
Meta Tag NoAI: Controllare l’Accesso dell’AI Tramite Header
Scopri come implementare i meta tag noai e noimageai per controllare l’accesso dei crawler AI ai contenuti del tuo sito. Guida completa ai header di controllo e...
7 min di lettura
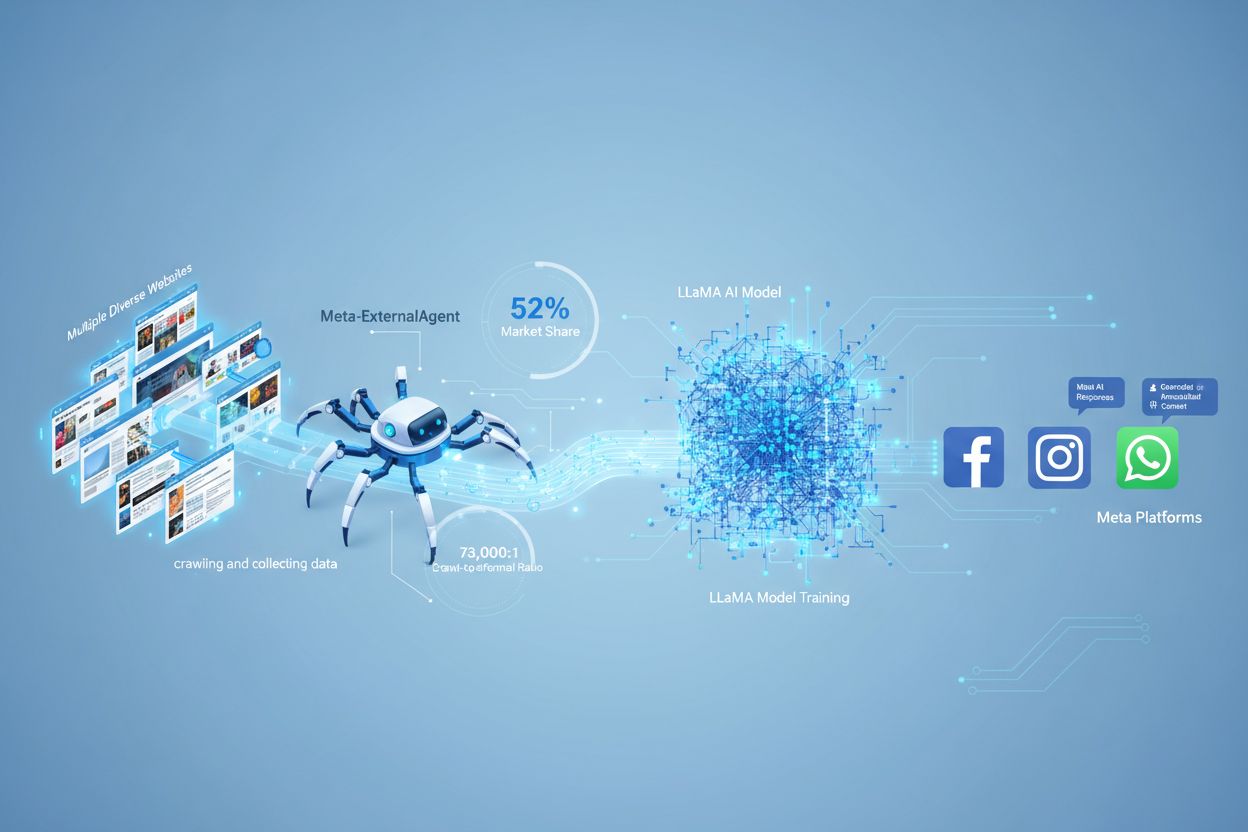
Meta-ExternalAgent è il bot crawler web di Meta lanciato a luglio 2024 per raccogliere contenuti pubblicamente disponibili da utilizzare nell’addestramento di modelli di intelligenza artificiale come LLaMA. Si identifica con la stringa User-Agent meta-externalagent/1.1 e controlla se i contenuti appaiono o meno nelle risposte di Meta AI su Facebook, Instagram e WhatsApp. I publisher possono bloccarlo tramite robots.txt o configurazioni a livello di server, anche se il rispetto di queste direttive è volontario e non vincolante a livello legale.
Meta-ExternalAgent è il bot crawler web di Meta lanciato a luglio 2024 per raccogliere contenuti pubblicamente disponibili da utilizzare nell’addestramento di modelli di intelligenza artificiale come LLaMA. Si identifica con la stringa User-Agent meta-externalagent/1.1 e controlla se i contenuti appaiono o meno nelle risposte di Meta AI su Facebook, Instagram e WhatsApp. I publisher possono bloccarlo tramite robots.txt o configurazioni a livello di server, anche se il rispetto di queste direttive è volontario e non vincolante a livello legale.
