
Adattamento AI in Tempo Reale
Scopri l'adattamento AI in tempo reale: la tecnologia che consente ai sistemi AI di apprendere continuamente dagli eventi e dai dati attuali. Esplora come funzi...
8 min di lettura

Confronta l’ottimizzazione dei dati di addestramento e le strategie di recupero in tempo reale per l’IA. Scopri quando utilizzare il fine-tuning rispetto a RAG, le implicazioni sui costi e gli approcci ibridi per prestazioni IA ottimali.
L’ottimizzazione dei dati di addestramento e il recupero in tempo reale rappresentano approcci fondamentalmente diversi per dotare i modelli di IA di conoscenza. L’ottimizzazione dei dati di addestramento consiste nell’incorporare la conoscenza direttamente nei parametri di un modello tramite fine-tuning su dataset specifici di dominio, creando una conoscenza statica che rimane invariata dopo il completamento dell’addestramento. Il recupero in tempo reale, invece, mantiene la conoscenza esterna al modello e recupera dinamicamente le informazioni rilevanti durante l’inferenza, consentendo l’accesso a informazioni dinamiche che possono variare tra le richieste. La distinzione chiave risiede in quando la conoscenza viene integrata nel modello: l’ottimizzazione dei dati di addestramento avviene prima della messa in produzione, mentre il recupero in tempo reale avviene ad ogni chiamata di inferenza. Questa differenza fondamentale si riflette in ogni aspetto dell’implementazione, dai requisiti infrastrutturali alle caratteristiche di accuratezza fino alle considerazioni di compliance. Comprendere questa distinzione è essenziale per le organizzazioni che devono decidere quale strategia di ottimizzazione si allinea meglio con i propri casi d’uso e vincoli specifici.
L’ottimizzazione dei dati di addestramento agisce regolando sistematicamente i parametri interni di un modello tramite l’esposizione a dataset curati e specifici di dominio durante il processo di fine-tuning. Quando un modello incontra ripetutamente esempi di addestramento, interiorizza gradualmente pattern, terminologia e competenze di dominio tramite backpropagation e aggiornamenti del gradiente che rimodellano i meccanismi di apprendimento del modello. Questo processo consente alle organizzazioni di codificare conoscenze specialistiche—che si tratti di terminologia medica, quadri giuridici o logiche aziendali proprietarie—direttamente nei pesi e nei bias del modello. Il modello risultante diventa altamente specializzato per il proprio dominio di destinazione, spesso raggiungendo prestazioni paragonabili a modelli molto più grandi; una ricerca di Snorkel AI ha dimostrato che modelli più piccoli ottimizzati tramite fine-tuning possono performare in modo equivalente a modelli 1.400 volte più grandi. Le caratteristiche chiave dell’ottimizzazione dei dati di addestramento includono:
