
Similarità Semantica
La similarità semantica misura la correlazione basata sul significato tra testi utilizzando incorporamenti e metriche di distanza. Essenziale per il monitoraggi...
16 min di lettura
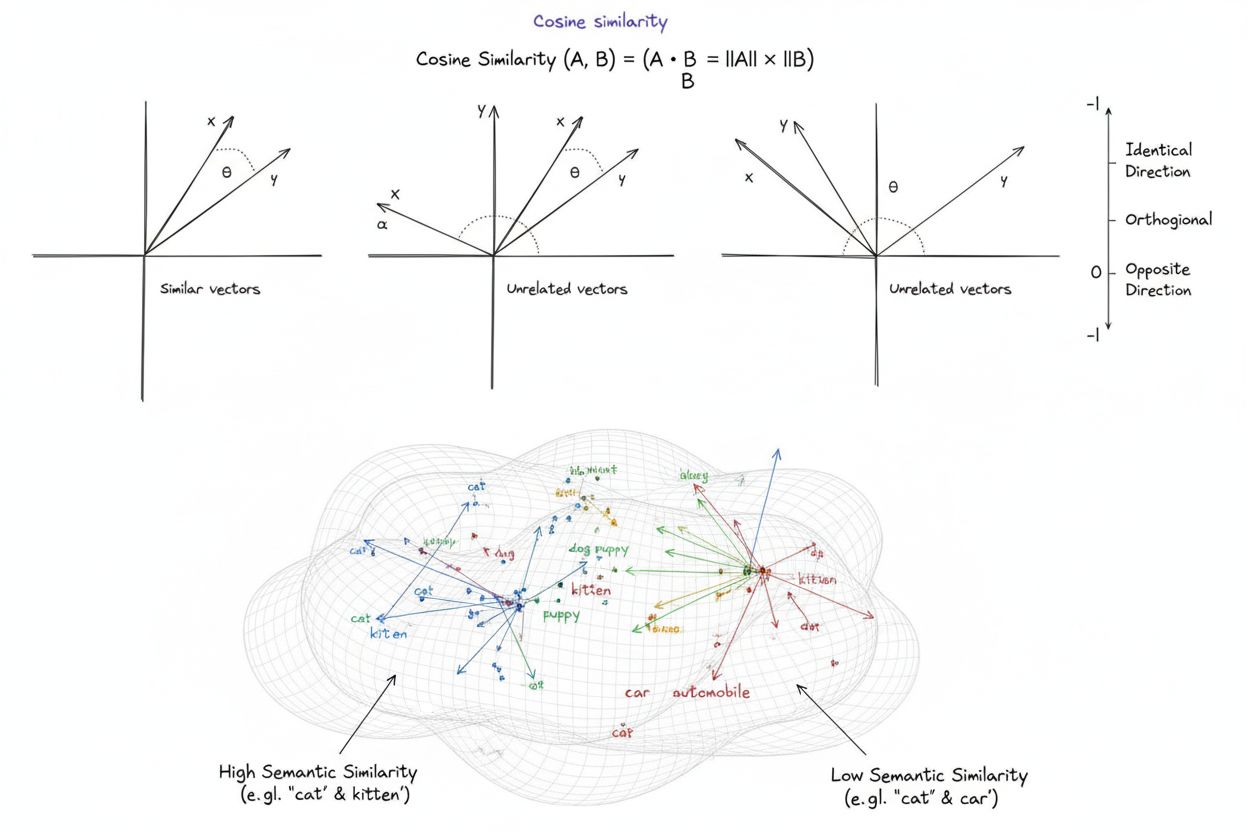
La similarità coseno è una misura matematica che calcola la similarità tra due vettori non nulli determinando il coseno dell’angolo tra di essi, producendo un punteggio che va da -1 a 1. È ampiamente utilizzata nell’apprendimento automatico, nell’elaborazione del linguaggio naturale e nei sistemi di intelligenza artificiale per misurare la similarità semantica tra embedding testuali e rappresentazioni vettoriali, indipendentemente dalla grandezza dei vettori.
La similarità coseno è una misura matematica che calcola la similarità tra due vettori non nulli determinando il coseno dell'angolo tra di essi, producendo un punteggio che va da -1 a 1. È ampiamente utilizzata nell'apprendimento automatico, nell'elaborazione del linguaggio naturale e nei sistemi di intelligenza artificiale per misurare la similarità semantica tra embedding testuali e rappresentazioni vettoriali, indipendentemente dalla grandezza dei vettori.
