Scopri come il Retrieval-Augmented Generation trasforma le citazioni dell’IA, permettendo un’attribuzione accurata delle fonti e risposte fondate su ChatGPT, Perplexity e Google AI Overviews.
Pubblicato il Jan 3, 2026.Ultima modifica il Jan 3, 2026 alle 3:24 am
I grandi modelli linguistici hanno rivoluzionato l’IA, ma presentano un difetto critico: limiti di conoscenza. Questi modelli sono addestrati su dati fino a un certo momento, il che significa che non possono accedere a informazioni successive a quella data. Oltre alla mancanza di aggiornamento, i LLM tradizionali soffrono di allucinazioni—generando con sicurezza informazioni false che sembrano plausibili—e non forniscono alcuna attribuzione delle fonti per le proprie affermazioni. Quando un’azienda ha bisogno di dati di mercato attuali, ricerche proprietarie o fatti verificabili, i LLM tradizionali non sono sufficienti, lasciando gli utenti con risposte che non possono né fidarsi né verificare.
Cos’è il RAG - Definizione e Componenti Chiave
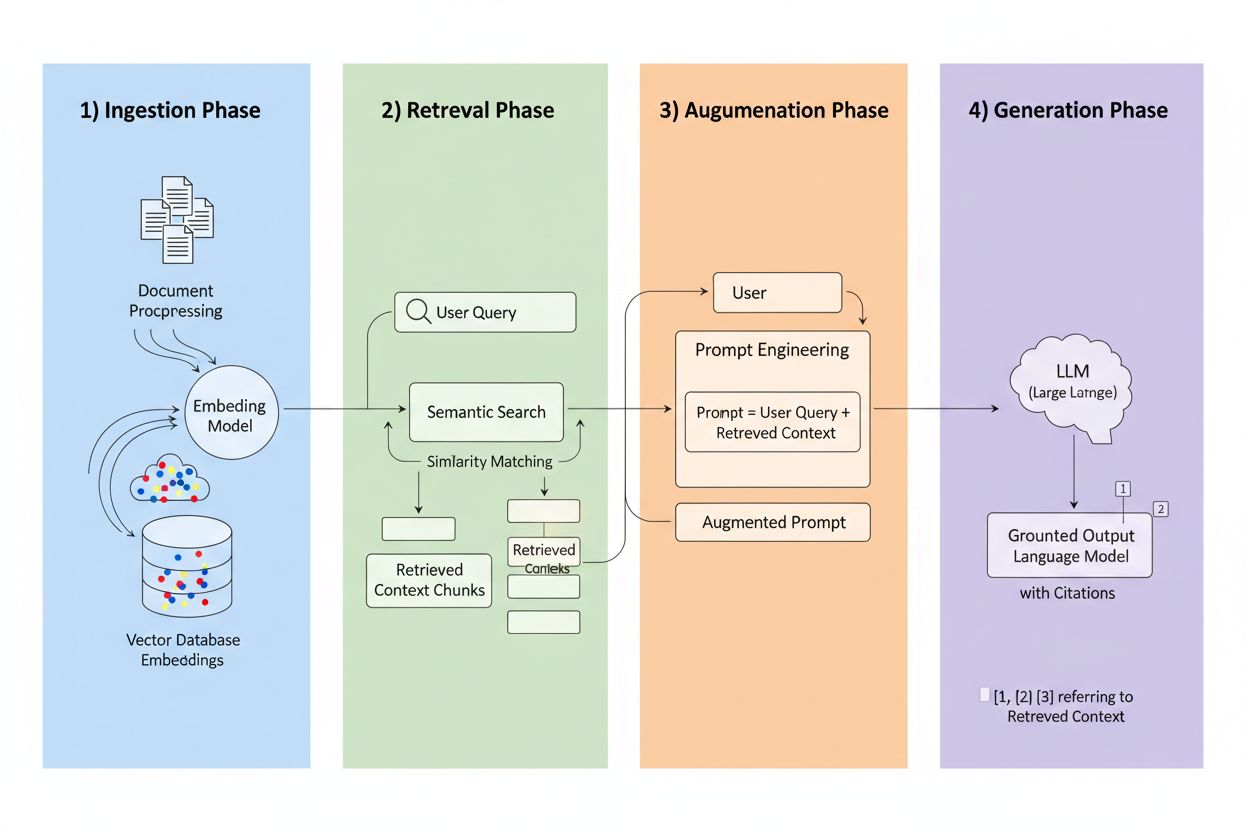
Retrieval-Augmented Generation (RAG) è un framework che combina la capacità generativa dei LLM con la precisione dei sistemi di recupero delle informazioni. Invece di affidarsi solo ai dati di addestramento, i sistemi RAG recuperano informazioni rilevanti da fonti esterne prima di generare le risposte, creando una pipeline che fonda le risposte su dati reali. I quattro componenti principali lavorano in sinergia: Ingestione (conversione dei documenti in formati ricercabili), Recupero (ricerca delle fonti più rilevanti), Arricchimento (enrichment del prompt con contesto recuperato) e Generazione (creazione della risposta finale con citazioni). Ecco come il RAG si confronta con gli approcci tradizionali:
Aspetto
LLM Tradizionale
Sistema RAG
Fonte della conoscenza
Dati di addestramento statici
Fonti indicizzate esterne
Capacità di citazione
Nessuna/allucinata
Rintracciabile alle fonti
Accuratezza
Soggetto a errori
Fondato sui fatti
Dati in tempo reale
No
Sì
Rischio di allucinazione
Alto
Basso
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Come Funziona il Recupero RAG - Approfondimento Tecnico
Il motore di recupero è il cuore pulsante del RAG, ed è molto più sofisticato di un semplice matching di parole chiave. I documenti vengono convertiti in vector embedding—rappresentazioni matematiche che catturano il significato semantico—consentendo al sistema di trovare contenuti concettualmente simili anche quando le parole non coincidono esattamente. Il sistema suddivide i documenti in parti gestibili, solitamente da 256 a 1024 token, bilanciando la conservazione del contesto con la precisione del recupero. I sistemi RAG più avanzati utilizzano la ricerca ibrida, combinando similarità semantica