simultanee e analizzano contenuti HTML. Il consumo di banda rappresenta uno dei costi più visibili: un singolo sito popolare può servire gigabyte di dati ai crawler ogni giorno. L’utilizzo della memoria aumenta significativamente poiché i server mantengono pool di connessioni e bufferizzano grandi quantità di dati per l’elaborazione. Le query al database si moltiplicano quando i crawler richiedono pagine che generano contenuti dinamici, creando ulteriore pressione su I/O. L’I/O del disco diventa un collo di bottiglia quando i server devono leggere dai dischi per servire le richieste dei crawler, specialmente per siti con grandi librerie di contenuti.
| Risorsa | Impatto | Esempio reale |
|---|---|---|
| CPU | Picchi del 200-300% durante il crawling | Media del carico server da 2.0 a 8.0 |
| Banda | 15-40% del consumo mensile totale | Sito da 500GB che serve 150GB ai crawler al mese |
| Memoria | Aumento del 20-30% nel consumo RAM | Server da 8GB che richiede 10GB durante attività crawler |
| Database | 2-5x aumento del carico query | Tempi di risposta query da 50ms a 250ms |
| I/O Disco | Operazioni di lettura sostenute elevate | Utilizzo disco da 30% a 85% |
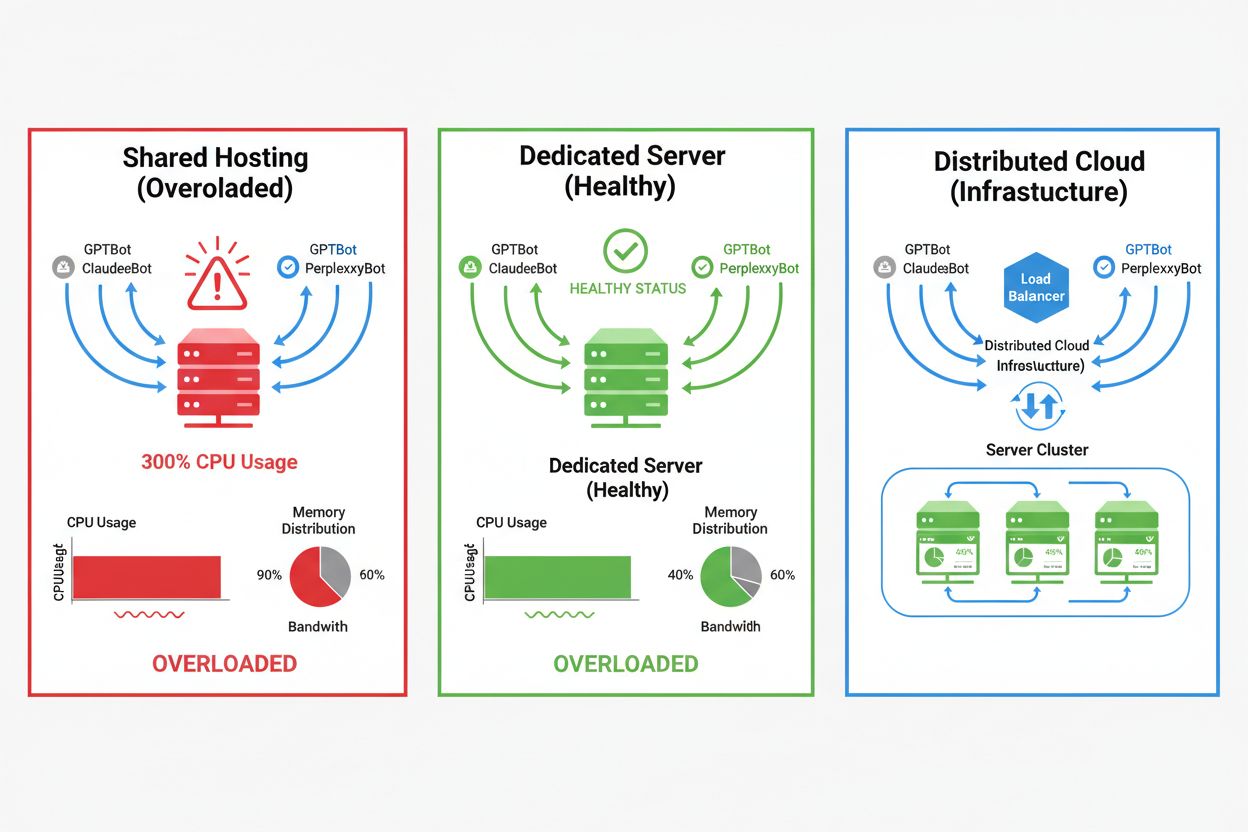
L’impatto dei crawler AI varia notevolmente a seconda dell’ambiente di hosting, con gli ambienti condivisi che subiscono le conseguenze più gravi. Negli scenari di hosting condiviso, la “noisy neighbor syndrome” diventa particolarmente problematica—quando un sito su un server condiviso attira molto traffico di crawler, consuma risorse che sarebbero altrimenti disponibili per altri siti ospitati, degradando le prestazioni per tutti gli utenti. I server dedicati e l’infrastruttura cloud offrono migliore isolamento e garanzie sulle risorse, consentendo di assorbire traffico da crawler senza influenzare altri servizi. Tuttavia, anche l’infrastruttura dedicata richiede monitoraggio attento e scalabilità per gestire il carico cumulativo da più crawler AI attivi contemporaneamente.