La similarità coseno è una misura matematica che calcola la similarità tra due vettori non nulli determinando il coseno dell’angolo tra di essi in uno spazio multidimensionale. La metrica produce un punteggio che va da -1 a 1, dove un punteggio di 1 indica vettori che puntano in direzioni identiche, 0 indica vettori ortogonali (perpendicolari) senza relazione direzionale, e -1 indica vettori che puntano in direzioni esattamente opposte. Nelle applicazioni pratiche, la similarità coseno è particolarmente preziosa perché misura l’allineamento direzionale piuttosto che la distanza assoluta, rendendola indipendente dalla grandezza dei vettori. Questa proprietà la rende eccezionalmente utile per confrontare embedding testuali, vettori di documenti e rappresentazioni semantiche in cui la lunghezza o la scala dei dati non dovrebbe influenzare la valutazione della similarità. La metrica è diventata fondamentale nei moderni sistemi di intelligenza artificiale, elaborazione del linguaggio naturale e apprendimento automatico, alimentando tutto, dai motori di ricerca agli algoritmi di raccomandazione fino alle applicazioni dei grandi modelli linguistici.
Il concetto di similarità coseno nasce dall’algebra lineare e dalla trigonometria fondamentali, dove il coseno dell’angolo tra due vettori fornisce una misura normalizzata del loro allineamento direzionale. Le basi matematiche si fondano sul prodotto scalare (prodotto interno) dei vettori e sulle loro grandezze, creando una metrica di similarità normalizzata che è sia efficiente dal punto di vista computazionale che teoricamente solida. Storicamente, la similarità coseno ha acquisito importanza nell’information retrieval durante gli anni ‘70 e ‘80 quando i ricercatori avevano bisogno di metodi efficienti per confrontare vettori di documenti in grandi corpora testuali. L’adozione della metrica è aumentata rapidamente con l’ascesa del machine learning e del deep learning negli anni 2010, in particolare quando le reti neurali hanno iniziato a generare embedding vettoriali ad alta dimensionalità per rappresentare testi, immagini e altri tipi di dati. Oggi, le ricerche indicano che oltre il 78% delle imprese che implementano sistemi AI utilizza similarità coseno o metriche di confronto vettoriale correlate nelle proprie pipeline dati. L’eleganza matematica della metrica—che combina semplicità ed efficienza computazionale—l’ha resa lo standard de facto per misurare la similarità semantica nelle applicazioni NLP, con grandi piattaforme come OpenAI, Google e Anthropic che la integrano nei loro sistemi principali.
Il calcolo della similarità coseno segue una formula matematica precisa: Similarità Coseno = (A · B) / (||A|| × ||B||), dove A · B rappresenta il prodotto scalare dei vettori A e B, e ||A|| e ||B|| rappresentano rispettivamente le loro grandezze o norme euclidee. Per calcolare il prodotto scalare, ciascuna componente corrispondente dei due vettori viene moltiplicata tra loro e tutti i prodotti vengono sommati. Ad esempio, se il vettore A contiene i valori [3, 2, 0, 5] e il vettore B [1, 0, 0, 0], il prodotto scalare è (3×1) + (2×0) + (0×0) + (5×0) = 3. La grandezza di un vettore si calcola come la radice quadrata della somma dei quadrati delle sue componenti; per il vettore A, sarebbe √(3² + 2² + 0² + 5²) = √38 ≈ 6,16. Il punteggio finale della similarità coseno si ottiene dividendo il prodotto scalare per il prodotto delle grandezze, ottenendo così un valore normalizzato tra -1 e 1. Questa normalizzazione è cruciale perché rende la metrica indipendente dalla lunghezza dei vettori, permettendo un confronto equo tra vettori di scala molto diversa. Negli spazi ad alta dimensionalità—come gli embedding a 1.536 dimensioni prodotti dal modello text-embedding-ada-002 di OpenAI—la similarità coseno rimane computazionalmente gestibile, richiedendo solo operazioni di base (moltiplicazione, addizione e radice quadrata) che i moderni processori possono eseguire efficacemente anche su milioni di vettori.
