
Token
Scopri cosa sono i token nei modelli linguistici. I token sono unità fondamentali di elaborazione del testo nei sistemi di IA, che rappresentano parole, sottopa...
12 min di lettura

Scopri come i limiti dei token influenzano le prestazioni dell’IA e apprendi strategie pratiche per l’ottimizzazione dei contenuti, tra cui RAG, chunking e tecniche di sintesi.
I token sono i mattoni fondamentali che i modelli di IA utilizzano per elaborare e comprendere le informazioni. Invece di lavorare con parole o frasi complete, i grandi modelli linguistici suddividono il testo in unità più piccole chiamate token, che possono essere singoli caratteri, sottoparole o parole complete a seconda dell’algoritmo di tokenizzazione. A ciascun token viene assegnato un identificatore numerico univoco che il modello utilizza internamente per i calcoli. Questo processo di tokenizzazione è essenziale perché consente ai sistemi di IA di gestire input di lunghezza variabile in modo efficiente e di mantenere un’elaborazione coerente tra diversi tipi di contenuti. Comprendere i token è fondamentale per chiunque lavori con sistemi di IA, poiché influiscono direttamente su prestazioni, costi e qualità dei risultati che è possibile ottenere.
I diversi modelli di IA hanno limiti di token molto diversi, che definiscono la quantità massima di informazioni che possono essere elaborate in una singola richiesta. Questi limiti si sono evoluti notevolmente negli ultimi anni, con i modelli più recenti che supportano finestre di contesto significativamente più ampie. Il limite dei token include sia i token di input (il tuo prompt e i dati) sia i token di output (la risposta del modello), creando un budget condiviso che deve essere gestito con attenzione. Comprendere questi limiti è essenziale per scegliere il modello giusto per il tuo caso d’uso e pianificare di conseguenza l’architettura della tua applicazione.
| Modello | Limite Token | Caso d’Uso Principale | Livello di Costo |
|---|---|---|---|
| GPT-3.5 Turbo | 4.096 | Conversazioni brevi, compiti rapidi | Basso |
| GPT-4 | 8.192 | Applicazioni standard, complessità moderata | Medio |
| GPT-4 Turbo | 128.000 | Documenti lunghi, analisi complesse | Alto |
| Claude 3.5 Sonnet | 200.000 | Documenti estesi, analisi approfondite | Alto |
| Gemini 1.5 Pro | 1.000.000 | Dati massivi, interi libri, analisi video | Molto Alto |
Considerazioni chiave nella valutazione dei limiti dei token:
I limiti dei token creano vincoli significativi che influenzano direttamente l’accuratezza, l’affidabilità e la convenienza economica delle applicazioni di IA. Quando si supera il limite di token di un modello, l’applicazione fallisce completamente—non c’è alcuna degradazione graduale o elaborazione parziale. Anche restando entro i limiti, approcci ingenui come la semplice troncatura possono compromettere gravemente le prestazioni eliminando contesti critici di cui il modello ha bisogno per generare risposte accurate. Questo è particolarmente problematico in ambiti come l’analisi legale, la ricerca medica e l’ingegneria del software, dove la mancanza anche di un solo dettaglio importante può portare a conclusioni errate. La sfida si complica ulteriormente se si considera che diversi tipi di contenuto consumano token a velocità diverse—dati strutturati come codice o JSON richiedono molti più token rispetto al testo in inglese semplice a causa di simboli e formattazione.
La troncatura è il metodo più semplice per gestire i limiti dei token—si elimina semplicemente il contenuto in eccesso quando si supera la capacità del modello. Sebbene sia facile da implementare, questo approccio comporta rischi significativi. Quando si tronca un testo, si perdono inevitabilmente informazioni e il modello non ha modo di sapere cosa è stato rimosso. Questo può portare ad analisi incomplete, contesto mancante e allucinazioni in cui il modello genera informazioni plausibili ma errate per colmare le lacune nella comprensione.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Una strategia di troncatura più sofisticata distingue tra contenuti essenziali e opzionali. È possibile dare priorità agli elementi indispensabili come la query attuale dell’utente e le istruzioni principali, quindi aggiungere contesto opzionale come la cronologia delle conversazioni solo se lo spazio lo consente. Questo approccio preserva le informazioni critiche pur rispettando i limiti dei token.
