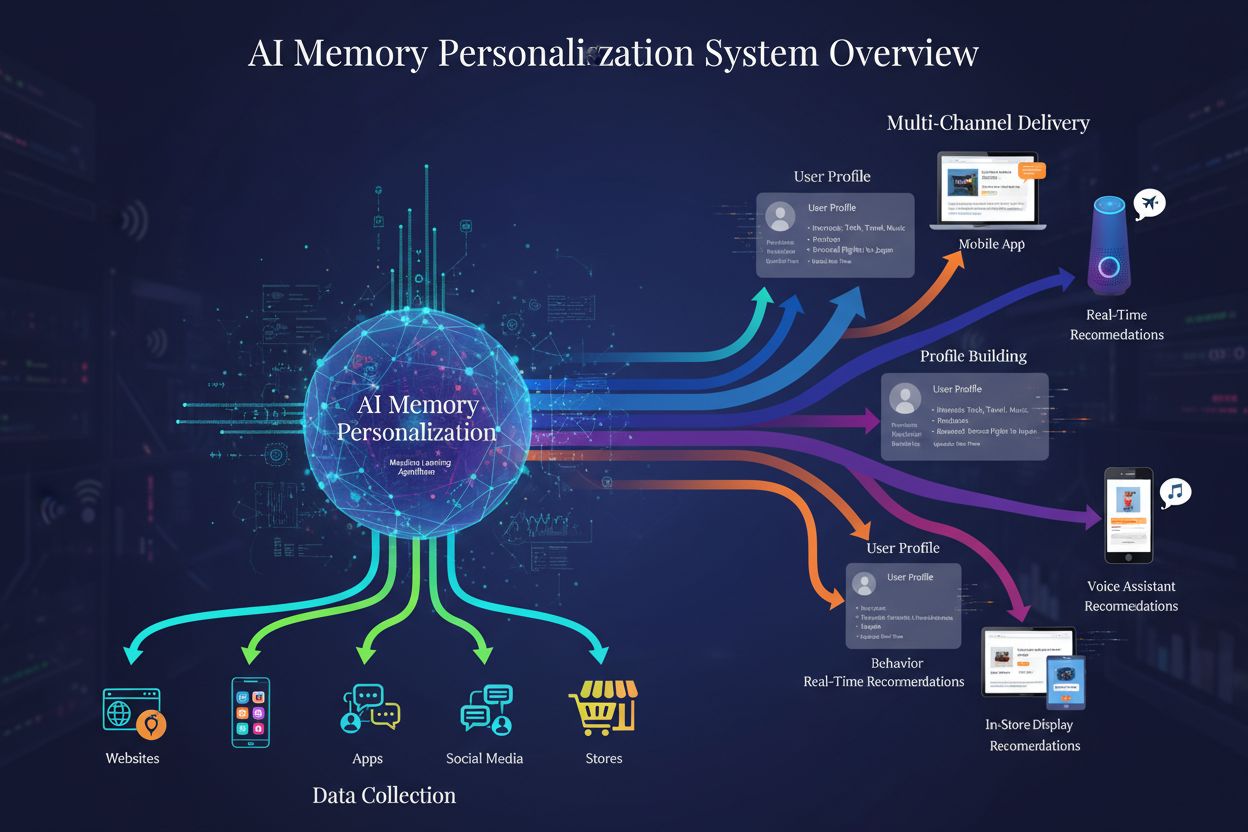
Personalizzazione della Memoria AI
Scopri come i sistemi di personalizzazione della memoria AI costruiscono profili utente dettagliati per offrire raccomandazioni di brand personalizzate. Compren...
16 min di lettura

La personalizzazione dei modelli di IA è il processo di adattamento di modelli di intelligenza artificiale pre-addestrati per svolgere compiti specifici o lavorare con dati specializzati, modificando i loro parametri tramite un ulteriore addestramento su dataset di settore specifici. Questo approccio sfrutta le conoscenze di base già acquisite, consentendo di personalizzare i modelli per applicazioni aziendali particolari e permettendo alle organizzazioni di creare sistemi di IA altamente specializzati senza i costi computazionali dell’addestramento da zero.