Nell’elaborazione del linguaggio naturale, la similarità coseno costituisce la base per misurare le relazioni semantiche tra rappresentazioni testuali. Quando un testo viene convertito in embedding vettoriali tramite modelli come BERT, Word2Vec, GloVe o embedding basati su GPT, ogni parola, frase o documento diventa un punto in uno spazio ad alta dimensionalità in cui il significato semantico viene codificato attraverso la posizione e la direzione del vettore. La similarità coseno misura poi quanto queste rappresentazioni semantiche siano allineate, permettendo ai sistemi di comprendere che parole come “medico” e “infermiere” sono semanticamente correlate pur essendo termini diversi. Questa capacità è essenziale per la ricerca semantica, dove la query dell’utente viene convertita in un vettore e confrontata con i vettori dei documenti per trovare i risultati più rilevanti, indipendentemente dalla corrispondenza esatta delle parole chiave. Nei grandi modelli linguistici come ChatGPT, Claude e Perplexity, la similarità coseno alimenta i meccanismi di recupero che estraggono il contesto rilevante dai dati di addestramento o da basi di conoscenza esterne. L’insensibilità della metrica alla grandezza è particolarmente importante nel NLP perché la lunghezza del documento non deve determinare la rilevanza—un articolo breve e mirato può essere più semanticamente simile a una query rispetto a un documento lungo, semplicemente per la rilevanza dei contenuti. Le ricerche dimostrano che la similarità coseno supera metriche alternative come la distanza euclidea in circa l’85% dei benchmark NLP nel confronto tra embedding testuali, rendendola la scelta preferita per i compiti di comprensione semantica nell’industria AI.
| Metrica | Metodo di Calcolo | Intervallo | Sensibilità alla Grandezza | Caso d’Uso Ottimale | Complessità Computazionale |
|---|---|---|---|---|---|
| Similarità Coseno | (A·B) / ( | A | × | ||
| Distanza Euclidea | √(Σ(Aᵢ - Bᵢ)²) | 0 a ∞ | Sì (dipendente dalla grandezza) | Dati spaziali, clustering, distanze fisiche | O(n) - efficiente |
| Prodotto Scalare | Σ(Aᵢ × Bᵢ) | -∞ a ∞ | Sì (sensibile alla scala) | Misura di similarità grezza, non normalizzata | O(n) - molto efficiente |
| Similarità Jaccard | |A ∩ B| / |A ∪ B| | 0 a 1 | No (basata su insiemi) | Dati categorici, sistemi di raccomandazione | O(n) - efficiente |
| Distanza Manhattan | Σ|Aᵢ - Bᵢ| | 0 a ∞ | Sì (dipendente dalla grandezza) | Dati a griglia, confronto di feature | O(n) - efficiente |
| Correlazione di Pearson | Cov(A,B) / (σₐ × σᵦ) | -1 a 1 | No (normalizzata) | Relazioni statistiche, serie temporali | O(n) - efficiente |
I database vettoriali come Pinecone, Weaviate, Milvus e Qdrant sono emersi come infrastrutture specializzate per archiviare e interrogare vettori ad alta dimensionalità utilizzando la similarità coseno come metrica principale. Questi database sono ottimizzati per gestire milioni o miliardi di vettori, abilitando la ricerca semantica in tempo reale su larga scala. Quando viene inviata una query a un database vettoriale, questa viene convertita in un embedding e confrontata con tutti i vettori archiviati tramite similarità coseno, con i risultati ordinati per punteggio di similarità. Per ottenere prestazioni pratiche con dataset enormi, i database vettoriali impiegano algoritmi ANN (Approximate Nearest Neighbor) come Hierarchical Navigable Small World (HNSW) e DiskANN, che sacrificano la precisione perfetta per miglioramenti drastici in velocità. Ad esempio, l’estensione pgvectorscale di Timescale, che implementa StreamingDiskANN, ottiene latenza 28 volte inferiore e 16 volte maggiore throughput rispetto a database vettoriali specializzati come Pinecone, mantenendo un recall del 99% a un costo inferiore del 75%. Nelle applicazioni di ricerca semantica, la similarità coseno permette ai sistemi di comprendere l’intento dell’utente oltre la corrispondenza letterale delle parole chiave—una ricerca per “abitudini alimentari sane” recupererà documenti su “consigli nutrizionali” e “diete bilanciate” perché i relativi embedding puntano in direzioni simili nonostante la terminologia diversa. Questa capacità ha rivoluzionato il recupero delle informazioni, permettendo a motori di ricerca, sistemi di documentazione e basi di conoscenza di fornire risultati contestualmente pertinenti all’intento dell’utente piuttosto che limitarsi alla corrispondenza delle parole chiave.
