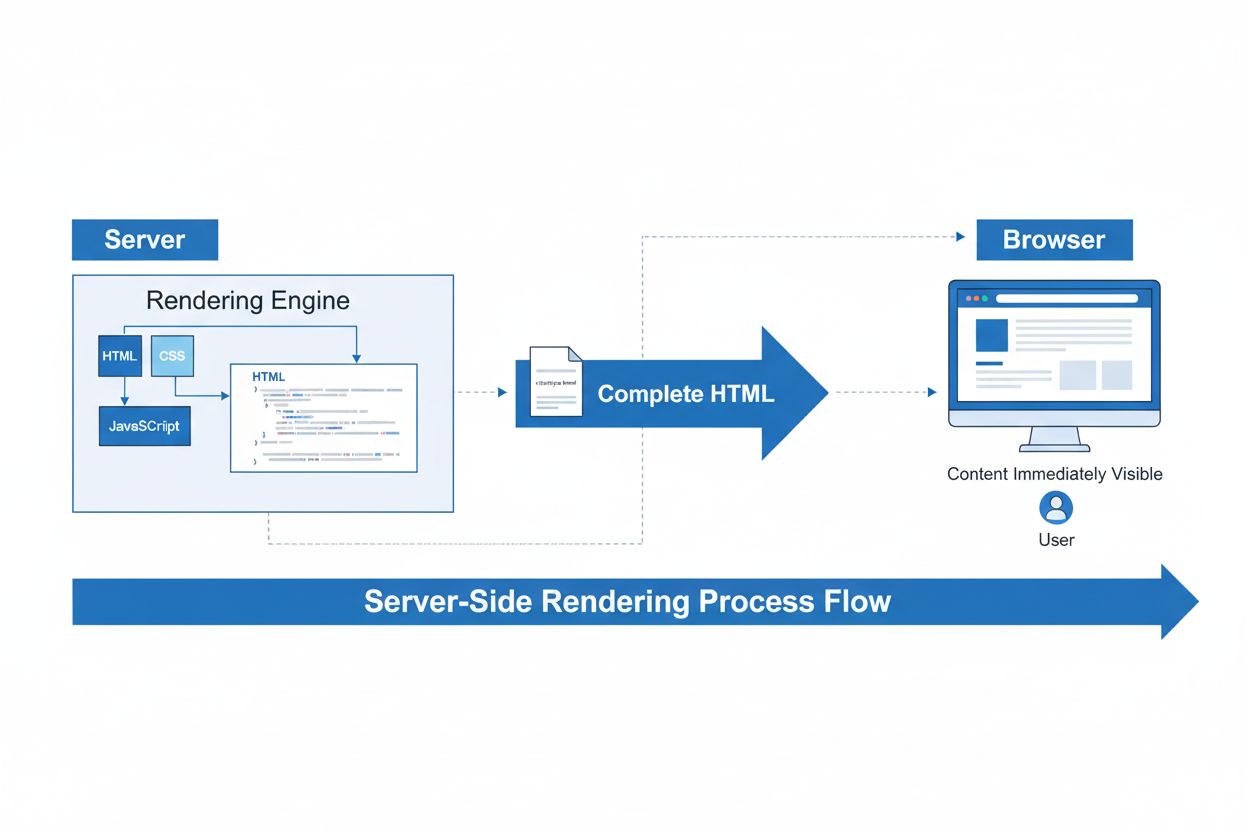
Server-Side Rendering (SSR)
Il Server-Side Rendering (SSR) è una tecnica web in cui i server renderizzano pagine HTML complete prima di inviarle ai browser. Scopri come il SSR migliora la ...
13 min di lettura

Scopri come il server-side rendering consente un’elaborazione efficiente dell’IA, il deployment dei modelli e inferenze in tempo reale per applicazioni potenziate dall’IA e carichi di lavoro LLM.
