
Accesso Differenziale dei Crawler
Scopri come permettere o bloccare selettivamente i crawler AI in base agli obiettivi aziendali. Implementa l’accesso differenziale dei crawler per proteggere i ...
9 min di lettura

Scopri come utilizzare robots.txt per controllare quali bot IA accedono ai tuoi contenuti. Guida completa al blocco di GPTBot, ClaudeBot e altri crawler IA con esempi pratici e strategie di configurazione.
Il panorama del crawling web è cambiato radicalmente negli ultimi due anni, andando oltre il familiare territorio dell’indicizzazione dei motori di ricerca per entrare nel complesso mondo dell’addestramento dei modelli IA. Se Googlebot è stato a lungo un visitatore prevedibile dei siti degli editori, una nuova generazione di crawler arriva ora con intenzioni e modelli di consumo radicalmente diversi. Il GPTBot di OpenAI mostra un rapporto crawl-to-refer di circa 1.700:1, cioè esegue la scansione di 1.700 pagine per generare un solo referral verso il tuo sito, mentre ClaudeBot di Anthropic opera a un livello ancora più estremo, con un rapporto di 73.000:1—molto diverso dal rapporto 14:1 di Google, dove l’attività di crawling si traduce in traffico significativo. Questa differenza fondamentale crea una decisione aziendale urgente per i creatori di contenuti: consentire a questi bot un accesso illimitato significa che i tuoi contenuti addestrano modelli IA che competono con il tuo traffico e i tuoi ricavi, mentre il tuo sito riceve una compensazione o un traffico minimi in cambio. Gli editori devono ora decidere attivamente se il valore dell’accesso dei bot IA è in linea con il loro modello di business, rendendo la configurazione del robots.txt non solo una questione tecnica ma una vera e propria priorità strategica.
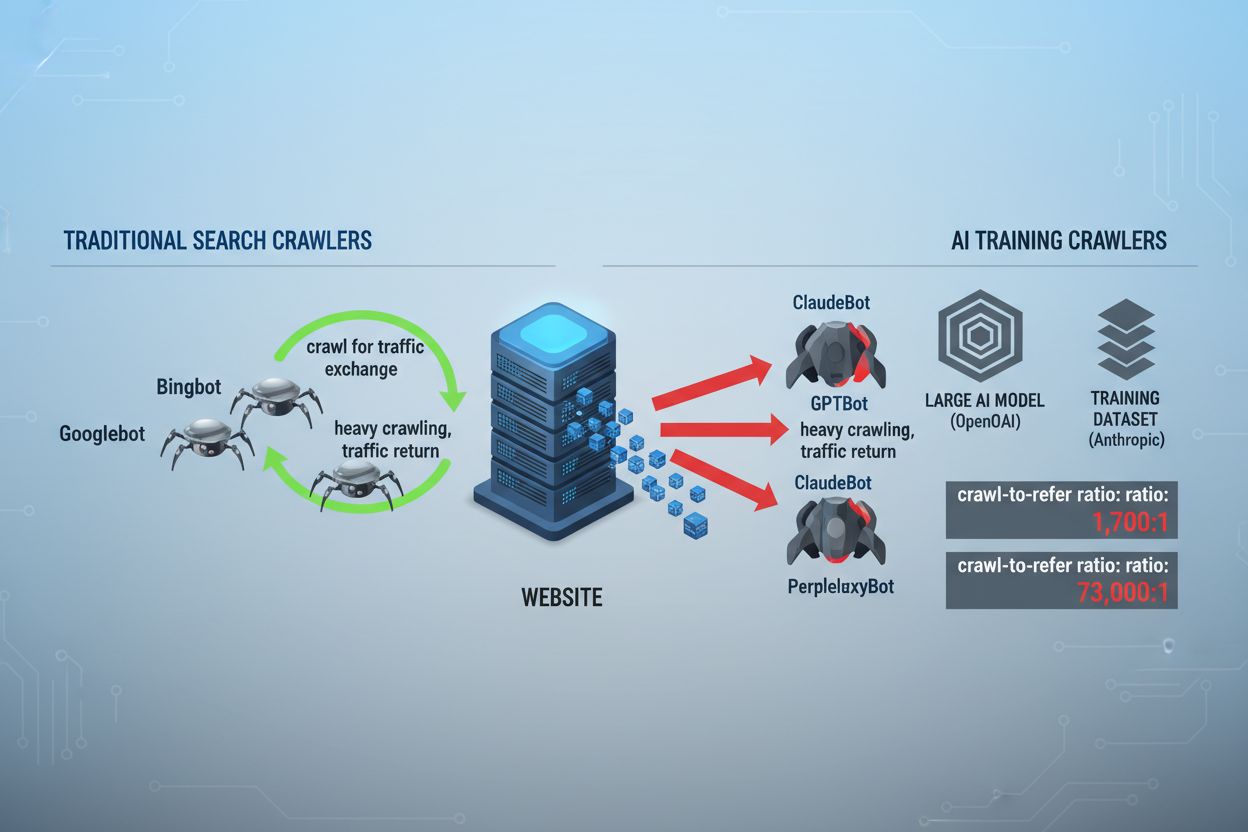
I crawler IA operano in tre categorie distinte, ognuna con scopi diversi e che richiede strategie di blocco differenti. I crawler di training sono progettati per acquisire grandi volumi di contenuti per addestrare modelli IA—tra questi ci sono GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), e nuovi attori come Amazonbot, Bytespider e cohere-ai. I crawler di ricerca, invece, alimentano esperienze di ricerca IA e di solito riportano traffico agli editori; tra questi OAI-SearchBot (OpenAI), Claude-Web (Anthropic) e la funzione search di Perplexity. Gli agenti attivati dall’utente