Le citazioni di Wikipedia come dati di addestramento per l'IA: l'effetto a catena
Scopri come le citazioni di Wikipedia plasmano i dati di addestramento dell’IA e creano un effetto a catena su tutti gli LLM. Scopri perché la tua presenza su Wikipedia è importante per le menzioni AI e la percezione del brand.
Pubblicato il Jan 3, 2026.Ultima modifica il Jan 3, 2026 alle 3:24 am
Le fondamenta: il ruolo di Wikipedia nell’addestramento degli LLM
Wikipedia è diventata il dataset di addestramento fondamentale per praticamente ogni grande modello linguistico esistente oggi—da ChatGPT di OpenAI e Gemini di Google a Claude di Anthropic e al motore di ricerca di Perplexity. In molti casi, Wikipedia rappresenta la più grande fonte singola di testo strutturato e di alta qualità all’interno dei dataset di addestramento di questi sistemi di IA, spesso costituendo il 5-15% del corpus totale a seconda del modello. Questo predominio deriva dalle caratteristiche uniche di Wikipedia: la sua politica di neutralità, il rigoroso fact-checking guidato dalla comunità, la formattazione strutturata e la licenza open ne fanno una risorsa senza paragoni per insegnare ai sistemi di IA come ragionare, citare fonti e comunicare con precisione. Tuttavia, questa relazione ha trasformato radicalmente il ruolo di Wikipedia nell’ecosistema digitale—non è più solo una destinazione per lettori umani in cerca di informazioni, ma piuttosto la spina dorsale invisibile che alimenta le IA conversazionali con cui milioni di persone interagiscono ogni giorno. Comprendere questa connessione rivela un effetto a catena cruciale: la qualità, i pregiudizi e le lacune di Wikipedia modellano direttamente le capacità e i limiti dei sistemi di IA che ora mediano l’accesso e la comprensione delle informazioni da parte di miliardi di persone.
Come gli LLM usano effettivamente i dati di Wikipedia
Quando i grandi modelli linguistici elaborano le informazioni durante l’addestramento, non trattano tutte le fonti allo stesso modo—Wikipedia occupa una posizione privilegiata nella loro gerarchia decisionale. Durante il processo di riconoscimento delle entità, gli LLM identificano fatti e concetti chiave, quindi li confrontano tra più fonti per stabilire punteggi di credibilità. Wikipedia funge da “controllo primario di autorità” in questo processo grazie alla sua storia di modifiche trasparente, ai meccanismi di verifica comunitari e alla politica di neutralità, che insieme segnalano affidabilità ai sistemi di IA. L’effetto moltiplicatore della credibilità amplifica questo vantaggio: quando un’informazione appare costantemente su Wikipedia, nei knowledge graph strutturati come Google Knowledge Graph e Wikidata, e nelle fonti accademiche, gli LLM assegnano una fiducia esponenzialmente maggiore a quell’informazione. Questo sistema di ponderazione spiega perché Wikipedia riceve un trattamento speciale nell’addestramento—serve sia come fonte diretta di conoscenza sia come livello di validazione per i fatti estratti da altre fonti. Il risultato è che gli LLM hanno imparato a trattare Wikipedia non semplicemente come un dato tra molti, ma come un riferimento fondamentale che conferma o mette in discussione informazioni provenienti da fonti meno verificate.
