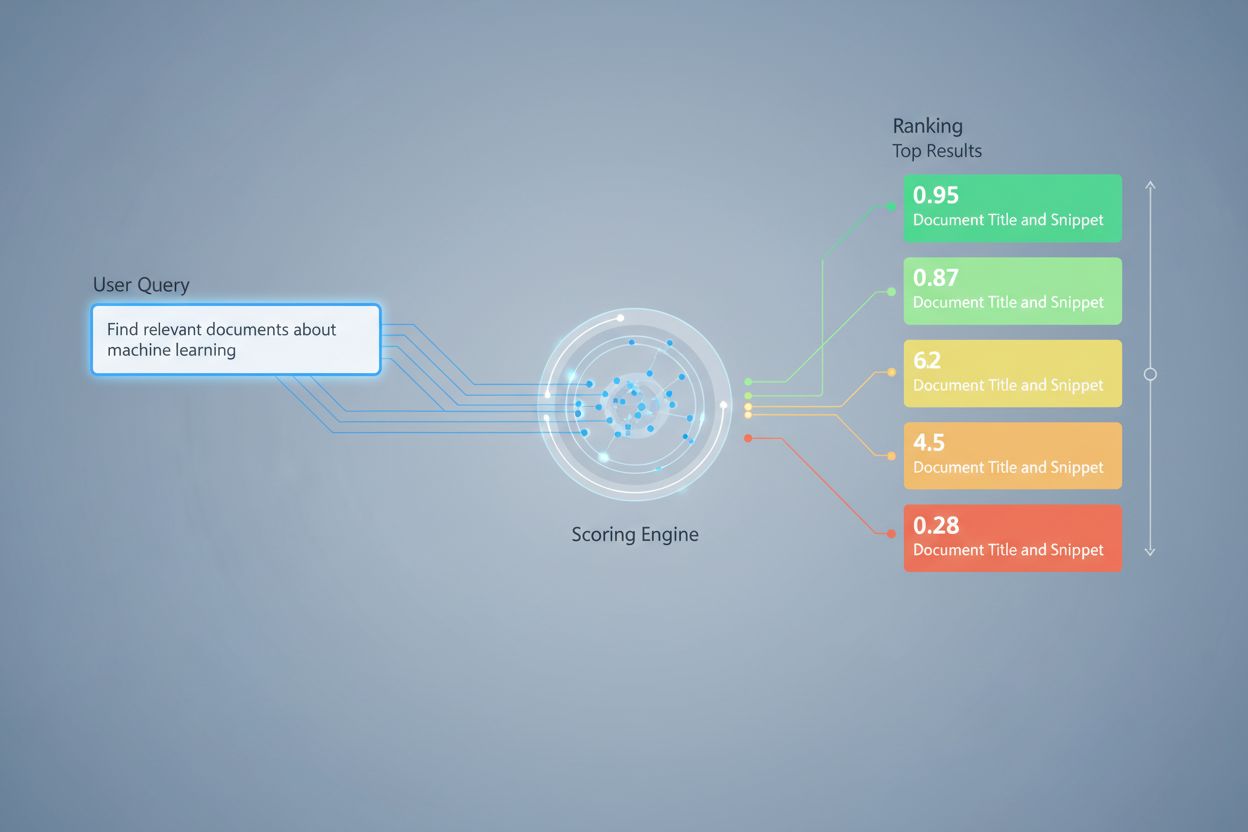
La valutazione del recupero AI è il processo di quantificazione della rilevanza e della qualità dei documenti o passaggi recuperati in relazione a una query utente. Impiega algoritmi sofisticati per valutare il significato semantico, l’adeguatezza contestuale e la qualità delle informazioni, determinando quali fonti vengono inviate ai modelli linguistici per la generazione delle risposte nei sistemi RAG.