con il matching classico di parole chiave per rilevare sia corrispondenze concettuali che letterali. Un meccanismo di reranking assegna poi un punteggio ai candidati, spesso utilizzando modelli cross-encoder che valutano la rilevanza con maggiore accuratezza rispetto al recupero iniziale. La rilevanza viene calcolata tramite molteplici segnali: punteggi di similarità semantica, sovrapposizione di parole chiave, matching di metadati e autorità del dominio. L’intero processo avviene in millisecondi, garantendo risposte rapide e accurate senza latenza percepibile.
Il Vantaggio della Citazione
Qui il RAG trasforma lo scenario delle citazioni: quando un sistema recupera informazioni da una fonte indicizzata specifica, quella fonte diventa rintracciabile e verificabile. Ogni frammento di testo può essere ricondotto al suo documento, URL o pubblicazione originale, rendendo la citazione automatica anziché allucinata. Questo cambiamento fondamentale crea un’inedita trasparenza nelle decisioni dell’IA—gli utenti possono vedere esattamente quali fonti hanno informato la risposta, verificare autonomamente le affermazioni e valutare la credibilità delle fonti. A differenza dei LLM tradizionali, dove le citazioni sono spesso inventate o generiche, le citazioni RAG sono fondate su veri eventi di recupero. Questa tracciabilità aumenta enormemente la fiducia degli utenti, che possono validare le informazioni invece di accettarle per fede. Per i creatori di contenuti e gli editori, questo significa che il proprio lavoro può essere scoperto e accreditato dai sistemi IA, aprendo nuovi canali di visibilità.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Fattori di Qualità della Citazione nei Sistemi RAG
Non tutte le fonti sono uguali nei sistemi RAG, e diversi fattori determinano quali contenuti vengono citati più frequentemente:
Autorità: Reputazione del dominio, profili backlink e presenza nei knowledge graph segnalano affidabilità agli algoritmi di recupero
Recentezza: I contenuti aggiornati ogni 48-72 ore si posizionano meglio, poiché la freschezza indica manutenzione attiva e affidabilità
Rilevanza: L’allineamento semantico con le query degli utenti determina se il contenuto appare nei risultati di recupero
Struttura: Gerarchia chiara, intestazioni descrittive e markup semantico aiutano i sistemi a comprendere ed estrarre accuratamente le informazioni
Densità Fattuale: Contenuti ricchi di dati, statistiche e citazioni offrono più “nuggets” recuperabili rispetto a panoramiche generiche
Knowledge Graph: La presenza su Wikipedia, Wikidata o knowledge base di settore aumenta drasticamente la probabilità di citazione
