
Quali crawler AI dovrei autorizzare? Guida completa per il 2025
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...
12 min di lettura

Scopri le differenze fondamentali tra i crawler di addestramento AI e i crawler di ricerca. Impara come influenzano la visibilità dei tuoi contenuti, le strategie di ottimizzazione e le citazioni AI.
I crawler dei motori di ricerca come Googlebot e Bingbot sono la spina dorsale delle operazioni dei motori di ricerca tradizionali. Questi bot automatizzati navigano sistematicamente il web, scoprendo e indicizzando contenuti per determinare cosa appare nelle pagine dei risultati dei motori di ricerca (SERP). Googlebot, gestito da Google, è il crawler di ricerca più noto e attivo, seguito da Bingbot di Microsoft e YandexBot di Yandex. Questi crawler possiedono capacità sofisticate che consentono loro di eseguire JavaScript, rendere contenuti dinamici e comprendere strutture di siti web complesse. Visitano frequentemente i siti web in base a fattori come autorità del sito, freschezza dei contenuti e storia degli aggiornamenti, con i siti ad alta autorità che ricevono scansioni più frequenti. L’obiettivo principale dei crawler di ricerca è indicizzare i contenuti ai fini del ranking, valutando le pagine secondo criteri di rilevanza, qualità e segnali di esperienza utente.
| Tipo di Crawler | Scopo Primario | Supporto JavaScript | Frequenza di Scansione | Obiettivo |
|---|---|---|---|---|
| Googlebot | Indicizzazione per ranking di ricerca | Sì (con limitazioni) | Frequente, in base all’autorità | Ranking e visibilità |
| Bingbot | Indicizzazione per ranking di ricerca | Sì (con limitazioni) | Regolare, in base agli aggiornamenti dei contenuti | Ranking e visibilità |
| YandexBot | Indicizzazione per ranking di ricerca | Sì (con limitazioni) | Regolare, in base ai segnali del sito | Ranking e visibilità |
I crawler di addestramento AI rappresentano una categoria fondamentalmente diversa di bot web progettati per raccogliere dati destinati all’addestramento di modelli linguistici di grandi dimensioni (LLM) piuttosto che per l’indicizzazione di ricerca. GPTBot, gestito da OpenAI, è il crawler di addestramento AI più noto, insieme a ClaudeBot di Anthropic, PetalBot di Huawei e CCBot di Common Crawl. A differenza dei crawler di ricerca che mirano a posizionare i contenuti, i crawler di addestramento AI si concentrano sulla raccolta di informazioni di alta qualità e ricche di contesto per migliorare la base di conoscenza e le capacità di generazione di risposte dei modelli AI. Questi crawler operano generalmente con minore frequenza rispetto ai crawler di ricerca, visitando spesso un sito web solo una volta ogni alcune settimane o mesi, e danno priorità alla qualità dei contenuti rispetto al volume. La distinzione è cruciale: mentre i tuoi contenuti potrebbero essere completamente indicizzati da Googlebot per la visibilità nella ricerca, potrebbero essere solo parzialmente o raramente scansionati da GPTBot per l’addestramento dei modelli AI.
| Tipo di Crawler | Scopo Primario | Supporto JavaScript | Frequenza di Scansione | Obiettivo |
|---|---|---|---|---|
| GPTBot | Raccolta dati per addestramento LLM | No | Raro, selettivo | Qualità dei dati di addestramento |
| ClaudeBot | Raccolta dati per addestramento LLM | No | Raro, selettivo | Qualità dei dati di addestramento |
| PetalBot | Raccolta dati per addestramento LLM | No | Raro, selettivo | Qualità dei dati di addestramento |
| CCBot | Raccolta dati per Common Crawl | No | Raro, selettivo | Qualità dei dati di addestramento |
Le distinzioni tecniche tra crawler di ricerca e di addestramento AI hanno importanti implicazioni sulla visibilità dei contenuti. La differenza più rilevante è l’esecuzione di JavaScript: i crawler di ricerca come Googlebot possono eseguire JavaScript (seppur con alcune limitazioni), consentendo loro di visualizzare contenuti resi dinamicamente. I crawler di addestramento AI, invece, non eseguono affatto JavaScript—si limitano ad analizzare l’HTML grezzo disponibile al caricamento iniziale della pagina. Questa differenza fondamentale implica che i contenuti caricati dinamicamente tramite script lato client restano completamente invisibili ai crawler AI. Inoltre, i crawler di ricerca rispettano i crawl budget e danno priorità alle pagine in base all’architettura del sito e al linking interno, mentre i crawler AI adottano pattern di scansione più selettivi e guidati dalla qualità. I crawler di ricerca seguono generalmente in modo rigoroso le linee guida del robots.txt, mentre alcuni crawler AI storicamente sono stati meno trasparenti rispetto alla loro conformità. La frequenza di scansione è molto diversa: i crawler di ricerca visitano siti attivi più volte a settimana o anche ogni giorno, mentre i crawler di addestramento AI possono visitare solo una volta ogni alcune settimane o mesi. Inoltre, i crawler di ricerca sono progettati per comprendere segnali di ranking e metriche di esperienza utente, mentre i crawler AI si concentrano sull’estrazione di testo pulito e ben strutturato per l’addestramento dei modelli.