Ponderazione della credibilità delle fonti nell’addestramento LLM
Tipo di fonte
Peso di credibilità
Motivo
Trattamento AI
Wikipedia
Molto alto
Neutrale, modificata dalla comunità, verificata
Riferimento primario
Sito aziendale
Medio
Autopromozionale
Fonte secondaria
Articoli di notizie
Alto
Terze parti, ma potenzialmente di parte
Fonte di conferma
Knowledge graph
Molto alto
Strutturati, aggregati
Moltiplicatore di autorità
Social media
Basso
Non verificato, promozionale
Peso minimo
Fonti accademiche
Molto alto
Revisionate da pari, autorevoli
Alta fiducia
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
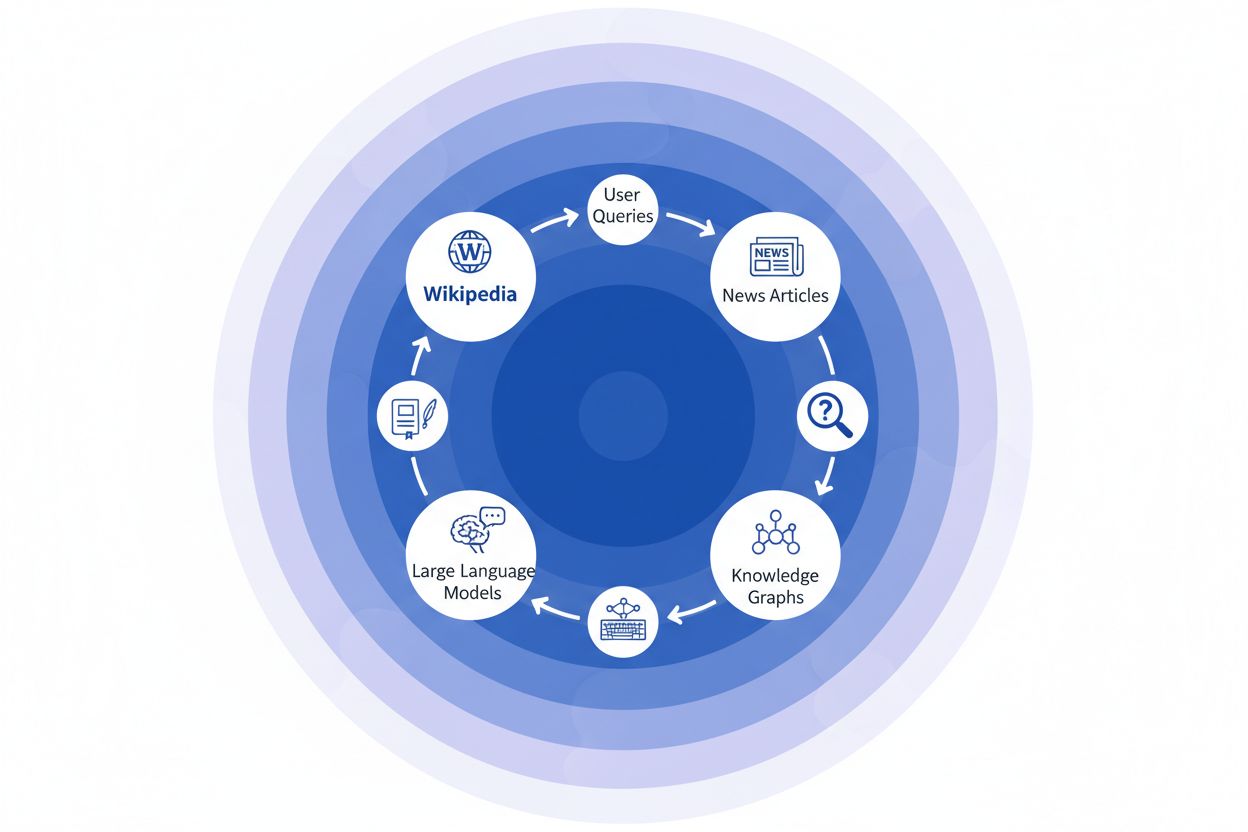
La catena delle citazioni: come Wikipedia influenza le risposte dell’IA
Quando un’organizzazione giornalistica cita Wikipedia come fonte, crea quella che chiamiamo la “catena delle citazioni”—un meccanismo a cascata in cui la credibilità si compone su più livelli dell’infrastruttura informativa. Un giornalista che scrive di scienza climatica potrebbe citare un articolo di Wikipedia sul riscaldamento globale, che a sua volta cita studi peer-reviewed; quell’articolo giornalistico viene poi indicizzato dai motori di ricerca e incorporato nei knowledge graph, che successivamente addestrano grandi modelli linguistici interrogati ogni giorno da milioni di utenti. Si crea così un potente ciclo di feedback: Wikipedia → Knowledge Graph → LLM → Utente, dove l’impostazione e l’enfasi originali della voce Wikipedia possono modellare in modo sottile come i sistemi di IA presentano le informazioni agli utenti finali, spesso senza che questi si rendano conto che l’informazione risale a un’enciclopedia collaborativa. Un esempio concreto: se la voce di Wikipedia su un trattamento farmacologico enfatizza alcuni trial clinici e ne minimizza altri, questa scelta editoriale si propaga nella copertura mediatica, viene incorporata nei knowledge graph e finisce per influenzare come ChatGPT o modelli simili rispondono alle domande dei pazienti sulle opzioni terapeutiche. Questo “effetto a catena” significa che le decisioni editoriali di Wikipedia non influenzano solo i lettori che visitano direttamente il sito—plasmano fondamentalmente il panorama informativo da cui i sistemi di IA apprendono e che riflettono a miliardi di utenti. La catena delle citazioni trasforma essenzialmente Wikipedia da una destinazione di riferimento a uno strato invisibile ma influente della pipeline di addestramento AI, dove accuratezza e bias alla fonte possono amplificarsi su tutto l’ecosistema.
L’effetto a catena: conseguenze a valle