Valutazione del Recupero AI
La valutazione del recupero AI è il processo di quantificazione della rilevanza e della qualità dei documenti o passaggi recuperati in relazione a una query utente. Impiega algoritmi sofisticati per valutare il significato semantico, l’adeguatezza contestuale e la qualità delle informazioni, determinando quali fonti vengono inviate ai modelli linguistici per la generazione delle risposte nei sistemi RAG.
Che cos’è la Valutazione del Recupero AI
La valutazione del recupero AI è il processo di quantificazione della rilevanza e della qualità dei documenti o passaggi recuperati in relazione a una query o compito dell’utente. A differenza del semplice matching di parole chiave, che identifica solo la sovrapposizione superficiale dei termini, la valutazione del recupero impiega algoritmi sofisticati per valutare il significato semantico, l’adeguatezza contestuale e la qualità delle informazioni. Questo meccanismo di valutazione è fondamentale per i sistemi di Generazione Potenziata dal Recupero (RAG), dove determina quali fonti vengono inviate ai modelli linguistici per la generazione delle risposte. Nelle moderne applicazioni LLM, la valutazione del recupero influisce direttamente sull’accuratezza delle risposte, sulla riduzione delle allucinazioni e sulla soddisfazione dell’utente, assicurando che solo le informazioni più rilevanti raggiungano la fase di generazione. La qualità della valutazione del recupero è quindi una componente critica della performance complessiva e dell’affidabilità del sistema.
Metodi e Algoritmi di Valutazione del Recupero
La valutazione del recupero impiega molteplici approcci algoritmici, ciascuno con punti di forza distinti per diversi casi d’uso. La valutazione della similarità semantica utilizza modelli di embedding per misurare l’allineamento concettuale tra query e documenti nello spazio vettoriale, cogliendo significati oltre le parole chiave superficiali. BM25 (Best Matching 25) è una funzione di ranking probabilistica che considera la frequenza dei termini, la frequenza inversa dei documenti e la normalizzazione della lunghezza del documento, risultando molto efficace per il recupero testuale tradizionale. TF-IDF (Term Frequency-Inverse Document Frequency) pondera i termini in base alla loro importanza all’interno dei documenti e tra le collezioni, anche se manca di comprensione semantica. Gli approcci ibridi combinano più metodi—come la fusione di punteggi BM25 e semantici—per sfruttare sia segnali lessicali che semantici. Oltre ai metodi di valutazione, metriche di valutazione come Precision@k (percentuale dei primi k risultati rilevanti), Recall@k (percentuale di tutti i documenti rilevanti trovati nei primi k), NDCG (Normalized Discounted Cumulative Gain, che tiene conto della posizione nel ranking) e MRR (Mean Reciprocal Rank) forniscono misure quantitative della qualità del recupero. Comprendere i punti di forza e di debolezza di ciascun approccio—come l’efficienza di BM25 rispetto alla comprensione profonda della valutazione semantica—è essenziale per selezionare i metodi appropriati per specifiche applicazioni.