rappresentano una terza categoria, in cui i contenuti vengono richiesti su domanda esplicita da parte di un utente, come ChatGPT-User o interazioni Claude-Web avviate direttamente dall’utente finale. Comprendere questa tassonomia è fondamentale perché la strategia di blocco deve riflettere le tue priorità aziendali—potresti voler accogliere i crawler di ricerca che generano traffico referral, ma bloccare i crawler di training che consumano contenuti senza compenso. Ogni azienda IA gestisce la propria flotta di crawler specializzati, e la distinzione tra di essi si riduce spesso al particolare user agent utilizzato, rendendo l’identificazione accurata e il blocco mirato essenziali per una configurazione efficace del robots.txt.
| Azienda | Crawler di Training | Crawler di Ricerca | Agente Attivato dall’Utente |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Usa Googlebot standard) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Mantenere una lista aggiornata e accurata degli user agent dei bot IA è essenziale per una configurazione efficace del robots.txt, ma questo scenario evolve rapidamente con il lancio di nuovi modelli e modifiche nelle strategie di crawling. I principali crawler di training da conoscere sono GPTBot (OpenAI), ClaudeBot (Anthropic), anthropic-ai (Anthropic, identificativo alternativo), Google-Extended (Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), CCBot (Common Crawl), Amazonbot (Amazon), Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (DuckDuckGo) e YouBot (You.com). I crawler focalizzati sulla ricerca che normalmente restituiscono traffico includono OAI-SearchBot, Claude-Web e PerplexityBot in modalità search. La sfida è che questa lista non è statica—nuove aziende IA emergono regolarmente, le aziende esistenti rilasciano nuovi crawler per nuovi prodotti e gli user agent cambiano o si ampliano. Gli editori dovrebbero considerare il robots.txt come un documento vivo, da rivedere almeno ogni trimestre, magari iscrivendosi a risorse di settore o monitorando i log del server per individuare user agent sconosciuti che potrebbero essere nuovi crawler IA. Non mantenere aggiornata la lista degli user agent significa rischiare di consentire accidentalmente l’accesso a nuovi crawler di training che intendevi bloccare, oppure bloccare inutilmente crawler di ricerca legittimi che potrebbero generare traffico di valore.