La personalizzazione dei modelli di IA è il processo di adattamento di modelli di intelligenza artificiale pre-addestrati per svolgere compiti specifici o lavorare con dati specializzati, modificando i loro parametri tramite un ulteriore addestramento su dataset di settore specifici. Questo approccio sfrutta le conoscenze di base già acquisite, consentendo di personalizzare i modelli per applicazioni aziendali particolari e permettendo alle organizzazioni di creare sistemi di IA altamente specializzati senza i costi computazionali dell’addestramento da zero.
La personalizzazione dei modelli di IA è il processo di prendere un modello di intelligenza artificiale pre-addestrato e adattarlo per svolgere compiti specifici o lavorare con dati specializzati. Invece di addestrare un modello da zero, la personalizzazione sfrutta le conoscenze di base già incorporate nel modello e ne regola i parametri tramite ulteriore addestramento su dataset specifici di settore o compito. Questo approccio combina l’efficienza del transfer learning con la personalizzazione necessaria per le applicazioni aziendali. La personalizzazione permette di creare modelli di IA altamente specializzati senza l’onere computazionale e l’investimento di tempo richiesti dall’addestramento da zero, diventando una tecnica essenziale nello sviluppo moderno di machine learning.
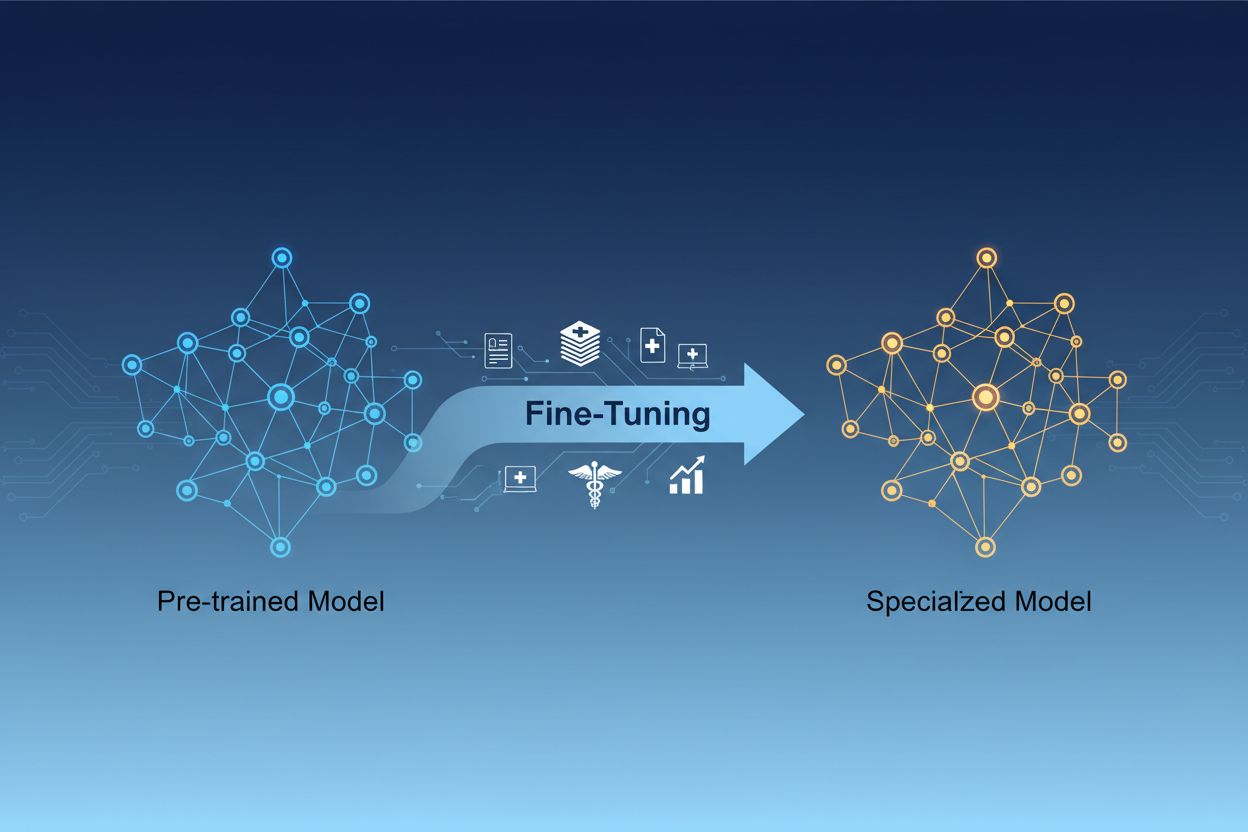
La distinzione tra personalizzazione e addestramento da zero rappresenta una delle decisioni più importanti nello sviluppo di sistemi di machine learning. Addestrando un modello da zero, si parte con pesi inizializzati casualmente e bisogna insegnare al modello tutto sulle strutture linguistiche, sulle caratteristiche visive o sulle conoscenze di dominio usando enormi quantità di dati e notevoli risorse computazionali. Questo approccio può richiedere settimane o mesi e l’uso di hardware specializzato come GPU o TPU. La personalizzazione, invece, parte da un modello che già comprende schemi e concetti fondamentali, richiedendo solo una frazione dei dati e della potenza di calcolo per adattarlo alle tue esigenze. Il modello pre-addestrato ha già appreso le caratteristiche generali nella sua fase iniziale, quindi la personalizzazione si concentra sull’adattare queste competenze al tuo caso d’uso. Questo guadagno di efficienza rende la personalizzazione l’approccio preferito dalla maggior parte delle organizzazioni, poiché riduce tempi di sviluppo e costi infrastrutturali, spesso ottenendo prestazioni migliori rispetto all’addestramento da zero di modelli più piccoli.
| Aspetto | Personalizzazione | Addestramento da Zero |
|---|---|---|
| Tempo di Addestramento | Da giorni a settimane | Da settimane a mesi |
| Requisiti di Dati | Da migliaia a milioni di esempi | Da milioni a miliardi di esempi |
| Costo Computazionale | Moderato (spesso basta una singola GPU) | Estremamente elevato (richieste più GPU/TPU) |
| Conoscenza Iniziale | Sfrutta pesi pre-addestrati | Inizia con pesi casuali |