Metodo di Valutazione
Come Funziona
Ideale Per
Vantaggio Chiave
Similarità Semantica
Confronta gli embeddings usando la similarità del coseno o altre metriche di distanza
Significato concettuale, sinonimi, parafrasi
Coglie relazioni semantiche oltre le parole chiave
BM25
Ranking probabilistico che considera frequenza dei termini e lunghezza del documento
Corrispondenza esatta di frasi, query basate su parole chiave
Veloce, efficiente, comprovato nei sistemi di produzione
TF-IDF
Pondera i termini in base alla frequenza nel documento e rarità nella collezione
Recupero di informazioni tradizionale
Semplice, interpretabile, leggero
Valutazione Ibrida
Combina approcci semantici e basati su parole chiave con fusione ponderata
Recupero generico, query complesse
Sfrutta i punti di forza di più metodi
Valutazione basata su LLM
Usa modelli linguistici per giudicare la rilevanza con prompt personalizzati
Valutazione contestuale complessa, compiti specifici di dominio
Coglie relazioni semantiche sfumate
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
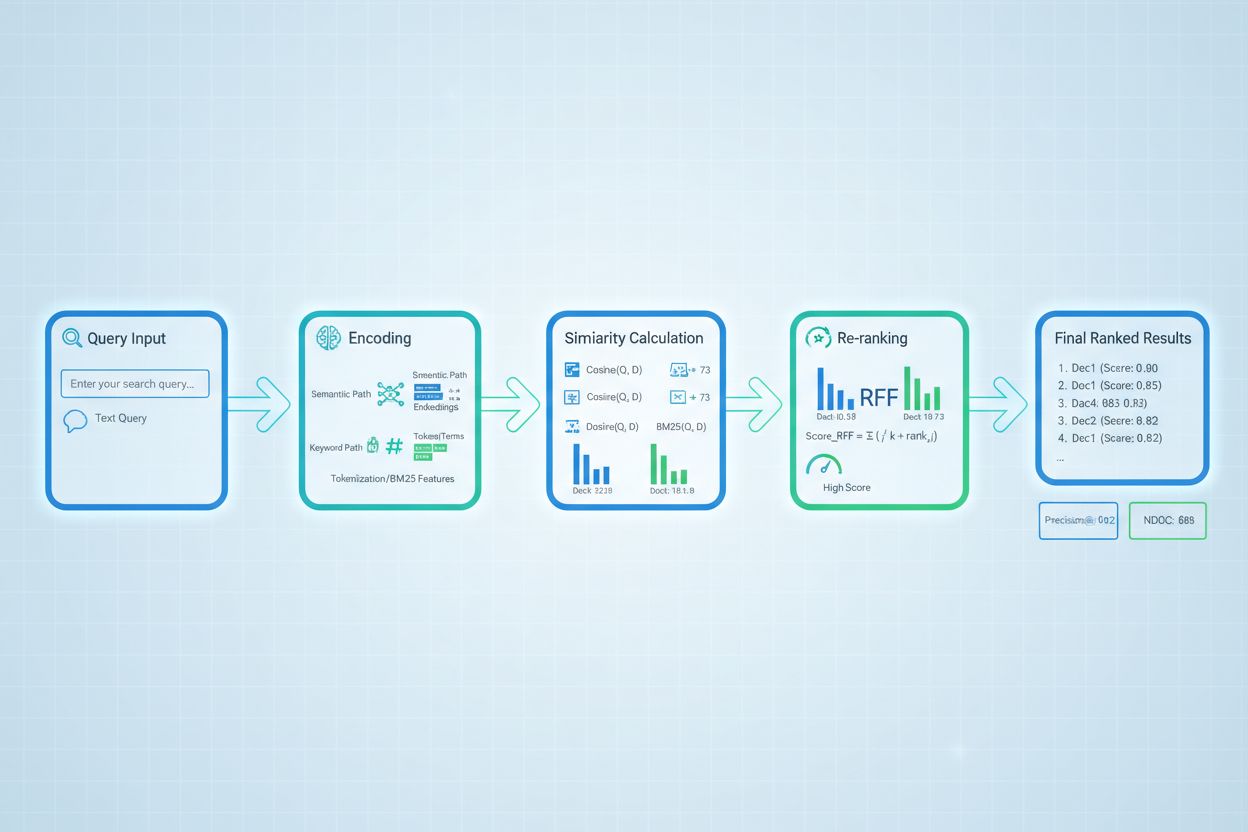
Nei sistemi RAG, la valutazione del recupero opera a più livelli per garantire la qualità della generazione. Il sistema solitamente valuta singoli chunk o passaggi all’interno dei documenti, consentendo una valutazione della rilevanza a grana fine piuttosto che trattare interi documenti come unità atomiche. Questa valutazione della rilevanza per chunk permette al sistema di estrarre solo i segmenti informativi più pertinenti, riducendo il rumore e il contesto irrilevante che potrebbero confondere il modello linguistico. I sistemi RAG implementano spesso soglie di valutazione o meccanismi di cutoff che filtrano i risultati con punteggi bassi prima che raggiungano la fase di generazione, evitando che fonti di scarsa qualità influenzino la risposta finale. La qualità del contesto recuperato è direttamente correlata alla qualità della generazione—passaggi rilevanti e con punteggio elevato portano a risposte più accurate e fondate, mentre recuperi di bassa qualità introducono allucinazioni ed errori fattuali. Il monitoraggio dei punteggi di valutazione fornisce segnali di allerta precoce per il degrado del sistema, rendendolo una metrica chiave per il monitoraggio delle risposte AI e l’assicurazione della qualità nei sistemi di produzione.