Invece di troncare, il chunking suddivide il contenuto in blocchi più piccoli e gestibili che possono essere elaborati in modo indipendente o selettivo. Il chunking a dimensione fissa suddivide il testo in segmenti uniformi, mentre il chunking semantico utilizza gli embedding per identificare punti di interruzione naturali basati sul significato anziché su conteggi arbitrari di token. Le finestre scorrevoli con sovrapposizione preservano il contesto tra i chunk, assicurando che le informazioni importanti che si estendono sui confini dei chunk non vadano perse.
Il chunking gerarchico crea più livelli di astrazione—paragrafi a livello più fine, sezioni al livello successivo e capitoli al livello più alto. Questo approccio consente strategie di recupero sofisticate in cui è possibile individuare rapidamente le sezioni rilevanti senza elaborare l’intero documento. Quando combinato con database vettoriali e ricerca semantica, il chunking diventa un potente strumento per gestire grandi basi di conoscenza mantenendo rilevanza e accuratezza.
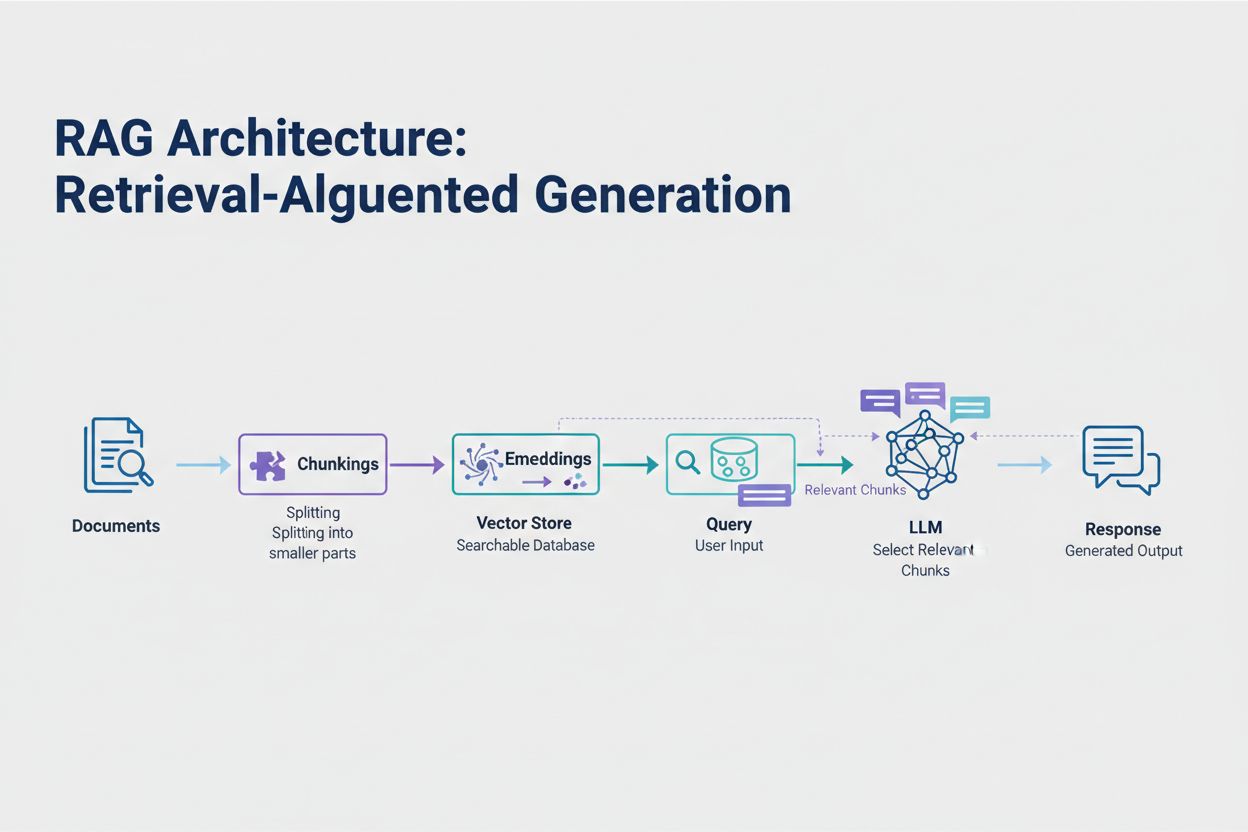
La Retrieval-Augmented Generation (RAG) rappresenta l’approccio moderno più efficace per gestire i limiti dei token. Invece di provare a inserire tutti i dati nella finestra di contesto del modello, RAG recupera solo le informazioni più rilevanti al momento della richiesta. Il processo inizia convertendo i tuoi documenti in embedding—rappresentazioni numeriche che catturano il significato semantico. Questi embedding vengono memorizzati in un database vettoriale, consentendo ricerche per similarità rapide.