| Prestazioni | Spesso superiori con pochi dati | Migliori con dataset enormi |
| Competenze Richieste | Intermedie | Avanzate |
| Livello di Personalizzazione | Alto per compiti specifici | Massima flessibilità |
| Infrastruttura | Risorse cloud standard | Cluster hardware specializzati |
La personalizzazione è diventata una capacità essenziale per le organizzazioni che vogliono implementare soluzioni di IA in grado di offrire vantaggi competitivi. Adattando i modelli pre-addestrati al tuo contesto aziendale, puoi creare sistemi di IA che comprendono la terminologia di settore, le preferenze dei clienti e le esigenze operative con grande accuratezza. Questa personalizzazione permette di ottenere prestazioni che i modelli generici non possono offrire, soprattutto in settori specializzati come sanità, servizi legali o assistenza tecnica. Il rapporto costi-benefici della personalizzazione consente anche alle realtà più piccole di accedere a capacità di IA di livello enterprise senza dover investire in grandi infrastrutture. Inoltre, i modelli personalizzati possono essere distribuiti più rapidamente, permettendo di rispondere tempestivamente alle opportunità di mercato e alle pressioni della concorrenza. La possibilità di migliorare continuamente i modelli, personalizzandoli su nuovi dati, assicura che i sistemi di IA restino efficaci nel tempo.
I principali vantaggi di business della personalizzazione sono:
Sono emerse varie tecniche considerate best practice nel panorama della personalizzazione, ognuna con vantaggi distinti a seconda delle necessità. La personalizzazione completa prevede l’aggiornamento di tutti i parametri del modello pre-addestrato, offrendo la massima flessibilità e spesso le migliori prestazioni, ma richiedendo molta potenza di calcolo e dataset più grandi per evitare l’overfitting. I metodi di personalizzazione efficiente come LoRA (Low-Rank Adaptation) e QLoRA hanno rivoluzionato il settore permettendo di adattare efficacemente i modelli aggiornando solo una piccola frazione dei parametri, riducendo drasticamente memoria richiesta e tempi di addestramento. Queste tecniche funzionano aggiungendo matrici a basso rango addestrabili ai pesi del modello, catturando le specificità del compito senza modificare i pesi originari. I moduli adapter rappresentano un altro approccio: piccoli network addestrabili vengono inseriti tra gli strati congelati del modello, consentendo una personalizzazione efficiente con pochi parametri aggiuntivi. La personalizzazione basata su prompt si concentra sull’ottimizzazione degli input piuttosto che sui pesi del modello, utile quando non si può accedere direttamente ai parametri. La personalizzazione tramite istruzioni addestra i modelli a seguire comandi e istruzioni specifiche, fondamentale per i grandi modelli linguistici che devono rispondere a richieste varie. La scelta tra queste tecniche dipende dai vincoli computazionali, dalla quantità di dati, dai requisiti di performance e dall’architettura del modello.