L’effetto a catena nell’ecosistema Wikipedia-IA è forse la dinamica più importante da comprendere per brand e organizzazioni. Una singola modifica su Wikipedia non cambia solo una fonte—si propaga attraverso una rete interconnessa di sistemi di IA, ciascuno dei quali attinge e amplifica l’informazione in modi che ne moltiplicano esponenzialmente l’impatto. Quando appare un’informazione errata su una pagina Wikipedia, non rimane isolata; si diffonde invece su tutto il panorama IA, modellando come il tuo brand viene descritto, compreso e presentato a milioni di utenti ogni giorno. Questo effetto moltiplicatore significa che investire sull’accuratezza di Wikipedia non riguarda solo una piattaforma—si tratta di controllare la tua narrazione su tutto l’ecosistema dell’IA generativa. Per i professionisti della digital PR e del brand management, questa realtà cambia radicalmente il modo di allocare risorse e attenzione.
Principali effetti a catena da monitorare:
La qualità della pagina Wikipedia influisce direttamente su come i sistemi di IA descrivono il tuo brand — Un contenuto Wikipedia scadente diventa la base su cui ChatGPT, Gemini, Claude e altri sistemi AI caratterizzano la tua organizzazione
Una singola citazione Wikipedia influenza i knowledge graph, che influenzano le AI Overviews — Le citazioni fluiscono nell’infrastruttura informativa di Google e impattano direttamente la presentazione nelle sintesi AI generate
Informazioni inaccurate su Wikipedia si propagano su tutto l’ecosistema IA — Una volta inserita nei dati di addestramento, la disinformazione diventa esponenzialmente più difficile da correggere su più piattaforme
Una presenza positiva su Wikipedia si amplifica su tutte le principali piattaforme AI — Una pagina Wikipedia ben curata crea una comunicazione coerente e autorevole su ChatGPT, Gemini, Claude, Perplexity e i sistemi AI emergenti
Le modifiche su Wikipedia hanno effetti ritardati ma cumulativi sull’addestramento AI — I cambiamenti fatti oggi influenzano gli output dei modelli di IA per mesi o anni mentre le informazioni vengono riaddestrate
L’effetto a catena arriva fino a Google AI Overviews, featured snippet e knowledge panel — Wikipedia funge da fonte autorevole che alimenta i risultati AI generati da Google e le visualizzazioni strutturate dei dati
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
La sfida della sostenibilità di Wikipedia: una minaccia per l’ecosistema
Ricerche recenti dello studio IUP di Vetter et al. hanno messo in luce una vulnerabilità critica nella nostra infrastruttura AI: la sostenibilità di Wikipedia come risorsa di addestramento è sempre più minacciata dalla stessa tecnologia che contribuisce ad alimentare. Con la proliferazione dei grandi modelli linguistici e l’addestramento su dataset sempre più ampi contenenti contenuti generati da LLM, il settore si trova di fronte a un crescente problema di “model collapse”, in cui output artificiali iniziano a contaminare i dati di addestramento, degradando la qualità dei modelli nelle generazioni successive. Questo fenomeno è particolarmente acuto considerando che Wikipedia—un’enciclopedia collaborativa fondata sulla competenza umana e sul lavoro volontario—è diventata