Quando un utente invia una query, il sistema crea un embedding della domanda e recupera i chunk di documento più rilevanti dallo store vettoriale. Solo questi chunk rilevanti vengono inseriti nel prompt insieme alla domanda dell’utente, riducendo drasticamente il consumo di token e migliorando l’accuratezza. Ad esempio, analizzare un contratto legale di 100 pagine con RAG potrebbe richiedere solo 3-5 clausole chiave nel prompt, rispetto alle migliaia di token necessari per includere l’intero documento.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
La sintesi condensa contenuti lunghi preservando le informazioni essenziali, riducendo efficacemente il consumo di token. La sintesi estrattiva seleziona le frasi chiave dal testo originale, mentre la sintesi astrattiva genera nuovo testo conciso che cattura le idee principali. La sintesi gerarchica crea più livelli di riassunto—prima riassumendo le singole sezioni, poi combinando tali riassunti in panoramiche di livello superiore. Questo approccio funziona particolarmente bene per documenti strutturati come articoli scientifici o report tecnici.
La compressione del contesto adotta un approccio diverso rimuovendo ridondanze e contenuti superflui mantenendo l’espressione originale. Gli approcci basati su knowledge graph estraggono entità e relazioni dal testo, quindi ricostruiscono il contesto utilizzando solo i fatti più rilevanti. Queste tecniche possono ottenere una riduzione dei token del 40-60% mantenendo la precisione semantica, rendendole preziose per l’ottimizzazione dei costi nei sistemi in produzione.
La gestione dei token influisce direttamente sui costi della tua applicazione di IA. Ogni token consumato durante l’inferenza comporta un addebito e i costi crescono linearmente con l’uso dei token. Monitorare il consumo dei token è essenziale per comprendere la struttura dei costi e identificare opportunità di ottimizzazione. Molte piattaforme di IA offrono ora strumenti di conteggio dei token e dashboard in tempo reale che monitorano i modelli di utilizzo, aiutandoti a individuare quali query o funzionalità consumano più token.
Un monitoraggio efficace rivela opportunità di ottimizzazione—magari alcuni tipi di query superano costantemente i limiti di token, o alcune funzionalità consumano risorse in misura sproporzionata. Monitorando questi modelli, puoi prendere decisioni informate su quale strategia di ottimizzazione implementare. Alcune applicazioni beneficiano dell’instradamento delle richieste più grandi verso modelli più capaci (ma più costosi), mentre altre traggono maggiore vantaggio dall’implementazione di RAG o della sintesi. La chiave è misurare le prestazioni e i costi effettivi per validare le scelte di ottimizzazione.
La scelta della strategia di gestione dei token più adatta dipende dal caso d’uso specifico, dai requisiti di prestazione e dai vincoli di costo. Le applicazioni che richiedono alta accuratezza con risposte documentate beneficiano soprattutto di RAG, che preserva la fedeltà delle informazioni gestendo il consumo dei token. Le applicazioni conversazionali di lunga durata beneficiano di tecniche di memory buffering che sintetizzano la cronologia delle conversazioni preservando decisioni e contesto chiave. Le applicazioni ricche di documenti come l’analisi legale o gli strumenti di ricerca spesso traggono vantaggio dalla sintesi gerarchica combinata con chunking semantico.
Test e validazione sono fondamentali prima di implementare qualsiasi strategia di gestione dei token in produzione. Crea casi di test che superano i limiti di token del tuo modello, poi valuta come le varie strategie influiscono su accuratezza, latenza e costi. Misura metriche come rilevanza delle risposte, accuratezza fattuale ed efficienza dei token per assicurarti che l’approccio scelto soddisfi i tuoi requisiti. Gli errori comuni includono la sintesi troppo aggressiva che fa perdere dettagli critici, sistemi di recupero che non trovano informazioni rilevanti e strategie di chunking che suddividono il contenuto in punti semanticamente inappropriati.