La personalizzazione dei grandi modelli linguistici (LLM) presenta opportunità e sfide uniche rispetto ai modelli più piccoli o ad altre tipologie di reti neurali. I moderni LLM come i modelli GPT contano miliardi di parametri, rendendo la personalizzazione completa proibitiva per la maggior parte delle organizzazioni. Questo ha spinto l’adozione di tecniche efficienti che permettono l’adattamento efficace dei LLM senza necessità di infrastrutture enterprise. La personalizzazione tramite istruzioni è diventata particolarmente importante per i LLM, dove si addestra il modello su esempi di comandi abbinati a risposte di alta qualità, migliorando la capacità di seguire le direttive. Il Reinforcement Learning from Human Feedback (RLHF) rappresenta una tecnica avanzata in cui i modelli vengono ulteriormente raffinati in base a preferenze e valutazioni umane, migliorando l’allineamento con valori e aspettative delle persone. La quantità relativamente ridotta di dati specifici richiesti per personalizzare i LLM—spesso poche centinaia o migliaia di esempi—rende questo approccio accessibile anche senza grandi dataset etichettati. Tuttavia, la personalizzazione dei LLM richiede attenzione nella scelta degli iperparametri, nella schedulazione del learning rate e nella prevenzione del cosiddetto catastrophic forgetting, ovvero la perdita di capacità precedentemente apprese durante l’adattamento a nuovi compiti.

Organizzazioni di tutti i settori hanno scoperto applicazioni potenti per modelli di IA personalizzati che generano valore concreto. L’automazione del servizio clienti è uno degli usi più diffusi: i modelli vengono personalizzati su ticket di supporto, schede prodotto e stili comunicativi aziendali per creare chatbot che rispondono con competenza e coerenza di brand. L’analisi di documenti medici e legali sfrutta la personalizzazione per adattare i modelli generali a terminologie specifiche, requisiti normativi e formati di settore, abilitando estrazione e classificazione accurate delle informazioni. Analisi del sentiment e moderazione dei contenuti possono essere notevolmente migliorate personalizzando i modelli su esempi del proprio settore o comunità, cogliendo sfumature e contesti che i modelli generici ignorano. La generazione di codice e l’assistenza allo sviluppo software beneficiano della personalizzazione su basi di codice aziendali, convenzioni di programmazione e pattern architetturali, permettendo ad assistenti IA di produrre codice conforme agli standard interni. I sistemi di raccomandazione vengono spesso personalizzati su dati comportamentali degli utenti e cataloghi prodotto per offrire suggerimenti personalizzati che incrementano engagement e ricavi. Il riconoscimento di entità e l’estrazione di informazioni da documenti specifici di settore—come report finanziari, articoli scientifici o specifiche tecniche—possono essere migliorati notevolmente tramite la personalizzazione su esempi pertinenti. Queste applicazioni dimostrano che la personalizzazione non è limitata a un solo settore, ma rappresenta una capacità fondamentale per creare sistemi di IA che offrono vantaggi competitivi in quasi ogni ambito aziendale.