un pilastro fondamentale per l’addestramento dei sistemi AI avanzati, spesso senza un riconoscimento esplicito o una compensazione per i suoi contributori. Le implicazioni etiche sono profonde: mentre le aziende AI estraggono valore dalla conoscenza liberamente condivisa di Wikipedia e al contempo inondano l’ecosistema informativo di contenuti sintetici, le strutture di incentivo che hanno sostenuto la comunità di volontari di Wikipedia per oltre due decenni subiscono una pressione senza precedenti. Senza un intervento deliberato per preservare il contenuto umano come risorsa distinta e protetta, rischiamo di creare un ciclo di feedback in cui il testo generato dalle IA sostituisce progressivamente la conoscenza autentica, minando alla fine le fondamenta stesse su cui dipendono i moderni modelli linguistici. La sostenibilità di Wikipedia non è quindi solo un tema per l’enciclopedia stessa, ma una questione critica per l’intero ecosistema informativo e il futuro delle IA che dipendono dalla conoscenza umana autentica.
Monitorare la tua presenza su Wikipedia: il ruolo di AmICited
Poiché i sistemi di intelligenza artificiale si affidano sempre più a Wikipedia come fonte di conoscenza fondamentale, monitorare come appare il tuo brand nelle risposte AI è diventato essenziale per le organizzazioni moderne. AmICited.com è specializzata nel tracciare le citazioni di Wikipedia mentre si propagano nei sistemi di IA, offrendo ai brand visibilità su come la loro presenza su Wikipedia si traduce in menzioni e raccomandazioni AI. Mentre strumenti alternativi come FlowHunt.io offrono capacità di monitoraggio web generico, AmICited si concentra in modo unico sulla pipeline di citazione Wikipedia-AI, catturando il momento preciso in cui i sistemi di IA fanno riferimento alla tua voce Wikipedia e come ciò influenza le loro risposte. Comprendere questa connessione è fondamentale perché le citazioni Wikipedia hanno un peso significativo nei dati di addestramento AI e nella generazione delle risposte—una presenza Wikipedia ben mantenuta non informa solo i lettori umani, ma modella come i sistemi AI percepiscono e presentano il tuo brand a milioni di utenti. Monitorando le tue menzioni Wikipedia tramite AmICited, ottieni insight azionabili sulla tua impronta AI, potendo così ottimizzare la tua presenza su Wikipedia con piena consapevolezza del suo impatto a valle sulla scoperta AI e sulla percezione del brand.
Domande frequenti
Wikipedia viene davvero usata per addestrare ogni LLM?
Sì, ogni grande LLM incluso ChatGPT, Gemini, Claude e Perplexity include Wikipedia nei suoi dati di addestramento. Wikipedia è spesso la singola fonte più grande di informazioni strutturate e verificate nei dataset di addestramento LLM, tipicamente rappresentando il 5-15% del corpus totale a seconda del modello.
Come influisce Wikipedia su ciò che i sistemi di IA dicono sul mio brand?