| Caratteristica | Crawler di Ricerca | Crawler di Addestramento AI |
|---|---|---|
| Esecuzione JavaScript | Sì (con limitazioni) | No |
| Frequenza di Scansione | Alta (più volte a settimana) | Bassa (una volta ogni alcune settimane) |
| Analisi dei Contenuti | Rendering completo della pagina | Solo HTML grezzo |
| Conformità robots.txt | Rigorosa | Variabile |
| Focus del Crawl Budget | Priorità in base all’autorità | Selezione basata sulla qualità |
| Gestione Contenuti Dinamici | Può renderizzare e indicizzare | Li ignora completamente |
| Obiettivo Primario | Ranking e visibilità nella ricerca | Raccolta dati per addestramento |
| Tolleranza Timeout | Maggiore (consente rendering complesso) | Bassa (1-5 secondi) |
L’incapacità dei crawler AI di eseguire JavaScript crea un divario critico di visibilità che interessa molti siti web moderni. Quando un sito si affida a JavaScript per caricare dinamicamente i contenuti—come descrizioni prodotto, recensioni, prezzi o immagini—quei contenuti diventano invisibili ai crawler AI. Questo è particolarmente problematico per le single-page application (SPA) sviluppate con React, Vue o Angular, dove la maggior parte dei contenuti viene caricata lato client dopo l’invio dell’HTML iniziale. Ad esempio, un sito ecommerce potrebbe mostrare disponibilità e prezzi tramite JavaScript, il che significa che GPTBot vede solo una pagina vuota o uno scheletro HTML di base. Allo stesso modo, i siti che usano il lazy-loading per le immagini o lo scroll infinito per i contenuti vedranno quegli elementi completamente ignorati dai crawler AI. Le conseguenze per il business sono rilevanti: se dettagli prodotto, testimonianze clienti o contenuti chiave sono nascosti dietro JavaScript, i sistemi AI come ChatGPT e Perplexity non avranno accesso a tali informazioni durante la generazione delle risposte. Si crea così una situazione in cui i tuoi contenuti possono posizionarsi bene su Google ma essere completamente assenti nelle risposte generate dall’AI, rendendoti di fatto invisibile a una fetta crescente di utenti che si affidano all’AI per la scoperta delle informazioni.