Ogni fattore si somma agli altri—un articolo ben strutturato, frequentemente aggiornato, proveniente da un dominio autorevole con forti backlink e presenza nei knowledge graph diventa un magnete di citazioni nei sistemi RAG. Si crea così un nuovo paradigma di ottimizzazione dove la visibilità dipende meno dalla SEO per il traffico e più dal diventare una fonte strutturata e affidabile.
Come le Diverse Piattaforme IA Usano il RAG per le Citazioni
Le diverse piattaforme IA implementano il RAG con strategie distinte, generando schemi di citazione differenti. ChatGPT attribuisce grande peso alle fonti di Wikipedia, con studi che mostrano circa il 26-35% delle citazioni provenienti solo da Wikipedia, riflettendo la sua autorevolezza e il formato strutturato. Google AI Overviews applica una selezione di fonti più diversificata, attingendo da siti di notizie, articoli accademici e forum, con Reddit che appare in circa il 5% delle citazioni nonostante un’autorità tradizionale minore. Perplexity AI cita generalmente 3-5 fonti per risposta e mostra una forte preferenza per pubblicazioni di settore e notizie recenti, ottimizzando per completezza e tempestività. Queste piattaforme ponderano in modo diverso l’autorità del dominio—alcune danno priorità a segnali tradizionali come backlink e anzianità del dominio, altre enfatizzano la freschezza dei contenuti e la rilevanza semantica. Comprendere queste strategie di recupero specifiche per piattaforma è cruciale per i creatori di contenuti, poiché l’ottimizzazione per il sistema RAG di una piattaforma può differire notevolmente da quella di un’altra.
RAG vs Ricerca Tradizionale - Implicazioni sulle Citazioni
L’ascesa del RAG sconvolge radicalmente la saggezza SEO tradizionale. Nell’ottimizzazione per i motori di ricerca, citazioni e visibilità sono correlate direttamente al traffico—servono i click per contare. Il RAG inverte questa equazione: un contenuto può essere citato e influenzare le risposte IA senza generare alcun traffico. Un articolo ben strutturato e autorevole potrebbe apparire in decine di risposte IA ogni giorno senza ricevere nemmeno un click, poiché gli utenti ottengono la risposta direttamente dal riassunto dell’IA. Questo significa che i segnali di autorità contano più che mai, essendo il principale meccanismo che i sistemi RAG usano per valutare la qualità delle fonti. La coerenza tra le piattaforme diventa fondamentale—se il tuo contenuto appare sul tuo sito, su LinkedIn, nei database di settore e nei knowledge graph, i sistemi RAG percepiscono segnali di autorità rafforzati. La presenza nei knowledge graph passa da “nice-to-have” a infrastruttura essenziale, poiché questi database strutturati sono fonti di recupero primarie per molte implementazioni RAG. Il gioco delle citazioni è cambiato radicalmente: da “guidare traffico” a “diventare una fonte di informazione affidabile”.