Il server-side rendering per l'IA è un approccio architetturale in cui modelli di intelligenza artificiale ed elaborazione delle inferenze avvengono sul server anziché sui dispositivi client. Questo consente una gestione efficiente di compiti IA computazionalmente intensivi, garantisce prestazioni costanti per tutti gli utenti e semplifica il deployment e l'aggiornamento dei modelli.
Il server-side rendering per l’IA si riferisce a un modello architetturale in cui modelli di intelligenza artificiale, processi di inferenza e compiti computazionali vengono eseguiti su server backend invece che su dispositivi client come browser o smartphone. Questo approccio si differenzia fondamentalmente dal rendering tradizionale lato client, dove JavaScript viene eseguito nel browser dell’utente per generare contenuti. Nelle applicazioni IA, il server-side rendering significa che grandi modelli linguistici (LLM), inferenze di machine learning e generazione di contenuti tramite IA avvengono centralmente su infrastruttura server potente prima che i risultati vengano inviati agli utenti. Questo cambiamento architetturale è diventato sempre più importante man mano che le capacità dell’IA sono diventate più esigenti dal punto di vista computazionale e fondamentali per le moderne applicazioni web.
Il concetto nasce dal riconoscimento di una discrepanza critica tra ciò che le moderne applicazioni IA richiedono e ciò che i dispositivi client possono realisticamente fornire. I framework di sviluppo web tradizionali come React, Angular e Vue.js hanno reso popolare il rendering lato client negli anni 2010, ma questo approccio crea notevoli sfide quando applicato a carichi di lavoro intensivi in IA. Il server-side rendering per l’IA affronta queste sfide sfruttando hardware specializzato, gestione centralizzata dei modelli e infrastruttura ottimizzata che i dispositivi client semplicemente non possono eguagliare. Questo rappresenta un cambiamento di paradigma fondamentale nel modo in cui gli sviluppatori progettano applicazioni potenziate dall’IA.
I requisiti computazionali dei moderni sistemi di IA rendono il server-side rendering non solo vantaggioso, ma spesso necessario. I dispositivi client, in particolare smartphone e laptop economici, non hanno la potenza di calcolo per gestire in modo efficiente l’inferenza IA in tempo reale. Quando i modelli di IA vengono eseguiti sui dispositivi client, gli utenti sperimentano ritardi evidenti, maggiore consumo della batteria e prestazioni incoerenti in base alle capacità hardware. Il server-side rendering elimina questi problemi centralizzando l’elaborazione IA su infrastrutture dotate di GPU, TPU e acceleratori IA specializzati che offrono prestazioni di gran lunga superiori rispetto ai dispositivi consumer.
Oltre alle prestazioni, il server-side rendering per l’IA offre vantaggi cruciali nella gestione dei modelli, sicurezza e coerenza. Quando i modelli IA vengono eseguiti su server, gli sviluppatori possono aggiornare, ottimizzare e distribuire nuove versioni istantaneamente senza richiedere agli utenti di scaricare aggiornamenti o gestire versioni diverse localmente. Questo è particolarmente importante per grandi modelli linguistici e sistemi di machine learning che evolvono rapidamente con frequenti miglioramenti e patch di sicurezza. Inoltre, mantenere i modelli IA sui server previene accessi non autorizzati, estrazione dei modelli e furto di proprietà intellettuale che diventano possibili quando i modelli sono distribuiti ai dispositivi client.