Re-ranking e Affinamento dei Punteggi
Il re-ranking funge da meccanismo di filtro di secondo passaggio che affina i risultati iniziali del recupero, migliorando spesso in modo significativo l’accuratezza del ranking. Dopo che un retriever iniziale genera risultati candidati con punteggi preliminari, un re-ranker applica una logica di valutazione più sofisticata per riordinare o filtrare questi candidati, tipicamente usando modelli computazionalmente più costosi che possono permettersi un’analisi più approfondita. Reciprocal Rank Fusion (RRF) è una tecnica popolare che combina i ranking di più retriever assegnando punteggi in base alla posizione del risultato, quindi fondendo questi punteggi per produrre un ranking unificato che spesso supera i singoli retriever. La normalizzazione dei punteggi diventa critica quando si combinano risultati da diversi metodi di recupero, poiché i punteggi grezzi di BM25, similarità semantica e altri approcci operano su scale diverse e devono essere calibrati su intervalli comparabili. Gli approcci di retriever ensemble sfruttano simultaneamente più strategie di recupero, con il re-ranking che determina l’ordinamento finale in base alle evidenze combinate. Questo approccio multi-stadio migliora significativamente accuratezza e robustezza del ranking rispetto al recupero a singolo stadio, in particolare in domini complessi dove diversi metodi di recupero catturano segnali di rilevanza complementari.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Principali Metriche di Valutazione per la Valutazione del Recupero
Precision@k: misura la proporzione di documenti rilevanti tra i primi k risultati; utile per valutare se i risultati recuperati sono affidabili (es. Precision@5 = 4/5 significa che l’80% dei primi 5 risultati è rilevante)
Recall@k: calcola la percentuale di tutti i documenti rilevanti trovati tra i primi k risultati; importante per garantire una copertura completa delle informazioni rilevanti disponibili
Hit Rate: metrica binaria che indica se almeno un documento rilevante appare tra i primi k risultati; utile per controlli rapidi della qualità nei sistemi di produzione
NDCG (Normalized Discounted Cumulative Gain): tiene conto della posizione nel ranking assegnando valore maggiore ai documenti rilevanti che appaiono prima; varia da 0 a 1 ed è ideale per valutare la qualità del ranking
MRR (Mean Reciprocal Rank): misura la posizione media del primo risultato rilevante su più query; particolarmente utile per valutare se il documento più rilevante è in alto nel ranking
F1 Score: media armonica di precisione e recall; fornisce una valutazione bilanciata quando sia i falsi positivi che i falsi negativi sono importanti
MAP (Mean Average Precision): fa la media dei valori di precisione in ogni posizione in cui viene trovato un documento rilevante; metrica completa per la qualità complessiva del ranking su più query
Valutazione della Rilevanza basata su LLM
La valutazione della rilevanza basata su LLM sfrutta gli stessi modelli linguistici come giudici della rilevanza dei documenti, offrendo un’alternativa flessibile agli approcci algoritmici tradizionali. In questo paradigma, prompt attentamente progettati istruiscono un LLM a valutare se un passaggio recuperato risponde a una determinata query, producendo sia punteggi di rilevanza binari (rilevante/non rilevante) sia punteggi numerici (es. scala da 1 a 5 che indica la forza della rilevanza). Questo approccio coglie relazioni semantiche sfumate e rilevanza specifica di dominio che gli algoritmi tradizionali potrebbero non rilevare, in particolare per query complesse che richiedono una comprensione profonda. Tuttavia, la valutazione basata su LLM introduce sfide tra cui il costo computazionale (l’inferenza LLM è più costosa rispetto alla similarità tra embedding), la potenziale incoerenza tra prompt e modelli diversi e la necessità di calibrazione con etichette umane per garantire che i punteggi riflettano la reale rilevanza. Nonostante queste limitazioni, la valutazione basata su LLM si è dimostrata preziosa per valutare la qualità dei sistemi RAG e per creare dati di training per modelli di valutazione specializzati, rendendola uno strumento importante nel toolkit di monitoraggio AI per la valutazione della qualità delle risposte.
