Cos'è la Prompt Engineering per la Ricerca AI - Guida Completa
Scopri cos’è la prompt engineering, come funziona con i motori di ricerca AI come ChatGPT e Perplexity, e scopri le tecniche fondamentali per ottimizzare i tuoi...
11 min di lettura
Un meccanismo di attenzione è una componente delle reti neurali che assegna dinamicamente il peso all’importanza dei diversi elementi di input, permettendo ai modelli di concentrarsi sulle parti più rilevanti dei dati durante le previsioni. Calcola i pesi di attenzione attraverso trasformazioni apprese di query, chiavi e valori, consentendo ai modelli di deep learning di catturare dipendenze a lungo raggio e relazioni contestuali nei dati sequenziali.
Un meccanismo di attenzione è una componente delle reti neurali che assegna dinamicamente il peso all’importanza dei diversi elementi di input, permettendo ai modelli di concentrarsi sulle parti più rilevanti dei dati durante le previsioni. Calcola i pesi di attenzione attraverso trasformazioni apprese di query, chiavi e valori, consentendo ai modelli di deep learning di catturare dipendenze a lungo raggio e relazioni contestuali nei dati sequenziali.
Il meccanismo di attenzione è una tecnica di machine learning che guida i modelli di deep learning a dare priorità (o “prestare attenzione”) alle parti più rilevanti dei dati di input durante le previsioni. Invece di trattare tutti gli elementi di input allo stesso modo, i meccanismi di attenzione calcolano pesi di attenzione che riflettono l’importanza relativa di ciascun elemento rispetto al compito da svolgere, e applicano tali pesi per enfatizzare o attenuare dinamicamente specifici input. Questa innovazione fondamentale è diventata il pilastro delle moderne architetture transformer e dei large language model (LLM) come ChatGPT, Claude e Perplexity, permettendo loro di elaborare dati sequenziali con efficienza e accuratezza senza precedenti. Il meccanismo si ispira all’attenzione cognitiva umana—la capacità di concentrarsi selettivamente sui dettagli salienti escludendo le informazioni irrilevanti—e traduce questo principio biologico in una componente delle reti neurali matematicamente rigorosa e apprendibile.
Il concetto di meccanismi di attenzione è stato introdotto per la prima volta da Bahdanau e colleghi nel 2014 per affrontare i limiti critici delle reti neurali ricorrenti (RNN) utilizzate per la traduzione automatica. Prima dell’introduzione dell’attenzione, i modelli Seq2Seq si affidavano a un singolo vettore di contesto per codificare intere frasi di origine, creando un collo di bottiglia informativo che limitava gravemente le prestazioni su sequenze più lunghe. Il meccanismo di attenzione originale consentiva al decoder di accedere a tutti gli stati nascosti dell’encoder invece che solo all’ultimo, selezionando dinamicamente quali parti dell’input fossero più rilevanti a ogni passo di decodifica. Questa innovazione migliorò drasticamente la qualità della traduzione, in particolare per le frasi più lunghe. Nel 2015, Luong e colleghi introdussero la dot-product attention, che sostituì la costosa additive attention con una moltiplicazione matriciale efficiente. Il momento cruciale arrivò nel 2017 con la pubblicazione di “Attention is All You Need”, che introdusse l’architettura transformer eliminando completamente la ricorrenza a favore di puri meccanismi di attenzione. Questo articolo rivoluzionò il deep learning, consentendo lo sviluppo di BERT, dei modelli GPT e di tutto l’ecosistema moderno dell’IA generativa. Oggi, i meccanismi di attenzione sono onnipresenti nell’elaborazione del linguaggio naturale, nella computer vision e nei sistemi IA multimodali, con oltre l’85% dei modelli all’avanguardia che incorporano qualche forma di architettura basata sull’attenzione.
