Centro di Eccellenza per la Visibilità dell’IA
Scopri cos'è un Centro di Eccellenza per la Visibilità dell’IA, le sue principali responsabilità, capacità di monitoraggio e come consente alle organizzazioni d...
9 min di lettura

Cohere è un’azienda di intelligenza artificiale focalizzata sulle imprese che sviluppa la famiglia Command di grandi modelli linguistici e gestisce un web crawler per la raccolta di dati di addestramento. La piattaforma offre soluzioni di IA sicure e personalizzabili per le aziende, tra cui generazione di testo, ricerca semantica e funzionalità di retrieval-augmented generation. La tecnologia di Cohere alimenta agenti di IA, automazione dei flussi di lavoro e creazione di contenuti su larga scala in diversi settori.
Cohere è un'azienda di intelligenza artificiale focalizzata sulle imprese che sviluppa la famiglia Command di grandi modelli linguistici e gestisce un web crawler per la raccolta di dati di addestramento. La piattaforma offre soluzioni di IA sicure e personalizzabili per le aziende, tra cui generazione di testo, ricerca semantica e funzionalità di retrieval-augmented generation. La tecnologia di Cohere alimenta agenti di IA, automazione dei flussi di lavoro e creazione di contenuti su larga scala in diversi settori.
Cohere è un’azienda di intelligenza artificiale focalizzata sulle imprese che si specializza nello sviluppo di potenti modelli linguistici e soluzioni di IA progettate specificamente per applicazioni aziendali. Fondata con la missione di rendere l’IA avanzata accessibile e sicura per le imprese, Cohere si è posizionata come leader nell’offrire tecnologie di IA personalizzabili, pronte per la produzione e che danno priorità alla sicurezza dei dati e al controllo organizzativo. L’offerta principale dell’azienda si concentra sulla famiglia di modelli linguistici Command, progettati per gestire flussi di lavoro aziendali complessi tra cui generazione di contenuti, retrieval-augmented generation (RAG), utilizzo di strumenti e applicazioni di IA agentica. A differenza delle piattaforme di IA rivolte ai consumatori, Cohere pone l’accento su sicurezza di livello enterprise, opzioni di implementazione privata e capacità di personalizzare i modelli su dati proprietari. L’azienda serve un’ampia gamma di settori tra cui servizi finanziari, sanità, tecnologia, manifatturiero e settore pubblico, con clienti di rilievo come Oracle, Fujitsu, Notion, Dell Technologies, RBC, SAP e Salesforce.