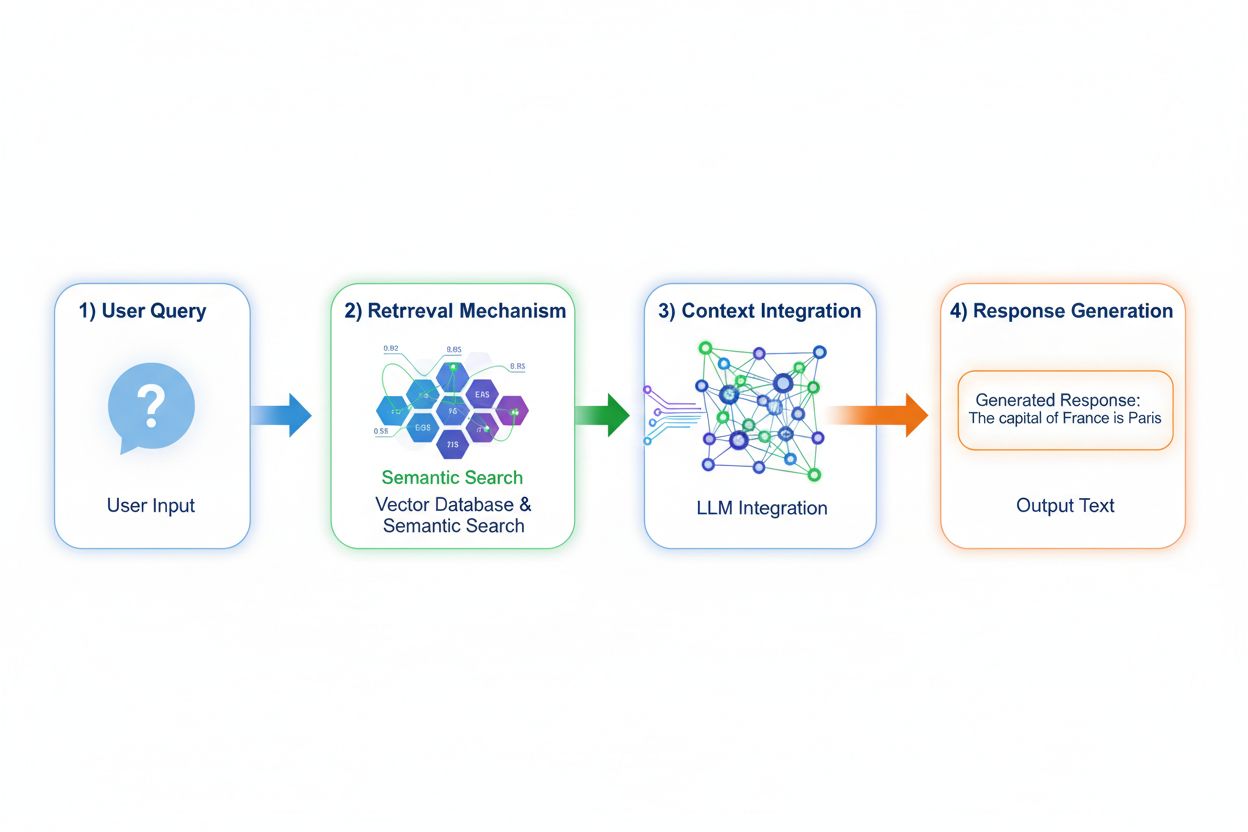
Retrieval Augmented Generation (RAG) cambia radicalmente il modo in cui i modelli accedono alla conoscenza implementando un processo in quattro fasi: codifica della query, ricerca semantica, ranking del contesto e generazione con grounding. Quando un utente invia una query, RAG la converte prima in una rappresentazione vettoriale densa tramite modelli di embedding, poi effettua una ricerca in un database vettoriale contenente documenti indicizzati o fonti di conoscenza. La fase di recupero utilizza la ricerca semantica per trovare passaggi contestualmente rilevanti invece del semplice matching di parole chiave, classificando i risultati in base ai punteggi di rilevanza. Infine, il modello genera risposte mantenendo riferimenti espliciti alle fonti recuperate, ancorando il proprio output a dati reali invece che a parametri appresi. Questa architettura consente ai modelli di accedere a informazioni che non esistevano durante l’addestramento, rendendo RAG particolarmente prezioso per applicazioni che richiedono dati sempre aggiornati, informazioni proprietarie o basi di conoscenza frequentemente modificate. Il meccanismo RAG trasforma essenzialmente il modello da un contenitore statico di conoscenza a un sintetizzatore dinamico di informazioni che può incorporare nuovi dati senza essere riaddestrato.
I profili di accuratezza e di allucinazione di questi approcci differiscono sensibilmente, impattando l’implementazione reale. L’ottimizzazione dei dati di addestramento produce modelli con profonda comprensione del dominio ma limitata capacità di riconoscere i propri limiti di conoscenza; quando un modello fine-tuned affronta domande fuori dalla propria distribuzione di addestramento, può generare con sicurezza informazioni plausibili ma errate. RAG riduce in modo sostanziale le allucinazioni ancorando le risposte ai documenti recuperati—il modello non può dichiarare informazioni che non compaiono nella fonte, creando vincoli naturali alla fabbricazione. Tuttavia, RAG introduce altri rischi di accuratezza: se la fase di recupero non trova fonti rilevanti o classifica in alto documenti non pertinenti, il modello genera risposte basate su un contesto scarso. La freschezza dei dati diventa cruciale nei sistemi RAG; l’ottimizzazione dei dati di addestramento cattura uno snapshot statico al momento dell’addestramento, mentre RAG riflette costantemente lo stato attuale dei documenti sorgente. Un’altra differenza riguarda l’attribuzione delle fonti: RAG consente intrinsecamente la citazione e la verifica delle affermazioni, mentre i modelli fine-tuned non possono indicare fonti specifiche per le proprie conoscenze, complicando il fact-checking e la verifica di compliance.