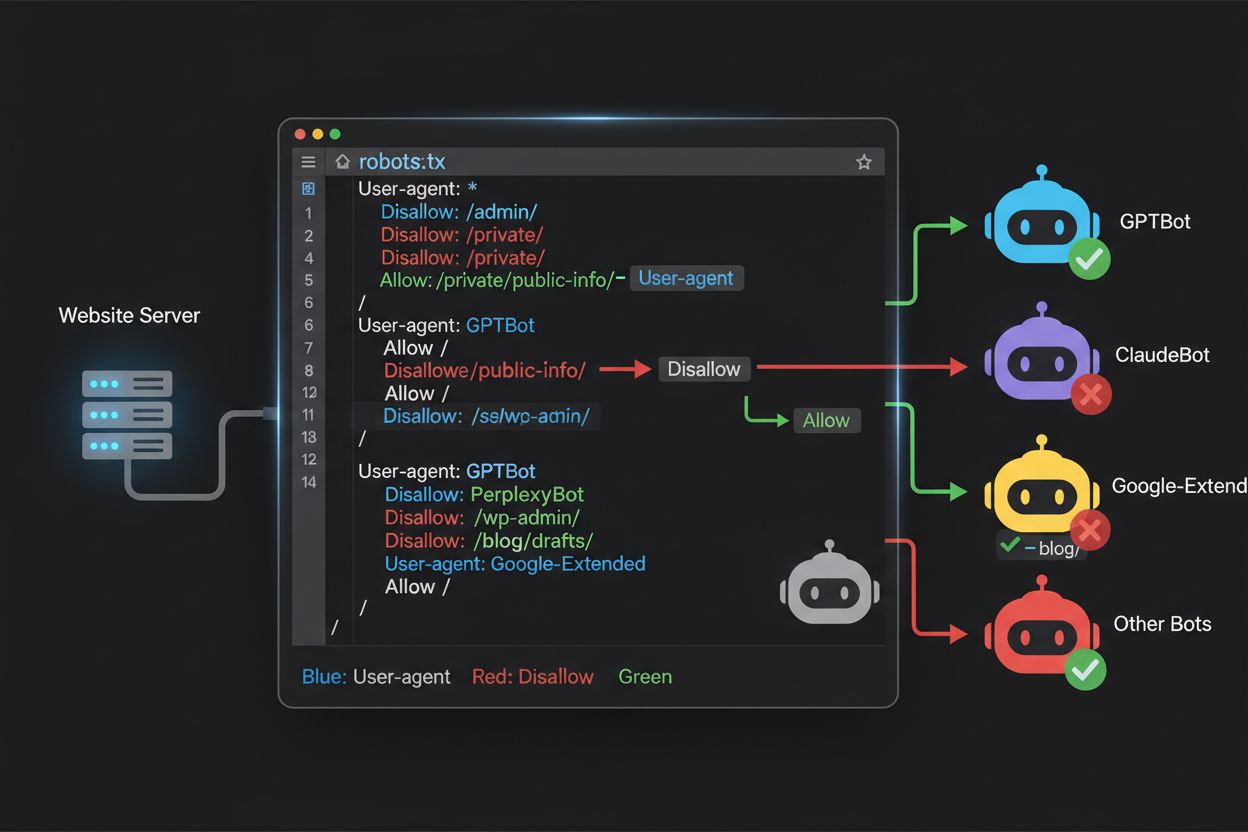
Il file robots.txt, posizionato nella root del tuo dominio (tuodominio.com/robots.txt), utilizza una sintassi semplice per comunicare le preferenze di crawling ai bot che rispettano il protocollo. Ogni regola inizia con una direttiva User-Agent che specifica il bot a cui si applica, seguita da una o più direttive Disallow che indicano quali percorsi il bot non può accedere. Per bloccare tutti i principali crawler di training IA consentendo l’accesso ai motori di ricerca tradizionali, crea blocchi User-Agent separati per ogni bot di training da escludere: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended e altri, ciascuno con “Disallow: /” per impedirgli di accedere a qualsiasi contenuto del sito. Contemporaneamente, assicurati che i crawler di ricerca legittimi come Googlebot, Bingbot e le varianti focalizzate sulla ricerca come OAI-SearchBot non siano bloccati, così da permettere l’indicizzazione e il traffico. Un robots.txt ben configurato dovrebbe anche includere un riferimento Sitemap che punti alla sitemap XML, aiutando i motori di ricerca a scoprire e indicizzare efficacemente i tuoi contenuti. L’importanza di una configurazione corretta non può essere sottovalutata—un solo errore di sintassi, un carattere fuori posto o uno user agent errato può vanificare tutta la strategia di blocco, consentendo ai crawler indesiderati l’accesso ai tuoi contenuti e bloccando eventuali fonti di traffico legittime. Testare la configurazione prima della pubblicazione non è opzionale, ma essenziale, per assicurarsi che il robots.txt abbia l’effetto desiderato.
# Blocca i crawler di training IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Consenti i motori di ricerca tradizionali
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Riferimento Sitemap