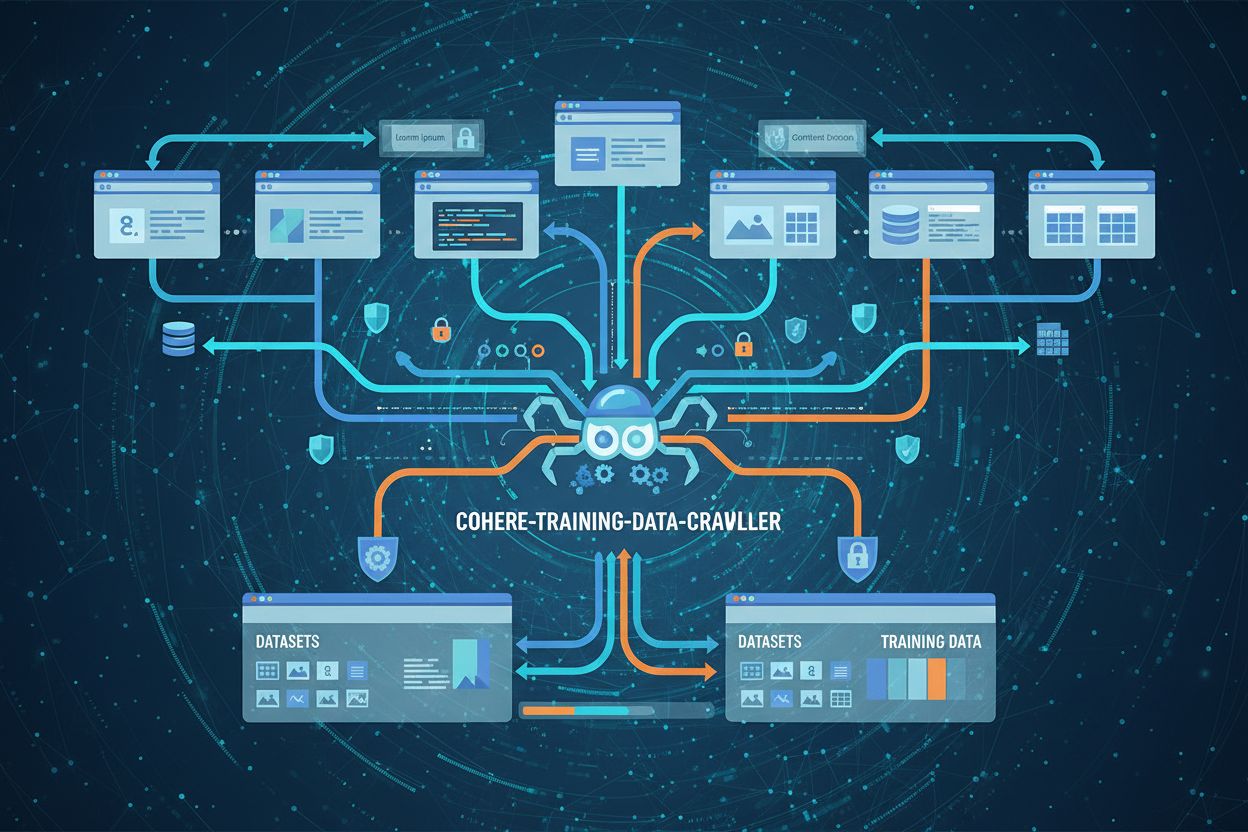
Il cohere-training-data-crawler è un web crawler gestito da Cohere per scaricare e raccogliere sistematicamente contenuti pubblicamente disponibili dai siti web per addestrare i suoi grandi modelli linguistici. A differenza dei crawler tradizionali dei motori di ricerca che indicizzano i contenuti per aiutare gli utenti a trovare informazioni tramite i risultati di ricerca, il crawler di Cohere si concentra specificamente sulla raccolta di contenuti a fini di machine learning, scaricando intere pagine e documenti per costruire dataset di addestramento. Questa distinzione è cruciale: i crawler dei motori di ricerca (come Googlebot) creano indici per il recupero, mentre i data scraper di IA come cohere-training-data-crawler raccolgono contenuti grezzi per migliorare le capacità dei modelli. Il crawler opera con meno trasparenza rispetto ai motori di ricerca riguardo ai criteri di selezione dei siti, frequenza di crawling e priorità d’uso dei dati. I proprietari di siti web possono bloccare il crawler tramite la configurazione di robots.txt aggiungendo la regola “User-agent: cohere-training-data-crawler” seguita da “Disallow: /”, anche se l’efficacia delle diverse modalità di blocco può variare.
Caratteristiche principali del cohere-training-data-crawler:
La famiglia Command rappresenta la suite di punta dei modelli linguistici generativi di Cohere, ciascuno ottimizzato per specifici casi d’uso aziendali e requisiti di performance. Questi modelli sono di tipo conversazionale e seguono istruzioni, eccellendo nella comprensione di compiti aziendali complessi e nella generazione di testi di alta qualità. La famiglia include diverse varianti progettate per bilanciare prestazioni, velocità ed economicità, consentendo alle organizzazioni di scegliere il modello più adatto alle proprie esigenze. I modelli Command supportano funzionalità avanzate tra cui uso di strumenti (che permette agli agenti di IA di interagire con sistemi esterni), retrieval-augmented generation (RAG) per risposte basate su dati proprietari, elaborazione multilingue in 23 lingue e IA agentica per l’automazione autonoma dei flussi di lavoro. L’ultima versione, Command A, è il modello più performante di Cohere, con una lunghezza di contesto di 256K, richiedendo solo due GPU per il deployment e offrendo una produttività superiore del 150% rispetto alle versioni precedenti.