I profili economici di questi approcci generano strutture di costo distinte che le organizzazioni devono valutare attentamente. L’ottimizzazione dei dati di addestramento richiede un costo computazionale elevato iniziale: cluster GPU attivi per giorni o settimane per il fine-tuning dei modelli, servizi di annotazione dati per creare dataset etichettati e competenze di ingegneria ML per progettare pipeline di addestramento efficaci. Una volta addestrato, il costo di servizio resta relativamente basso poiché l’inferenza richiede solo l’infrastruttura standard di serving del modello senza consultazioni esterne. I sistemi RAG invertono questa struttura: costi di training iniziali più bassi in quanto non c’è fine-tuning, ma spese infrastrutturali continue per mantenere database vettoriali, modelli di embedding, servizi di recupero e pipeline di indicizzazione dei documenti. I fattori di costo principali includono:
Le implicazioni per sicurezza e compliance divergono notevolmente tra questi approcci, con impatti significativi nei settori regolamentati. I modelli fine-tuned creano sfide di protezione dei dati poiché i dati di addestramento vengono incorporati nei pesi del modello; estrarre o auditare quali conoscenze contiene richiede tecniche sofisticate e sorgono preoccupazioni sulla privacy quando dati sensibili influenzano il comportamento del modello. La compliance con normative come il GDPR si complica perché il modello “ricorda” i dati di addestramento in modi che resistono alla cancellazione o alla modifica. I sistemi RAG offrono profili di sicurezza differenti: la conoscenza resta in fonti esterne e auditabili invece che nei parametri del modello, abilitando controlli di sicurezza e restrizioni di accesso dirette. Le organizzazioni possono applicare permessi granulari sulle fonti di recupero, auditare quali documenti sono stati consultati per ciascuna risposta e rimuovere rapidamente dati sensibili aggiornando le fonti senza riaddestrare. Tuttavia, RAG introduce rischi legati alla protezione dei database vettoriali, sicurezza dei modelli di embedding e al rischio di fuga di informazioni sensibili nei documenti recuperati. Le organizzazioni sanitarie soggette a HIPAA e le aziende europee soggette a GDPR preferiscono spesso la trasparenza e l’auditabilità di RAG, mentre chi privilegia portabilità del modello e funzionamento offline tende verso il fine-tuning.
La scelta tra questi approcci richiede la valutazione dei vincoli organizzativi e delle caratteristiche dei casi d’uso specifici. Le organizzazioni dovrebbero privilegiare il fine-tuning quando la conoscenza è stabile e non soggetta a frequenti aggiornamenti, quando la latenza di inferenza è critica, quando i modelli devono funzionare offline o in ambienti isolati, o quando sono essenziali stile e formattazione specifici per il dominio. Il recupero in tempo reale diventa preferibile quando la conoscenza varia regolarmente, quando attribuzione delle fonti e auditabilità sono importanti per la compliance, quando la base di conoscenza è troppo ampia per essere efficacemente codificata nei parametri del modello, o quando è necessario aggiornare le informazioni senza riaddestrare il modello. Alcuni casi d’uso illustrano queste distinzioni:
Gli approcci ibridi combinano fine-tuning e RAG per cogliere i vantaggi di entrambe le strategie, mitigando le rispettive limitazioni. Le organizzazioni possono ottimizzare i modelli sulle basi del dominio e sui pattern comunicativi tramite fine-tuning, utilizzando RAG per accedere a informazioni aggiornate e dettagliate—il modello impara come ragionare su un dominio mentre recupera quali fatti specifici incorporare. Questa strategia combinata si rivela particolarmente efficace per applicazioni che richiedono sia competenze specialistiche sia informazioni aggiornate: un bot finanziario ottimizzato su principi e terminologia degli investimenti può recuperare dati di mercato in tempo reale e bilanci aziendali tramite RAG. Esempi di implementazioni ibride includono sistemi sanitari che fanno fine-tuning sulle conoscenze mediche e i protocolli recuperando dati specifici dei pazienti tramite RAG, e piattaforme di ricerca legale che ottimizzano sul ragionamento giuridico recuperando la giurisprudenza aggiornata. I vantaggi sinergici includono minori allucinazioni (grazie al grounding sulle fonti recuperate), migliore comprensione del dominio (dal fine-tuning), inferenza più rapida su query comuni (grazie alla conoscenza fine-tuned) e flessibilità nell’aggiornare informazioni specialistiche senza riaddestramenti. Le organizzazioni adottano sempre più questo approccio di ottimizzazione man mano che le risorse computazionali diventano più accessibili e la complessità delle applicazioni reali richiede sia profondità che attualità.