| Aspetto | IA Lato Client | IA Lato Server |
|---|---|---|
| Luogo di Elaborazione | Browser o dispositivo dell’utente | Server backend |
| Requisiti Hardware | Limitati alle capacità del dispositivo | GPU, TPU, acceleratori IA specializzati |
| Prestazioni | Variabili, dipendenti dal dispositivo | Costanti, ottimizzate |
| Aggiornamenti Modello | Richiedono download utente | Deployment istantaneo |
| Sicurezza | Modelli esposti all’estrazione | Modelli protetti sui server |
| Latenza | Dipende dalla potenza del dispositivo | Infrastruttura ottimizzata |
| Scalabilità | Limitata per dispositivo | Altamente scalabile tra utenti |
| Complessità di Sviluppo | Elevata (frammentazione dispositivi) | Inferiore (gestione centralizzata) |
Overhead di Rete e Latenza rappresentano sfide significative nelle applicazioni IA. I moderni sistemi IA richiedono comunicazione costante con i server per aggiornamenti dei modelli, recupero dati di addestramento e scenari di elaborazione ibrida. Ironia della sorte, il rendering lato client aumenta le richieste di rete rispetto alle applicazioni tradizionali, riducendo i benefici prestazionali che l’elaborazione lato client dovrebbe fornire. Il server-side rendering consolida queste comunicazioni, riducendo i ritardi e consentendo a funzionalità IA in tempo reale come traduzioni live, generazione di contenuti ed elaborazione di computer vision di funzionare senza i ritardi dell’inferenza lato client.
Complessità di Sincronizzazione emerge quando le applicazioni IA devono mantenere la coerenza dello stato tra più servizi IA simultaneamente. Le applicazioni moderne spesso utilizzano servizi di embedding, modelli di completamento, modelli ottimizzati e motori di inferenza specializzati che devono coordinarsi tra loro. Gestire questo stato distribuito sui dispositivi client introduce notevole complessità e possibilità di inconsistenze, soprattutto nelle funzionalità IA collaborative in tempo reale. Il server-side rendering centralizza la gestione dello stato, assicurando che tutti gli utenti vedano risultati coerenti ed eliminando la complessità ingegneristica della sincronizzazione lato client.
Frammentazione dei Dispositivi crea notevoli sfide di sviluppo per l’IA lato client. Dispositivi diversi hanno capacità IA differenti, inclusi Neural Processing Unit, accelerazione GPU, supporto WebGL e limiti di memoria. Creare esperienze IA coerenti in questo panorama frammentato richiede notevoli sforzi ingegneristici, strategie di degradazione graduale e percorsi multipli di codice per diverse capacità dispositive. Il server-side rendering elimina completamente questa frammentazione assicurando che tutti gli utenti accedano alla stessa infrastruttura IA ottimizzata, indipendentemente dalle specifiche del dispositivo.
Il server-side rendering permette architetture di applicazioni IA più semplici e facili da mantenere centralizzando le funzionalità critiche. Invece di distribuire modelli IA e logiche di inferenza su migliaia di dispositivi client, gli sviluppatori mantengono una singola implementazione ottimizzata sui server. Questa centralizzazione offre benefici immediati tra cui cicli di deployment più rapidi, debugging semplificato e ottimizzazione delle prestazioni più diretta. Quando un modello IA necessita di miglioramenti o viene scoperto un bug, gli sviluppatori lo risolvono una sola volta sul server invece di tentare di inviare aggiornamenti a milioni di dispositivi client con tassi di adozione variabili.
L’efficienza delle risorse migliora notevolmente con il server-side rendering. L’infrastruttura server consente condivisione efficiente delle risorse tra tutti gli utenti, con pooling delle connessioni, strategie di caching e bilanciamento del carico che ottimizzano l’uso dell’hardware. Una singola GPU su un server può gestire richieste di inferenza da migliaia di utenti in sequenza, mentre distribuire la stessa capacità ai dispositivi client richiederebbe milioni di GPU. Questa efficienza si traduce in costi operativi inferiori, minore impatto ambientale e migliore scalabilità man mano che le applicazioni crescono.
Sicurezza e protezione della proprietà intellettuale diventano molto più semplici con il server-side rendering. I modelli IA rappresentano un grande investimento in ricerca, dati di addestramento e risorse computazionali. Mantenere i modelli sui server previene attacchi di estrazione dei modelli, accessi non autorizzati e furto di proprietà intellettuale che diventano possibili quando i modelli sono distribuiti ai dispositivi client. Inoltre, l’elaborazione lato server consente controlli di accesso granulari, audit logging e monitoraggio della conformità che sarebbe impossibile applicare su dispositivi client distribuiti.