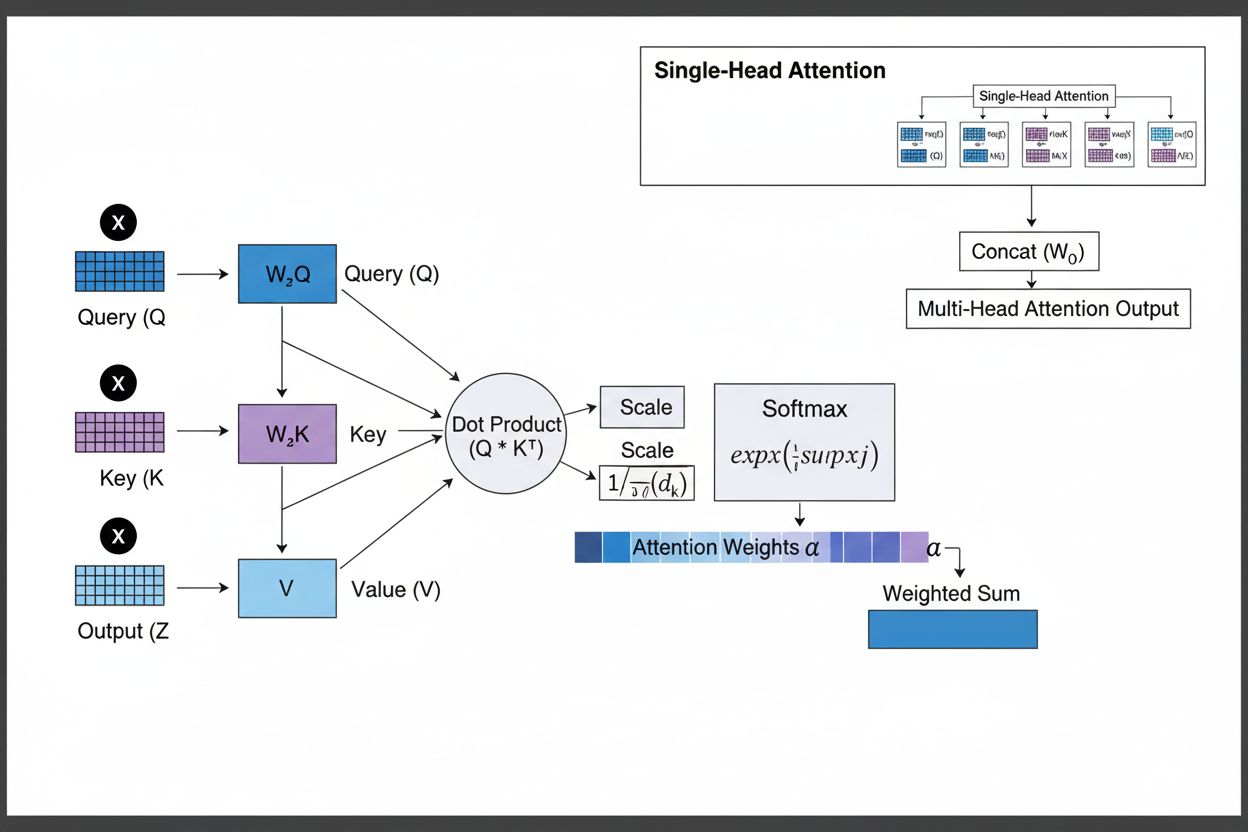
Il meccanismo di attenzione opera tramite un sofisticato intreccio di tre componenti matematiche fondamentali: query (Q), chiavi (K) e valori (V). Ogni elemento di input viene trasformato in queste tre rappresentazioni tramite proiezioni lineari apprese, creando una struttura simile a un database relazionale dove le chiavi fungono da identificatori e i valori contengono le informazioni effettive. Il meccanismo calcola i punteggi di allineamento misurando la similarità tra una query e tutte le chiavi, tipicamente usando la scaled dot-product attention dove il punteggio è calcolato come QK^T/√d_k. Questi punteggi grezzi vengono poi normalizzati tramite la funzione softmax, che li converte in una distribuzione di probabilità in cui tutti i pesi sommano a 1, assicurando che ogni elemento riceva un peso tra 0 e 1. L’ultimo passo consiste nel calcolare una somma pesata dei vettori valore utilizzando questi pesi di attenzione, producendo un vettore di contesto che rappresenta le informazioni più rilevanti dell’intera sequenza di input. Questo vettore di contesto viene poi combinato con l’input originale tramite connessioni residue e passato attraverso layer feedforward, permettendo al modello di raffinare iterativamente la comprensione dell’input. L’eleganza matematica di questo design—che combina trasformazioni apprendibili, calcoli di similarità e pesatura probabilistica—consente ai meccanismi di attenzione di catturare dipendenze complesse rimanendo completamente differenziabili per l’ottimizzazione tramite gradiente.