Wikipedia funge da punto di controllo di credibilità per i sistemi di IA. Quando un LLM genera informazioni sul tuo brand, dà maggiore peso alla descrizione fornita da Wikipedia rispetto ad altre fonti, rendendo la tua pagina Wikipedia un'influenza cruciale su come i sistemi di IA ti rappresentano su ChatGPT, Gemini, Claude e altre piattaforme.
Cosa significa 'effetto a catena' nel contesto di Wikipedia e IA?
L'effetto a catena si riferisce a come una singola citazione o modifica su Wikipedia crea conseguenze a cascata su tutto l'ecosistema IA. Un cambiamento su Wikipedia può influenzare i knowledge graph, che a loro volta influenzano le panoramiche AI, e quindi il modo in cui molteplici sistemi di IA descrivono il tuo brand a milioni di utenti.
Informazioni inaccurate su Wikipedia possono danneggiare il mio brand nei sistemi di IA?
Sì. Poiché gli LLM considerano Wikipedia altamente credibile, informazioni errate sulla tua pagina Wikipedia si propagheranno nei sistemi di IA. Questo può influenzare come ChatGPT, Gemini e altre piattaforme AI descrivono la tua organizzazione, potenzialmente danneggiando la percezione del tuo brand.
Come posso monitorare l'influenza di Wikipedia sul mio brand nei sistemi di IA?
Strumenti come AmICited.com tengono traccia di come il tuo brand viene citato e menzionato nei sistemi di IA inclusi ChatGPT, Perplexity e Google AI Overviews. Questo ti aiuta a capire l'effetto a catena della tua presenza su Wikipedia e a ottimizzare di conseguenza.
Dovrei creare o modificare io stesso la mia pagina Wikipedia?
Wikipedia ha regole rigorose contro l'autopromozione. Qualsiasi modifica deve seguire le linee guida di Wikipedia e basarsi su fonti affidabili e di terze parti. Molte organizzazioni si affidano a specialisti di Wikipedia per garantire la conformità mantenendo una presenza accurata.
Quanto tempo occorre perché i cambiamenti su Wikipedia influenzino i sistemi di IA?
Gli LLM sono addestrati su snapshot di dati, quindi i cambiamenti richiedono tempo per propagarsi. Tuttavia, i knowledge graph si aggiornano più frequentemente, quindi l'effetto a catena può iniziare in settimane o mesi a seconda del sistema di IA e della tempistica del suo riaddestramento.
Qual è la differenza tra Wikipedia e knowledge graph nell'addestramento AI?
Wikipedia è una fonte primaria usata direttamente nell'addestramento LLM. I knowledge graph come il Knowledge Graph di Google aggregano informazioni da più fonti inclusa Wikipedia e le trasferiscono nei sistemi di IA, creando un ulteriore livello di influenza su come questi sistemi comprendono e presentano le informazioni.
Monitora la tua presenza su Wikipedia nei sistemi di IA
Tieni traccia di come le citazioni di Wikipedia si propagano su ChatGPT, Gemini, Claude e altri sistemi di IA. Comprendi la tua impronta AI e ottimizza la tua presenza su Wikipedia con AmICited.
Ottenere Citazioni negli Articoli di Wikipedia: Un Approccio Non Manipolativo
Scopri strategie etiche per far citare il tuo brand su Wikipedia. Comprendi le policy sui contenuti di Wikipedia, le fonti affidabili e come sfruttare le citazi...
Il ruolo di Wikipedia nei dati di addestramento dell'IA: qualità, impatto e licenze
Scopri come Wikipedia funge da dataset critico per l'addestramento dell'IA, il suo impatto sull'accuratezza dei modelli, gli accordi di licenza e perché le azie...
Il Ruolo di Wikipedia nelle Citazioni dell'IA: Come Influenza le Risposte Generate dall'IA
Scopri come Wikipedia influenza le citazioni dell'IA su ChatGPT, Perplexity e Google AI. Scopri perché Wikipedia è la fonte più affidabile per l'addestramento d...
14 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.