Ottimizzazione dei Contenuti per le Citazioni RAG
Per massimizzare le citazioni RAG, la strategia dei contenuti deve spostarsi dall’ottimizzazione per il traffico a quella per la fonte. Implementa cicli di aggiornamento ogni 48-72 ore per i contenuti evergreen, segnalando ai sistemi di recupero che le tue informazioni sono sempre attuali. Utilizza markup di dati strutturati (Schema.org, JSON-LD) per aiutare i sistemi a interpretare e comprendere il significato e le relazioni dei tuoi contenuti. Allinea i tuoi contenuti semanticamente ai modelli di query comuni—usa un linguaggio naturale che rispecchi il modo in cui le persone pongono domande, non solo come cercano. Formattta i contenuti con sezioni FAQ e Q&A, in quanto corrispondono direttamente allo schema domanda-risposta dei sistemi RAG. Sviluppa o contribuisci a voci Wikipedia e knowledge graph, essendo queste fonti di recupero primarie per la maggior parte delle piattaforme. Costruisci autorità tramite backlink attraverso partnership strategiche e citazioni da altre fonti autorevoli, poiché i profili di link restano segnali di autorità forti. Infine, mantieni coerenza tra le piattaforme—assicura che le affermazioni chiave, i dati e il messaggio siano allineati tra sito, profili social, database di settore e knowledge graph, creando segnali rafforzati di affidabilità.
Il Futuro del RAG e delle Citazioni
La tecnologia RAG continua a evolversi rapidamente, con diverse tendenze che stanno ridefinendo il funzionamento delle citazioni. Algoritmi di recupero più sofisticati andranno oltre la similarità semantica per una comprensione più profonda dell’intento e del contesto della query, migliorando la rilevanza delle citazioni. Knowledge base specializzate emergeranno per domini specifici—sistemi RAG medici che utilizzano letteratura curata, sistemi legali che usano giurisprudenza e normative—creando nuove opportunità di citazione per fonti autorevoli di settore. L’integrazione con sistemi multi-agente permetterà al RAG di orchestrare molteplici recuperatori specializzati, combinando intuizioni da diversi knowledge base per risposte più complete. L’accesso ai dati in tempo reale migliorerà drasticamente, permettendo ai sistemi RAG di incorporare informazioni live da API, database e fonti in streaming. Agentic RAG—dove agenti IA decidono autonomamente cosa recuperare, come processarlo e quando iterare—creerà schemi di citazione più dinamici, potenzialmente citando più volte le stesse fonti mentre gli agenti perfezionano il ragionamento.
Il Ruolo di AmICited nel Monitoraggio delle Citazioni RAG
Poiché il RAG ridefinisce il modo in cui i sistemi IA scoprono e citano le fonti, comprendere la propria performance in termini di citazioni diventa essenziale. AmICited monitora le citazioni IA su più piattaforme, tracciando quali delle tue fonti compaiono su ChatGPT, Google AI Overviews, Perplexity e i sistemi IA emergenti. Potrai vedere quali fonti vengono citate, con quale frequenza e in quale contesto—rivelando quali contenuti risuonano con gli algoritmi di recupero RAG. La nostra piattaforma ti aiuta a comprendere i modelli di citazione nel tuo portafoglio contenuti, identificando cosa rende certi pezzi degni di citazione e altri invisibili. Misura la visibilità del tuo brand nelle risposte IA con metriche rilevanti per l’era RAG, andando oltre le tradizionali analisi di traffico. Conduci analisi competitiva delle performance di citazione, confrontando le tue fonti con quelle dei concorrenti nelle risposte generate dall’IA. In un mondo in cui le citazioni IA guidano visibilità e autorevolezza, avere chiara visibilità sulla propria performance di citazione non è opzionale—è il modo per restare competitivi.
Domande frequenti
Qual è la differenza tra RAG e i tradizionali LLM?
I LLM tradizionali si basano su dati di addestramento statici con limiti di conoscenza e non possono accedere a informazioni in tempo reale, spesso generando allucinazioni e affermazioni non verificabili. I sistemi RAG recuperano informazioni da fonti indicizzate esterne prima di generare le risposte, consentendo citazioni accurate e risposte fondate su dati attuali e verificabili.