Principali differenze tra ambienti di hosting:
L’impatto finanziario del traffico dei crawler AI va oltre i semplici costi di banda, comprendendo sia spese dirette che nascoste che possono incidere significativamente sui profitti. I costi diretti includono l’aumento dei costi di banda dal provider di hosting, che possono aggiungere centinaia o migliaia di euro al mese a seconda del volume di traffico e dell’intensità dei crawler. I costi nascosti emergono tramite maggiori richieste infrastrutturali—potresti dover passare a piani hosting superiori, implementare ulteriori livelli di caching o investire in servizi CDN appositamente per gestire il traffico dei crawler. Il calcolo del ROI diventa complesso considerando che i crawler AI forniscono valore diretto minimo alla tua attività mentre consumano risorse che potrebbero servire clienti paganti o migliorare l’esperienza utente. Molti proprietari di siti scoprono che il costo di ospitare il traffico dei crawler supera qualsiasi potenziale beneficio dall’addestramento dei modelli AI o dalla visibilità nei risultati di ricerca basati su AI.
Il traffico dei crawler AI degrada direttamente l’esperienza degli utenti legittimi consumando risorse del server che altrimenti servirebbero più velocemente gli utenti umani. Le metriche Core Web Vitals peggiorano sensibilmente, con il Largest Contentful Paint (LCP) che aumenta di 200-500ms e il Time to First Byte (TTFB) che peggiora di 100-300ms durante periodi di intensa attività dei crawler. Questi peggioramenti delle performance innescano effetti negativi a catena: caricamenti più lenti riducono l’engagement, aumentano il bounce rate e diminuiscono i tassi di conversione per siti e-commerce o lead-generation. Anche il posizionamento nei motori di ricerca ne risente, poiché l’algoritmo di ranking di Google integra i Core Web Vitals come fattore di ranking, creando un circolo vizioso in cui il traffico dei crawler danneggia indirettamente la SEO. Gli utenti che sperimentano tempi di caricamento lenti sono più propensi ad abbandonare il sito e visitare concorrenti, con impatto diretto su ricavi e percezione del brand.
La gestione efficace del traffico dei crawler AI inizia da un monitoraggio e rilevamento completi, che consentono di capire la portata del problema prima di implementare soluzioni. La maggior parte dei server web registra le stringhe user-agent che identificano il crawler per ogni richiesta, fornendo la base per analisi del traffico e decisioni di filtraggio. Log di server, piattaforme di analisi e strumenti di monitoraggio specializzati possono analizzare queste stringhe per identificare e quantificare i pattern di traffico dei crawler.
Principali metodi e strumenti di rilevamento:
La prima linea di difesa contro il traffico eccessivo dei crawler AI è implementare un file robots.txt ben configurato che controlli esplicitamente l’accesso dei crawler al sito. Questo semplice file di testo, posizionato nella root del sito, consente di vietare specifici crawler, limitare la frequenza di crawling e indirizzare i crawler verso una sitemap contenente solo i contenuti che desideri indicizzare. Il rate limiting a livello applicativo o di server fornisce un ulteriore livello di protezione, limitando le richieste da specifici indirizzi IP o user-agent per prevenire l’esaurimento delle risorse. Queste strategie non sono bloccanti e sono reversibili, rendendole ideali come punto di partenza prima di adottare misure più aggressive.