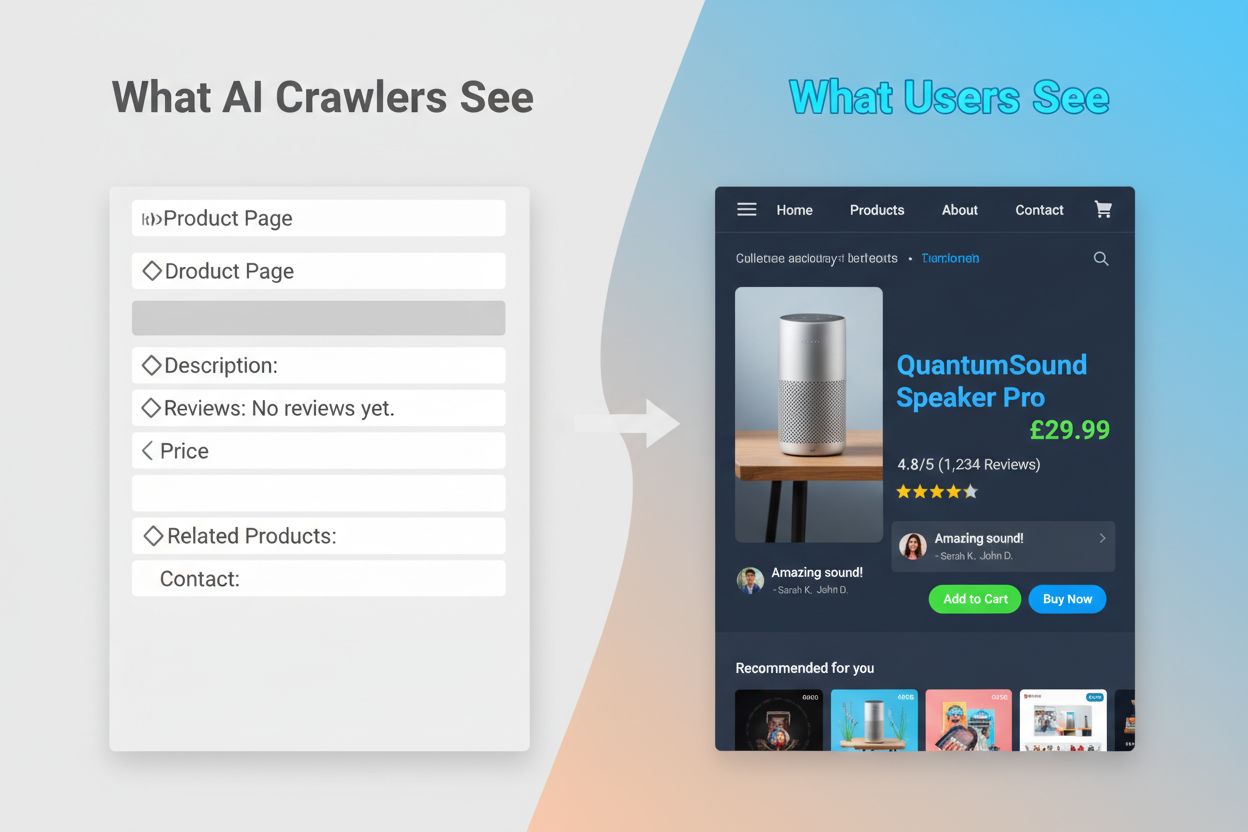
Le conseguenze pratiche di queste differenze tecniche sono profonde e spesso fraintese dai proprietari di siti web. Il tuo sito potrebbe ottenere ottimi posizionamenti su Google risultando allo stesso tempo quasi invisibile su ChatGPT, Perplexity e altri sistemi AI. Ciò crea una situazione paradossale in cui il successo SEO tradizionale non garantisce la visibilità nell’AI. Quando gli utenti chiedono a ChatGPT informazioni sul tuo settore o prodotto, il sistema AI potrebbe citare i tuoi concorrenti invece di te, semplicemente perché i loro contenuti erano più accessibili ai crawler AI. La relazione tra dati di addestramento e citazioni nella ricerca aggiunge un ulteriore livello di complessità: i contenuti utilizzati per addestrare un modello AI possono ricevere trattamento preferenziale nei risultati di ricerca di quel modello, il che significa che bloccare i crawler di addestramento AI potrebbe ridurre la tua visibilità nelle risposte AI. Per editori e creatori di contenuti, questo implica che la decisione strategica di permettere o bloccare i crawler AI ha reali conseguenze sul traffico futuro. Un sito che blocca GPTBot per proteggere i contenuti dall’uso nell’addestramento rischia di ridurre le proprie probabilità di apparire nei risultati di ChatGPT. Al contrario, consentire l’accesso ai crawler AI fornisce dati per l’addestramento ma non garantisce citazioni o traffico, creando un vero dilemma strategico senza una soluzione perfetta.