Meta-ExternalAgent è un web crawler gestito da Meta Platforms, lanciato a luglio 2024 per raccogliere dati da utilizzare nell’addestramento di modelli di intelligenza artificiale. Identificato dalla stringa User-Agent meta-externalagent/1.1, questo crawler si distingue dal precedente facebookexternalhit di Meta, usato principalmente per anteprime dei link e funzionalità di condivisione sui social. Meta-ExternalAgent rappresenta un cambiamento significativo nel modo in cui Meta acquisisce dati di addestramento per le sue iniziative AI, inclusi i modelli linguistici LLaMA e il chatbot Meta AI integrato su Facebook, Instagram e WhatsApp. A differenza dei crawler precedenti di Meta, questo agente opera con scarsa trasparenza ed è stato distribuito senza un annuncio pubblico formale.

Meta-ExternalAgent funziona come un bot automatico che scansiona sistematicamente i siti web in Internet per estrarre testi e contenuti da usare nell’addestramento dei modelli AI. Il crawler invia richieste HTTP ai server web, si identifica tramite un header User-Agent univoco e scarica i contenuti delle pagine per l’elaborazione. Una volta raccolti, i sistemi di Meta analizzano e tokenizzano i testi, convertendoli in dati di addestramento per migliorare le capacità dei modelli linguistici di grandi dimensioni. Il crawler rispetta il file robots.txt su base volontaria, secondo un sistema d’onore e non un obbligo legale. Secondo i dati di Cloudflare, Meta-ExternalAgent rappresenta circa il 52% di tutto il traffico dei crawler AI a livello globale, rendendolo una delle operazioni di raccolta dati più aggressive nel settore AI. Il crawler opera in modo continuo, e alcuni publisher segnalano frequenze di scansione che suggeriscono una priorità di copertura globale dei contenuti web rispetto a una raccolta selettiva e mirata.
| Nome Crawler | Stringa User-Agent | Scopo Principale | Data Lancio | Uso dei Dati |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | Addestramento modelli AI (LLaMA, Meta AI) | Luglio 2024 | Dati di addestramento per AI generativa |
| facebookexternalhit | facebookexternalhit/1.1 | Anteprime link e condivisione social | ~2010 | Metadati Open Graph, miniature |
| Facebot | facebot/1.0 | Verifica contenuti app Facebook | ~2015 | Validazione contenuti per app mobili |
| Applebot | Applebot/0.1 | Siri di Apple e indicizzazione ricerche | ~2015 | Indicizzazione e assistenti vocali |
| Googlebot | Googlebot/2.1 | Indicizzazione ricerca Google | ~1998 | Costruzione indice motore ricerca |
Meta-ExternalAgent rappresenta un tema critico per creatori di contenuti e publisher perché opera su una scala senza precedenti offrendo pochissima visibilità su come i contenuti vengono utilizzati. Secondo Cloudflare, Meta-ExternalAgent genera il 52% di tutto il traffico dei crawler AI, superando di gran lunga concorrenti come GPTBot di OpenAI e i crawler AI di Google. Questo predominio significa che Meta raccoglie più dati per l’addestramento AI di qualsiasi altra azienda, ma i publisher non ricevono alcuna compensazione o attribuzione quando i loro contenuti vengono usati per addestrare i modelli di Meta. Il rapporto crawl-to-referral di 73.000:1 dimostra che Meta estrae quantità enormi di contenuti senza restituire praticamente traffico ai siti sorgente: uno squilibrio fondamentale nello scambio di valore. Nonostante questi problemi, solo il 2% dei siti web blocca attivamente Meta-ExternalAgent, rispetto al 25% che blocca GPTBot, segno che molti publisher non sono consapevoli della presenza del crawler o delle sue implicazioni. Con Meta che investe 40 miliardi di dollari in infrastruttura AI, è probabile che l’impegno nella raccolta dati diventi sempre più aggressivo, rendendo essenziale per i publisher comprendere e gestire attivamente il proprio rapporto con questo crawler.
I publisher possono controllare l’accesso di Meta-ExternalAgent tramite il file robots.txt, ma è importante sapere che questo sistema è volontario e non legalmente vincolante. Per bloccare Meta-ExternalAgent, aggiungi questa direttiva al tuo file robots.txt:
User-agent: meta-externalagent
Disallow: /
In alternativa, se vuoi consentire al crawler l’accesso solo ad alcune directory, puoi usare:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Tuttavia, alcuni publisher hanno segnalato che Meta-ExternalAgent continua a scansionare i loro siti anche dopo il blocco tramite robots.txt, il che suggerisce che Meta potrebbe non rispettare sempre queste direttive. Per una protezione più efficace, è possibile implementare blocchi a livello di header HTTP o utilizzare regole di Content Delivery Network (CDN) per identificare e rifiutare le richieste provenienti da Meta-ExternalAgent sulla base della stringa User-Agent. Inoltre, i publisher possono monitorare i log del server per la stringa User-Agent meta-externalagent/1.1 e verificare se il crawler accede ai loro contenuti. Strumenti come AmICited.com aiutano a tracciare se i contenuti vengono citati o referenziati nelle risposte di Meta AI, offrendo visibilità su come le opere vengono utilizzate dai sistemi AI di Meta.