| Nome Modello | Rilascio | Capacità principali | Lunghezza contesto | Ideale per |
|---|---|---|---|---|
| Command A | 2025 | Uso di strumenti, agenti, RAG, multilingue, ragionamento | 256K | Flussi di lavoro aziendali complessi, IA agentica |
| Command R7B | 2024 | RAG, uso di strumenti, agenti, ragionamento | 128K | Applicazioni aziendali rapide ed efficienti |
| Command R+ | 2024 | RAG complesso, uso di strumenti multi-step | 128K | Recupero avanzato e compiti di ragionamento |
| Command R | 2024 | Conversazionale, attività linguistiche, programmazione | 128K | Applicazioni aziendali generiche |
| Aya Expanse | 2024 | Multilingue (23 lingue) | 128K | Aziende globali, contenuti non in inglese |

I modelli Command di Cohere alimentano diverse applicazioni aziendali in molteplici settori, permettendo alle organizzazioni di automatizzare flussi di lavoro complessi e aumentare la produttività su larga scala. Nei servizi finanziari, le istituzioni utilizzano i modelli Command per la generazione automatica di report, analisi finanziaria, comunicazione con i clienti e documentazione di conformità, con clienti come RBC e altre grandi banche che sfruttano la tecnologia per la creazione di contenuti ad alto volume. Le organizzazioni sanitarie impiegano i modelli di Cohere per l’elaborazione di documenti medici, sistemi di Q&A per i pazienti, generazione di note cliniche e analisi di articoli scientifici, dove è fondamentale gestire terminologie specialistiche e mantenere l’accuratezza. Le aziende tecnologiche utilizzano Command per la generazione di codice, la creazione di documentazione, l’integrazione API e strumenti per la produttività degli sviluppatori, con Notion che integra le capacità di Cohere nella propria piattaforma. I settori manifatturiero e logistico beneficiano di automazione dei flussi di lavoro, ottimizzazione della supply chain e generazione di documentazione operativa. Fujitsu, grande conglomerato tecnologico, ha collaborato con Cohere per offrire LLM aziendali sicuri a livello globale, sottolineando l’importanza di sicurezza e personalizzazione nell’adozione dell’IA in azienda. La piattaforma North, alimentata dai modelli Command, rappresenta la soluzione integrata di Cohere per la produttività in azienda, combinando agenti di IA, ricerca intelligente e capacità generative in un unico sistema pronto per l’impresa.
L’operatività del cohere-training-data-crawler solleva importanti considerazioni per i proprietari di siti web, i creatori di contenuti e le organizzazioni interessate all’uso e all’attribuzione dei dati. Sebbene il crawler prenda di mira contenuti pubblicamente disponibili, la raccolta di questi dati per l’addestramento di modelli di IA differisce fondamentalmente dall’indicizzazione web tradizionale, poiché i contenuti diventano parte di dataset di addestramento proprietari con poca trasparenza su come verranno utilizzati o attribuiti. I creatori di contenuti possono avere legittime preoccupazioni per l’uso dei propri lavori nell’addestramento di sistemi di IA commerciali senza esplicito permesso o compenso, soprattutto per contenuti creativi, giornalistici o professionali specializzati. Le implicazioni etiche vanno oltre i singoli siti e si estendono a questioni più ampie sulla provenienza dei dati di addestramento dell’IA, le pratiche di attribuzione e i diritti dei creatori in un’economia guidata dall’IA.
Considerazioni pratiche per la gestione del cohere-training-data-crawler:
Cohere si differenzia dai principali concorrenti IA come OpenAI, Google e Anthropic grazie al focus esplicito sulle esigenze enterprise, sicurezza e capacità di personalizzazione. Mentre ChatGPT di OpenAI e Gemini di Google puntano ai mercati consumer e general-purpose, Cohere si è strategicamente posizionata come piattaforma di IA per le aziende, offrendo funzionalità richieste dalle grandi organizzazioni: implementazioni private all’interno di virtual private cloud (VPC) dedicati, opzioni di deployment on-premises per ambienti isolati e la possibilità di personalizzare i modelli su dati proprietari senza esporre informazioni sensibili a terze parti. Le capacità multilingue della famiglia Aya, che supporta 23 lingue, offrono grandi vantaggi alle imprese globali che operano in più regioni e lingue. L’enfasi di Cohere su tool use e IA agentica consente automazioni di workflow sofisticate che vanno oltre la semplice generazione di testo, permettendo ai sistemi di IA di interagire con applicazioni aziendali, database e API esterne. La flessibilità di deployment su più piattaforme — tra cui Amazon Bedrock, Azure AI Foundry, Oracle GenAI Service e SageMaker — assicura alle aziende l’integrazione dei modelli Cohere nei propri stack tecnologici senza vincolo di fornitore. La combinazione di architettura orientata alla sicurezza, opzioni di personalizzazione, supporto multilingue e affidabilità di livello enterprise rende Cohere la scelta preferita per le organizzazioni che danno priorità a protezione dei dati, conformità e controllo operativo rispetto alle funzionalità IA rivolte ai consumatori.