Sitemap: https://yoursite.com/sitemap.xml
Molti editori affrontano una decisione più complessa: vogliono mantenere la visibilità nei risultati di ricerca IA e ricevere il traffico referral che queste piattaforme generano, ma desiderano impedire che i loro contenuti vengano usati per addestrare modelli IA che competono con il loro business. Questa strategia di blocco selettivo richiede di distinguere tra crawler di ricerca e crawler di training della stessa azienda—ad esempio, consentire OAI-SearchBot di OpenAI (che alimenta la ricerca di ChatGPT e restituisce traffico) ma bloccare GPTBot (che addestra il modello sottostante). Allo stesso modo, puoi consentire il crawler di ricerca di Perplexity ma bloccare le sue operazioni di training, oppure consentire Claude-Web per le ricerche attivate dagli utenti ma bloccare le attività di training di ClaudeBot. Il razionale aziendale è chiaro: i crawler di ricerca operano con rapporti crawl-to-refer molto più bassi perché sono progettati per generare traffico verso il tuo sito, mentre i crawler di training consumano contenuti su larga scala con benefici minimi in cambio. Questo approccio richiede una configurazione attenta e un monitoraggio costante, dato che le aziende possono cambiare strategie o introdurre nuovi user agent che confondono la distinzione tra ricerca e training. Gli editori che adottano questa strategia dovrebbero controllare regolarmente i log del server per verificare che i crawler desiderati accedano ai contenuti e che quelli bloccati vengano effettivamente esclusi, adattando il robots.txt man mano che lo scenario IA evolve e nuovi attori entrano nel mercato.