| Tipo di Attenzione | Metodo di Calcolo | Complessità Computazionale | Caso d’Uso Ottimale | Vantaggio Chiave |
|---|---|---|---|---|
| Additive Attention | Rete feed-forward + attivazione tanh | O(n·d) per query | Sequenze brevi, dimensioni variabili | Gestisce diverse dimensioni query/chiave |
| Dot-Product Attention | Semplice moltiplicazione matriciale | O(n·d) per query | Sequenze standard | Efficiente computazionalmente |
| Scaled Dot-Product | QK^T/√d_k + softmax | O(n·d) per query | Transformer moderni | Previene la scomparsa dei gradienti |
| Multi-Head Attention | Più teste di attenzione parallele | O(h·n·d) con h=teste | Relazioni complesse | Cattura aspetti semantici diversi |
| Self-Attention | Query, chiavi, valori dalla stessa sequenza | O(n²·d) | Relazioni intra-sequenza | Permette l’elaborazione parallela |
| Cross-Attention | Query da una sequenza, chiavi/valori da un’altra | O(n·m·d) | Encoder-decoder, multimodale | Allinea diverse modalità |
| Grouped Query Attention | Chiavi/valori condivisi tra le teste di query | O(n·d) | Inferenza efficiente | Riduce memoria e calcolo |
| Sparse Attention | Attenzione limitata a posizioni locali/strided | O(n·√n·d) | Sequenze molto lunghe | Gestisce sequenze estremamente lunghe |
Il meccanismo di attenzione opera tramite una sequenza orchestrata di trasformazioni matematiche che permettono alle reti neurali di concentrarsi dinamicamente sulle informazioni rilevanti. Durante l’elaborazione di una sequenza di input, ogni elemento viene prima incorporato in uno spazio vettoriale ad alta dimensione, catturando informazioni semantiche e sintattiche. Questi embedding vengono poi proiettati in tre spazi separati tramite matrici di peso apprese: lo spazio delle query (che rappresenta le informazioni cercate), lo spazio delle chiavi (che rappresenta ciò che ogni elemento contiene) e lo spazio dei valori (che contiene i dati effettivi da aggregare). Per ogni posizione query, il meccanismo calcola un punteggio di similarità con ogni chiave tramite il prodotto scalare, producendo un vettore di punteggi grezzi di allineamento. Questi punteggi vengono scalati dividendo per la radice quadrata della dimensione delle chiavi (√d_k), un passo critico che impedisce ai prodotti scalari di diventare troppo grandi con dimensioni elevate, evitando così la scomparsa dei gradienti durante il backpropagation. I punteggi scalati vengono poi passati tramite una funzione softmax, che li esponenzia e li normalizza affinché sommino a 1, creando una distribuzione di probabilità su tutte le posizioni di input. Infine, questi pesi di attenzione vengono usati per calcolare una media pesata dei vettori valore, dove le posizioni con pesi di attenzione più elevati contribuiscono maggiormente al vettore di contesto finale. Questo vettore di contesto viene poi combinato con l’input originale tramite connessioni residue e processato da layer feedforward, permettendo al modello di raffinare iterativamente le sue rappresentazioni. L’intero processo è differenziabile, consentendo al modello di apprendere schemi di attenzione ottimali tramite discesa del gradiente durante l’addestramento.