I limiti dei token continuano ad aumentare man mano che i modelli diventano più sofisticati ed efficienti. Tecniche emergenti come i meccanismi di attenzione sparsa e i transformer efficienti promettono di ridurre il costo computazionale dell’elaborazione di finestre di contesto ampie. I modelli multimodali che gestiscono testo, immagini, audio e video contemporaneamente introducono nuove sfide e opportunità di tokenizzazione. I reasoning token—token speciali utilizzati dai modelli per “ragionare” su problemi complessi—rappresentano una nuova categoria di consumo di token che consente una risoluzione dei problemi più sofisticata ma richiede una gestione attenta.
La direzione è chiara: man mano che le finestre di contesto si espandono e l’elaborazione dei token diventa più efficiente, il collo di bottiglia si sposta dalla capacità grezza alla selezione intelligente dei contenuti. Il futuro appartiene a sistemi in grado di identificare e recuperare efficacemente le informazioni più rilevanti da enormi basi di conoscenza, piuttosto che a sistemi che elaborano semplicemente volumi maggiori di dati. Questo rende le tecniche come RAG e la ricerca semantica sempre più importanti per costruire applicazioni di IA scalabili e convenienti.
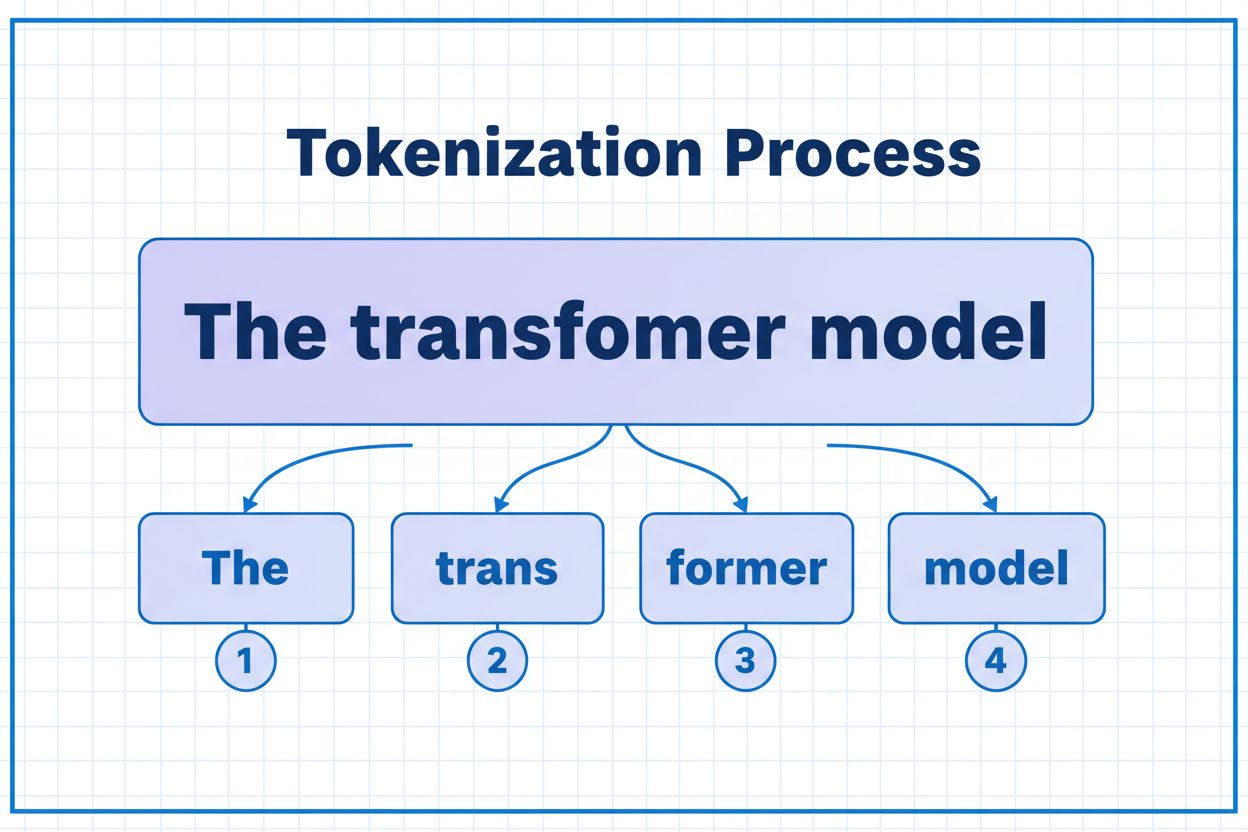
Un token è la più piccola unità di dati che un modello di IA elabora. I token possono essere singoli caratteri, sottoparole o parole complete a seconda dell'algoritmo di tokenizzazione. Ad esempio, la parola 'transformer' potrebbe essere suddivisa in 'trans' e 'former' come due token separati. A ciascun token viene assegnato un identificatore numerico univoco che il modello utilizza internamente per i calcoli.