# Consenti i crawler di ricerca IA
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blocca i crawler di training
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Anche i webmaster più esperti commettono spesso errori di configurazione che annullano completamente la strategia del robots.txt, lasciando i contenuti esposti proprio ai crawler che si voleva bloccare. Il primo errore comune è creare righe User-Agent isolate senza direttive Disallow corrispondenti—ad esempio, scrivere “User-Agent: GPTBot” su una riga e poi iniziare subito una nuova regola senza specificare cosa dovrebbe essere vietato a GPTBot, lasciandolo di fatto non bloccato. Il secondo errore riguarda il posizionamento, il nome o la sensibilità alle maiuscole: il file deve chiamarsi esattamente “robots.txt” (minuscolo), essere nella root del dominio e restituire codice HTTP 200—se si trova in una sottocartella o si chiama “Robots.txt” o “robots.TXT” sarà invisibile ai crawler. Il terzo errore consiste nell’inserire righe vuote all’interno di un blocco di regole, che molti parser robots.txt interpretano come fine della regola, ignorando o applicando male le direttive successive. Il quarto errore riguarda la sensibilità delle maiuscole nei percorsi delle URL: mentre i nomi degli user agent non sono case-sensitive, i percorsi nelle direttive Disallow lo sono; quindi “Disallow: /Admin” non bloccherà “/admin” o “/ADMIN”. Il quinto errore è l’uso scorretto dei caratteri jolly: l’asterisco (*) corrisponde a qualsiasi sequenza di caratteri, ma molti editori lo usano male scrivendo “Disallow: .pdf” invece che “Disallow: /.pdf” o “Disallow: /*pdf” per bloccare correttamente le estensioni. Inoltre, alcuni editori creano regole troppo complesse con più direttive Disallow che si contraddicono, o non tengono conto di parametri URL e query string, bloccando così contenuti legittimi o lasciando accessibili contenuti indesiderati. Testare la configurazione con appositi validatori robots.txt prima della pubblicazione consente di intercettare questi errori prima che influiscano sulla crawlabilità del sito.
Errori comuni da evitare:
Google-Extended rappresenta un caso particolare nella configurazione del robots.txt perché si comporta come un token di controllo più che come un crawler tradizionale, e comprenderne la distinzione è fondamentale per bloccare con consapevolezza. Diversamente da Googlebot, che esegue la scansione per l’indicizzazione dei risultati di ricerca Google, Google-Extended è un segnale che controlla se i tuoi contenuti possano essere utilizzati per addestrare i modelli IA Gemini di Google e alimentare la funzione AI Overviews nei risultati di ricerca. Bloccare Google-Extended impedisce ai tuoi contenuti di essere usati per il training di Gemini e per la generazione degli AI Overviews, ma non influisce sulla tua visibilità nei risultati classici di ricerca Google—Googlebot continuerà a indicizzare normalmente i tuoi contenuti. Il compromesso è significativo: bloccare Google-Extended significa che i tuoi contenuti non appariranno negli AI Overviews, sempre più presenti nei risultati Google e potenzialmente generatori di traffico, ma protegge i tuoi contenuti dal training di modelli concorrenti. Al contrario, consentire Google-Extended significa che i tuoi contenuti potranno comparire negli AI Overviews (potenzialmente generando traffico) ma contribuiranno anche all’addestramento di Gemini, che potrebbe in futuro competere con i tuoi contenuti o il tuo business. Gli editori dovrebbero valutare attentamente la propria situazione—per le testate giornalistiche o i creatori di contenuti che dipendono dal traffico diretto potrebbe essere vantaggioso bloccare Google-Extended, mentre altri potrebbero apprezzare la maggiore visibilità e il potenziale traffico degli AI Overviews. Questa decisione va presa consapevolmente, non in modo predefinito, perché incide profondamente sulla visibilità e il traffico a lungo termine nel sistema di ricerca Google.
Testare la configurazione del robots.txt prima della pubblicazione in produzione è assolutamente fondamentale, perché eventuali errori possono avere conseguenze molto ampie sia sulla visibilità nei motori di ricerca sia sulla protezione dei contenuti. Google Search Console offre un tester robots.txt integrato che consente di verificare se specifici user agent possono accedere a determinati URL del tuo sito—puoi inserire uno user agent come “GPTBot” e un percorso URL, e Google ti dirà se il bot sarebbe consentito o bloccato secondo la configurazione attuale. Il Merkle Robots.txt Tester offre funzioni simili con un’interfaccia user-friendly e spiegazioni dettagliate di come vengono interpretate le regole. TechnicalSEO.com propone un altro strumento gratuito che valida la sintassi del robots.txt e mostra come vengono trattati i diversi bot. Per monitoraggi più avanzati, Knowatoa AI Search Console offre strumenti specializzati per tracciare l’attività dei crawler IA e validare la configurazione rispetto ai bot che si desidera bloccare. Il flusso di validazione dovrebbe includere il caricamento del robots.txt in un ambiente di staging, la verifica che le pagine critiche restino accessibili, la conferma che i bot IA da bloccare siano effettivamente esclusi e il monitoraggio dei log del server per eventuali attività inattese. Questa fase di test deve includere anche il controllo del riferimento alla Sitemap e che i motori di ricerca possano ancora accedere ai contenuti normalmente—l’obiettivo è bloccare i crawler di training IA senza bloccare accidentalmente il traffico di ricerca legittimo. Solo dopo test approfonditi si dovrebbe pubblicare la configurazione in produzione, monitorando comunque i log per la prima settimana per intercettare eventuali problemi.