I meccanismi di attenzione costituiscono il blocco fondamentale delle architetture transformer, che sono diventate il paradigma dominante nel deep learning. A differenza delle RNN che elaborano le sequenze in modo sequenziale e delle CNN che operano su finestre fisse locali, i transformer utilizzano la self-attention per permettere a ogni posizione di prestare attenzione direttamente a tutte le altre posizioni contemporaneamente, abilitando una massiccia parallelizzazione su GPU e TPU. L’architettura transformer consiste in layer alternati di multi-head self-attention e reti feedforward, con ogni layer di attenzione che consente al modello di raffinare la comprensione dell’input concentrandosi selettivamente su diversi aspetti. La multi-head attention esegue più meccanismi di attenzione in parallelo, con ogni testa che impara a concentrarsi su diversi tipi di relazioni—una testa può specializzarsi in dipendenze grammaticali, un’altra in relazioni semantiche e una terza in coreferenze a lunga distanza. Gli output di tutte le teste vengono concatenati e proiettati, consentendo al modello di mantenere consapevolezza simultanea di molteplici fenomeni linguistici. Questa architettura si è dimostrata straordinariamente efficace per i large language model come GPT-4, Claude 3 e Gemini, che utilizzano architetture transformer solo decoder dove ogni token può prestare attenzione solo ai token precedenti (causal masking) per mantenere la proprietà autoregressiva della generazione. La capacità del meccanismo di attenzione di catturare dipendenze a lungo raggio senza i problemi di gradienti che affliggevano le RNN è stata fondamentale per permettere a questi modelli di processare finestre di contesto di oltre 100.000 token, mantenendo coerenza e consistenza su grandi quantità di testo. Le ricerche dimostrano che circa il 92% dei modelli NLP all’avanguardia ora si basa su architetture transformer alimentate da meccanismi di attenzione, a conferma della loro importanza fondamentale nei sistemi IA moderni.
Nel contesto delle piattaforme di ricerca IA come ChatGPT, Perplexity, Claude e Google AI Overviews, i meccanismi di attenzione svolgono un ruolo cruciale nel determinare quali parti dei documenti recuperati e delle basi di conoscenza siano più rilevanti per le query degli utenti. Quando questi sistemi generano risposte, i loro meccanismi di attenzione ponderano dinamicamente diverse fonti e passaggi in base alla rilevanza, consentendo loro di sintetizzare risposte coerenti da più fonti mantenendo l’accuratezza fattuale. I pesi di attenzione calcolati durante la generazione possono essere analizzati per capire quali informazioni il modello ha privilegiato, fornendo insight su come i sistemi IA interpretano e rispondono alle query. Per il monitoraggio del brand e la GEO (Generative Engine Optimization), comprendere i meccanismi di attenzione è essenziale perché determinano quali contenuti e fonti ricevono enfasi nelle risposte generate dall’IA. I contenuti strutturati in modo da allinearsi a come i meccanismi di attenzione ponderano le informazioni—tramite definizioni chiare di entità, fonti autorevoli e rilevanza contestuale—hanno maggiori probabilità di essere citati e messi in evidenza nelle risposte IA. AmICited sfrutta le conoscenze sui meccanismi di attenzione per tracciare come brand e domini appaiono sulle piattaforme IA, riconoscendo che le citazioni ponderate dall’attenzione rappresentano le menzioni più influenti nei contenuti generati dall’IA. Poiché le aziende monitorano sempre più la loro presenza nelle risposte IA, comprendere che i meccanismi di attenzione guidano i pattern di citazione diventa fondamentale per ottimizzare la strategia dei contenuti e garantire la visibilità del brand nell’era dell’IA generativa.