Come migliora il RAG la precisione delle citazioni?
Il RAG traccia ogni informazione recuperata alla sua fonte originale, rendendo le citazioni automatiche e verificabili anziché allucinate. Questo crea un collegamento diretto tra la risposta e il materiale di origine, permettendo agli utenti di verificare autonomamente le affermazioni e valutare la credibilità delle fonti.
Quali fattori determinano quali fonti vengono citate nei sistemi RAG?
I sistemi RAG valutano le fonti in base all'autorità (reputazione del dominio e backlink), alla recentezza (contenuti aggiornati entro 48-72 ore), alla rilevanza semantica rispetto alla query, alla struttura e chiarezza dei contenuti, alla densità fattuale con dati specifici e alla presenza in knowledge graph come Wikipedia. Questi fattori si combinano per determinare la probabilità di citazione.
Come posso ottimizzare i miei contenuti per le citazioni RAG?
Aggiorna i contenuti ogni 48-72 ore per mantenere segnali di freschezza, implementa markup di dati strutturati (Schema.org), allinea semanticamente i contenuti alle query comuni, utilizza formattazione FAQ e Q&A, sviluppa la presenza su Wikipedia e knowledge graph, costruisci autorità tramite backlink e mantieni coerenza su tutte le piattaforme.
Perché la presenza nei knowledge graph è importante per le citazioni IA?
I knowledge graph come Wikipedia e Wikidata sono fonti di recupero primarie per la maggior parte dei sistemi RAG. La presenza in questi database strutturati aumenta drasticamente la probabilità di citazione e crea segnali fondamentali di fiducia che i sistemi IA richiamano ripetutamente su query diverse.
Quanto spesso dovrei aggiornare i contenuti per la visibilità RAG?
I contenuti dovrebbero essere aggiornati ogni 48-72 ore per mantenere forti segnali di recentezza nei sistemi RAG. Non è necessario riscrivere tutto: aggiungere nuovi dati, aggiornare statistiche o espandere sezioni con sviluppi recenti è sufficiente per restare idonei alla citazione.
Che ruolo ha l'autorità del dominio nelle citazioni RAG?
L'autorità del dominio funge da proxy di affidabilità negli algoritmi RAG, incidendo per circa il 5% sulla probabilità di citazione. Viene valutata tramite età del dominio, certificati SSL, profili di backlink, attribuzione di esperti e presenza nei knowledge graph, tutti elementi che si sommano per influenzare la selezione delle fonti.
Come AmICited aiuta a monitorare le citazioni RAG?
AmICited traccia quali delle tue fonti appaiono nelle risposte generate dall'IA su ChatGPT, Google AI Overviews, Perplexity e altre piattaforme. Potrai vedere frequenza delle citazioni, contesto e performance rispetto ai concorrenti, aiutandoti a capire cosa rende un contenuto degno di citazione nell'era RAG.
Monitora le Citazioni della Tua Marca nell'IA
Comprendi come appare la tua marca nelle risposte generate dall'IA su ChatGPT, Perplexity, Google AI Overviews e altro ancora. Traccia i modelli di citazione, misura la visibilità e ottimizza la tua presenza nel panorama di ricerca guidato dall'IA.
Che cos'è il RAG nella Ricerca AI: Guida Completa alla Retrieval-Augmented Generation
Scopri cos'è il RAG (Retrieval-Augmented Generation) nella ricerca AI. Scopri come il RAG migliora l'accuratezza, riduce le allucinazioni e alimenta ChatGPT, Pe...
Come funziona la Retrieval-Augmented Generation: Architettura e Processo
Scopri come RAG combina LLM e fonti di dati esterne per generare risposte AI accurate. Comprendi il processo in cinque fasi, i componenti e perché è importante ...
Come Gestiscono i Sistemi RAG le Informazioni Obsolete?
Scopri come i sistemi Retrieval-Augmented Generation gestiscono l'aggiornamento delle basi di conoscenza, prevengono dati obsoleti e mantengono le informazioni ...
12 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.