Comprendere quali crawler accedono al tuo sito e con quale frequenza è essenziale per ottimizzare la tua strategia di contenuti. L’analisi dei file di log è il metodo principale per identificare l’attività dei crawler, permettendoti di segmentare e analizzare i log del server per vedere quali bot hanno visitato il sito, con quale frequenza e quali pagine hanno privilegiato. Analizzando le stringhe User-Agent nei log del server puoi distinguere tra Googlebot, GPTBot, OAI-SearchBot e altri crawler, rivelando i pattern del loro comportamento. Le metriche chiave da monitorare includono frequenza di scansione (quanto spesso ogni crawler visita il sito), profondità di scansione (quanti livelli della struttura del sito vengono scansionati) e crawl budget (il numero totale di pagine scansionate in un determinato periodo). Strumenti come Google Search Console e Bing Webmaster Tools offrono insight sull’attività dei crawler di ricerca, mentre soluzioni specializzate come AmICited.com forniscono un monitoraggio completo dell’attività dei crawler AI su più piattaforme, inclusi ChatGPT, Perplexity e Google AI Overviews. AmICited.com traccia in modo specifico come i sistemi AI fanno riferimento al tuo brand e ai tuoi contenuti, offrendo visibilità su quali piattaforme AI ti citano e con quale frequenza. Comprendere questi pattern ti aiuta a individuare tempestivamente problemi tecnici, ottimizzare la distribuzione del crawl budget e prendere decisioni informate su accesso ai crawler e ottimizzazione dei contenuti.
Ottimizzare per i crawler di ricerca tradizionali richiede di concentrarsi sui fondamentali della SEO tecnica, garantendo che i tuoi contenuti siano individuabili e indicizzabili. Le seguenti strategie rimangono essenziali per mantenere una solida visibilità nella ricerca:
I motori di ricerca come Google sono sempre più orientati all’efficienza di scansione, con rappresentanti di Google che indicano che Googlebot in futuro effettuerà meno scan. Ciò significa che il tuo sito dovrebbe essere il più snello e comprensibile possibile, con gerarchie chiare e linking interno efficiente che indirizzi i crawler direttamente alle tue pagine più importanti.
Ottimizzare per i crawler di addestramento AI richiede un approccio diverso, focalizzato su qualità, chiarezza e accessibilità dei contenuti piuttosto che sui segnali di ranking. Poiché i crawler AI danno priorità a contenuti ben strutturati e ricchi di contesto, la tua strategia di ottimizzazione dovrebbe puntare su completezza e leggibilità. Evita contenuti critici dipendenti da JavaScript: assicurati che dettagli prodotto, prezzi, recensioni e dati chiave siano presenti in HTML grezzo e accessibili ai crawler AI. Crea contenuti completi e approfonditi che coprano gli argomenti in modo esaustivo e forniscano il contesto da cui i modelli AI possano apprendere. Utilizza una formattazione chiara con intestazioni, elenchi puntati e numerati che suddividano il testo e rendano i contenuti facilmente analizzabili. Scrivi con chiarezza semantica usando un linguaggio diretto e senza jargon eccessivo che possa confondere i modelli AI. Implementa una corretta gerarchia di intestazioni (H1, H2, H3) per aiutare i crawler AI a comprendere la struttura e le relazioni tra i contenuti. Includi metadati rilevanti e schema markup che aggiungano contesto ai tuoi contenuti. Garantisci tempi di caricamento rapidi poiché i crawler AI hanno timeout stretti (tipicamente 1-5 secondi) e possono saltare del tutto le pagine troppo lente.
La differenza chiave rispetto all’ottimizzazione per la ricerca è che i crawler AI non tengono conto di segnali di ranking, backlink o densità di parole chiave. Valutano invece contenuti chiari, ben organizzati e informativi. Una pagina che potrebbe non posizionarsi bene su Google può essere estremamente preziosa per i modelli AI se contiene informazioni complete e ben strutturate su un dato argomento.
Lo scenario del crawling web sta evolvendo rapidamente, con i crawler AI che diventano sempre più importanti per la visibilità dei contenuti e la notorietà del brand. Man mano che strumenti di ricerca potenziati dall’AI come ChatGPT, Perplexity e Google AI Overviews continuano a diffondersi, la possibilità di essere scoperti e citati da questi sistemi diventerà tanto cruciale quanto il ranking nei motori di ricerca tradizionali. La distinzione tra crawler di addestramento e di ricerca diventerà probabilmente più sfumata, con le aziende che potranno offrire una separazione più chiara tra raccolta dati e ricerca, come già avviene con GPTBot e OAI-SearchBot di OpenAI. I proprietari di siti dovranno sviluppare strategie che bilancino l’ottimizzazione SEO tradizionale con la visibilità AI, riconoscendo che questi obiettivi sono complementari e non in competizione. L’emergere di strumenti e soluzioni di monitoraggio specializzati renderà più semplice tracciare l’attività dei crawler su entrambe le piattaforme tradizionali e AI, consentendo decisioni basate sui dati sull’accesso dei crawler e sull’ottimizzazione dei contenuti. Chi saprà ottimizzare ora per entrambi i tipi di crawler avrà un vantaggio competitivo, posizionando i propri contenuti per essere scoperti tramite più canali man mano che lo scenario della ricerca evolve. Il futuro della visibilità dei contenuti dipende dalla comprensione e dall’ottimizzazione per l’intero spettro di crawler che scoprono e utilizzano i tuoi contenuti.