Il processo di personalizzazione segue un workflow strutturato che parte dalla preparazione e si estende fino al deployment e al monitoraggio. La preparazione dei dati è il primo passaggio cruciale: occorre raccogliere, pulire e formattare il dataset di settore in modo che corrisponda alla struttura input-output attesa dal modello pre-addestrato. Il dataset deve essere rappresentativo dei compiti reali e la qualità conta più della quantità: un dataset piccolo ma di alta qualità supera uno più grande ma rumoroso o incoerente. La suddivisione train-validation-test (tipicamente 70-80% training, 10-15% validazione, 10-15% test) consente di valutare correttamente le prestazioni. La scelta degli iperparametri (learning rate, batch size, numero di epoche, ecc.) influenza significativamente performance ed efficienza dell’addestramento. L’inizializzazione del modello usa i pesi pre-addestrati come punto di partenza, preservando le conoscenze di base e permettendo l’adattamento ai compiti specifici. L’esecuzione dell’addestramento prevede aggiornamenti iterativi dei parametri monitorando la performance in validazione per rilevare overfitting. Valutazione e iterazione consentono, tramite il test set, di verificare i risultati e decidere se servono ulteriori personalizzazioni, dati o iperparametri diversi. La preparazione al deployment include l’ottimizzazione per l’inferenza (tramite quantizzazione o distillazione). Infine, il monitoraggio e la manutenzione in produzione assicurano che il modello resti efficace nel tempo, con riaddestramenti periodici su nuovi dati per mantenere l’accuratezza.
La personalizzazione, pur essendo più efficiente dell’addestramento da zero, presenta sfide che vanno affrontate con attenzione. L’overfitting si verifica quando i modelli memorizzano i dati invece di apprendere schemi generali, rischio maggiore con dataset piccoli; si può mitigare tramite early stopping, regolarizzazione e data augmentation. Il catastrophic forgetting avviene quando il modello perde capacità acquisite adattandosi a nuovi compiti, problema soprattutto nell’adattamento di modelli generali a compiti specifici; la scelta attenta dei learning rate e tecniche come la knowledge distillation aiutano a preservare le conoscenze di base. La qualità dei dati e l’etichettatura sono sfide pratiche importanti, poiché la personalizzazione richiede esempi di alta qualità rappresentativi del dominio. La gestione delle risorse computazionali impone di bilanciare miglioramenti e costi, particolarmente importante con modelli grandi. La sensibilità agli iperparametri implica che le prestazioni possano variare drasticamente a seconda delle impostazioni, rendendo necessarie sperimentazione e validazione sistematiche.
Best practice per una personalizzazione efficace:
Le organizzazioni spesso si trovano a scegliere tra tre approcci complementari per adattare i modelli di IA a compiti specifici: personalizzazione, Retrieval-Augmented Generation (RAG) e prompt engineering. Il prompt engineering consiste nel progettare istruzioni ed esempi accurati per guidare il comportamento del modello senza modificarne i parametri; è rapido e non richiede addestramento, ma ha efficacia limitata su compiti complessi e non insegna conoscenze veramente nuove. RAG arricchisce le risposte del modello recuperando documenti o dati rilevanti da fonti esterne prima di generare le risposte, permettendo di accedere a informazioni aggiornate e settoriali senza aggiornare i parametri; è efficace in compiti knowledge-intensive ma aggiunge latenza e complessità. La personalizzazione modifica i parametri del modello per inglobare profondamente conoscenze e schemi specifici, offrendo le migliori prestazioni su compiti ben definiti e con dati sufficienti, ma richiedendo più tempo e risorse. La soluzione ottimale spesso combina queste tecniche: prompt engineering per prototipazione rapida, RAG per applicazioni knowledge-intensive, personalizzazione per sistemi ad alte prestazioni dove l’investimento è giustificato. La personalizzazione eccelle quando serve comportamento coerente e prestazionale su compiti specifici, con dati sufficienti e quando il guadagno in performance giustifica lo sforzo. RAG è ideale per applicazioni che richiedono accesso a informazioni attuali o proprietarie in rapido mutamento. Il prompt engineering è ottimo per l’esplorazione e il prototyping prima di impegnarsi in sviluppi più onerosi. Comprendere punti di forza e limiti di ogni approccio permette di scegliere la strategia migliore per ogni componente dei sistemi di IA aziendali.
Il transfer learning è il concetto più ampio di sfruttare le conoscenze acquisite da un compito per migliorare le prestazioni su un altro, mentre la personalizzazione è una specifica implementazione del transfer learning. La personalizzazione prende un modello pre-addestrato e ne regola i parametri su nuovi dati, mentre il transfer learning può includere anche l’estrazione di caratteristiche, in cui si congelano i pesi pre-addestrati e si addestrano solo nuovi livelli. Tutta la personalizzazione implica transfer learning, ma non tutto il transfer learning richiede la personalizzazione.