Considerazioni Pratiche sull’Implementazione
Implementare una valutazione del recupero efficace richiede un’attenta considerazione di diversi fattori pratici. La selezione del metodo dipende dai requisiti del caso d’uso: la valutazione semantica eccelle nel cogliere il significato ma richiede modelli di embedding, mentre BM25 offre velocità ed efficienza per il matching lessicale. Il compromesso tra velocità e accuratezza è fondamentale—la valutazione basata sugli embedding offre una comprensione della rilevanza superiore ma introduce costi di latenza, mentre BM25 e TF-IDF sono più veloci ma meno sofisticati semanticamente. Le considerazioni sul costo computazionale includono il tempo di inferenza del modello, i requisiti di memoria e le esigenze di scalabilità dell’infrastruttura, particolarmente importanti per sistemi di produzione ad alto volume. L’ottimizzazione dei parametri comporta la regolazione di soglie, pesi negli approcci ibridi e cut-off nel re-ranking per ottimizzare le prestazioni in domini e casi d’uso specifici. Il monitoraggio continuo delle prestazioni di valutazione tramite metriche come NDCG e Precision@k aiuta a identificare tempestivamente eventuali degradi, consentendo miglioramenti proattivi del sistema e garantendo una qualità delle risposte costante nei sistemi RAG di produzione.
Tecniche di Valutazione Avanzate
Le tecniche avanzate di valutazione del recupero vanno oltre la semplice valutazione della rilevanza per cogliere relazioni contestuali complesse. La riscrittura delle query può migliorare la valutazione riformulando le query utente in più forme semanticamente equivalenti, consentendo al retriever di trovare documenti rilevanti che potrebbero essere persi con il matching letterale. Gli embedding di documenti ipotetici (HyDE) generano documenti sintetici rilevanti a partire dalle query, utilizzando poi questi ipotetici per migliorare la valutazione del recupero trovando documenti reali simili al contenuto rilevante idealizzato. Gli approcci multi-query inviano più variazioni di query ai retriever e aggregano i loro punteggi, migliorando la robustezza e la copertura rispetto al recupero a singola query. I modelli di valutazione specifici di dominio addestrati su dati etichettati di particolari settori o domini di conoscenza possono ottenere prestazioni superiori rispetto ai modelli generalisti, particolarmente preziosi per applicazioni specialistiche come i sistemi AI in ambito medico o legale. Le regolazioni contestuali della valutazione tengono conto di fattori come la recentezza del documento, l’autorevolezza della fonte e il contesto utente, consentendo una valutazione della rilevanza più sofisticata che va oltre la pura similarità semantica per incorporare fattori di rilevanza reale cruciali per i sistemi AI in produzione.
Domande frequenti
Qual è la differenza tra valutazione del recupero e ranking?