I crawler di ricerca come Googlebot indicizzano i contenuti per il posizionamento nei risultati e possono eseguire JavaScript per visualizzare contenuti dinamici. I crawler di addestramento AI come GPTBot raccolgono dati per addestrare i LLM e generalmente non possono eseguire JavaScript, perdendosi così i contenuti caricati dinamicamente. Questa differenza fondamentale significa che il tuo sito potrebbe posizionarsi bene su Google ma risultare quasi invisibile su ChatGPT.
Sì, puoi utilizzare robots.txt per bloccare specifici crawler AI come GPTBot consentendo invece l'accesso ai crawler di ricerca. Tuttavia, questo potrebbe ridurre la tua visibilità nelle risposte e sintesi generate dall'AI. La scelta strategica dipende dal fatto che tu dia priorità alla protezione dei contenuti o al potenziale traffico proveniente da AI.
I crawler AI come GPTBot analizzano solo l'HTML grezzo al caricamento iniziale della pagina e non eseguono JavaScript. I contenuti caricati dinamicamente tramite script—come dettagli prodotto, recensioni o immagini—rimangono completamente invisibili per loro. Si tratta di una limitazione critica per i siti moderni che si basano molto sul rendering lato client.
I crawler di addestramento AI visitano tipicamente meno frequentemente dei crawler di ricerca, con intervalli più lunghi tra una visita e l'altra. Danno priorità ai contenuti autorevoli e possono effettuare la scansione di una pagina solo una volta ogni alcune settimane o mesi. Questo schema di scansione poco frequente riflette il loro focus sulla qualità piuttosto che sulla quantità.
Dettagli prodotto, recensioni clienti, immagini lazy-loaded, elementi interattivi (tab, caroselli, modali), informazioni sui prezzi e qualsiasi contenuto nascosto dietro JavaScript sono i più vulnerabili. Per siti ecommerce e basati su SPA, ciò può rappresentare una parte significativa dei contenuti critici.
Assicurati che i contenuti chiave siano presenti in HTML grezzo, migliora la velocità del sito, utilizza una struttura e una formattazione chiare con una gerarchia di intestazioni corretta, implementa lo schema markup ed evita che i contenuti critici dipendano da JavaScript. L'obiettivo è rendere i tuoi contenuti accessibili a entrambi i tipi di crawler.
Strumenti di analisi dei file di log, Google Search Console, Bing Webmaster Tools e soluzioni specializzate di monitoraggio dei crawler come AmICited.com possono aiutare a tracciare il comportamento dei crawler. AmICited.com monitora specificamente come i sistemi AI fanno riferimento al tuo brand su ChatGPT, Perplexity e Google AI Overviews.
Potenzialmente sì. Sebbene bloccare i crawler di addestramento possa proteggere i tuoi contenuti, potrebbe ridurre la tua visibilità nei risultati di ricerca e nelle sintesi generate dall'AI. Inoltre, i contenuti già scansionati prima del blocco rimangono nei modelli addestrati. La decisione richiede di bilanciare la protezione dei contenuti con la possibile perdita di scoperta tramite AI.
Traccia come i sistemi AI fanno riferimento al tuo brand su ChatGPT, Perplexity e Google AI Overviews. Ottieni informazioni in tempo reale sulla tua visibilità AI e ottimizza la tua strategia di contenuti.
Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...

Guida di riferimento completa ai crawler e bot AI. Identifica GPTBot, ClaudeBot, Google-Extended e oltre 20 altri crawler AI con user agent, frequenze di scansi...
Scopri come consentire ai bot AI come GPTBot, PerplexityBot e ClaudeBot di scansionare il tuo sito. Configura robots.txt, imposta llms.txt e ottimizza per la vi...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.