Quando gli utenti interagiscono con i chatbot Meta AI su Facebook, Instagram o WhatsApp, le risposte generate si basano anche sui contenuti raccolti da Meta-ExternalAgent. Tuttavia, le risposte di Meta AI di solito non includono citazioni visibili o attribuzioni ai siti sorgente, il che significa che gli utenti non possono sapere quali publisher hanno contribuito alle risposte ricevute. Questa mancanza di trasparenza crea una sfida importante per i creatori di contenuti che vogliono comprendere il valore che il proprio lavoro offre ai sistemi AI di Meta. A differenza di alcuni concorrenti che includono citazioni nelle risposte AI, Meta privilegia l’esperienza utente rispetto all’attribuzione al publisher. L’assenza di citazioni visibili rende difficile per i publisher monitorare con quale frequenza i loro contenuti influenzano le risposte di Meta AI, complicando la valutazione dell’impatto aziendale derivante dall’uso dei loro contenuti per l’addestramento AI. Questa carenza di visibilità è uno dei motivi principali per cui le soluzioni di monitoraggio stanno diventando sempre più importanti per i publisher che desiderano comprendere il proprio ruolo nell’ecosistema AI.
I publisher possono verificare l’attività di Meta-ExternalAgent tramite l’analisi dei log del server, che mostra gli indirizzi IP del crawler, i pattern delle richieste e la frequenza di accesso ai contenuti. Esaminando i log di accesso, è possibile identificare richieste con la stringa User-Agent meta-externalagent/1.1 e capire quali pagine vengono scansionate più frequentemente. Strumenti avanzati di monitoraggio possono tracciare i pattern di scansione nel tempo, rivelando se Meta dà priorità a certi tipi di contenuto o sezioni di un sito. I publisher dovrebbero anche monitorare l’uso della propria banda, dato che una scansione aggressiva da parte di Meta-ExternalAgent può consumare risorse significative, specialmente per siti con grandi archivi di contenuti. Inoltre, strumenti come AmICited.com consentono di monitorare se i propri contenuti compaiono nelle risposte di Meta AI e tracciare i pattern di citazione sulle piattaforme Meta. Impostare avvisi per attività di scansione insolita può aiutare i publisher a rilevare cambiamenti nei comportamenti di raccolta dati e rispondere in modo proattivo. Audit regolari dei log del server dovrebbero far parte di ogni strategia di gestione dei crawler AI per mantenere la consapevolezza su come i contenuti vengono acceduti e utilizzati.
Lo status legale di Meta-ExternalAgent è oggetto di dibattito, con cause in corso da parte di creatori, artisti ed editori che contestano il diritto di Meta di utilizzare le loro opere per l’addestramento AI senza consenso esplicito o compenso. Mentre Meta sostiene che il web crawling rientri nel fair use, i critici affermano che la scala e la natura commerciale della raccolta dati, unite all’assenza di attribuzione, costituiscano una violazione del copyright. Il file robots.txt, pur essendo uno standard di settore ampiamente rispettato, non ha valore legale, quindi Meta non è obbligata a rispettare le direttive di blocco. Diverse giurisdizioni stanno sviluppando regolamenti sull’addestramento AI, con l’AI Act dell’Unione Europea e proposte di legge in altre regioni che potrebbero imporre requisiti più severi a società come Meta. Da un punto di vista etico, la questione centrale è se i creatori di contenuti debbano avere il diritto di controllare l’uso commerciale delle proprie opere nell’AI e se il sistema attuale li compensi adeguatamente per il valore fornito. I publisher dovrebbero restare aggiornati sulle evoluzioni legali e valutare la consulenza di un legale in merito ai propri diritti e obblighi sull’accesso dei crawler AI. Il bilanciamento tra favorire l’innovazione AI e tutelare i diritti dei creatori resta irrisolto, rendendo quest’area soggetta a sviluppi normativi e legali continui.