Il campo dei meccanismi di attenzione continua a evolversi rapidamente, con i ricercatori che sviluppano varianti sempre più sofisticate per affrontare limiti computazionali e migliorare le prestazioni. Gli schemi di attenzione sparsa limitano l’attenzione ai vicinati locali o a posizioni strided, riducendo la complessità da O(n²) a O(n·√n) mantenendo le prestazioni su sequenze molto lunghe. I meccanismi di attenzione efficiente come FlashAttention ottimizzano i pattern di accesso alla memoria del calcolo dell’attenzione, ottenendo velocità 2-4x superiori grazie a un migliore utilizzo della GPU. La grouped query attention e la multi-query attention riducono il numero di teste chiave-valore mantenendo le prestazioni, diminuendo notevolmente i requisiti di memoria in fase di inferenza—una considerazione critica per il deployment di grandi modelli in produzione. Le architetture Mixture of Experts combinano l’attenzione con il routing sparso, permettendo ai modelli di scalare a trilioni di parametri mantenendo l’efficienza computazionale. Le ricerche emergenti esplorano pattern di attenzione appresi che si adattano dinamicamente in base alle caratteristiche dell’input, e attenzione gerarchica operante a più livelli di astrazione. L’integrazione dei meccanismi di attenzione con la retrieval-augmented generation (RAG) consente ai modelli di rivolgersi dinamicamente a conoscenze esterne rilevanti, migliorando la factualità e riducendo le allucinazioni. Poiché i sistemi IA vengono sempre più utilizzati in applicazioni critiche, i meccanismi di attenzione vengono arricchiti con funzionalità di spiegabilità che forniscono insight più chiari nelle decisioni del modello. Il futuro probabilmente vedrà architetture ibride che combinano l’attenzione con meccanismi alternativi come i modelli state-space (esemplificati da Mamba), che offrono complessità lineare mantenendo prestazioni competitive. Comprendere questi meccanismi di attenzione in evoluzione è essenziale sia per i professionisti che costruiscono i sistemi IA di nuova generazione sia per le organizzazioni che monitorano la propria presenza nei contenuti generati dall’IA, poiché i meccanismi che determinano i pattern di citazione e la prominenza dei contenuti continuano a progredire.
Per le organizzazioni che utilizzano AmICited per monitorare la visibilità del brand nelle risposte IA, comprendere i meccanismi di attenzione fornisce un contesto cruciale per interpretare i pattern di citazione. Quando ChatGPT, Claude o Perplexity citano il tuo dominio nelle loro risposte, i pesi di attenzione calcolati durante la generazione hanno determinato che i tuoi contenuti erano i più rilevanti per la query dell’utente. Contenuti di alta qualità e ben strutturati che definiscono chiaramente le entità e forniscono informazioni autorevoli ricevono naturalmente pesi di attenzione più elevati, aumentando la probabilità di essere selezionati per la citazione. Le funzionalità di visualizzazione dell’attenzione in alcune piattaforme IA mostrano quali fonti hanno ricevuto maggiore attenzione durante la generazione della risposta, evidenziando di fatto quali citazioni sono state più influenti. Questo insight consente alle organizzazioni di ottimizzare la loro strategia di contenuto comprendendo che i meccanismi di attenzione premiano chiarezza, rilevanza e autorevolezza delle fonti. Con la crescita della ricerca IA—oltre il 60% delle aziende ora investe in iniziative di IA generativa—la capacità di comprendere e ottimizzare per i meccanismi di attenzione diventa sempre più preziosa per mantenere la visibilità del brand e garantire una rappresentazione accurata nei contenuti generati dall’IA. L’intersezione tra meccanismi di attenzione e monitoraggio del brand rappresenta una frontiera della GEO, dove la comprensione delle basi matematiche su cui i sistemi IA ponderano e citano le informazioni si traduce direttamente in maggiore visibilità e influenza nell’ecosistema dell’IA generativa.
Le RNN tradizionali elaborano le sequenze in modo seriale, rendendo difficile catturare dipendenze a lungo raggio, mentre le CNN hanno campi recettivi locali fissi che limitano la capacità di modellare relazioni distanti. I meccanismi di attenzione superano queste limitazioni calcolando le relazioni tra tutte le posizioni di input contemporaneamente, consentendo l’elaborazione parallela e la cattura delle dipendenze indipendentemente dalla distanza. Questa flessibilità sia nel tempo che nello spazio rende i meccanismi di attenzione significativamente più efficienti ed efficaci per dati sequenziali e spaziali complessi.