Il tempo di personalizzazione varia notevolmente in base alla dimensione del modello, alla quantità di dati e all’hardware disponibile. Utilizzando tecniche efficienti come LoRA, un modello da 13 miliardi di parametri può essere personalizzato in circa 5 ore su una singola GPU A100. Modelli più piccoli o metodi efficienti possono richiedere solo poche ore, mentre la personalizzazione completa di modelli molto grandi può richiedere giorni o settimane. Il vantaggio principale è che la personalizzazione è molto più veloce rispetto all’addestramento da zero, che può richiedere mesi.
Sì, la personalizzazione è progettata proprio per funzionare efficacemente con dati limitati. I modelli pre-addestrati hanno già appreso schemi generali, quindi di solito bastano centinaia o migliaia di esempi per una personalizzazione efficace, rispetto ai milioni necessari per l’addestramento da zero. Tuttavia, la qualità dei dati è più importante della quantità: un piccolo dataset di esempi di alta qualità e rappresentativi darà risultati migliori di un dataset più grande ma con etichette poco coerenti o rumorose.
LoRA (Low-Rank Adaptation) è una tecnica di personalizzazione efficiente che aggiunge matrici a basso rango addestrabili alle matrici dei pesi di un modello invece di aggiornare tutti i parametri. Questo approccio riduce i parametri da addestrare di migliaia di volte mantenendo prestazioni paragonabili alla personalizzazione completa. LoRA è importante perché rende la personalizzazione accessibile anche su hardware standard, riduce drasticamente la memoria necessaria e permette alle organizzazioni di personalizzare grandi modelli senza infrastrutture costose.
L’overfitting si verifica quando la perdita di addestramento diminuisce ma quella di validazione aumenta, indicando che il modello sta memorizzando i dati di addestramento invece di apprendere schemi generalizzabili. Monitora entrambe le metriche durante l’addestramento: se le prestazioni in validazione si stabilizzano o peggiorano mentre quelle in training continuano a migliorare, probabilmente il tuo modello sta overfittando. Usa l’early stopping per interrompere l’addestramento quando le prestazioni in validazione smettono di migliorare e adotta tecniche come la regolarizzazione e l’augmentazione dei dati per prevenire l’overfitting.
I costi della personalizzazione includono risorse computazionali (tempo GPU/TPU), preparazione e etichettatura dei dati, infrastruttura per l’archiviazione e il deployment dei modelli, oltre al monitoraggio e alla manutenzione. Tuttavia, questi costi sono tipicamente 10-100 volte inferiori rispetto all’addestramento da zero. L’uso di tecniche efficienti come LoRA può ridurre i costi computazionali dell’80-90% rispetto alla personalizzazione completa, rendendo la personalizzazione una scelta economica per la maggior parte delle organizzazioni.
Sì, la personalizzazione generalmente migliora notevolmente l’accuratezza del modello su compiti specifici. Addestrando su dati settoriali, i modelli apprendono schemi e terminologie rilevanti che i modelli generici non colgono. Studi dimostrano che la personalizzazione può aumentare l’accuratezza del 10-30% o più a seconda del compito e della qualità dei dati. Il miglioramento è più marcato quando il compito di personalizzazione differisce da quello di pre-addestramento, poiché il modello adatta le sue abilità alle esigenze specifiche.
La personalizzazione consente alle organizzazioni di mantenere i dati sensibili sulle proprie infrastrutture senza inviarli a API di terzi. Puoi personalizzare i modelli localmente su dati proprietari o regolamentati senza esporli all’esterno, garantendo la conformità a regolamenti come GDPR, HIPAA o altri requisiti settoriali. Questo approccio offre vantaggi in termini di sicurezza e conformità, mantenendo le prestazioni dei modelli pre-addestrati.
Tieni traccia di come sistemi di IA come GPTs, Perplexity e Google AI Overviews citano e fanno riferimento al tuo brand con la piattaforma di monitoraggio IA di AmICited.
Scopri come i sistemi di personalizzazione della memoria AI costruiscono profili utente dettagliati per offrire raccomandazioni di brand personalizzate. Compren...

Definizione di fine-tuning: adattamento dei modelli AI pre-addestrati a compiti specifici tramite addestramento su dati di dominio. Scopri come il fine-tuning m...

Scopri cosa sono le immagini personalizzate e i contenuti visivi originali, la loro importanza per l'identità del brand, la SEO e la visibilità nella ricerca IA...