La capacità di monitorare in tempo reale le risposte dell’IA diventa sempre più cruciale man mano che le organizzazioni implementano queste strategie di ottimizzazione su larga scala, specialmente per comprendere quale approccio offra risultati migliori per casi d’uso specifici. I sistemi di monitoraggio IA tracciano gli output dei modelli, la qualità del recupero e le metriche di soddisfazione degli utenti, consentendo di misurare se i modelli fine-tuned o i sistemi RAG servano meglio le applicazioni. Il tracciamento delle citazioni rivela differenze chiave tra gli approcci: i sistemi RAG generano naturalmente citazioni e riferimenti alle fonti, creando una traccia di controllo dei documenti che hanno influenzato ogni risposta, mentre i modelli fine-tuned non forniscono un meccanismo intrinseco di monitoraggio delle risposte o attribuzione. Questa differenza è fondamentale per la sicurezza del brand e l’intelligence competitiva—le organizzazioni devono sapere come i sistemi IA citano i concorrenti, fanno riferimento ai propri prodotti o attribuiscono le informazioni alle fonti. Strumenti come AmICited.com colmano questa lacuna monitorando come i sistemi IA citano marchi e aziende attraverso diverse strategie di ottimizzazione, fornendo monitoraggio in tempo reale di pattern e frequenza delle citazioni. Implementando un monitoraggio completo, le organizzazioni possono verificare se la strategia di ottimizzazione scelta (fine-tuning, RAG o ibrida) migliori davvero l’accuratezza delle citazioni, riduca le allucinazioni sui concorrenti e mantenga un’attribuzione appropriata alle fonti autorevoli. Questo approccio data-driven al monitoraggio permette un affinamento continuo delle strategie di ottimizzazione sulla base delle performance effettive e non solo delle aspettative teoriche.
Il settore si sta evolvendo verso approcci ibridi e adattivi sempre più sofisticati che selezionano dinamicamente tra strategie di ottimizzazione in base alle caratteristiche della query e ai requisiti di conoscenza. Le nuove best practice includono l’implementazione di retrieval-augmented fine-tuning, in cui i modelli vengono ottimizzati su come utilizzare efficacemente le informazioni recuperate anziché memorizzare fatti, e sistemi di routing adattivo che indirizzano le query a modelli fine-tuned per conoscenze stabili o a sistemi RAG per informazioni dinamiche. I trend indicano una crescente adozione di modelli di embedding e database vettoriali specializzati per domini specifici, che consentono ricerche semantiche più precise e riducono il rumore nel recupero. Le organizzazioni stanno sviluppando pattern per il miglioramento continuo dei modelli che combinano aggiornamenti periodici di fine-tuning con l’augmentazione RAG in tempo reale, creando sistemi che migliorano nel tempo mantenendo l’accesso a informazioni aggiornate. L’evoluzione delle strategie di ottimizzazione riflette il riconoscimento, a livello di settore, che nessun singolo approccio soddisfa in modo ottimale tutti i casi d’uso; i sistemi futuri probabilmente implementeranno meccanismi intelligenti di selezione che sceglieranno dinamicamente tra fine-tuning, RAG e approcci ibridi in base al contesto della query, alla stabilità della conoscenza, ai requisiti di latenza e ai vincoli di compliance. Con la maturazione di queste tecnologie, il vantaggio competitivo passerà dalla scelta di un singolo approccio all’implementazione esperta di sistemi adattivi che sfruttano i punti di forza di ogni strategia.
L’ottimizzazione dei dati di addestramento incorpora la conoscenza direttamente nei parametri del modello tramite il fine-tuning, creando conoscenza statica che rimane fissa dopo l’addestramento. Il recupero in tempo reale mantiene la conoscenza esterna e recupera dinamicamente le informazioni rilevanti durante l’inferenza, permettendo l’accesso a informazioni dinamiche che possono variare tra una richiesta e l’altra. La distinzione principale riguarda il momento in cui la conoscenza viene integrata: l’ottimizzazione dei dati di addestramento avviene prima della messa in produzione, mentre il recupero in tempo reale avviene ad ogni chiamata di inferenza.