Strumenti di test:
Sebbene robots.txt sia una valida prima linea di difesa, è importante capire che opera su base volontaria—i bot che rispettano il protocollo seguiranno le tue direttive, ma i crawler malevoli o progettati male potrebbero ignorarlo completamente e accedere comunque ai tuoi contenuti. Secondo i dati di settore, robots.txt blocca con successo circa il 40-60% dei crawler indesiderati, il che significa che il 40-60% dei bot ignora o aggira il protocollo. Per chi ha bisogno di una protezione più solida, diventano necessari livelli aggiuntivi di difesa. Il Web Application Firewall (WAF) di Cloudflare consente di creare regole per bloccare il traffico in base agli user agent, agli indirizzi IP o a pattern comportamentali, offrendo protezione contro i bot che ignorano il robots.txt. Strumenti a livello server come .htaccess (su Apache) o configurazioni equivalenti su Nginx permettono di bloccare specifici user agent o range IP prima ancora che la richiesta arrivi all’applicazione. Il blocco IP può essere efficace se identifichi i range utilizzati da determinati crawler, ma richiede manutenzione costante poiché le infrastrutture dei crawler cambiano. Tool come Fail2ban possono bloccare automaticamente gli IP che mostrano comportamenti sospetti, come richieste ad alta velocità o accesso a percorsi sensibili. Tuttavia, implementare queste protezioni aggiuntive richiede attenzione—un blocco troppo aggressivo può escludere accidentalmente traffico legittimo, compresi utenti reali che accedono tramite VPN o proxy aziendali condivisi con i crawler. L’approccio più efficace combina robots.txt come richiesta cortese, blocco degli user agent a livello server per i bot che ignorano il robots.txt e monitoraggio comportamentale per identificare i crawler più sofisticati che mascherano lo user agent o utilizzano IP distribuiti. Gli editori dovrebbero implementare questi livelli gradualmente, testando ciascuno per evitare di bloccare traffico valido e per raggiungere gli obiettivi di protezione dei contenuti.
Comprendere chi accede effettivamente al tuo sito è essenziale per validare che la configurazione del robots.txt funzioni come previsto e per individuare nuovi crawler che potrebbero richiedere il blocco. L’analisi dei log del server è il metodo principale per questo monitoraggio: i log del server web (Apache, Nginx o equivalenti) contengono registrazioni dettagliate di ogni richiesta, compresi user agent, indirizzo IP, timestamp e risorsa richiesta. Puoi usare strumenti come grep per cercare user agent specifici; ad esempio, “grep ‘GPTBot’ /var/log/apache2/access.log” mostrerà tutte le richieste provenienti da GPTBot, permettendoti di verificare se le regole di blocco funzionano. Analisi più sofisticate possono includere il tasso di crawling dei vari bot, le pagine accessibili e il rispetto delle direttive robots.txt. Soluzioni di monitoraggio automatico possono analizzare costantemente i log e avvisarti quando compaiono nuovi crawler inattesi, particolarmente utile dato il ritmo a cui evolve il panorama dei crawler IA. Alcuni editori utilizzano piattaforme di aggregazione log come ELK Stack, Splunk o soluzioni cloud per centralizzare e analizzare l’attività dei crawler su più server. Il cambiamento rapido nel panorama dei crawler IA rende il monitoraggio un’attività continua, non una tantum—nuovi bot emergono regolarmente, gli user agent cambiano e il comportamento dei crawler evolve con le strategie delle aziende. Stabilire una routine regolare di revisione dei log (settimanale o mensile) aiuta a restare aggiornati e a modificare il robots.txt in modo proattivo, evitando di scoprire problemi solo dopo che hanno avuto impatto sul sito.