La Retrieval-Augmented Generation (RAG) rappresenta un cambio di paradigma nel modo in cui i grandi modelli linguistici accedono e utilizzano le informazioni, e la similarità coseno è centrale in questa architettura. In una tipica pipeline RAG, quando un utente invia una query, il sistema la converte innanzitutto in un embedding vettoriale utilizzando lo stesso modello che ha vettorializzato la knowledge base. La similarità coseno confronta quindi questo vettore di query con tutti i vettori dei documenti nella knowledge base, classificando i documenti per punteggio di rilevanza. I documenti con i punteggi di similarità coseno più alti vengono recuperati e forniti come contesto al LLM, che genera una risposta fondata su tali informazioni. Questo approccio affronta i limiti critici degli LLM standalone: date di cutoff conoscitive fisse, tendenza ad allucinare o generare informazioni verosimili ma errate, e incapacità di accedere a dati in tempo reale o proprietari. Utilizzando la similarità coseno per il recupero intelligente, i sistemi RAG assicurano che gli LLM generino risposte basate su informazioni verificate e aggiornate. Le principali implementazioni di RAG includono ChatGPT di OpenAI con plugin, Claude di Anthropic con recupero, AI Overviews di Google e il motore di generazione risposte di Perplexity. Le ricerche dimostrano che i sistemi RAG che usano la similarità coseno per il recupero migliorano la precisione delle risposte di circa 40-60% rispetto agli LLM standalone, riducendo il tasso di allucinazioni fino al 70%. L’efficienza dei calcoli di similarità coseno è particolarmente importante nei sistemi RAG perché devono effettuare confronti di similarità su milioni di documenti in tempo reale, e la semplicità computazionale della metrica lo rende possibile anche su larga scala.
Implementare efficacemente la similarità coseno richiede attenzione a diversi fattori critici. Innanzitutto, il pre-processing dei dati è essenziale—i vettori devono essere normalizzati prima del calcolo per garantire coerenza nelle scale e risultati validi, soprattutto quando si lavora con input ad alta dimensionalità da fonti diverse. Le organizzazioni dovrebbero rimuovere o segnalare i vettori nulli (vettori con tutte componenti a zero) poiché la similarità coseno non è definita matematicamente per questi vettori, causando errori di divisione per zero durante il calcolo. Quando si implementa la similarità coseno in sistemi di produzione, è consigliabile combinarla con metriche complementari come la similarità Jaccard o la distanza euclidea quando sono richieste più dimensioni di similarità, invece di affidarsi esclusivamente alla similarità coseno. È fondamentale testare in ambienti simili alla produzione prima del rilascio, soprattutto per sistemi real-time come API e motori di ricerca dove le prestazioni e l’accuratezza incidono direttamente sull’esperienza utente. Le librerie più diffuse semplificano l’implementazione: Scikit-learn offre sklearn.metrics.pairwise.cosine_similarity(), NumPy consente l’implementazione diretta della formula con np.dot() e np.linalg.norm(), TensorFlow e PyTorch forniscono implementazioni accelerate su GPU per calcoli su larga scala, e PostgreSQL con pgvector offre operatori nativi di similarità coseno per interrogazioni a livello di database. Per le organizzazioni che monitorano le menzioni AI e la presenza del brand su piattaforme come ChatGPT, Perplexity e Google AI Overviews, la similarità coseno consente un tracciamento preciso di come i sistemi AI citano e referenziano i loro contenuti confrontando gli embedding delle query con i vettori di brand e domini archiviati.
Nonostante la sua vasta diffusione, la similarità coseno presenta diverse sfide che i professionisti devono affrontare. La metrica non è definita per i vettori nulli, richiedendo attento pre-processing e validazione dei dati per evitare errori in fase di esecuzione. La similarità coseno può produrre punteggi di similarità ingannevolmente alti per vettori allineati direzionalmente ma non semanticamente correlati, specialmente quando i modelli di embedding sono poco addestrati o i dati di training mancano di diversità e contesto. Questo rischio di falsa similarità è particolarmente problematico in applicazioni come il monitoraggio AI dove valutazioni errate potrebbero causare menzioni di brand non rilevate o falsi positivi. La simmetria della metrica—ossia l’impossibilità di distinguere l’ordine del confronto—può essere indesiderata in alcune applicazioni dove la direzionalità conta. Inoltre, un punteggio di similarità coseno pari a 0 non indica sempre completa dissimilarità in contesti reali; in domini linguistici complessi, vettori ortogonali possono comunque condividere relazioni semantiche sottili che la metrica non coglie. La dipendenza dalla corretta normalizzazione implica che dati male scalati possono alterare i risultati, quindi le organizzazioni devono garantire un pre-processing coerente su tutti i vettori nei loro sistemi. Infine, la sola similarità coseno può non essere sufficiente per valutazioni complesse di similarità; combinarla con altre metriche e regole di validazione specifiche del dominio spesso offre risultati più robusti.