I framework moderni si sono evoluti per supportare efficacemente il server-side rendering per carichi di lavoro IA. Next.js guida questa evoluzione con le Server Actions che abilitano l’elaborazione IA direttamente dai componenti server. Gli sviluppatori possono chiamare API IA, elaborare grandi modelli linguistici e inviare risposte in streaming ai client con pochissimo codice boilerplate. Il framework gestisce la complessità della comunicazione server-client, permettendo agli sviluppatori di concentrarsi sulla logica IA piuttosto che sulle problematiche infrastrutturali.
SvelteKit offre un approccio focalizzato sulle prestazioni al rendering IA lato server attraverso le sue load functions che vengono eseguite sul server prima del rendering. Questo consente pre-elaborazione dei dati IA, generazione di raccomandazioni e preparazione di contenuti arricchiti dall’IA prima di inviare l’HTML ai client. Le applicazioni risultanti hanno una minima presenza JavaScript mantenendo tutte le capacità IA, creando esperienze utente eccezionalmente rapide.
Strumenti specializzati come il Vercel AI SDK astraggono la complessità dello streaming delle risposte IA, gestione dei token e interfacciamento con vari provider IA. Questi strumenti permettono agli sviluppatori di costruire applicazioni IA sofisticate senza competenze infrastrutturali approfondite. Opzioni infrastrutturali come Vercel Edge Functions, Cloudflare Workers e AWS Lambda offrono elaborazione IA lato server distribuita globalmente, riducendo la latenza elaborando le richieste vicino agli utenti mantenendo la gestione centralizzata dei modelli.
Un efficace rendering IA lato server richiede strategie di caching sofisticate per gestire costi computazionali e latenza. Il caching Redis memorizza risposte IA frequentemente richieste e sessioni utente, eliminando elaborazioni ridondanti per query simili. Il caching CDN distribuisce globalmente contenuti IA statici generati, assicurando che gli utenti ricevano risposte da server geograficamente vicini. Strategie di edge caching distribuiscono contenuti IA processati attraverso reti edge, offrendo risposte a latenza ultra-bassa mantenendo la gestione centralizzata dei modelli.
Questi approcci di caching lavorano insieme per creare sistemi IA efficienti che scalano a milioni di utenti senza aumenti proporzionali dei costi computazionali. Caching delle risposte IA a più livelli consente alle applicazioni di servire la maggior parte delle richieste dalla cache, elaborando solo nuove risposte per query effettivamente inedite. Questo riduce drasticamente i costi infrastrutturali e migliora l’esperienza utente grazie a tempi di risposta più rapidi.
L’evoluzione verso il server-side rendering rappresenta una maturazione delle pratiche di sviluppo web in risposta alle esigenze dell’IA. Poiché l’IA diventa centrale nelle applicazioni web, le realtà computazionali impongono architetture centrate sul server. Il futuro prevede sofisticati approcci ibridi che decidono automaticamente dove effettuare il rendering in base al tipo di contenuto, capacità del dispositivo, condizioni di rete e requisiti di elaborazione IA. I framework arricchiranno progressivamente le applicazioni con funzionalità IA, garantendo che le funzionalità core funzionino universalmente e migliorando l’esperienza dove possibile.
Questo cambiamento di paradigma incorpora le lezioni apprese dall’era delle Single Page Application affrontando le sfide delle applicazioni native IA. Gli strumenti e i framework sono pronti per consentire agli sviluppatori di sfruttare i benefici del server-side rendering nell’era dell’IA, abilitando la prossima generazione di applicazioni web intelligenti, reattive ed efficienti.
Monitora come il tuo dominio e brand appaiono nelle risposte generate dall'IA su ChatGPT, Perplexity e altri motori di ricerca IA. Ottieni insight in tempo reale sulla tua visibilità IA.