La configurazione del robots.txt per i crawler IA è fondamentalmente una decisione di revenue, e merita la stessa attenzione strategica che si dedicherebbe a qualsiasi scelta aziendale con importanti implicazioni economiche. Consentire ai crawler di training accesso illimitato ai tuoi contenuti significa che i modelli IA addestrati sui tuoi dati potrebbero in futuro competere con il tuo traffico e le tue entrate—se il tuo modello di business si basa su traffico diretto, visibilità nei motori di ricerca o pubblicità, stai di fatto fornendo dati gratuiti per prodotti concorrenti. Al contrario, bloccare tutti i crawler IA significa perdere visibilità nei risultati di ricerca IA e il traffico referral degli assistenti IA, che rappresentano una quota crescente della scoperta di contenuti. La strategia ottimale dipende dal tuo modello di business: gli editori che vivono di pubblicità potrebbero trarre vantaggio dal consentire i crawler di ricerca (che generano traffico e impression pubblicitarie) ma bloccare quelli di training (che non generano traffico). Gli editori in abbonamento potrebbero optare per una posizione più aggressiva, bloccando la maggior parte dei crawler IA per proteggere i contenuti da sintesi o repliche da parte dei sistemi IA. Chi punta su visibilità e thought leadership potrebbe invece accogliere la visibilità nei risultati IA come forma di distribuzione. L’importante è prendere questa decisione in modo intenzionale e non per default—molti editori non hanno mai configurato robots.txt per i crawler IA, consentendo di fatto l’accesso a tutti i bot, e così facendo hanno deciso passivamente di contribuire al training IA senza una scelta attiva. Considera anche l’implementazione di schema markup per garantire la corretta attribuzione quando i tuoi contenuti sono usati dai sistemi IA, favorendo che traffico e credito tornino al tuo sito anche quando i contenuti sono citati dagli assistenti IA. La configurazione del robots.txt dovrebbe riflettere una strategia aziendale consapevole, rivista e aggiornata regolarmente in base all’evoluzione dello scenario IA e delle tue priorità di business.
Il panorama dei crawler IA evolve a un ritmo senza precedenti, con nuove aziende che lanciano prodotti IA, altre che introducono nuovi crawler e user agent che cambiano o si moltiplicano regolarmente. Il tuo robots.txt non deve essere un file da impostare e dimenticare, ma un documento vivo da rivedere almeno ogni trimestre. Stabilisci un processo per monitorare gli annunci di settore su nuovi crawler IA, iscriviti a newsletter o blog che seguono queste novità e controlla regolarmente i log del server per individuare user agent sconosciuti che potrebbero essere nuovi crawler. Quando scopri nuovi crawler, analizzane lo scopo e il modello di business per capire se sono compatibili con la tua strategia di protezione dei contenuti, poi aggiorna di conseguenza il robots.txt. Monitora anche l’efficacia della configurazione tracciando metriche come il volume di traffico dei crawler, il rapporto tra richieste dei bot e traffico utente e qualsiasi variazione nella visibilità organica o nel traffico referral dai risultati IA. Alcuni editori scoprono che la strategia iniziale va rivista dopo qualche mese di dati reali—magari il blocco di un crawler ha avuto effetti inattesi, o consentirne altri genera più traffico di quanto previsto. Sii pronto a iterare la strategia in base ai risultati effettivi, non solo alle ipotesi. Infine, comunica la strategia del robots.txt ai referenti della tua organizzazione—team SEO, team contenuti e management devono comprenderne le motivazioni, così che le decisioni restino coerenti e intenzionali anche nel tempo. Questa attenzione costante alla gestione dei crawler garantisce che la strategia di protezione dei contenuti resti efficace e allineata agli obiettivi aziendali mentre lo scenario IA continua a trasformarsi.