La valutazione del recupero assegna valori numerici di rilevanza ai documenti in base alla loro relazione con una query, mentre il ranking ordina i documenti in base a questi punteggi. La valutazione è il processo di valutazione, il ranking è il risultato dell’ordinamento. Entrambi sono essenziali affinché i sistemi RAG forniscano risposte accurate.
Perché la valutazione del recupero è importante per i sistemi RAG?
La valutazione del recupero determina quali fonti raggiungono il modello linguistico per la generazione delle risposte. Una valutazione di alta qualità garantisce la selezione di informazioni rilevanti, riducendo le allucinazioni e migliorando l’accuratezza delle risposte. Una valutazione scadente porta a contesti irrilevanti e risposte AI inaffidabili.
In cosa differiscono la valutazione semantica e quella basata sulle parole chiave?
La valutazione semantica utilizza gli embeddings per comprendere il significato concettuale e cogliere sinonimi e concetti correlati. La valutazione basata sulle parole chiave (come BM25) abbina termini e frasi esatti. La valutazione semantica è migliore per comprendere l’intento, mentre quella per parole chiave eccelle nel trovare informazioni specifiche.
Quali metriche dovrei usare per valutare la valutazione del recupero?
Le metriche chiave includono Precision@k (accuratezza dei primi risultati), Recall@k (copertura dei documenti rilevanti), NDCG (qualità del ranking) e MRR (posizione del primo risultato rilevante). Scegli le metriche in base al tuo caso d’uso: Precision@k per sistemi orientati alla qualità, Recall@k per una copertura completa.
Si possono usare gli LLM per valutare i risultati del recupero?
Sì, la valutazione basata su LLM utilizza i modelli linguistici come giudici per valutare la rilevanza. Questo approccio coglie relazioni semantiche sfumate ma è computazionalmente costoso. È utile per valutare la qualità dei sistemi RAG e creare dati di training, sebbene richieda calibrazione con etichette umane.
Come il re-ranking migliora la valutazione del recupero?
Il re-ranking applica un filtro di secondo livello utilizzando modelli più sofisticati per affinare i risultati iniziali. Tecniche come Reciprocal Rank Fusion combinano più metodi di recupero, migliorando accuratezza e robustezza. Il re-ranking supera di gran lunga il recupero a singolo stadio in domini complessi.
Qual è il costo computazionale dei diversi metodi di valutazione?
BM25 e TF-IDF sono veloci e leggeri, adatti a sistemi in tempo reale. La valutazione semantica richiede l’inferenza di modelli di embedding, aggiungendo latenza. La valutazione basata su LLM è la più costosa. Scegli in base alle tue esigenze di latenza e alle risorse computazionali disponibili.
Come scelgo il metodo di valutazione giusto per il mio caso d’uso?
Considera le tue priorità: valutazione semantica per attività incentrate sul significato, BM25 per velocità ed efficienza, approcci ibridi per prestazioni bilanciate. Valuta sul tuo dominio specifico usando metriche come NDCG e Precision@k. Testa più metodi e misura il loro impatto sulla qualità finale delle risposte.
Monitora la Qualità delle Fonti della Tua AI con AmICited
Traccia come sistemi AI come ChatGPT, Perplexity e Google AI fanno riferimento al tuo brand e valuta la qualità del loro recupero e classificazione delle fonti. Assicurati che i tuoi contenuti siano correttamente citati e classificati dai sistemi AI.
Come funziona la Retrieval-Augmented Generation: Architettura e Processo
Scopri come RAG combina LLM e fonti di dati esterne per generare risposte AI accurate. Comprendi il processo in cinque fasi, i componenti e perché è importante ...
Scopri cos'è la Generazione Aumentata dal Recupero (RAG), come funziona e perché è essenziale per risposte AI accurate. Esplora l’architettura RAG, i vantaggi e...
Scopri come la valutazione della rilevanza dei contenuti utilizza algoritmi AI per misurare quanto bene i contenuti corrispondono alle query e all’intento degli...
8 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.