Cohere è un'azienda di intelligenza artificiale focalizzata sulle imprese che sviluppa grandi modelli linguistici e soluzioni di IA per le aziende. L'azienda offre la famiglia Command di modelli linguistici, che alimentano applicazioni come agenti di IA, generazione di contenuti e retrieval-augmented generation (RAG). Cohere gestisce anche un web crawler chiamato cohere-training-data-crawler che raccoglie contenuti pubblicamente disponibili per addestrare i suoi modelli di IA.
A differenza dei crawler dei motori di ricerca che indicizzano i contenuti per il recupero nei risultati di ricerca, il cohere-training-data-crawler scarica i contenuti specificamente per l'addestramento di modelli di machine learning. I crawler dei motori di ricerca aiutano gli utenti a trovare informazioni, mentre il crawler di Cohere raccoglie dati per migliorare le capacità dei modelli di IA. Il crawler opera con meno trasparenza riguardo alla selezione dei siti e alla frequenza di crawling rispetto ai motori di ricerca tradizionali.
La famiglia Command include diversi modelli linguistici come Command A, Command R e Command R+, ciascuno ottimizzato per diversi casi d'uso. Questi modelli eccellono nell'uso di strumenti, agenti, retrieval-augmented generation (RAG) e attività multilingue. Command A è l'ultimo e più performante modello di Cohere, supporta una lunghezza di contesto di 256K e gestisce ragionamenti complessi, generazione di codice e flussi di lavoro aziendali.
Puoi bloccare il cohere-training-data-crawler aggiungendo una regola robots.txt: User-agent: cohere-training-data-crawler seguito da Disallow: /. Tuttavia, la maggior parte delle aziende affidabili rispetta queste direttive e potresti aver bisogno di restrizioni a livello di server per un blocco completo. Strumenti come Dark Visitors forniscono Agent Analytics per monitorare le visite dei crawler e verificare se le tue regole robots.txt vengono rispettate.
Cohere serve diversi settori tra cui servizi finanziari (analisi dei dati e reportistica), sanità (elaborazione di documenti e Q&A), tecnologia (generazione di codice e automazione), manifatturiero (automazione dei flussi di lavoro) e settore pubblico (recupero di informazioni). Clienti come Oracle, Fujitsu, Notion e Salesforce utilizzano Cohere per generazione di contenuti, ricerca, automazione del servizio clienti e applicazioni di IA aziendali.
Cohere si differenzia per il focus sulle imprese, offrendo implementazioni private, opzioni di personalizzazione e robuste caratteristiche di sicurezza. Mentre OpenAI e Google si concentrano sull'IA per i consumatori, Cohere è specializzata in soluzioni aziendali con opzioni di implementazione flessibili. Cohere supporta 23 lingue con Aya Expanse e punta molto su tool use e capacità agentiche, risultando particolarmente forte per l'automazione aziendale e applicazioni multilingue.
Il crawler raccoglie contenuti pubblicamente disponibili per addestrare modelli di IA, il che solleva domande su attribuzione e su come i tuoi contenuti potrebbero essere usati negli output generati dall'IA. Sebbene i contenuti siano pubblici, potresti voler bloccare il crawler se sei preoccupato per compensi, attribuzione o per come il tuo lavoro creativo appare nei sistemi di IA. La trasparenza di Cohere riguardo allo scopo del crawler aiuta i proprietari di siti a prendere decisioni informate sul blocco.
Sì, Cohere offre accesso API ai suoi modelli tramite varie piattaforme tra cui la propria dashboard proprietaria, Amazon Bedrock, Amazon SageMaker, Microsoft Azure e Oracle GenAI Service. Le aziende possono integrare i modelli Command per la generazione di testo, i modelli Embed per la ricerca semantica e i modelli Rerank per il raffinamento dei risultati. Cohere offre anche implementazioni private e opzioni di personalizzazione per clienti enterprise con specifici requisiti di sicurezza o prestazioni.
Traccia le menzioni del tuo brand su piattaforme di IA come ChatGPT, Perplexity e Google AI Overviews. Ottieni informazioni su come i sistemi di IA citano e fanno riferimento ai tuoi contenuti.
Scopri cos'è un Centro di Eccellenza per la Visibilità dell’IA, le sue principali responsabilità, capacità di monitoraggio e come consente alle organizzazioni d...

Strategia di ricerca AI per aziende: integrazione, governance, metriche di ROI. Scopri come le grandi organizzazioni implementano piattaforme di ricerca AI per ...

Scopri cos'è l'AI agentica, come funzionano gli agenti di AI autonomi, le loro applicazioni reali, i benefici e le sfide. Scopri come l'AI agentica sta trasform...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.