No. Bloccare i crawler di training IA come GPTBot, ClaudeBot e CCBot non influisce sul tuo posizionamento su Google o Bing. I motori di ricerca tradizionali utilizzano crawler diversi (Googlebot, Bingbot) che operano in modo indipendente. Blocca solo questi se desideri sparire completamente dai risultati di ricerca.
I principali crawler di OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) e Perplexity (PerplexityBot) dichiarano ufficialmente di rispettare le direttive robots.txt. Tuttavia, bot più piccoli o meno trasparenti possono ignorare la tua configurazione, motivo per cui esistono strategie di protezione a più livelli.
Dipende dalla tua strategia. Bloccare solo i crawler di training (GPTBot, ClaudeBot, CCBot) protegge i tuoi contenuti dall’addestramento dei modelli, consentendo ai crawler focalizzati sulla ricerca di aiutarti a comparire nei risultati di ricerca IA. Il blocco totale ti esclude completamente dagli ecosistemi IA.
Rivedi la tua configurazione almeno ogni trimestre. Le aziende IA introducono regolarmente nuovi crawler. Anthropic ha unito i bot 'anthropic-ai' e 'Claude-Web' in 'ClaudeBot', dando temporaneamente a quest’ultimo accesso illimitato ai siti che non avevano aggiornato le regole.
Robots.txt è un file nella root del dominio che si applica a tutte le pagine, mentre i meta tag robots sono direttive HTML su singole pagine. Robots.txt viene controllato per primo e può impedire ai crawler di accedere a una pagina, mentre i meta tag vengono letti solo se la pagina viene raggiunta. Usa entrambi per un controllo completo.
Sì. Puoi utilizzare regole Disallow specifiche per percorso nel robots.txt (ad esempio, 'Disallow: /premium/' per bloccare solo i contenuti premium) oppure usare meta tag robots su singole pagine. Così puoi proteggere i contenuti sensibili consentendo ai crawler l’accesso ad altre aree.
Se un bot ignora il robots.txt, avrai bisogno di metodi di protezione aggiuntivi come blocco a livello server (.htaccess), blocco IP o regole WAF. Robots.txt ferma circa il 40-60% dei crawler indesiderati, quindi la protezione multilivello è importante per una difesa completa.
Utilizza strumenti di test come il tester robots.txt di Google Search Console, il Merkle Robots.txt Tester o TechnicalSEO.com per validare la tua configurazione. Monitora i log del server per l’attività dei crawler e verifica che i bot bloccati vengano effettivamente esclusi e quelli ammessi accedano ai tuoi contenuti.
Robots.txt è solo il primo passo. Usa AmICited per tracciare quali sistemi IA citano i tuoi contenuti, con quale frequenza ti menzionano e assicurati una corretta attribuzione su GPTs, Perplexity, Google AI Overviews e altro ancora.
Scopri come permettere o bloccare selettivamente i crawler AI in base agli obiettivi aziendali. Implementa l’accesso differenziale dei crawler per proteggere i ...

Scopri come i Web Application Firewall offrono un controllo avanzato sui crawler AI oltre robots.txt. Implementa regole WAF per proteggere i tuoi contenuti dall...

Scopri come verificare se crawler AI come ChatGPT, Claude e Perplexity possono accedere ai contenuti del tuo sito web. Scopri metodi di test, strumenti e best p...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.