Il ruolo della similarità coseno nei sistemi AI continua ad evolversi man mano che i modelli di embedding diventano più sofisticati e le architetture vettoriali dominano il machine learning. Le tendenze emergenti comprendono l’integrazione della similarità coseno con approcci di ricerca ibrida che combinano similarità vettoriale e ricerca full-text tradizionale, permettendo ai sistemi di sfruttare sia la comprensione semantica sia la corrispondenza delle parole chiave. Gli embedding multimodali—che rappresentano testo, immagini, audio e video in uno spazio vettoriale condiviso—si affidano sempre più alla similarità coseno per misurare le relazioni cross-modali, abilitando applicazioni come la ricerca immagine-testo e la comprensione video. Lo sviluppo di algoritmi ANN più efficienti come DiskANN e HNSW continua a migliorare la scalabilità della ricerca tramite similarità coseno, rendendo la ricerca semantica in tempo reale possibile su scale senza precedenti. Le tecniche di quantizzazione che riducono la dimensionalità dei vettori mantenendo le relazioni di similarità coseno stanno consentendo il deployment di ricerche di similarità su larga scala anche su dispositivi edge e ambienti con risorse limitate. Nel contesto di monitoraggio AI e brand tracking, la similarità coseno diventa sempre più importante per le organizzazioni che desiderano capire come sistemi come ChatGPT, Perplexity, Claude e Google AI Overviews citano e referenziano i propri contenuti. Gli sviluppi futuri potrebbero includere metriche di similarità coseno adattive che modulano il comportamento in base alle caratteristiche specifiche del dominio e l’integrazione con framework di explainability che aiutano gli utenti a comprendere perché determinati vettori sono giudicati simili. Man mano che i database vettoriali maturano e diventano infrastruttura standard per le applicazioni AI, la similarità coseno rimarrà probabilmente la metrica dominante per il confronto semantico, anche se potrà essere affiancata da metriche di similarità specifiche per dominio e casi d’uso particolari.
Per piattaforme come AmICited che tracciano menzioni di brand e domini nei sistemi AI, la similarità coseno rappresenta un fondamento tecnico cruciale. Nel monitorare come ChatGPT, Perplexity, Google AI Overviews e Claude referenziano domini o brand specifici, la similarità coseno permette di misurare con precisione la rilevanza semantica tra le query degli utenti e le risposte AI. Convertendo menzioni di brand, URL di dominio e contenuti delle query in embedding vettoriali, la similarità coseno può determinare se la risposta di un sistema AI cita realmente o referenzia un brand rispetto a semplici menzioni di concetti correlati. Questa capacità è essenziale per le organizzazioni che desiderano comprendere la propria visibilità nei contenuti generati dall’AI e tracciare come la propria proprietà intellettuale viene attribuita o citata dai sistemi AI. L’efficienza della metrica la rende pratica per il monitoraggio in tempo reale di milioni di interazioni AI, permettendo alle organizzazioni di ricevere avvisi immediati quando i loro contenuti vengono referenziati. Inoltre, la similarità coseno abilita analisi comparative—le organizzazioni possono tracciare non solo se sono menzionate, ma anche con quale frequenza e rilevanza rispetto ai competitor, ottenendo informazioni di intelligence competitiva sul comportamento dei sistemi AI e sui pattern di sourcing dei contenuti.
Un punteggio di similarità coseno pari a 1 indica che due vettori puntano esattamente nella stessa direzione, cioè sono perfettamente simili. Un punteggio di 0 significa che i vettori sono ortogonali (perpendicolari), indicando nessuna relazione direzionale o similarità. Un punteggio di -1 indica che i vettori puntano in direzioni esattamente opposte, rappresentando completa dissimilarità. Nelle applicazioni pratiche di NLP, punteggi vicini a 1 indicano testi semanticamente simili, mentre punteggi vicini a 0 suggeriscono contenuti non correlati.