I limiti dei token definiscono la quantità massima di informazioni che il tuo modello di IA può elaborare in una singola richiesta. Se superi questo limite, la tua applicazione fallisce completamente. Anche restando entro i limiti, approcci ingenui come la troncatura possono ridurre l'accuratezza rimuovendo contesti critici. I limiti dei token influiscono anche direttamente sui costi, poiché di solito si paga per ogni token utilizzato.
I token di input sono i token presenti nel tuo prompt e nei dati che invii al modello, mentre i token di output sono quelli che il modello genera nella sua risposta. Questi condividono un budget combinato definito dalla finestra di contesto del modello. Se il tuo input utilizza il 90% di una finestra da 128K token, ti resta solo il 10% per l'output del modello.
La troncatura è semplice da implementare ma rischiosa. Rimuove informazioni senza che il modello sappia cosa è stato eliminato, portando ad analisi incomplete e potenziali allucinazioni. Pur essendo utile come ultima risorsa, approcci migliori come RAG, chunking o sintesi preservano la fedeltà delle informazioni gestendo il consumo dei token in modo più efficace.
La Retrieval-Augmented Generation (RAG) recupera solo le informazioni più rilevanti al momento della richiesta anziché includere interi documenti. I tuoi documenti vengono convertiti in embedding e memorizzati in un database vettoriale. Quando un utente invia una query, il sistema recupera solo i chunk rilevanti e li inserisce nel prompt, riducendo drasticamente il consumo di token e migliorando l'accuratezza.
La maggior parte delle piattaforme di IA offre strumenti di conteggio dei token e dashboard in tempo reale per monitorare i modelli di utilizzo. Monitora quali query o funzionalità consumano più token, quindi implementa strategie di ottimizzazione come RAG per applicazioni con molti documenti, sintesi per conversazioni lunghe o instradamento verso modelli più grandi per compiti complessi. Misura le prestazioni effettive e i costi per validare le tue scelte.
I servizi di IA di solito addebitano il costo per ogni token utilizzato. I costi crescono linearmente con l'uso dei token, quindi ottimizzare i token ha un impatto diretto sulle spese. Una riduzione del 20% nel consumo di token si traduce in una riduzione dei costi del 20%. Comprendere l'efficienza dei token ti aiuta a scegliere la strategia di ottimizzazione giusta per i tuoi vincoli di budget.
I limiti dei token continuano ad aumentare man mano che i modelli diventano più sofisticati. Tecniche emergenti come i meccanismi di attenzione sparsa promettono di ridurre i costi computazionali dell'elaborazione di contesti ampi. Il futuro si concentra sulla selezione e il recupero intelligente dei contenuti piuttosto che sulla pura capacità di elaborazione, rendendo tecniche come RAG sempre più importanti per applicazioni di IA scalabili.
Comprendi l'efficienza dei token e monitora come i modelli di IA citano il tuo brand con la piattaforma completa di monitoraggio delle citazioni IA di AmICited.
Scopri cosa sono i token nei modelli linguistici. I token sono unità fondamentali di elaborazione del testo nei sistemi di IA, che rappresentano parole, sottopa...

Scopri come i modelli di intelligenza artificiale elaborano il testo tramite tokenizzazione, embedding, blocchi transformer e reti neurali. Comprendi l'intera p...
Scopri come ottimizzare la leggibilità dei contenuti per i sistemi di IA, ChatGPT, Perplexity e i motori di ricerca basati su IA. Scopri le best practice su str...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.