# robots.txt - Blocca i crawler AI consentendo i motori di ricerca legittimi
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Consenti Google e Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl delay per tutti gli altri bot
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
I Web Application Firewall (WAF) e le Content Delivery Network (CDN) offrono protezione sofisticata e di livello enterprise contro il traffico indesiderato dei crawler tramite analisi comportamentale e filtraggio intelligente. Cloudflare e fornitori CDN simili offrono funzionalità di gestione bot integrate che possono identificare e bloccare i crawler AI in base a pattern comportamentali, reputazione IP e caratteristiche della richiesta, senza necessità di configurazioni manuali. Le regole WAF possono essere configurate per sfidare richieste sospette, limitare la frequenza per specifici user-agent o bloccare completamente il traffico da IP noti dei crawler. Queste soluzioni operano all’edge, filtrando il traffico malevolo prima che raggiunga il server origin, riducendo drasticamente il carico sull’infrastruttura. Il vantaggio delle soluzioni WAF e CDN è la capacità di adattarsi a nuovi crawler e pattern di attacco senza richiedere aggiornamenti manuali alle configurazioni.
Decidere se bloccare i crawler AI richiede un’attenta valutazione dei compromessi tra la protezione delle risorse del server e il mantenimento della visibilità nei risultati di ricerca e applicazioni basati su AI. Bloccare tutti i crawler AI elimina la possibilità che i tuoi contenuti appaiano nei risultati di ricerca di ChatGPT, nelle risposte di Perplexity AI o in altri meccanismi di scoperta AI, riducendo potenzialmente il traffico referenziato e la visibilità del brand. Al contrario, consentire accesso illimitato ai crawler consuma molte risorse e può degradare l’esperienza utente senza fornire benefici misurabili all’attività. La strategia ottimale dipende dalla situazione specifica: siti ad alto traffico con risorse abbondanti possono scegliere di consentire i crawler, mentre siti con risorse limitate dovrebbero dare priorità all’esperienza utente bloccando o limitando l’accesso dei crawler. Le decisioni strategiche dovrebbero considerare il settore, il target, il tipo di contenuto e gli obiettivi di business, invece di adottare una soluzione valida per tutti.
Per i siti che scelgono di accogliere il traffico dei crawler AI, la scalabilità infrastrutturale offre una via per mantenere le prestazioni assorbendo il carico aumentato. Lo scaling verticale—l’aggiornamento a server con più CPU, RAM e banda—offre una soluzione semplice ma costosa che prima o poi raggiunge limiti fisici. Lo scaling orizzontale—distribuire il traffico tra più server usando bilanciatori di carico—garantisce scalabilità e resilienza migliori nel lungo termine. Le piattaforme cloud come AWS, Google Cloud e Azure offrono capacità di autoscaling che forniscono risorse aggiuntive automaticamente durante i picchi di traffico, per poi ridurre i costi nei periodi di calma. Le Content Delivery Network (CDN) possono memorizzare contenuti statici nelle edge location, riducendo il carico sul server origin e migliorando le prestazioni sia per utenti umani che per crawler. Ottimizzazione del database, caching delle query e miglioramenti applicativi possono anche ridurre il consumo di risorse per richiesta, aumentando l’efficienza senza necessità di ulteriore infrastruttura.
Un monitoraggio costante e l’ottimizzazione continua sono essenziali per mantenere prestazioni ottimali di fronte al traffico persistente dei crawler AI. Strumenti specializzati offrono visibilità su attività dei crawler, consumo di risorse e metriche di performance, abilitando decisioni basate sui dati sulle strategie di gestione dei crawler. Implementare un monitoraggio completo fin dall’inizio consente di stabilire baseline, identificare trend e misurare l’efficacia delle strategie di mitigazione nel tempo.