Le query rappresentano le informazioni che il modello sta cercando, le chiavi rappresentano il contenuto informativo che ogni elemento di input contiene, e i valori contengono i dati reali da aggregare. Il modello calcola i punteggi di similarità tra query e chiavi per determinare quali valori dovrebbero ricevere il peso maggiore. Questa terminologia ispirata ai database, resa popolare dall’articolo 'Attention is All You Need', fornisce un quadro intuitivo per comprendere come i meccanismi di attenzione selezionano e combinano in modo selettivo le informazioni rilevanti dalle sequenze di input.
La self-attention calcola le relazioni all’interno di una singola sequenza di input, dove query, chiavi e valori provengono tutti dalla stessa fonte, permettendo al modello di capire come i diversi elementi si relazionano tra loro. La cross-attention, invece, utilizza query da una sequenza e chiavi/valori da un’altra sequenza, consentendo al modello di allineare e combinare informazioni da più fonti. La cross-attention è essenziale nelle architetture encoder-decoder come la traduzione automatica e nei modelli multimodali come Stable Diffusion che combinano informazioni testuali e visive.
La scaled dot-product attention utilizza la moltiplicazione invece dell’addizione per calcolare i punteggi di allineamento, rendendola computazionalmente più efficiente grazie alle operazioni matriciali che sfruttano la parallelizzazione della GPU. Il fattore di scala 1/√dk impedisce che i prodotti scalari diventino troppo grandi quando la dimensione delle chiavi è elevata, il che causerebbe la scomparsa dei gradienti durante il backpropagation. Sebbene la additive attention a volte superi la dot-product attention per dimensioni molto grandi, l’efficienza computazionale superiore e le prestazioni pratiche della scaled dot-product attention la rendono la scelta standard nelle architetture transformer moderne.
La multi-head attention esegue più meccanismi di attenzione in parallelo, ciascuna testa impara a concentrarsi su diversi aspetti dell’input come relazioni grammaticali, significato semantico o dipendenze a lunga distanza. Ogni testa opera su diverse proiezioni lineari dell’input, permettendo al modello di catturare simultaneamente diversi tipi di relazioni. Gli output di tutte le teste vengono concatenati e proiettati, consentendo al modello di mantenere una consapevolezza completa di molteplici caratteristiche linguistiche e contestuali simultaneamente, migliorando significativamente la qualità delle rappresentazioni e le prestazioni nei task a valle.
La softmax normalizza i punteggi grezzi di allineamento calcolati tra query e chiavi in una distribuzione di probabilità in cui tutti i pesi sommano a 1. Questa normalizzazione assicura che i pesi di attenzione siano interpretabili come punteggi di importanza, con valori più alti che indicano maggiore rilevanza. La funzione softmax è differenziabile, permettendo l’apprendimento basato su gradiente del meccanismo di attenzione durante l’addestramento, e la sua natura esponenziale enfatizza le differenze tra i punteggi, rendendo la focalizzazione del modello più selettiva e interpretabile.
I meccanismi di attenzione permettono a questi modelli di assegnare dinamicamente peso alle diverse parti del prompt di input in base alla rilevanza per il passo di generazione corrente. Durante la generazione di una risposta, il modello utilizza l’attenzione per determinare quali token precedenti ed elementi di input devono influenzare maggiormente la predizione del token successivo. Questa ponderazione contestuale consente ai modelli di mantenere coerenza, tracciare entità su lunghi documenti, risolvere ambiguità e generare risposte che fanno riferimento in modo appropriato a parti specifiche dell’input, rendendo gli output più accurati e contestualmente adeguati.
Inizia a tracciare come i chatbot AI menzionano il tuo brand su ChatGPT, Perplexity e altre piattaforme. Ottieni informazioni utili per migliorare la tua presenza AI.
Scopri cos’è la prompt engineering, come funziona con i motori di ricerca AI come ChatGPT e Perplexity, e scopri le tecniche fondamentali per ottimizzare i tuoi...
Scopri cos’è la LLMO e le tecniche comprovate per ottimizzare il tuo brand e ottenere visibilità nelle risposte generate dall’IA di ChatGPT, Perplexity, Claude ...
Scopri cos'è l'LLMO, come funziona e perché è importante per la visibilità nell'IA. Scopri tecniche di ottimizzazione per far menzionare il tuo brand in ChatGPT...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.