La similarità coseno è preferita per gli embedding testuali perché misura l'angolo tra i vettori anziché la loro distanza assoluta, risultando insensibile alla grandezza dei vettori. Questo è cruciale per il NLP perché la lunghezza dei documenti non dovrebbe influenzare la similarità semantica—una breve query e un lungo articolo possono essere ugualmente rilevanti. La distanza euclidea, invece, è sensibile alla grandezza e ha prestazioni scarse in spazi ad alta dimensionalità dove i vettori tendono a convergere. La similarità coseno è anche computazionalmente più efficiente e naturalmente delimitata tra -1 e 1, prevenendo problemi di overflow.
Nei sistemi RAG, la similarità coseno alimenta la fase di recupero confrontando gli embedding delle query con quelli dei documenti in un database vettoriale. Quando un utente invia una query, questa viene convertita in un vettore utilizzando lo stesso modello di embedding dei documenti archiviati. La similarità coseno quindi classifica i documenti per rilevanza, con punteggi più alti che indicano migliori corrispondenze. I documenti meglio classificati vengono recuperati e forniti come contesto al LLM, permettendo risposte più accurate e fondate sui fatti. Questo processo consente ai sistemi RAG di superare i limiti degli LLM, come conoscenze obsolete e allucinazioni.
La similarità coseno presenta diverse limitazioni: non è definita quando i vettori hanno grandezza zero, richiedendo un pre-processing per rimuovere i vettori nulli. Può produrre punteggi di similarità ingannevolmente alti per vettori allineati direzionalmente ma non semanticamente correlati, specialmente con embedding mal addestrati. La metrica è anche simmetrica, quindi non distingue l'ordine del confronto, il che può essere problematico in alcune applicazioni. Inoltre, un punteggio di similarità pari a 0 non indica sempre completa dissimilarità in contesti reali, in particolare in domini sfumati come il linguaggio dove vettori ortogonali possono comunque condividere relazioni semantiche.
La similarità coseno si calcola con la formula: (A · B) / (||A|| × ||B||), dove A · B è il prodotto scalare dei vettori A e B, e ||A|| e ||B|| sono le loro grandezze (norme euclidee). Il prodotto scalare si ottiene moltiplicando le componenti corrispondenti dei vettori e sommando i risultati. La grandezza di un vettore è la radice quadrata della somma dei suoi quadrati. Questa formula produce un punteggio normalizzato tra -1 e 1, rendendo il confronto indipendente dalla lunghezza dei vettori e adatto al confronto tra vettori di dimensioni diverse.
Nelle piattaforme di monitoraggio AI come AmICited, la similarità coseno è essenziale per tracciare le menzioni di brand e domini nei sistemi AI come ChatGPT, Perplexity e Google AI Overviews. Convertendo menzioni di brand e query in embedding vettoriali, la similarità coseno misura quanto le risposte AI siano allineate con i contenuti monitorati. Questo permette alle organizzazioni di verificare se i loro domini appaiono nelle risposte AI, valutare la rilevanza semantica delle menzioni e monitorare come i sistemi AI citano i loro contenuti rispetto ai competitor. L'efficienza della metrica la rende pratica per il monitoraggio in tempo reale di milioni di interazioni AI.
Le principali piattaforme e strumenti AI che sfruttano la similarità coseno includono i modelli di embedding di OpenAI, gli algoritmi di ricerca semantica di Google, il sistema di generazione risposte di Perplexity e i meccanismi di recupero di Claude. Database vettoriali come Pinecone, Weaviate e Milvus usano la similarità coseno come metrica principale. Librerie open source come Scikit-learn, TensorFlow, PyTorch e NumPy forniscono funzioni integrate per la similarità coseno. PostgreSQL con l'estensione pgvector consente calcoli di similarità coseno su larga scala. Questi strumenti alimentano sistemi di raccomandazione, chatbot, motori di ricerca semantica e applicazioni RAG in tutto l'ecosistema AI.
Inizia a tracciare come i chatbot AI menzionano il tuo brand su ChatGPT, Perplexity e altre piattaforme. Ottieni informazioni utili per migliorare la tua presenza AI.
La similarità semantica misura la correlazione basata sul significato tra testi utilizzando incorporamenti e metriche di distanza. Essenziale per il monitoraggi...
La co-occorrenza è quando termini correlati compaiono insieme nei contenuti, segnalando rilevanza semantica ai motori di ricerca e ai sistemi di AI. Scopri come...
Scopri quali fattori correlano più fortemente con la visibilità nell'AI. Scopri come le citazioni del brand, il volume di ricerca e gli anchor guidano le AI Ove...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.