Strumenti e pratiche di monitoraggio essenziali:
Il panorama della gestione dei crawler AI continua a evolversi, con nuovi standard e iniziative di settore che plasmano l’interazione tra siti e aziende AI. Lo standard llms.txt rappresenta un approccio emergente per fornire alle aziende AI informazioni strutturate sui diritti d’uso dei contenuti e sulle preferenze, offrendo potenzialmente un’alternativa più sfumata rispetto al blocco o al consenso totale. Le discussioni sul settore riguardo a modelli di compensazione suggeriscono che le aziende AI in futuro potrebbero pagare i siti per l’accesso ai dati di addestramento, cambiando radicalmente l’economia del traffico dei crawler. Preparare la propria infrastruttura al futuro significa rimanere aggiornati sui nuovi standard, monitorare gli sviluppi del settore e mantenere flessibilità nelle politiche di gestione dei crawler. Costruire relazioni con le aziende AI, partecipare alle discussioni di settore e promuovere modelli di compensazione equi sarà sempre più importante man mano che l’AI diventa centrale nella scoperta e nel consumo di contenuti online. I siti che prospereranno in questo scenario saranno quelli che sapranno bilanciare innovazione e pragmatismo, proteggendo le proprie risorse ma restando aperti alle opportunità di visibilità e partnership legittime.
I crawler AI (GPTBot, ClaudeBot) estraggono contenuti per l'addestramento di LLM senza necessariamente inviare traffico di ritorno. I crawler dei motori di ricerca (Googlebot) indicizzano i contenuti per la visibilità nella ricerca e in genere inviano traffico referenziato. I crawler AI operano più aggressivamente con richieste batch più grandi e ignorano le linee guida per il risparmio di banda.
Esempi reali mostrano oltre 30TB al mese da singoli crawler. Il consumo dipende dalla dimensione del sito, dal volume dei contenuti e dalla frequenza del crawler. Solo GPTBot di OpenAI ha generato 569 milioni di richieste in un solo mese sulla rete di Vercel.
Bloccare i crawler per l'addestramento AI (GPTBot, ClaudeBot) non influenzerà il posizionamento su Google. Tuttavia, bloccare i crawler AI per la ricerca potrebbe ridurre la visibilità nei risultati di ricerca basati su AI come Perplexity o la ricerca di ChatGPT.
Cerca picchi inspiegabili di CPU (oltre il 300%), maggiore utilizzo di banda senza più visitatori umani, tempi di caricamento delle pagine più lenti e stringhe user-agent insolite nei log del server. Anche le metriche Core Web Vitals possono peggiorare notevolmente.
Per i siti che sperimentano molto traffico da crawler, l'hosting dedicato offre migliore isolamento delle risorse, controllo e prevedibilità dei costi. Gli ambienti condivisi soffrono del 'noisy neighbor syndrome' dove il traffico dei crawler di un sito impatta tutti i siti ospitati.
Utilizza Google Search Console per i dati di Googlebot, i log di accesso del server per analisi dettagliate del traffico, le analisi del CDN (Cloudflare) e piattaforme specializzate come AmICited.com per un monitoraggio e tracciamento completo dei crawler AI.
Sì, tramite direttive robots.txt, regole WAF e filtraggio basato su IP. Puoi consentire crawler utili come Googlebot mentre blocchi i crawler AI per l'addestramento più intensivi usando regole specifiche per user-agent.
Confronta le metriche del server prima e dopo aver applicato controlli sui crawler. Monitora Core Web Vitals (LCP, TTFB), tempi di caricamento delle pagine, utilizzo della CPU e metriche di esperienza utente. Strumenti come Google PageSpeed Insights e piattaforme di monitoraggio del server forniscono approfondimenti dettagliati.
Ottieni approfondimenti in tempo reale su come i modelli AI accedono ai tuoi contenuti e influenzano le risorse del server con la piattaforma di monitoraggio specializzata di AmICited.
Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...

Guida di riferimento completa ai crawler e bot AI. Identifica GPTBot, ClaudeBot, Google-Extended e oltre 20 altri crawler AI con user agent, frequenze di scansi...

Scopri come prendere decisioni strategiche sul blocco dei crawler AI. Valuta tipo di contenuto, fonti di traffico, modelli di ricavo e posizione competitiva con...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.