Il Server-Side Rendering (SSR) è una tecnica web in cui i server renderizzano pagine HTML complete prima di inviarle ai browser. Scopri come il SSR migliora la ...
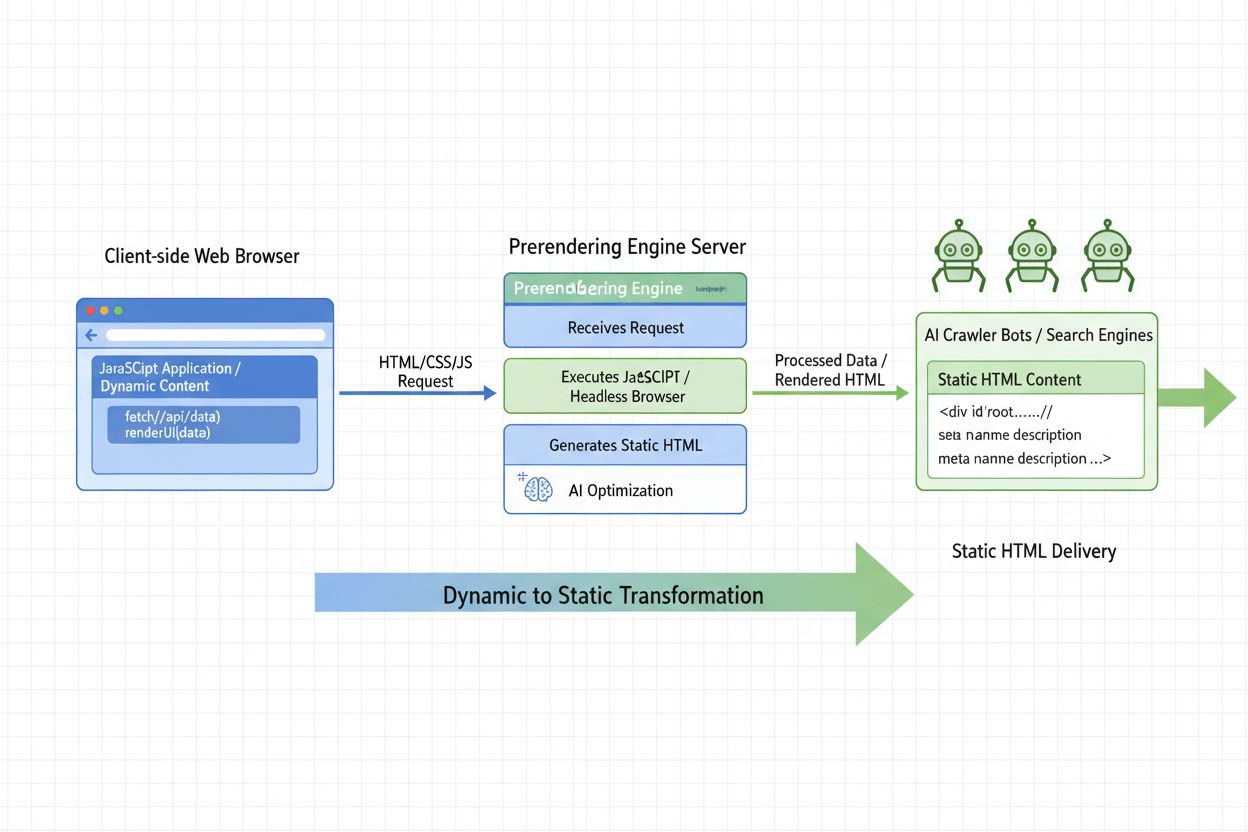
Scopri cos'è il Prerendering AI e come le strategie di rendering lato server ottimizzano il tuo sito per la visibilità ai crawler AI. Scopri strategie di implem...

Scopri come il rendering dinamico influisce sulla visibilità dei crawler IA, ChatGPT, Perplexity e Claude. Scopri perché i sistemi di IA non possono eseguire Ja...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.