Lo scenario della gestione dei crawler AI sta evolvendo rapidamente mentre publisher, regolatori e aziende AI negoziano le condizioni per la raccolta e l’uso dei dati. Il dispiegamento aggressivo di Meta-ExternalAgent segnala che le grandi aziende tech vedono i contenuti web come materiale essenziale per addestrare sistemi AI competitivi, e questa tendenza è destinata ad accelerare man mano che l’AI diventa centrale nelle strategie aziendali. Gli sviluppi futuri potrebbero includere tutele legali più forti per i creatori, sistemi di licensing obbligatori per i dati di addestramento AI e standard tecnici che facilitino il controllo e la monetizzazione dell’uso dei contenuti nei sistemi AI. L’emergere di strumenti come AmICited.com riflette la crescente domanda di trasparenza e responsabilità su come i contenuti pubblicati vengono usati dai sistemi AI, suggerendo che il monitoraggio e la verifica diventeranno pratiche standard per i creatori. Con la maturazione del settore AI, ci si può aspettare negoziati più sofisticati tra creatori e aziende AI, potenzialmente portando a nuovi modelli di business che compensino equamente i publisher per il contributo all’addestramento AI.
Meta-ExternalAgent è il crawler AI dedicato all’addestramento lanciato da Meta a luglio 2024, identificato dalla stringa User-Agent meta-externalagent/1.1. Si differenzia da facebookexternalhit, che genera anteprime dei link per la condivisione sociale. Meta-ExternalAgent raccoglie specificamente contenuti per addestrare i modelli LLaMA e Meta AI, mentre facebookexternalhit è usato per le funzionalità social dal 2010 circa.
Puoi bloccare Meta-ExternalAgent aggiungendo delle direttive al file robots.txt. Inserisci 'User-agent: meta-externalagent' seguito da 'Disallow: /' per bloccarlo completamente. Per una protezione più ampia, implementa un blocco a livello di server usando .htaccess (Apache) o regole di configurazione Nginx. Tuttavia, robots.txt è volontario e non legalmente vincolante, quindi alcuni publisher segnalano che il bot continua a scansionare nonostante i blocchi.
No, bloccare Meta-ExternalAgent non influisce sulle anteprime dei link su Facebook. Il crawler facebookexternalhit si occupa delle anteprime e delle funzionalità di condivisione sociale. Puoi bloccare meta-externalagent e consentire comunque a facebookexternalhit di generare anteprime quando i tuoi contenuti vengono condivisi sulle piattaforme Meta.
Meta-ExternalAgent ha un rapporto crawl-to-referral di circa 73.000:1, il che significa che Meta estrae contenuti su scala enorme senza restituire praticamente traffico ai siti sorgente. Questo rappresenta uno squilibrio fondamentale rispetto ai motori di ricerca tradizionali, che scansionano i contenuti in cambio di traffico di referral.
robots.txt è un sistema basato sulla fiducia e non è legalmente vincolante. Sebbene molti crawler rispettino le direttive di robots.txt, alcuni publisher hanno segnalato che Meta-ExternalAgent continua a scansionare i loro siti nonostante i blocchi espliciti. Per una protezione garantita, implementa un blocco a livello di server usando intestazioni HTTP, regole CDN o configurazioni firewall.
Controlla i log di accesso del server per richieste con la stringa User-Agent 'meta-externalagent/1.1'. Puoi anche usare strumenti di monitoraggio come AmICited.com per verificare se i tuoi contenuti compaiono nelle risposte di Meta AI. Strumenti come Dark Visitors e Cloudflare Analytics offrono ulteriori approfondimenti sull’attività dei crawler AI sul tuo sito.
Secondo i dati Cloudflare, Meta-ExternalAgent rappresenta circa il 52% di tutto il traffico dei crawler AI su Internet, rendendolo l’operazione di raccolta dati AI più aggressiva. Questo supera di molto concorrenti come GPTBot di OpenAI e i crawler AI di Google, indicando la posizione dominante di Meta nella raccolta di contenuti web per l’addestramento AI.
La decisione dipende dalle priorità del tuo business. Se il traffico di Meta AI è prezioso per il tuo pubblico, potresti consentirlo. Tuttavia, considera che Meta non offre compensi o attribuzione per i contenuti usati nell’addestramento AI. Molti publisher adottano strategie di blocco selettivo per impedire l’addestramento AI mantenendo le anteprime social.
Tieni traccia di come i tuoi contenuti appaiono nelle risposte di Meta AI su Facebook, Instagram e WhatsApp. Ottieni visibilità sulle citazioni AI e comprendi la presenza del tuo brand nelle risposte generate dall’intelligenza artificiale.
Scopri come implementare i meta tag noai e noimageai per controllare l’accesso dei crawler AI ai contenuti del tuo sito. Guida completa ai header di controllo e...

Comprendi come funzionano i crawler AI come GPTBot e ClaudeBot, le loro differenze rispetto ai crawler di ricerca tradizionali e come ottimizzare il tuo sito pe...

Scopri come l'ottimizzazione Meta AI trasforma la pubblicità su Facebook e Instagram con automazione basata su AI, offerte in tempo reale e targeting intelligen...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.