Utilizza il fine-tuning quando la conoscenza è stabile e non soggetta a frequenti cambiamenti, quando la latenza di inferenza è critica, quando i modelli devono funzionare offline o quando sono essenziali uno stile coerente e una formattazione specifica per il dominio. Il fine-tuning è ideale per compiti specializzati come la diagnosi medica, l’analisi di documenti legali o l’assistenza clienti con informazioni su prodotti stabili. Tuttavia, il fine-tuning richiede notevoli risorse computazionali iniziali e diventa poco pratico quando le informazioni cambiano frequentemente.
Sì, gli approcci ibridi combinano fine-tuning e RAG per ottenere i benefici di entrambe le strategie. Le organizzazioni possono ottimizzare i modelli sui fondamenti del dominio tramite fine-tuning e utilizzare RAG per accedere a informazioni attuali e dettagliate. Questo approccio è particolarmente efficace per applicazioni che richiedono sia competenze specialistiche che informazioni aggiornate, come chatbot per la consulenza finanziaria o sistemi sanitari che necessitano sia di conoscenze mediche sia di dati specifici del paziente.
RAG riduce in modo sostanziale le allucinazioni ancorando le risposte a documenti recuperati—il modello non può dichiarare informazioni che non compaiono nel materiale di partenza, creando vincoli naturali alla fabbricazione. I modelli ottimizzati tramite fine-tuning, al contrario, possono generare con sicurezza informazioni plausibili ma errate quando affrontano domande fuori dalla loro distribuzione di addestramento. L’attribuzione delle fonti in RAG consente inoltre la verifica delle affermazioni, mentre i modelli fine-tuned non possono indicare fonti specifiche per le loro conoscenze.
Il fine-tuning richiede costi iniziali rilevanti: ore GPU (10.000$-100.000$+ per modello), annotazione dati (0,50$-5$ per esempio) e tempo di ingegnerizzazione. Una volta addestrati, i costi di servizio restano relativamente bassi. I sistemi RAG hanno costi iniziali inferiori ma spese infrastrutturali continue per database vettoriali, modelli di embedding e servizi di recupero. I modelli fine-tuned scalano linearmente con il volume di inferenza, mentre i sistemi RAG scalano sia con il volume di inferenza sia con la dimensione della base di conoscenza.
I sistemi RAG generano naturalmente citazioni e riferimenti alle fonti, creando una traccia di controllo dei documenti che hanno influenzato ciascuna risposta. Questo è fondamentale per la sicurezza del brand e l’intelligence competitiva—le organizzazioni possono tracciare come i sistemi di IA citano i concorrenti e fanno riferimento ai loro prodotti. Strumenti come AmICited.com monitorano come i sistemi di IA citano i brand attraverso diverse strategie di ottimizzazione, offrendo un monitoraggio in tempo reale dei pattern e della frequenza delle citazioni.
RAG è generalmente preferito per settori ad alta regolamentazione come sanità e finanza. La conoscenza resta in fonti di dati esterne e verificabili invece che nei parametri del modello, permettendo controlli di sicurezza e restrizioni di accesso semplici. Le organizzazioni possono applicare permessi granulari, auditare quali documenti il modello ha consultato e rimuovere rapidamente informazioni sensibili senza riaddestrare il modello. Le realtà sanitarie soggette a HIPAA e le aziende soggette al GDPR preferiscono spesso la trasparenza e l’auditabilità di RAG.
Implementa sistemi di monitoraggio IA che tracciano output del modello, qualità del recupero e metriche di soddisfazione degli utenti. Nei sistemi RAG monitora accuratezza del recupero e qualità delle citazioni. Nei modelli fine-tuned traccia l’accuratezza su task specifici del dominio e il tasso di allucinazioni. Usa strumenti come AmICited.com per monitorare come i tuoi sistemi IA citano le informazioni e confronta le prestazioni tra diverse strategie di ottimizzazione basandoti su risultati reali.
Traccia le citazioni in tempo reale su GPT, Perplexity e Google AI Overviews. Comprendi quali strategie di ottimizzazione stanno usando i tuoi concorrenti e come vengono referenziati nelle risposte dell'IA.
Scopri l'adattamento AI in tempo reale: la tecnologia che consente ai sistemi AI di apprendere continuamente dagli eventi e dai dati attuali. Esplora come funzi...

Scopri come funziona la ricerca in tempo reale nell'IA, i suoi vantaggi per utenti e aziende e in che modo si differenzia dai motori di ricerca tradizionali e d...
Scopri come ottimizzare i tuoi contenuti per l'inclusione nei dati di addestramento IA. Scopri le best practice per rendere il tuo sito web individuabile da Cha...